Gene
KWMTBOMO07478
Pre Gene Modal
BGIBMGA005207
Annotation
reverse_transcriptase_[Bombyx_mori]
Location in the cell
Mitochondrial Reliability : 1.752 Nuclear Reliability : 1.4
Sequence
CDS
ATGGAGTCCACGATCGATCTGTTCGCGGAATTCCTCCGTCTGAGGTACCCGACATTATCGGCCGAATTTTTAGAATTTAAGGCCAATCACGCCGCGAACTCAGAAGCGGTCTCCGTCGCGCCCGCCGCTCCCGTGTCCCCAATACTCGCGAGCAAAGCTCCCGCGTCGATCGCTGCGGTCTCGGTTCCAGCCCTGCGCTCATCCGCAGCACACGTCGCGTCCACGCGTTCATCCGCGGCCTCCATCGCGCCCGCGCCGTCCTCTGCCCCCGAGCGATTGTCCGTGGCCTCCGTCGCGACCGTCAACCCCGCGCCCTCTAAAACGCCCGCCTGCGGGTCGCCCGCGCCCTCCTCTTCATCCGACTCGGAGTCGGACATGGAGGTCGATCTTTCCCCCGCCCCCTCGACTGATGGATTCATAGTAGTCCAAAAAGGTAAGAGGCGCGCTGCGGAAGCCCGAGCTCCCGCGGCCGCCAAAGTAAGCAGAGCCGCGAACGCGTCGCGCCTCCGTCCACCGACCCCCGTTGCTCCCCCAGCCCGTGCTACACCGTCGCCGCGTCCGGTAGTACAAAAGAAAATTCAAGCCCCTCCCCCGGTAATCCTTCAAGAGAAGGCAGCCTGGGAACGAGTTTCCCTGGCCCTTAAGGCCAAAAATATTAATTTCACGAATGCCCGTAACCTCGCGAACGGCATTCAAATTAAGGTTCAAACACCCGACGACCATAGGGCCCTCTTTTCTTACCTCCGTAAGGAGCGTATAAGTTTCCATACGTATACGCTCCAGGAGGAGCGCGAACTTCGTGCCGTCATACGTGGCATCCCTAAAGAGTTGGATGCCGAACTCGTCAAGGCCGACCTTCTGGAACAAGGCCTACCAGTAAATTCAGTGCACCGCATGCACACCGGCCGCGGAAGGGAGCCATATAATATGGTTCTAGTCGCCCTCCAGCCTACCCCCGAGGGTAAGCAAATTTTTAACATACGGACCGTCTGTAGGCTCTCCGGTATCGCCGTCGAAGCCCCCCATAAAAAAGGCACTCCTAGCCAGTGCCATAACTGTCAACTGTACGGGCATTCTTCCCGTAACTGTCACGCGCGCCCCCGATGCGTCAAGTGTCTAGGCGATCACGCTACGGCCCTTTGCACTCGCGATCAAAAAACCGCGACGGAACCGCCTAGCTGCGTCCTGTGTCGAACACAGGGTCACCCCGCAAATTACCGCGGATGCCCCCGAGCCCCGAAAATAAATCGCCGCGTCGCCCGCCAAAACCGCCTCCGAGCTTCCCACCCAGACATCAAAGCCTCGGCACCCTCTGTGTCGCAGGCTAAGCCAGCGTTCGTTCCGGCGCCGGTGCCCAGTGGCTCGGCCTGGGCGAAACCGCTGCCGTACACGAACACGGCTACAACTCCCTCCTCCGCGATTCGTCCCGCCCCCGCGATACGCCCCTCCCCCGCGAATTGCCCTCCGACAGCGTCCGACAATCTTGCTCTAGCGATCGACTTCTTTCAATCGATTAACTTTGAGCGCGTTAACGCTTTAGGTGACGCCATCCGCGCCGCCTCCACTGCACAGCACTTCATCGCCGTTGTGCAAGAATACGCCGACGTATACGCGTCGTTAAATACGAACGACAGGCTCACTGCTCGTGGTGGTGGTACCGTCATCTACTACAGAAGAGCCTTGCACTGCATTCCGCTCGATCCCCCCGCGCTCGTTAACATCGAAGCATCAGTATGCCGAATCTCACTGACGGGACACGCGCCGATCGTTATCGCGTCCGTTTATCTTCCACCGGATAAGATCGTTCTAAGCAGTGATATCGAGGCGCTGCTCAGCATGGGAAGCTCTGTCATTCTGGCGGGCGACCTAAATTGTAAACACATCAGGTGGAAGTCTCACACCACAACCCCTAATGGCAGGCGGCTCGACGAGCTAGTCGATGATCTCGCCTTCGATATCATCGCTCCGCTAACCCCGACTCACTACCCGCTAAATATCGCGCATCGCCCGGATATACTCGACATAGCGTTATTAAAAAACGTAGCTCTGCGCTTACACTCGATCGAAGTAGTTTCAGAGTTAGATTCAGACCACCGTCCCGTCGTTATGAAGCTCGGTCGCGCTCCCGATTCCGTTCCCGTCACGAGGACTATGGTGGATTGGCACACGCTGGGCATCAGCCTGGCTGAATCTGATCCACCATCGCTCCCGTTTAGCCCGGACTCTACCCCGTCTCTTCATGATACCGCTGAAGCCATAGACATCCTAACGTCACACATTACCTCGACATTAGATAGGTCATCGAAGCAAGTTGTAGCGGAGGACTTCCTTCACCGCTTCGAATTGCCCGACGATATTAGGGAACTCCTTAGAGCTAAGAACGCTTCGATCCGCGCCTACGATAGGTATCCTACCGTGGAAAATCGTATTCGAATGCGTGCCCTACAACGCGACGTAAAGTCTCGCATCGCCGAAGTCCGAGATGCCAGGTGGTCTGATTTCTTAGAAGGACTCGCGCCCTCTCAAAGGTCTTACTACCGCTTAGCTCGTACTCTCAAATCGGATACGGTTGTAACTATGCCCCCCCTCGTAGGCCCCTCAGGTCGACTCGCGGCGTTTGATGATGACGAAAAAGCAGAGCTGCTGGCCGATACATTGCAAACCCAGTGCACGCCCAGCATTCAATCCGCGGACCCTGTTCATGTAGAATTAGTAGACAGTGAGGTAGAACGCAGAGCCTCCTTGCCACCCTCGGATGCGTTACCACCCGTCACCCCAATGGAAGTTAAAGACCTGATCAAAGACCTACGTCCTCGCAAGGCTCCCGGTTCCGACGGTATATCTAACCGCGTTATTAAACTTCTACCCATCCAACTCATCGTGATGTTGGCATCTATTTTCAATGCCGCTATGGCGAACTGTATCTTTCCCGCGGTGTGGAAAGAAGCGGACGTTATCGGCATACACAAACCCGGTAAACCAAAAAATAATCCGACGAGTTACCGCCCGATTAGCCTCCTCATGTCTCTGGGCAAACTGTATGAGCGTCTGCTCTACAAACGCCTCAGAGACTTCGTCTCATCAAAGGGCATTCTCATCGATGAACAATTCGGATTCCGTGCAAATCACTCATGCGTACAACAGGTGCACCGCCTCACGGAGCACATTCTTGTAGGACTTAACCGACCAAAACCGATCTATACGGGAACCCTCTTCTTCGACGTCGCAAAAGCTTTCGACAAAGTCTGGCACAACGATTTGATTTTCAAACTTTTCAACATGGGCGTACCGGACAGTCTCGTGCTCATCATACGAGACTTCTTGTCTAACCGCTCTTTTCGATATCGAGTAGAGGGAACCCGCTCCTCCCCGCGACCACTCACGGCTGGAGTCCCGCAAGGCTCCGTTCTCTCTCCGCTCCTATTTAGTTTATTTATTAACGATATTCCCCGGTCGCCGCCGACCCAGCTAGCCTTATTCGCTGACGACACAACCGTTTACTACTCAAGTAGAAACAAGTCCCTAATCGCGAGTAAGCTCCAGAGTGCAGCGTTAACCCTCGGACAGTGGTTCCGAAAATGGCGCATAGACATCAACCCAGCGAAAAGCACAGCAGTGTTATTTCAAAGGGGAAACTCACCGCTTATTTCCTCCCGCATTAGGAGGAGAAATATCACACCCCCGATCACCCTCTTCGGCCAACCTATACCCTGGGCTAGGAAGGTCAAGTACCTGGGAGTCACCCTGGATGCATCCATGACATTCCGCCCGCATATAAAAACAGTCCGCTATCGTGCCGCATTTATTCTCGGCAGACTCTATCCCATGATCTGTAAGCGGAGTAAAATGTCCCTTCGGAACAAGGTGACACTTTACAAAACTTGCATAAGGCCCGTCATGACTTACGCGAGTGTGGTGATCGCTCACGCGGCCCGCACACACATAGACACCCTCCAATCCCTACAATCCCGCTTTTGCAGGTTAGCCGTCGGGGCTCCGTGGTTCGTGAGGAACGTCGACCTACACGACGACCTGGGCCTCGAATCGATCCGCAAACACATGAAATGGGCTAGTAATCTTCGTTCGACCACAGACAGCTACCTCCACAATCCAGGGTCAGAACCTTTGACGTTAGCGACGCTCGGTGACATCATCGAAGAGACAGTTCATAAATTTCCTGGTAGAGTGGCCGTGAAGTCAATGCACGAAGGCATCAGTCTTACCTATGAGGAGTTGTTAATACGGGCGGATTCTATGGCATATGGTCTTCGAAATCAAGGACTACAAAAAGGCGATCGAGTAGGAATCTGGTCACATAACAGCGTTTCTTATTTAGTTTCCTTAGTGGCAGCAGCCAGAGCTGGTTTGATTTCGGTTTTAATCAATCCAGCATATGAAAAGAAGGAACTAAGTTTTTGCATTAAGAAATCAGAAATGAAGTGTTTACTGATAGGCGATGCTCTACCGAAGAGGGAGTATTACAGAACTTTAGAGCAATTAATACCTGAATTAAAAGACGGAAAGCCGGGGTTATTAAAGTCTAGAGAATTTCCTTTTTTATCTTCAATTATTGCTGATGGTAGGAACAAATTGCCTGGTACTATCTCATACAAATCGTTGACCGAGGATTATAAGAACAGAAGCGAAGTGTCACAATACGTCAAGGAAACCAAACCAAGTGACGGTTCTATCATTCACTTCACTTCCGGTACCACAGGGGAACCGAAAGCCGCATTGGACTCGCACCTCGGCGTTGTAAACAACACTTACTTTACAGGCAAGAGAAATACTTTCCACGAAGGACATCATAACATTTGTGTTCAGGTTCCAATATTCCACGCTCTCGGATCCATCGTGACAGTACTGGGAGGCTTCCGTCACGGGGCCAGCCTGGTGCTAGCCGCACCTATTTACGACATCTCTGCAAATGTGAAAGCTTTGTTTGGTGAAAAGTGTACAGCAATAACAGGCACTCCCACCATGTTCGTAGACATCTTATCCCAGATCAGAGCCCAAGGTCAGGAGGTGCTTTCTGAACTCCGGGTGGCGGTCGCCGCCGGAGCGCCCTGCAGCCCCCAATTAATTAGAGATATACAAACACATCTCAATGCTGAATCAGTTAAAAGTCTGTACGGTCTAACTGAGACAACAGCTTGCATATTCCAGTCCAACCAAGGCGACAGTATAGACGTCGTAGCCGAGACAGTTGGTTATATTCAAGATCACGTTGAAGTCAAGGTGGTAAACGAACAAGGGGAGATCGTTCCGTTTGAAACACCGGGCGAGCTTGTTGTACGCGGCTACAACAACATGATCTGCTACTGGAACGAACCGGAGAAGACTAGGCAAACTCTGGACAAAGACGGCTGGCTGAAGACCGGGGACAAGTTCACGATAAGCAAAGACGGCTACGGCAGGATAGTTGGAAGGATTAAAGATATCATCGTTCGAGGAGGGGAGAACATCGCGCCGAAAGAAATAGAAGATTTGCTGAACACACATCCCGATGTTGAAGAAAGTCAGGTCGTCGGAGTGTCGGACAAAAGAGTTGGAGAAGAGCTCTGTGCTGTTGTGAGGCTGCGTGAAGGCGCTGCGTTGAGTCTCGACGACGTAACAAAGCATTTAACAGGAGAAATCGCACGCTTCAAATTCCCGAGGATCCTCAAAGTCACACAAGAGTTCCCGAAGACCGCTTCAGGGAAGATCCAAAAGTATAGACTGAGAGAAATGATCGAGAAAGGACTATTGTGA
Protein
