Gene
KWMTBOMO11011
Annotation
S08405_hypothetical_protein_2_-_silkworm_transposon_mag
Location in the cell
Nuclear Reliability : 3.014
Sequence
CDS
ATGTCGGTCGGGCAGTTGAAAGAATTCGCGGTAAACAGTGGAAATTGGTCCTCATATGTTGAGAGATTAGAAATGTACTTCTTGGTGAATAAAGTGACTGACGATTTAAAATTACCCACATTAATTTCCGTTATGGGTGAGGAAGCGTACGATTTATTATCGACATTAGCCAGCCCTTCGAAGCCGTCACAGTTAACTTATGCTAATGCCGTGGCGATGTTGGCAGCTCACCTGCAACCGAAGCCCTCAATCTTGGCGGAAAGATACAAGTTTCGACAACGTCGGCAGCTGAATGAGTCAATAGCTGACTACCTCACAGAATTAAAAAAATTATCAAAAAATTGTGAATTCGGCTCGTCGCTGGATGAAAATCTGCGTGATCAAATGGTTTGTGGATTAAAGAGCGAAATCATACGGCAAAGGTTATTTGCCGAGGAGAAATTAGAATATAAGCGAGCAGTTACGTTAGCTTTGTCTTTAGAAGCTGCGGAGAGGGATGCGATTGCAGTGGAACGTACGCCAATTGAGGAGGTTAACAAAATTAACTTCAATGAATGTTCAAGATGTGGAGACAGGAGACACCAAGCAAAGGATTGCATATACAAAGACTACGTGTGCAGTTCATGTCATGAAACCGGCCATCTACGAAGAATGTGCCCCAAAAAAGGGCTTAAGAACCAGGCGGAGGCAGCCGGGGGTTCACCATGCACCGGGCGCCGGGGGAACCGGGGTGCAGGCGGCAACAGGCGATCGTGGCGCGGGCAGCGCGGTGCGGGACGAAGAGGCCGAGAGCGGGCTCCTTTGCACTTAGTCTTATTATACGATCAAAACAACGATGACACATACAACAACTTCAATAATGAACAGGACGGGTGTGGAGAAGAAAATGAGCCTATGTACCAAATGACATTGAGTAATTATAAACCGTCAGTGTGTGCCCAAAGTGCGAGTGTTCTATCTAGCGGTGTTGTTTCGGCGCGGAGACGTTCCGAGCAACGTAACGCAGGACCCGGGACCAGCACCCCCGGCCCGTCCCGCAAGGGACGTCAAGTTATGTCGAGTCTAAGATTCAGACCAGCACCAGCAACCCGTACAGTCTCGATGGGACTCGGGACAGACAGCCGGCCCGGGCCTCCGGTCGCGGCCCAGAGGACTCCGAGGATCGAACCGGAGGAAGATGTCCTTCCCCCGTTGACCGATCCCTCTGGGCCCCCTCGGCCGCGGAAGAAGGCCAGGTCCGAGTCTGACCGAGGCTCATCGAGCGAAAAGGACAAGCGTCCTAGAATAGGCCCCTCATCTAGATCGGAAGGAGAGGAAAGTGCGACCACATCCTCTGCACACTCCTCAACCGAATCGGTCACTCCTTCCTCAACTAGGTCTTCGTCCCCCTCTGGGAGTCCAATCCCAGCCCAACCAATTCCGAAGCCTAGGGCTCCCGCCAGGACAGGGATAGCCCCAAGGCAAGTAAGATCCCCTCCTCGCTCTCCTTCCCCAACGCTGTCTCCAATCCCGGTAGACTCAACTCGAGGTGCCCCCGCCCTAAGCGGCACGGCGGGCAACCTGGACTCGACCAGGTACATGGACCTCGAGTCTACCAGACCTCAACAAGTCACTAAGCCCAACCCCACTCCCTCCACCTCCTATGCTGCCATGGCAGCTAGGCCAGGTATCCCTACCGCCCAGAGGACTTCCCAATCCTCACGAGTCCCTCCCCCGAGGCCGAAGGGTCGCGCCCAGGAGGAACTGCGCCGACACCCGCCAATTATGGTGGAGGCCCTTCCAAATTGGTCCCGCCACATGGCGGCCATAAGGGAGCGCCTAGGCCGCGCCCCCTCGGCGCGACCCTTCGGCGCCGGCTTTAGATTTCTGCCGACGTCGGCTGAGGAGTATAGGGCGGTCCAGGCCTACCTGTCGGAGGCCTCTGCCAGGGACGGTACCATTAAATGGTACTGTTACGCCCTGGCGGAGGAGATGCCTTCGAAGGTGGCAGTCCGGGGCCTCCCTGCCGACACCGACGAGGCAGAAATAGTCAATGCCCTGAAGGAGCTGGGATTCCCGGCTCGATACGCCAGGTGCATTAGGTCCCGGAGAGGGCGTCCGGGCTGCGTTTTTCACGTAGCCCTGGACCACCTCTCGAAGGACGACCTCGCCCGCTTGTACGCAGTCAACGAACTGCTGTACCTGCCGGGGGTGACGGTCGAAGGATGGCGTCCAATCCGAGGGCCTGCGCAGTGTCATCGCTGCCAGGCCTTCGGACACGCCTCCTACAACTGTCATCGCGCGGTCCGTTGCGTAAGGTGTGCCGGGGAGCACATCGTAGCGGACTGCCCGAGGCCGAGGGACGGCCCGTTCTCCTGTGCCAACTGCGGGAAGGACCACGCCGCCGTCGACAGACGGTGTGCGGTCTTCCGCAAACGGGCCAGGATGATGGGAGTAACCGTCCCCCCTCCTGCACCACTGGCGACTCGAGCCGGGAGTGCAGCTCTTCCGGCTTCAATACCTGTAGCAAAGGGGAAGGGGAAGGGGAAAGGGAAAACTTCCCAGCCCCCTCCCCCATCCCACTCCGCTCCGTCTGCTGTGGTGGTGGAGGCACTGCCATCGGCGCCTACGCTGATGGCACAGGCCAACCCACCACGGCAGATAAATAAACCCAAACCCACTCCTGCTCCCCGTGGTCGTACATCTGCTGGTATATCAGTGCCTAAACCACTCCCGACTAGCGGCCCTACGTCCACTAAAAGGGAGAAGAACAAGAGGAAAAAGGCCAAAAGGAAAACAAGAAAAAGGGAAGAAAGTGAGAGACTAAGGGGTACATCTGAGCCCACAGTGCCAGAACCCCAACAAACCAACATAGAAACTATGGAGGTCTCCGAGGCCCCCCTTACTGCCCAACAACCGACATCAAGCCAACCACTGCCTACAGCCCATCCGGCCGAAGGCAAGCACGACTTGAACAACCAGCCCCCCCTCCCCCCCCGCCCTCAGCGCGAGCGCCGCAGCGGTCGACAGGCCTCCCAGCCTGCCGGCTTTGCTGCATGGCTGCTCGCACTGTGGGAGAAATTGTCCGAGGAGCTGCGCATCATTTATTGGAACCCCGACGGGATAAAGTCCCGAAAGAACGACCTGCTTGTTCTCGCCCGGGAGTATAACCCAGAGGTTGTGCTCCTGGGCGAGACCAAGCTACGTCCTCAGGATGCGTTCAGGATTCCAAACTACTTCATGTACCGACGTGACGAGCTTACCCCTGCCGGGCGGCCGTTCAGGGGCACTGCGGCCCTCGTCAGGCGGGACGTGGTGCATGATCAGTTGGAGTTGCTGTCCTTCACATCGACAAGGTCAGTCGGTGTGAGGGTACACACCTCGGGGGGAGATATGCGGATTTATGCCGCGTATAGACCCCCGGGGCCTGAATTTCACCCTGAGGACATAAGACGGGCCCTGAATCACGACAGCCGCCCAGCTCTGCTGGTCGGGGACCTCAACGCGAAGCACGTCGCGTGGGGCTCCCGACTTAACTCAGCAGTGGGCAGGCGGCTGTTAGAAGATGCCGATAGGGGCGACTACTCCGTGGTCGGCCCCGACGAACCCACACACATCCCGACCGCCGCGCGCTATCAGCCCGATGTGCTGGACGTGTGTGTGCACAAGGGGCTACGGTGCCCCGTAACGATCGAGGCACTGTACGACCTGGGTACCCCACATCTCCCTATCCTGGTGACACTGGGAATGGGGCTCACCCGGGTTGCGACCTCGCCCCTACGACCGAAGGTCGACTGGGAGCTCTTTAAGAGACGACTAGTCGACCTTCCCGTGATTCAGGACCCCAACACCCCTGATGGGGTCGACGATGCGGCAACCCGCCTTGTTGACTCCATCAGGGGAGCGATCGACCAGGCGACGACTCTTGTGCCCAGCGGCGGGCCCAGAGGTATACTCCCGGCCCATCTGAAGGCGATTATTCGCCGGAAGAGGGGCTTGAGGAGGCTCTGGGCGACAACTCGTTGTCCCAGGATAAAGCGCGAGCTTAATGAACTGGAAGCGGAGCTGGCGACAAAGATTAGCACCTTCCGGGGCTATGCCTGGCAGGAGAGGATCGAGGAGGCCCGCGAGGACCCCTCCTCAGTATCCCTTCACCGGCTTTGTCGCCAGCTCTCAAATCGGCCTGCCCCGACTTGTCCACTCGTGGACGAGAGGGGCAACCGATGCTTCTCGGCTCAGGCCCGCGCCGATGTCCTGGCCGAAATGCTGGAGCGGCAGTTCGCTCCTAATGACTCTGCACCCTCAGAGGCCGCATTCCACCAATCGGTGGAAGAGAGCGTAGCAAGCCTACTCTCCTCCCCGGTGCCACCGTTGGGAGATGGTGATCTCATCACTCCCAGCGAATTGCGCCTCATCATCAAGCGGATGAAGAGGCGCAAGGCGCCGGGCGAGGACGGTATTCCCTCCCTCGCTTTTTTCCACTTCCCTGAAACGGTCGTGTCATATATGACACGGCTGTTCAACTCCATTCTGTCCACAGGACACTTCCCGGGAATTTGGAAATTGGGCAAGGTTATCGCCTTGCCCAAAACCGGCAAGGACAGGAGAAATCCCTCCAGTTACCGTCCGATCACGCTGCTGTCGCACGTGGGCAAGTTGTTCGAGCGGCTGCTGCTGAGAAGGATGTCGCCGCACATCCTTCTCAGACCCGAGCAATTCGGGTTTCGTAGCGGTCACTCGACAACGCTGCAATTGGTCCGCGTCATGCATCACTTGGCGGATCGGACCAACGCGCGCCAGTACACGGCCGCAGTCTTTCTCGACATCGAGAAGGCCTTCGACCGTGTCTGGCATGCGGGACTGATCCACAAGCTGTTGCAGAACACGGACCTCCAGCACGCCTACGTGCGACTGCTGGGGTCGTACCTGGAGGGAAGATCCTTCCTTGTCGCGGTCGAGGGCGCAAAGTCGTCGGTGCGCCCAGTCACGGCCGGAGTTCCGCAGGGGAGCGTCCTGGCACCATTCCTCTACGCTCTCTACACCAACGACATTCCCACGCTCGAGGGCAACCTCGAAGCGTGGGAAGCCGACGTGAAGTTGGCGCTGTTTGCCGACGACAGCGCCTACTTCGCGTCATCCAACTTCCCCTCTGCGGCCATTTCGAGGATGCAGAGGTTATTGGACTTACTGCCCCAGTGGCTGGACCGATGGAGGGTCGCGGTCAACGTGGGGAAGACCGCGGCTATTCTCTTCGGTCCGGTCCGCACAAGAGTCGTCCCGGGACAGCTCAGTCTCCGTGGCGCTAATGTCGAGTTTAGATCCAGCGTCCGGTACTTGGGGGTCGATATCGACCGGAGTTTGAGGATGACCGCCCACGCCAAATTGGCGTTGGCGGCCGCTCGCTACGCGAGATTCCTCCTCCGGCCTGTGTTGGCCTCCAGGTTGCCGGTCAGGACTAAGCTCGGCATTTATAAGACGTATGTCCGTTCCCGTATCACGTACGCAGCTGCGGCCTGGTATCACCTCATCCCGCAGGCCATGCGGGTGAAGTTACAGGCCCAGCAGAATCTGGCTCTTCGCACGATAGTCGGAGCAGGGCGTTACGTCAGTAATGCCGTAATCGCCCGGGATCTGGATGTGGAGTCGCTCGAGGAGTTCATCCGGAGGCTAGCTCGTAATCTTTACGAGCGGGCTGACGGTGGACCCCACGAGCATCTCCACAATTTAGCTCCCTTGCACGCTAGACCACCTGATGGTCTGGCGCTACCAAGGGAGCTACTGGAACCCCCGGCTATGTGCGCCGAGACGCGCATAACGAACAGCCCCCCCCCTAGTATAACATCTTGCATCCACATCACCCCTGCCCTGTGTGGCAGGGAGCTTCGTCCCGGGCAGTGGGGATTGCCCCGAGGCCCGTTCCGTACCCCCGAAAGGGGAAATCAGGACCTAGACAGTCATTTAAAGTCTATAAAAGAAGTATTAGATATATTAGAAAGGTATGGCTTAAAAATTAAAAGGAGTAAGTGCGAGTTCATGGTAACAGAAGTGAGGTATTTAGGGTTCATAATAGATCAAAATGGGGTTCGTGTAGACCCAGAGAAAGTCAAATCAATAGCAACAATGCCACACCCAAATAACGTGACAGAATTAAAATCTTTCATCGGTATGGTAAACTTCTATTCGAAGTTCATACAAGATTTGAGTGCACATTTATCACCTTTATATGCCCTTTTAAAAAAAGGTAAGCACTGGATGTGGGGAAATGAACAGAATGCTGCTTTCCTGAATGTTAAAAAGTTTTTGTGTAGTACAAAAGCACTTGCACATTTTGATATGTCTTTGGAGTCGGTGTTGACTGTGGATGCGAGCGCGCGTGGTCTGGGTGCCGTGTTGGCGCAGCGCGGGCCAGGATGTCAGGAGCGCGTCGTTGCATACGCTTCACGCGCACTCACCACTCATGAATTACATTACAGTCAGATTCATAAGGAAGCATTGGCGATTGTTTTCGCGGTGGAAAAATTCCATCAATACTTATATGGGAGAAAGTTCATACTACGGACCGACCACAAACCTCTGGTGAGCATTTTCGGGCCTAACATAGGTATCCCGAGCGCGGCAGCTAGCCCCTTGCAGCGCTGGGCTATCAAACTATCAGCATATGACTTTGAAATCGAGTACGTTAGGACAGATAAAAATGTAGCCGATGCACTTTCACGGTTAATCGAGTCTCAAAAAAATGACGTAGCTTCCGAGGAAACAGACTTACCCGAGCAAACCTACTTACACTTCTCAACAGAAGCTCTGTTAATAGATTATAATGTTCTTAAAAAACAAACTAGTAGTGATCCAATCTTAAGTCGCGTGTTAAGTTATATAAGGGACGGATGGCCCTTAGACATAGAAATTAATGAATTAAAACCATATTATAATAGGAAAAACGAACTTTATATTGAATTAGGATGTATAATGTGGGGTCATCGTGTGGTTATACCCTCTTCATGCAGAAACAAAATAATAACGGAGCTTCATGATCCGCATTTGGGCATAGTGAAAACAAAATCGCTAGCACGTAGTTACGTTTGGTGGCCGGGAATCGACGAAGCGCTCGAGACGGAATGTCGCGCTTGCACCGTGTGTGCTGCCGTCGCAGACGCACCTTCTACACACGCGCCCCGCTCGTGGCCCTGGCCCTCACGCCCCTGGTCCAGGTTACACTTAGACTTCTTAGGCCCCATAGGTGGAGTCACTTATCTAGTTGTAGTGGATTCATGCTCCAAATGGATAGAGGCAATTAAAATGCAGAGGACAACGGCACAAGCGGTTATATCGGTACTGCGGGACTTGTGGTCAAAATTCGGCCTGCCAAAGCAAACGGTCAGTGACAATGGACCGCCTTTCTCGAGCTCTGATTTTCAGAAGTTTCTGATTCATAATGGCATAAAACATATTTATTCAGCTCCCTATCATCCCGCCTCTAATTGGGCCGCTGAAAATGCAGTTAAAATTTGTAAACGTGCGATTAAAAAGGCATTAAAACAGAATTTAAACGTAGATACAGCTCTGTGTAGATTTTTATTAGCCTACAGAAATACAGAACATGCAACTACCGGCGATAGTCCAGCCAATATATTACAGGGTCGAAGTCTCCGTATGAGATTAGATAATTTAAAACCAGAAAGGCAATCTCGAGTTATCGCGCAACAAGAGCGGAGCGAGCAAAACGCAGGGGGTGTGCAGCGACAACTCGAGCCGGGCACTAAGGTGTGGTATCGGGATTATCGAGGTCTGGATAAATGGGTACCTGGGACGATCCTCAAGCAATTAGGTAGTCGTGATTACTGTGTACGATCTAGTTTTGGAACCGAGAATCATAGGCACGTCGATCAGCTAAAATTAAGGGTTACAAAAAATATAGATAAAGTTGATACCTTTGCGTCGATTCGTAAAAATATAAGTCCCGAACTGATCGCGCAAAATTTAGACTTAAGAACACAATCACGTAAGTCGCTATCATTTCCCATGACAAGTGGCGAGGAACCAGTGGCGGTGGTCAACGATTCGGGGAAGAGTAGTTCACCACCAAAAAATAGCACACCGGCACAGGATGCTGTATCGCCTATTCGTGGCAGCCCTATGAGACCCGCTGTGCCGATAGACAAGGCAGCATGTAGTACTGGTGGTAAGAGTATCAATGAAAATGTGACACCCAAACGTGAACGTCCTGTAAGAATACGCAAGCCACCAGTTAGATATGGATTCGAGGAAATAGATTAA
Protein
MSVGQLKEFAVNSGNWSSYVERLEMYFLVNKVTDDLKLPTLISVMGEEAYDLLSTLASPSKPSQLTYANAVAMLAAHLQPKPSILAERYKFRQRRQLNESIADYLTELKKLSKNCEFGSSLDENLRDQMVCGLKSEIIRQRLFAEEKLEYKRAVTLALSLEAAERDAIAVERTPIEEVNKINFNECSRCGDRRHQAKDCIYKDYVCSSCHETGHLRRMCPKKGLKNQAEAAGGSPCTGRRGNRGAGGNRRSWRGQRGAGRRGRERAPLHLVLLYDQNNDDTYNNFNNEQDGCGEENEPMYQMTLSNYKPSVCAQSASVLSSGVVSARRRSEQRNAGPGTSTPGPSRKGRQVMSSLRFRPAPATRTVSMGLGTDSRPGPPVAAQRTPRIEPEEDVLPPLTDPSGPPRPRKKARSESDRGSSSEKDKRPRIGPSSRSEGEESATTSSAHSSTESVTPSSTRSSSPSGSPIPAQPIPKPRAPARTGIAPRQVRSPPRSPSPTLSPIPVDSTRGAPALSGTAGNLDSTRYMDLESTRPQQVTKPNPTPSTSYAAMAARPGIPTAQRTSQSSRVPPPRPKGRAQEELRRHPPIMVEALPNWSRHMAAIRERLGRAPSARPFGAGFRFLPTSAEEYRAVQAYLSEASARDGTIKWYCYALAEEMPSKVAVRGLPADTDEAEIVNALKELGFPARYARCIRSRRGRPGCVFHVALDHLSKDDLARLYAVNELLYLPGVTVEGWRPIRGPAQCHRCQAFGHASYNCHRAVRCVRCAGEHIVADCPRPRDGPFSCANCGKDHAAVDRRCAVFRKRARMMGVTVPPPAPLATRAGSAALPASIPVAKGKGKGKGKTSQPPPPSHSAPSAVVVEALPSAPTLMAQANPPRQINKPKPTPAPRGRTSAGISVPKPLPTSGPTSTKREKNKRKKAKRKTRKREESERLRGTSEPTVPEPQQTNIETMEVSEAPLTAQQPTSSQPLPTAHPAEGKHDLNNQPPLPPRPQRERRSGRQASQPAGFAAWLLALWEKLSEELRIIYWNPDGIKSRKNDLLVLAREYNPEVVLLGETKLRPQDAFRIPNYFMYRRDELTPAGRPFRGTAALVRRDVVHDQLELLSFTSTRSVGVRVHTSGGDMRIYAAYRPPGPEFHPEDIRRALNHDSRPALLVGDLNAKHVAWGSRLNSAVGRRLLEDADRGDYSVVGPDEPTHIPTAARYQPDVLDVCVHKGLRCPVTIEALYDLGTPHLPILVTLGMGLTRVATSPLRPKVDWELFKRRLVDLPVIQDPNTPDGVDDAATRLVDSIRGAIDQATTLVPSGGPRGILPAHLKAIIRRKRGLRRLWATTRCPRIKRELNELEAELATKISTFRGYAWQERIEEAREDPSSVSLHRLCRQLSNRPAPTCPLVDERGNRCFSAQARADVLAEMLERQFAPNDSAPSEAAFHQSVEESVASLLSSPVPPLGDGDLITPSELRLIIKRMKRRKAPGEDGIPSLAFFHFPETVVSYMTRLFNSILSTGHFPGIWKLGKVIALPKTGKDRRNPSSYRPITLLSHVGKLFERLLLRRMSPHILLRPEQFGFRSGHSTTLQLVRVMHHLADRTNARQYTAAVFLDIEKAFDRVWHAGLIHKLLQNTDLQHAYVRLLGSYLEGRSFLVAVEGAKSSVRPVTAGVPQGSVLAPFLYALYTNDIPTLEGNLEAWEADVKLALFADDSAYFASSNFPSAAISRMQRLLDLLPQWLDRWRVAVNVGKTAAILFGPVRTRVVPGQLSLRGANVEFRSSVRYLGVDIDRSLRMTAHAKLALAAARYARFLLRPVLASRLPVRTKLGIYKTYVRSRITYAAAAWYHLIPQAMRVKLQAQQNLALRTIVGAGRYVSNAVIARDLDVESLEEFIRRLARNLYERADGGPHEHLHNLAPLHARPPDGLALPRELLEPPAMCAETRITNSPPPSITSCIHITPALCGRELRPGQWGLPRGPFRTPERGNQDLDSHLKSIKEVLDILERYGLKIKRSKCEFMVTEVRYLGFIIDQNGVRVDPEKVKSIATMPHPNNVTELKSFIGMVNFYSKFIQDLSAHLSPLYALLKKGKHWMWGNEQNAAFLNVKKFLCSTKALAHFDMSLESVLTVDASARGLGAVLAQRGPGCQERVVAYASRALTTHELHYSQIHKEALAIVFAVEKFHQYLYGRKFILRTDHKPLVSIFGPNIGIPSAAASPLQRWAIKLSAYDFEIEYVRTDKNVADALSRLIESQKNDVASEETDLPEQTYLHFSTEALLIDYNVLKKQTSSDPILSRVLSYIRDGWPLDIEINELKPYYNRKNELYIELGCIMWGHRVVIPSSCRNKIITELHDPHLGIVKTKSLARSYVWWPGIDEALETECRACTVCAAVADAPSTHAPRSWPWPSRPWSRLHLDFLGPIGGVTYLVVVDSCSKWIEAIKMQRTTAQAVISVLRDLWSKFGLPKQTVSDNGPPFSSSDFQKFLIHNGIKHIYSAPYHPASNWAAENAVKICKRAIKKALKQNLNVDTALCRFLLAYRNTEHATTGDSPANILQGRSLRMRLDNLKPERQSRVIAQQERSEQNAGGVQRQLEPGTKVWYRDYRGLDKWVPGTILKQLGSRDYCVRSSFGTENHRHVDQLKLRVTKNIDKVDTFASIRKNISPELIAQNLDLRTQSRKSLSFPMTSGEEPVAVVNDSGKSSSPPKNSTPAQDAVSPIRGSPMRPAVPIDKAACSTGGKSINENVTPKRERPVRIRKPPVRYGFEEID
Summary
Uniprot
ProteinModelPortal
PDB
4OL8
E-value=3.52084e-29,
Score=327
Ontologies
GO
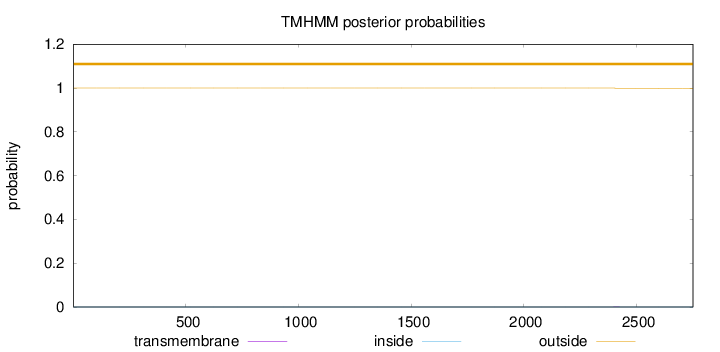
Topology
Length:
2750
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00994
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00003
outside
1 - 2750
Population Genetic Test Statistics
Pi
308.570345
Theta
204.490287
Tajima's D
2.30948
CLR
12.07395
CSRT
0.923553822308885
Interpretation
Uncertain
