Gene
KWMTBOMO14358
Annotation
PREDICTED:_RNA-directed_DNA_polymerase_from_mobile_element_jockey-like_[Plutella_xylostella]
Location in the cell
Nuclear Reliability : 3.342
Sequence
CDS
ATGTCGGGGGGGAACCCACCTCCAACTATCAGCACACCCGGCCCGTCTCATAAGGGACGACAGGCAATGCCGGAAGTTCAATTACCAACACCAACACCTGCAATCCGTATGGCCCCGATGGGACCCGGTGCGGGCAGTTCGGCCGGGCCTTCGGCCGCGGCCAGGGGACCCCTGAGGATCGTACCGGTGGAAAGTAACTTTCCTACGTCGGCCGATCCCTCTGGGCCCTCTCGGCCGCGGAAGAAGGCCAGGTCAGAGTCTGACCGAGGCTCATCGGGCGACCAAGATAAACGCCCACGTATAGGCCCTTCCTCCAGGTCGGAGGGAGAAGAGAGCGTGACCACGTCCACGGATCACTCCTCTACCGAGTCTATTACTCCTTCCTCGTCAAGATCCACTTCCCCCTCTGGGAGTCCGATCCCAGTCCAACCCGTTCCTAAGCCTAGAGCACCCGCCAGGACAGGGATTGCTCCTAGGCAATTGAGAACCCCTCCTCACTCTCCTTCCCCAACCCTATCCCCAATCCCGGTGGACTCTACCCGAGGTGCCCCCGCCCTAAGCGGCACGGCGGGTAACCTGGACTCCACCAGGTATATGGACCTAGAGTCCACCAGACCGCATCACGCGCCTAAGACAAATCCTACGCCCTCTACCTCCTATGCTGCTATGGCAGCTAGGCCGGGTATCCCATCCATCCAGAGGACATCCCAATCCTCTCATGTCCCTCCCCCGAGGCCGAAGGGTCGTGCCCAGGAGGAGCTGCGCCGACATCCGCCAATAATGGTGGAGGCCCTCCCTAATTGGTCCCGCCACATGGCGGCCATTAGGGAGCGCCTTGGCCGCGCCCCCTCGGCGCGACCCTTCGGCGCCGGTTTTAGATTCCTGCCGACGTCGGTTGAGGAATACAGGGCGGTCCAGGCCTACCTGTCGGAGGCCTCTGCCAGGGATAGTACCATTAAATGGTACTGCTATGCCCTGACAGGGGAGATTCCGACCAAGGTGGCTGTCCGGGGCCTCCCTGCCGATACTGACGCGGCAGAAATAACCGATGCCCTGAAGGAGCTGGGGTTCCCGGCTCGTCACGCCAGGTGCATCAGGTCCCAGAGAGGGCGCCCGGGCTGCGTGTTTCACGTAGCCTTGGACCACCTCTCGAAGGACGACCTCGCCCGCCTGTACGCAGTCAACGAACTGCTGTACTTGCCGGGGGTGACAGTTGAGGGATGGCGACCAACCCGCGGGCCTGCGCAGTGTCATCGCTGCCAGGCCTTCGGGCACGCCTCGAACAATTGTCACCGAGCGGTCCGTTGTGTTCGATGTGCCGGGGAGCACGTCGTAGCGGACTGCCCGAGGCCGAGGGACGGCCCATTCTCCTGCGCCAATTGCGGGAAGGACCACGCCGCCGTTGATAGGCGGTGTCCGGTCTACCGCAAGAAGGCCAGGATGATGGGAGTAACCGTCCCTCCTCCTGCGCCAATGGTGCCTCGACCCGGGAACACAGCTCTTCCCTCTGTAGCTCCCATTCCAAAGGGGAAGGGGAAAGGGAAAGGGAAATCCTCCCAGCCCCAACCCCCTCCCCTGTCCTCACCCATCCCCCCTGCCGTCTCAGTGGAGGCCAATCCATCAGCGGCAACGCTGATGGCAGAGGCCAACGCTCCGCGGCGGGGTATACCTGTTCCTACCCCTCGTGGTTCACACGCTGTTAGACCGCCCCATCTAAAAAGCAGCGTTCCAGCTCGTGCTGGAACACAAGCCCCGCAAATATCAGGTCCTAAACAAAAAAAAAATCGGCTTAAAAAATTGAAAAAAAAGCAAAAAAAGAGAGCTCAACGGGATGCAGCGGTGAGTGCTCCTGCTGCACCGGCTCCCGCGGTATCTACAATGGAGGTGGACGTAAACCCACCCATCGACCCAACTTCTCAACCGATTTCACAATCGGGAACGACCCCACTGCCCCAGGCTCAACCAGCCATCTCGGGCATATCTCAGCCCCCTCTCCCCCCCCGCCCGCAGCGCGAGCGGCGCAGCGACCGACAGGCCTCACAGCCTGCCGGTTTCGCTGCCTGGCTTCTCGCATTGTGGGAGAAATTGTCCGAGGTGATCTCCGGAGTAATCCGTGAGATCGCCTCGGGAGCCAGTCCCTTTGGGGCTATCCTCCAAGAGCTTCGCATCATCTATTGGAACCCCGACGGGATAAAGTCCCGGAAAAACGAGCTGCTTGTTCTCGCCCGGGAGTACAACCCTGAGGTTCTGCTCCTGGGCGAGACCAAGCTACGTCCTCAGGATGCGTTCAGGATTCCAAACTACTTCATGTACCGACGTGACGAGCTTACCCCTGCCGGGCGGCCGTTCAGGGGCACTGCGGCCCTCGTCAGGCGGGACGTGGTGCATGATCAGTTGGATTTGCTGTCCTTCACATCGACAAGGTCGGTCGGTGTGAGGGTACACACCTCGGGGGGGGATATGCGGATTTATGCCGCGTATAGACCCCCGGGGCCTGAATTTCACCCTGATGACATAAGACGGGCCCTGAATCACGACAGCCGCCCAGCTCTGCTGGTCGGGGACCTCAACGCGAAGCACGTCGCGTGGGGCTCCCGACTTAACTCAGCAGTGGGCAGGCGGCTGTTAGAAGATGCCGATAGGGGCGACTACTCCGTGGTCGGCCCCGACGAACCCACACACATCCCGATCGCCGCGCGCTATCAACCCGATGTGCTGGATGTGTGTGTGCACAAGGGGCTACGGTGCCCCGTAACGATCGAGGCACTGTACGACCTGGGTACCCCACATCTCCCTATCCTGGTGACACTGGGAATGGGGCTCACCCGGGTTGCGACCTCGCCCCTACGACCGAAGGTCGACTGGGAGCTCTTTAAGAGACGACTAGTCGACCTTCCCGTGATTCAGGACCCCAACACCCCTGATGGGGTCGACGATGCGGCAACCCGCCTTGTTGACTCCATCAGGGGAGCGATCGACCAGGCGACGACTCTTGTGCCCAGCGGCGGGCCCAGAGGTATACTCCCGGCCCATCTGAAGGCGATTATTCGCCGGAAGAGGGGCTTGAGGAGGCTCTGGGCGACAACTCGTTGTCCCAGGATAAAGCGCGAGCTTAATGAGCTGGAAGCGGAGCTGGCGACAAAGATTAGCACCTTTCGGGGCTATGCCTGGCAGGAGAGGATCGAAGAGGCCCGCGAGGACCCCTCCTCAGTATCCCTCCACCGGCTTTGTCGCCAGCTCTCAAATCGGCCTGCCCCGACTTGTCCACTCGTGGACGAGAGGGGCAACCGATGCTTCTCGGCTCAGGCCCGCGCCGATATCCTGGCCGAAATGCTGGAGCGGCAGTTCGCTCCTAATGACTCTGCACCCTCAGAGGCCGCATTCCACCAATCGGTGGAAGAGAGCGTAGCAAGCCTACTCTCCTCCCCGGTGCCACCGTTGGGAGATGGTGATCTCATCACTCCCAGCGAATTGCGCCTCATCATCAAGCGGATGAAGAGGCGCAAGGCGCCGGGCGAGGACGGTATTCCCTCCCTCGCTTTTTTCCACTTCCCTGAAACGGTCGTGTCATATATGACACGGCTGTTCAACTCCATCCTGTCCACAGGACACTTCCCGGGAATTTGGAAATTGGGCAAGGTTATCGCCTTGCCCAAACCCGGCAAGGACAGGAGAAATCCCTCCAGTTACCGTCCGATCACGCTGCTGTCGCACGTGGGCAAGTTGTTCGAGCGGCTGCTGCTGAGAAGGGTGTCGCCGCACATCCTTCTCAGACCCGAGCAATTCGGGTTTCGTAGCGGTCACTCGACAACGCTGCAATTGGTCCGCGTTATGCATCACTTGGCGGATCGGTCCAACGCGCGCCAGTACACGGCCGCAGTCTTTCTCGACATCGAGAAGGCCTTCGACCGTGTCTGGCATGCGGGACTGATCCACAAGCTGTTGCAGAACACGGACCTCCAGCACGCCTACGTGCGACTGCTGGGGTCGTACCTGGAGGGAAGATCCTTCCTTGTCGCGGTCGAGGGCGCCAAGTCGTCGGTGCGCCCAGTCACGGCCGGAGTTCCGCAGGGGAGCGTCCTGGCACCATTCCTCTACGCTCTCTATACCAACGATATTCCCACGCTCGAGGGCAACCTCCAAGCGTGGGAAGCCGACGTGAAGTTGGCGCTGTTTGCCGACGACAGCGCCTACTTCGCGTCATCCAACTTCCCCTCTGCGGCCATTTCGAGGATGCAGAGGTTATTGGACTTACTGCCCCAGTGGCTGGACCGATGGAGGGTCGCGGTCAACGTGGGGAAGACTGCGGCTATTCTCTTCGGTCCAGTCCGCACAACAGTCGTCCCGGGACAGCTCAGTCTCCGTGGCGCTAATGTCGAGTTTAGATCCAGCGTCCGGTACTTGGGGGTCGATATCGACCGGAGTTTGAGGATGACCGCCCACGCCATGTCGGCGTTGGCGGCAGCTCGCTATGCGAGATTCCTCCTCCGGCCGGTGTTGGCCTCCAGGTTGCCGGTCAGGACTAAGCTCGGCATTTATAAGACGTATGTCCGTTCCCGTATCACGTACGCAGCTGCGGCCTGGTATCACCTCATCCCGCAGGGTATGCGGGAGAGGTTACAGGTCCAGCAAAATCTGGCTCTTCGCACGATAGTCGGAGCAGGGCGTTACGTCAGAAATGACGTAATCGCCCGGGATCTAGATGTGGAGTCGCTCGAGGAGTTCATTCGGAGGCTAGCTCGTAATATGTACGAGCGGGCTGACGGTGGACCCCACGAGCATCTCCACAATATAGCTCCCTTGCACGCCAGACCACCTGATGGTAGGGCGCTACCAAGGGAGCTACTGGAACCCCCGGCTATGGAAGCAGAGGACAGCAGCCGGCGCCGGGGTGTCACCGCCGCGGGCATCGAGCCGTCACCAGACTGCCCATCGTATTATATATAA
Protein
MSGGNPPPTISTPGPSHKGRQAMPEVQLPTPTPAIRMAPMGPGAGSSAGPSAAARGPLRIVPVESNFPTSADPSGPSRPRKKARSESDRGSSGDQDKRPRIGPSSRSEGEESVTTSTDHSSTESITPSSSRSTSPSGSPIPVQPVPKPRAPARTGIAPRQLRTPPHSPSPTLSPIPVDSTRGAPALSGTAGNLDSTRYMDLESTRPHHAPKTNPTPSTSYAAMAARPGIPSIQRTSQSSHVPPPRPKGRAQEELRRHPPIMVEALPNWSRHMAAIRERLGRAPSARPFGAGFRFLPTSVEEYRAVQAYLSEASARDSTIKWYCYALTGEIPTKVAVRGLPADTDAAEITDALKELGFPARHARCIRSQRGRPGCVFHVALDHLSKDDLARLYAVNELLYLPGVTVEGWRPTRGPAQCHRCQAFGHASNNCHRAVRCVRCAGEHVVADCPRPRDGPFSCANCGKDHAAVDRRCPVYRKKARMMGVTVPPPAPMVPRPGNTALPSVAPIPKGKGKGKGKSSQPQPPPLSSPIPPAVSVEANPSAATLMAEANAPRRGIPVPTPRGSHAVRPPHLKSSVPARAGTQAPQISGPKQKKNRLKKLKKKQKKRAQRDAAVSAPAAPAPAVSTMEVDVNPPIDPTSQPISQSGTTPLPQAQPAISGISQPPLPPRPQRERRSDRQASQPAGFAAWLLALWEKLSEVISGVIREIASGASPFGAILQELRIIYWNPDGIKSRKNELLVLAREYNPEVLLLGETKLRPQDAFRIPNYFMYRRDELTPAGRPFRGTAALVRRDVVHDQLDLLSFTSTRSVGVRVHTSGGDMRIYAAYRPPGPEFHPDDIRRALNHDSRPALLVGDLNAKHVAWGSRLNSAVGRRLLEDADRGDYSVVGPDEPTHIPIAARYQPDVLDVCVHKGLRCPVTIEALYDLGTPHLPILVTLGMGLTRVATSPLRPKVDWELFKRRLVDLPVIQDPNTPDGVDDAATRLVDSIRGAIDQATTLVPSGGPRGILPAHLKAIIRRKRGLRRLWATTRCPRIKRELNELEAELATKISTFRGYAWQERIEEAREDPSSVSLHRLCRQLSNRPAPTCPLVDERGNRCFSAQARADILAEMLERQFAPNDSAPSEAAFHQSVEESVASLLSSPVPPLGDGDLITPSELRLIIKRMKRRKAPGEDGIPSLAFFHFPETVVSYMTRLFNSILSTGHFPGIWKLGKVIALPKPGKDRRNPSSYRPITLLSHVGKLFERLLLRRVSPHILLRPEQFGFRSGHSTTLQLVRVMHHLADRSNARQYTAAVFLDIEKAFDRVWHAGLIHKLLQNTDLQHAYVRLLGSYLEGRSFLVAVEGAKSSVRPVTAGVPQGSVLAPFLYALYTNDIPTLEGNLQAWEADVKLALFADDSAYFASSNFPSAAISRMQRLLDLLPQWLDRWRVAVNVGKTAAILFGPVRTTVVPGQLSLRGANVEFRSSVRYLGVDIDRSLRMTAHAMSALAAARYARFLLRPVLASRLPVRTKLGIYKTYVRSRITYAAAAWYHLIPQGMRERLQVQQNLALRTIVGAGRYVRNDVIARDLDVESLEEFIRRLARNMYERADGGPHEHLHNIAPLHARPPDGRALPRELLEPPAMEAEDSSRRRGVTAAGIEPSPDCPSYYI
Summary
Uniprot
ProteinModelPortal
PDB
6AR3
E-value=0.000348209,
Score=110
Ontologies
GO
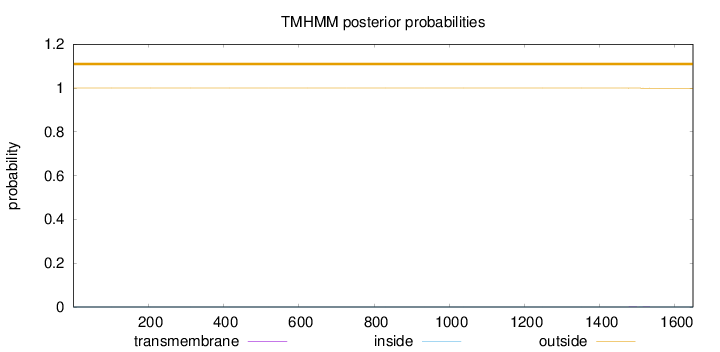
Topology
Length:
1648
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.01438
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00000
outside
1 - 1648
Population Genetic Test Statistics
Pi
423.098917
Theta
197.899427
Tajima's D
3.469703
CLR
0.005206
CSRT
0.993750312484376
Interpretation
Uncertain