MESTIDLFAEFLRLRYPTLSAEFLEFKANHAANSEAVSVAPAAPVSPILASKAPASIAAVSVPALRSSAAHVASTRSSAASIAPAPSSAPERLSVASVATVNPAPSKTPACGSPAPSSSSDSESDMEVDLSPAPSTDGFIVVQKGKRRAAEARAPAAAKVSRAANASRLRPPTPVAPPARATPSPRPVVQKKIQAPPPVILQEKAAWERVSLALKAKNINFTNARNLANGIQIKVQTPDDHRALFSYLRKERISFHTYTLQEERELRAVIRGIPKELDAELVKADLLEQGLPVNSVHRMHTGRGREPYNMVLVALQPTPEGKQIFNIRTVCRLSGIAVEAPHKKGTPSQCHNCQLYGHSSRNCHARPRCVKCLGDHATALCTRDQKTATEPPSCVLCRTQGHPANYRGCPRAPKINRRVARQNRLRASHPDIKASAPSVSQAKPAFVPAPVPSGSAWAKPLPYTNTATTPSSAIRPAPAIRPSPANCPPTASDNLALAIDFFQSINFERVNALGDAIRAASTAQHFIAVVQEYADVYASLNTNDRLTARGGGTVIYYRRALHCIPLDPPALVNIEASVCRISLTGHAPIVIASVYLPPDKIVLSSDIEALLSMGSSVILAGDLNCKHIRWKSHTTTPNGRRLDELVDDLAFDIIAPLTPTHYPLNIAHRPDILDIALLKNVALRLHSIEVVSELDSDHRPVVMKLGRAPDSVPVTRTMVDWHTLGISLAESDPPSLPFSPDSTPSLHDTAEAIDILTSHITSTLDRSSKQVVAEDFLHRFELPDDIRELLRAKNASIRAYDRYPTVENRIRMRALQRDVKSRIAEVRDARWSDFLEGLAPSQRSYYRLARTLKSDTVVTMPPLVGPSGRLAAFDDDEKAELLADTLQTQCTPSIQSADPVHVELVDSEVERRASLPPSDALPPVTPMEVKDLIKDLRPRKAPGSDGISNRVIKLLPIQLIVMLASIFNAAMANCIFPAVWKEADVIGIHKPGKPKNNPTSYRPISLLMSLGKLYERLLYKRLRDFVSSKGILIDEQFGFRANHSCVQQVHRLTEHILVGLNRPKPIYTGTLFFDVAKAFDKVWHNDLIFKLFNMGVPDSLVLIIRDFLSNRSFRYRVEGTRSSPRPLTAGVPQGSVLSPLLFSLFINDIPRSPPTQLALFADDTTVYYSSRNKSLIASKLQSAALTLGQWFRKWRIDINPAKSTAVLFQRGNSPLISSRIRRRNITPPITLFGQPIPWARKVKYLGVTLDASMTFRPHIKTVRYRAAFILGRLYPMICKRSKMSLRNKVTLYKTCIRPVMTYASVVIAHAARTHIDTLQSLQSRFCRLAVGAPWFVRNVDLHDDLGLESIRKHMKWASNLRSTTDSYLHNPGSEPLTLATLGDIIEETVHKFPGRVAVKSMHEGISLTYEELLIRADSMAYGLRNQGLQKGDRVGIWSHNSVSYLVSLVAAARAGLISVLINPAYEKKELSFCIKKSEMKCLLIGDALPKREYYRTLEQLIPELKDGKPGLLKSREFPFLSSIIADGRNKLPGTISYKSLTEDYKNRSEVSQYVKETKPSDGSIIHFTSGTTGEPKAALDSHLGVVNNTYFTGKRNTFHEGHHNICVQVPIFHALGSIVTVLGGFRHGASLVLAAPIYDISANVKALFGEKCTAITGTPTMFVDILSQIRAQGQEVLSELRVAVAAGAPCSPQLIRDIQTHLNAESVKSLYGLTETTACIFQSNQGDSIDVVAETVGYIQDHVEVKVVNEQGEIVPFETPGELVVRGYNNMICYWNEPEKTRQTLDKDGWLKTGDKFTISKDGYGRIVGRIKDIIVRGGENIAPKEIEDLLNTHPDVEESQVVGVSDKRVGEELCAVVRLREGAALSLDDVTKHLTGEIARFKFPRILKVTQEFPKTASGKIQKYRLREMIEKGLL
Summary
Uniprot
ProteinModelPortal
PDB
3CW8
E-value=5.64642e-46,
Score=471
Ontologies
GO
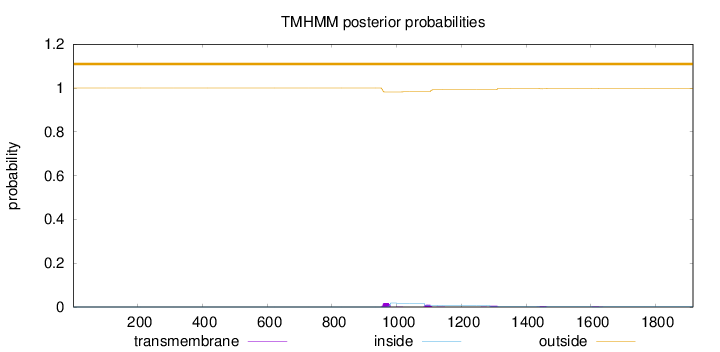
Topology
Length:
1916
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.871899999999997
Exp number, first 60 AAs:
0.00116
Total prob of N-in:
0.00006
outside
1 - 1916
Population Genetic Test Statistics
Pi
19.876068
Theta
20.836142
Tajima's D
-1.646046
CLR
11.373618
CSRT
0.0440977951102445
Interpretation
Uncertain
