Gene
KWMTBOMO16341
Annotation
PREDICTED:_LOW_QUALITY_PROTEIN:_uncharacterized_protein_LOC106708942_[Papilio_machaon]
Location in the cell
Mitochondrial Reliability : 1.135 Nuclear Reliability : 1.138
Sequence
CDS
ATGCTATTGTGGGTCTTCGCTGATAAAATAATAGGAGGGTACCTCCCGCTCAGCGGGAGGAGAATCCCTCCGTGTGGCCGACTCGTCGGACGCACGCTGCCCGCGTACTCTGGGGGGGGCAAAAACTGCCTAGACGTCAGGTCCGGGAAGGACGGAGTTCAAAAGAAGAAAATTATGTCCGAGAAGGACCCTGAAGTAAGCTCCTTAAGAGCCGATGTCGTGTCGGACAACGATATGGCCACAGTTGGTTCGGCCCAGTCGTCGACCCATTCGTCGCCGACACGACGACGACGGAAAAGGGTGCTCAATATAAGCTCGGACGGGCTGAGTAGCAGCTCCGGCTCGGAGGCTCAGGATCCGACACGTGTGAAGCCCAGAGCAGTCACGCCGTCAAAGCGTGGACGGGGACGCCCTGCGACCACAGGGCAGTACGTTGGCATGGCCGCTGCCAGGCAAGCGTACCTCAAGGCACAAAAAGAGGAGAAGGAGCTCACTGAGAGCGCGCGCACCACACGCCACAAGAGGAGAGCGGCTGAAGGGTCAGTCCCTAAGCCCGATGCCGAGCGTAGGCTCCATCAAAGTGCAGAGGTGGCCCTGATGGTCGCCGCCAAATCCAGCAGCCCGAAGGGCACGTACGTGCGTGCACTGAAGGAGTTGGCAGTCACTGTCAAGGAGGCCACGGAGGACCTTGTGGGCTACACCGCAGCCGAAGAGGCTAAGAGACTGCGAGCGGTCAACGTCAAGCAGGAGCAGGAGATCCTGCAACTGCGTAAGGAGCTCGATGAAGTTAGAAGGGAGTTGGCGAGGGTTTCGCAGGTGCTAGCGTTGCCCACATCGACTGCGACCCCGGCCCCGAACACCAAGGAGGAAGAGGAGGAGTTGCGCCTACAGCGCATTATGCGAGCTGTCGGCACTATGCTCGACGCTCGCTTTGAAGGGCTGGAGGCACGGCTTCTACCGGAGCCCCGAATGCGACCACCGCTAGCGGCGGACAAGCAGAGGAGCCGGGAAAAATCGTCTAATCCCCCTGTCGTCGTTGACGCTGCACCGGATGCGGCACCGTCATCAGTGCCACCGATGACATTGGCGAAAAAGAGGATGCGTGGCCCCAAGAGAAGTGTCACCGCGCAAGCGGCTTCATCCGAAACGCACACCTTCCTCCCGGCTCCAGCTTCCATGATCGAGAGCTGGTCAACGGTCACCCGTAGGGGTGCTCGACCGAGGGAGGAAGCAGTGAGGACGCTTCCAGCGGCAGCTATCGCTGAAGCGGAAAGGAAAGACCGGTCTTCTGTAAAGAGGAAAGAGAAGAAGCTGCGCCCTCCACGCACTCAGGCCGTTGTCCTCAAGCTGCAACCAGAGGCCGTGGAAAGAGGACTCACGTACCGCACTGTACTCGCCGAAGCGAGGGCCAAGGTAGATCCTGGGGCACTTGGAATACCCATCCAGCGCATCCGGTCTGCAGTGACTGGGTCTAAGGTGCTGGTAGTGGAAGGTGCAGACCAGAGCGCCAAGGCCGATCTCCTGGCCCAAAAGCTTCGTGAGGTTCTGCCCGCAGAAGGGGTCATAGTGACCAGGCCAGTAACGACCGCAGCCATCCGCATCAGCGGACTGGACGACTCCCTGATGCCGGAGGAACTTACCGCGGAGCTTGCCCGGATTGGCGAATGCGCTCCTGATGCGATGAAGATCGGAGACATCAAGTATGGCCCAGGCGGGATGGGTCAAGTATTGGTCCGGTTGCCCGTCGTTGCCACGATGAAGGTTCTCGCCGTTCCAAAACTGAGGGTTGGTTGGAGCGTGCTCCGCGCTTGTTTGTTAGAGGCTAAGAAGCTACAGTGCTTCCGATGCCATGAGCTAGGGCACGTGAGCGCCCGATGTCCTTCGTCGGTCGACCGCAGCCGGGATTGTTATCGGTGCGGCCAGACCGGCCACGTAGCGGCCGGCTGCTCTCTTGCACCACACTGCGCTGGGAATCTCAACCATTGCGCCAGAGCTCAGGACCTTTTGTTCCAGAGCATGGCGGAGGGGTTGACCCATCTTGCGGTGGTCGCCGAGCCGTATCGGGTCCCTTCGAGCCCCGATTGGGCGGCCGATTTGGAGGGCCGAGTGGCAATCATCCGGCGTTGTTGTGTGGGTGCTCCGCCTACGTTTGCCGTTGTTGAAAGAGGTCGCGGCTTCGTTGCCGTCCTCTGGGCCGAGATATTCGTGTTGGGAGTGTACTTTTCCCCAAACAGGACGCTCGCCGAGTTTGAGGTTTTCCTCAGCGAGCTCAGCCGCGTCGTTGGAAGGTCGCACTTCCGACGGATTCTCGTTCTGGGTGACCTAAATGCAAAGTCATTGTCTTGGGGTTCCTCTAGGACGTGCCCCAGAGGTAGAGCGGTGGAGGAGTGGCTGGTCGGAAGCGGTCTCCTCATCCTCAATCGCGGTACGGAACTCACATGCGTGCGACGTTTGGGCGGGTCCGTGGTGGACGTTACATTCGCCACGCCTGACGTCGCATATCGCGTACGCGGTTGGGCGGTGATGGTTGGCGAGGAGACCCTCTCCGACCACCGTTACATCCGATTCAGTGTCGCCGCGACCCCGGTGGGTTCTGTTCGGGGCTTTTCCTTGCCCATCAGTGGCAGCGCTAGGGGTCCTCGTTGGGCCCAGAAGCGCCTCAACATCGAGCGGTTGCGTGAGGCGGCCATAGTGCAGGCGTGGCGTCTTGACTCGCTTGGCGAGCCAGCAGACGTGTGCGAGGGGGTGGAGCGTCTGCGCGAGGCAATGTCACGGGTGTGTGACGCTGCTATGCCTCGCGTGAGAGCTCTCGCTCCTAAGCGCCAAGTTCATTGGTGGACCGAGGAGATCGCTAGCCAGCGCCGGCTATGCGATATTAGTCGTCGCACATACCAGCGATATCGACGACGAAGAACGCGCCGGGACCCCGACGAGGAGGACCGCCTGTACGAAGTGTACAGGACGGCGATAAGAACCCTGCGCTTGGCTATCGGGGAGGCGAAGGAGGCCGCCTGGAACGACCTACTGGCCTCGCTGGACCGTGACCCGTGGGGCGGCCCTACAGGCTGGCGCCGGGTAGTCGGGGGTCTGTTTCCCGATTTATCCGGGACGGCCTTCGTCCCCCCTGTGATGACAATGGCGCGGATTGCTGATAGCGAAGAGCTTGAGGACGTCTCCCAGGTGGAGTTCGATTTGGCTGTGCAGAGGATGCGGGCTAAGCGCACGGCACCCGGTCCCGATGGGATCTCGTCCCAAGCGTGGGCGCTCGCCTTGACAGGTGACGGCTTGGGGCCTGCCCTCCAAGGGCTATTCAGCAGGTGCCTCCGTGAGGGCAGGTTCCCAGAGCCATGGAAGACTGGTCGGCTTGTCCTTATTCCTAAGGAAGGCCGGCCACGTGACGAGCCAAGCGGGTACCGCCCAATCGTCGTGCTGGACGAGGCTGGTAAGCTCCTCGAGCGCATCGTCGCCAGTCGCCTCGTCCAGCACCTCGAAAGCGTTGGGCCTGACCTGGCTCCTAACCAATATGGTTTCCGGAGAGGTCGCTCCACCATGGACGCGGTCTTGCGCGTCCGCCACCTCTCCGATCGTGCGTGCTCCGAGGGGGGCGTGTTGTTGGCTGTGTCGATTGATATCGCCAACGCCTTCAACACGATCCCTTGGAGCACGATCGTGGAATCGCTCCGGTTTCACCGCGTCCCCCCTAGTCTCCGCACCCTGATAGAGGATTACCTCTCAGGGCGAAATGTGGTCTTCCCCGAGAGGAGAGGGTGGGGACGGAAAGCGGTGTCGTGCGGGGTCCCGCAGGGGTCGGTACTGGGACCACTCCTGTGGGACATCGGTTTCGACTGGGTCCTGCGCGGTGCTAGCCTGCGTGGCGTCGACGTAGTGTGCTATGCCGACGACACGCTGGTGACGGCCCGCGGAGCCGACTACAGAGCCGCAGCGATCCTTGCGACGGCGGCGGTCTCCACCGTCGTTAGTCGCATTCGGAGATTAGGTCTTGAGGTGGCCCTCCGCAAGTCCGAAGCGGTGTGCTTTCACCCAGTCCGGAGGGGACCTCCTCCGGGAGCGAATCTCATAGTCGGCGGAGTATCGATCGCTGTCCAGCCGAAGCTCAAATATTTGGGCCTTGTGCTGGACAGTCGATGGCGCTTCGACCACCACTTTGGTGAGTTAGTCCCGAAGCTGCTGGGGATGGCGGGCGCACTAGCCCGTCTTCTCCCCAACGTCGGTGGTTGCAGCGCCGGCGTCCGGCGTCTGTACCTGGGGGTCGTGCGCAGTATGGCTTTGTACGGCGCTCCCGTGTGGTCGCCCGCACTCTCTGCGCGCAATGCAGCTTTGCTGCTACGAGCGCAGCGGGTGCTCGCGGTGAGAGTCATCAGGGGGTACCGTACGATCTCCCGGGAGGTCGCCTGCGCCCTCGACGGTTCCCTTCCTTGGGATCTCGAGGCTGAGGTAGCAGCTGCGGTATACCGGCGTAGAACACAGTCCCTGAGTCGGGGACGGACGCCCGGCCCGTCGGCTGTCGGTCGGTGGAGGCGTGCTGCGCGTCATCTGGCGTACGCCAAGTGGAGGGAGCGGTTGCTGGAGGAGCTTGGCCAAACTTCAGTCACTCGCCGACGCACCCTCGAGGCCCTGGTGCCCGTGCTGGAGGCATGGTCAGATAGACGACACGGCGTGCTCTCCTTCCACTTAACGCAGGTCCTCTCGGGCATGGCTGCTTCGGGAGAGGAGATCAGCAGTTATACAGTCGGCATTCTCGTCACCCCAGGAATCAATTTAAGACAAGACCCTGAACGTATCAATCAATCAGGTGTAATGATAATATCAGTAGAGTTCCGCGGTTGA
Protein
MLLWVFADKIIGGYLPLSGRRIPPCGRLVGRTLPAYSGGGKNCLDVRSGKDGVQKKKIMSEKDPEVSSLRADVVSDNDMATVGSAQSSTHSSPTRRRRKRVLNISSDGLSSSSGSEAQDPTRVKPRAVTPSKRGRGRPATTGQYVGMAAARQAYLKAQKEEKELTESARTTRHKRRAAEGSVPKPDAERRLHQSAEVALMVAAKSSSPKGTYVRALKELAVTVKEATEDLVGYTAAEEAKRLRAVNVKQEQEILQLRKELDEVRRELARVSQVLALPTSTATPAPNTKEEEEELRLQRIMRAVGTMLDARFEGLEARLLPEPRMRPPLAADKQRSREKSSNPPVVVDAAPDAAPSSVPPMTLAKKRMRGPKRSVTAQAASSETHTFLPAPASMIESWSTVTRRGARPREEAVRTLPAAAIAEAERKDRSSVKRKEKKLRPPRTQAVVLKLQPEAVERGLTYRTVLAEARAKVDPGALGIPIQRIRSAVTGSKVLVVEGADQSAKADLLAQKLREVLPAEGVIVTRPVTTAAIRISGLDDSLMPEELTAELARIGECAPDAMKIGDIKYGPGGMGQVLVRLPVVATMKVLAVPKLRVGWSVLRACLLEAKKLQCFRCHELGHVSARCPSSVDRSRDCYRCGQTGHVAAGCSLAPHCAGNLNHCARAQDLLFQSMAEGLTHLAVVAEPYRVPSSPDWAADLEGRVAIIRRCCVGAPPTFAVVERGRGFVAVLWAEIFVLGVYFSPNRTLAEFEVFLSELSRVVGRSHFRRILVLGDLNAKSLSWGSSRTCPRGRAVEEWLVGSGLLILNRGTELTCVRRLGGSVVDVTFATPDVAYRVRGWAVMVGEETLSDHRYIRFSVAATPVGSVRGFSLPISGSARGPRWAQKRLNIERLREAAIVQAWRLDSLGEPADVCEGVERLREAMSRVCDAAMPRVRALAPKRQVHWWTEEIASQRRLCDISRRTYQRYRRRRTRRDPDEEDRLYEVYRTAIRTLRLAIGEAKEAAWNDLLASLDRDPWGGPTGWRRVVGGLFPDLSGTAFVPPVMTMARIADSEELEDVSQVEFDLAVQRMRAKRTAPGPDGISSQAWALALTGDGLGPALQGLFSRCLREGRFPEPWKTGRLVLIPKEGRPRDEPSGYRPIVVLDEAGKLLERIVASRLVQHLESVGPDLAPNQYGFRRGRSTMDAVLRVRHLSDRACSEGGVLLAVSIDIANAFNTIPWSTIVESLRFHRVPPSLRTLIEDYLSGRNVVFPERRGWGRKAVSCGVPQGSVLGPLLWDIGFDWVLRGASLRGVDVVCYADDTLVTARGADYRAAAILATAAVSTVVSRIRRLGLEVALRKSEAVCFHPVRRGPPPGANLIVGGVSIAVQPKLKYLGLVLDSRWRFDHHFGELVPKLLGMAGALARLLPNVGGCSAGVRRLYLGVVRSMALYGAPVWSPALSARNAALLLRAQRVLAVRVIRGYRTISREVACALDGSLPWDLEAEVAAAVYRRRTQSLSRGRTPGPSAVGRWRRAARHLAYAKWRERLLEELGQTSVTRRRTLEALVPVLEAWSDRRHGVLSFHLTQVLSGMAASGEEISSYTVGILVTPGINLRQDPERINQSGVMIISVEFRG
Summary
Uniprot
EMBL
Proteomes
Interpro
Gene 3D
ProteinModelPortal
PDB
1WDU
E-value=7.27099e-08,
Score=142
Ontologies
GO
Topology
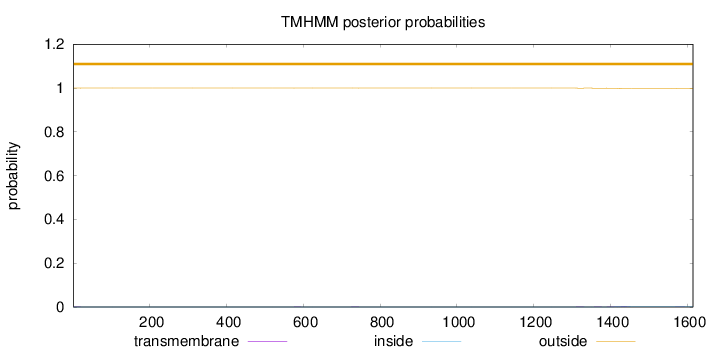
Length:
1615
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.0925699999999999
Exp number, first 60 AAs:
0.00563
Total prob of N-in:
0.00032
outside
1 - 1615
Population Genetic Test Statistics
Pi
1.873802
Theta
111.130655
Tajima's D
0
CLR
1.372777
CSRT
0.370181490925454
Interpretation
Uncertain
