Gene
KWMTBOMO16121
Pre Gene Modal
BGIBMGA004537
Annotation
PREDICTED:_uncharacterized_protein_LOC106123166_[Papilio_xuthus]
Location in the cell
Nuclear Reliability : 1.914
Sequence
CDS
ATGTATTTTCATTACTCGGTAGGAGCCATTTTTGGTATATTTATTTTGTGTGTTCATTGTGATAATGCTGGCGACAACGAAATTAAGGAGATTTACGTTCCGTCCGCTCCTCAGAACTTGACAGCAGATAATGTGACTTCGAAAGAGATACATCTTCTATGGACCCCGCCTTCAACTTTCACAGTCCATCCGGTGCCGATACGAGAAGACACGACCGAATCCGATCCTGTTTCACCTCAGAAGGTTCGGTCACAAAACGACGGGCCGACCAATGACGTCATCAATCCTGCTCCCGAATCCGTAGCTTCAGAGAGGCTCAAAGAGCTAGAGTACCCCTACGATATGTATAGAAACGATAAAAACGATGATTATTCGAATTCCGGTATATTAATGGACTCTTACAAGACCAAGAGGGATCTTTGGTCTCATCGACACAGAAAACGTTCTCATGATAACGTGACCGAATCGAAGGCACCACAGCTGGAGCAGTACGAATACTTTGAGGTCAATCTGCAAAACGACGAACCAATAGAAGTCGTTAAGAAAACGGTCCATCCGAAACCGCACAAGGACATGACACAAATCGCGTATATACTTTATTACGAGGTAGGCGTTCAGAATTACGACTTCAATGCAAGCGGTGTCCAGAAATCGGCAGACGTCCGAAAGAACAACGTGTTCTTGAGCGATCTTATGATGGAAGACAGTACGAAGCATACGAGGAACCTGACGCTGTGGAATAAATCCGGGATAGCGGCCAAAGTAGTAGCTTTCAACTTGAAGCATTTGAAGCCGTTCACAGCTTACAAGATTTGGGTCCGCGCCTTCTACAACACGTCGCCGTACCTCACGGTCCCGGATTTGTCGACGCACCTCAGCCCAAGATCGAAGCCGTTGTACGTCATGACCGACGTGGAGCCTCCGTCCGAACCCATCATCTTGAAGTTGTCCTGCGATATGGATAAAGGGTCACTCTACATACAATGGCGACAGCCCCTTTACTTCAACAACACGCTCAACCAATACGTAGTGACCTTGAGGAAGATACCGGAACACCACCCGAGGAAGACGGTCACTTTTCCGACCAGCAAAGATGATTTGGAAACGTTTTTTAGCGTCCCGGTTGAGCTCTGGAACAATACTAGGTACGAAGTGATCCTGTATGCTGTCACGTTTTCTATCGCTAAGGAAGGCTCGCTTGTGATGGGGAAACCTTCGGCCGCTCAGGAGGTGTCGAGCGAATCGTGTGTGGAGCGCGGCGGGGAGCAGGGGGCGGTGGGGGCAGCGGGGGCGGGCGCGGAAGTGGGGGACGCGCCGCAGGGGGACGCCAAGACCAAGGCCTTACTGGCCATACTGCCTCTGGCGCTACTCGCCGCTGTCGGCCTGGCGTTGGTTTACTGTAGATGCAGGTCTCGTCTGAGTAAGTGCATAAGTGCGGCGTACAATTACTTGGAGGAGGGAGGGGAGAGGGGTGCGAGAGCCCCACTAAACTCCTACAAGAAGCCCGTAGGTATAGGCATGGCGCCGGGGTCGGGCGGCTGTGCGGCGGCGGACGGGGGGCCGGCGGGGGGCCGCGGGGGTCCGCCCCCCCGCATCGCCGGCACCCACCACCCCGCGCTCTCCGCCACCGCCTTCCCGAGACACGTCGCCGCGCTGCATGCCGACGGAGATATTGGATTTAGTAAAGAATACGAAATCGTTGTATCGAGATCGAACGCGTTAGGGCACACCAGCCACCACAGCCACCGCCCAGAGAACCGGCTGAAGAACCGCTACTTGAACATCACTGCCTACGACCACTCCCGCGTGTGCGTGTCGGAGGGGGGGCGGTGCGGCGCGGCGGGGTGCGCGGGGGGCGGCGGTGCGGGCGCGCCCTGCGACTACGTCAACGCCAACTTCATCGACGGCGTGCTGCCGCAGCTGGGGGCCGACCACCTCGCCAGGATCAAAGCTAAACTCAGGAAGAGAGATAAACCTGATCGGCCGCCGTCAATAAAACAATCGAAGCCGCCTCCCCTGCTAGCGGAGGGCATAGAGTCGGCGTTCCTCAACATAGAGTTCAGCGGCATCGTGGAGTCGGAGGACAGAGAGGACTACGACAGCGACAGGAGCGACGACTCCGAGCTGGACGACGTGTATGTCGACATCGATGGCGTGCGCACTCGGATAAAACTAGAATGGGCGCTGTGGAAGCGTCGTTACATCGCGACGCAGGGCCCCACGCCGGCAACACTCGACGCCTTCTGGAGAATGATCTGGCAACACCGGGTGCACACGCTGGTCATGATCACCAACTTGGTTGAAAGGGGGCGTCGCAAGTGCGACATGTACTGGCCGGCGGGCGGGCGCGGCAGTGCGGCGCAGTTCGGGCCCGTGCGCGTCACGCTGCTGCACGAGGACGTGCGCGCCGCCTACACCGTGCGACACATGAGCGTGCGCGTGCCCGACAGCGAGCCGTCCACCCCGGGCGGCGGGGGGGCGGAGCGCGCCGTGGTGCAGTACCACTACACGGTGTGGCCCGACCACGGCACCCCGCGCCACCCGCTCGCCGTGCTGCCCTTCGTGCGGGCCGCCTCCGCGCACCCCAGCACCGTGCTCGTGCACTGCAGCGCGGGCGTCGGTCGGACTGGTACATACATAGTACTGGACGCGCAGCTCAACCAGCTGAAGCTGACGGGAACCCTGTCGCCCCTCGGCTTCCTGTGCCGAGCGCGCACGCAGCGGAACCACCTCGTGCAGACGGAGGAGCAATACGTGTTCGTGCACGACGCGCTGCTCGAGCACGTGCGCAGCGGGAACACGGAGGTCGAGTTCTCAAACACCCGCCAATATCTACTCAAGCTACTCGAAGACATTACCGAAGAGGAACTAGCGGTTTTGGACCTTAATCCTGGCAAGAATAAGGTCGAGAATGAATCGCCGCCGACAAACGTAATCGACGAGACTAATAACGACACTGGCAGTCAGGAATCTGTTCGAACAGTTGACTTGGATAGTGAACCCAAGTCGTCGTCCGAGAGCGAGGAGAAAGAGATAGTCAATGGAGACGAGAAGGAGGGAGAAAGGGAGACGCGGGAGGGTGAAGGGGAGGGCGTGTATGATTTGGCGCCCAGAACCGGGGTGACTTATGGAGACAAGATGGCAGCCTACAATAATATGTGTGAAGAGGAGAAAGAAGAAATTCGAAGGGTGAACCGCGCCGAGAACTACGCTCTGCTGGAACGCATGAGGGCCTTGGCCAACCGGCACTATACCTTCCAGGGCCCAGCGCCTGTCAACCTCCTGGAGAAACAGTTCATGCTGATAACGCACGGGTGCGCGTGCGCGGGCGGCGGAGCGTGCGGGGGCGCGGGCGGCGGGGCGGGCGCGGCGCTGGGCCCGCACAACGCGCACAAGAACCGGCCGCGGGGCGCGCTGCCGGCCGACGCCGCGCGCGTGCTTCTGCTGCCCAAACCAGGAGTCGAAGGCAGCGAGTACGTGAACGCGTCGTGGGTGTGCGGGCGGCGCCGCCTGCGCGAGTACGCGGTGGCGCAGCACCCGCCCCCCGCGCCCGCCGCCCCCGCCGCGCCCGCCGACCTGCCGGACCAGGCCCAGCTGTGGCGCCTGCTGTGGGACCACACCGCGCAGCTCGTGCTAGTGCTGTCCGACACCACCGACCCGGAATGTAAAGTGTTTTGGCCGACGGAAGAAGAGAAAGAGCTGTTCGTTGCGAATTTCCGAGCGAGTTTCGTGTCGAAGGACACGCTCGTCGCGCGCCGGAAGGAGGAGCGACGGGGGGAACGGGGGGCGGAGCGGGAGGGGGAGCGGGGGGTGTCCGCCGACAGCCCGCCGCCGCCCAACGGCGAGGCGGAGGGCGGCGGGCGGCGGGACCCCGGCGACTGCGCGGACGACGAGCGGCTCATCCCCGAGCGCGGCTCCCCGCTCAGCGACGCCGAGCCCGCCTACCGGTTCGACCGCGCCGACCTTCGCCTGGAGCGACTAAGCGGACACCGAGACCTCTCCGCCCGCAAGTCCATAGCCAACGGCGACCTGTTCTCCTCCATATCCGAAAAGAAAAACGGACCCAAATCGCCGAGAAGTCCTTCGAAGATGTCCCTCAAGAACTTCAAATTGAGTTCCCCGACAAAATTCAAGTTTCCCGACTGGGGGACCAACAGGACGGCCGGCTCCCCCCCGGACACGGCGCCCCCGCCGCCCCCCGTGGCCCCCGCGCTGTCCGTCGAGGAGGAAGCGGAACTGCGGAGACCGTGCTACTATTTCGAGAAAGTGGACAGTGTGCCGGAAGGCGTGCCGACGGATAGAGTGATCGAAGTGACCAATGTGAGCGTGCATTCGTTACAAGACGACTACCAGCTCAGTGTTAAGTTTATACAGTGCAGCGGTTGGCTGGAGGGCGACACGACGCGGTACACGACCGGGAGGCCGGAGGACAACGAGTACATCAGGGCCGTGAGGAGAGCGAGCAGTGACTGCGAGAGGGAGCAGGCGCTGGACCGGCTCGTGCAGCCCTACGAGGACTCCTTCGCGCTGCTGGAGTTCGTGGCCGGCTGCCAGATGGAGTACAAGAACGGGCCGGTGGTCGTCGTAGACAAATACGGAGGATGGAAGGCGATGACGTTCTGCAGTCTGTCGGCTGCGAGCGGGGGGGCGAGGGCCGCGGACGCCAACGACCCGTTCAGGCCGTTCCGTCCGCCCGCAGACGACACCGCCGACCTGTACTGCTGGTCGGCGCTGGCGGCCCACTCGCGGATCCTGGCCCCCATTCCGCCGAGCTCCCCCTGTGCGTCCCCGTCCTCGTCCCCTGGCTCCCCCGCGGTCCCCCCGCGCCCCACCGAGGCGATCCCGCACACCCCCTCGGCGCTGTTAGCCGCGTACTGTGCGCTGGCATCCTATGGCCCGAGGTTACACGCACCGTCTATTAGGTGA
Protein
MYFHYSVGAIFGIFILCVHCDNAGDNEIKEIYVPSAPQNLTADNVTSKEIHLLWTPPSTFTVHPVPIREDTTESDPVSPQKVRSQNDGPTNDVINPAPESVASERLKELEYPYDMYRNDKNDDYSNSGILMDSYKTKRDLWSHRHRKRSHDNVTESKAPQLEQYEYFEVNLQNDEPIEVVKKTVHPKPHKDMTQIAYILYYEVGVQNYDFNASGVQKSADVRKNNVFLSDLMMEDSTKHTRNLTLWNKSGIAAKVVAFNLKHLKPFTAYKIWVRAFYNTSPYLTVPDLSTHLSPRSKPLYVMTDVEPPSEPIILKLSCDMDKGSLYIQWRQPLYFNNTLNQYVVTLRKIPEHHPRKTVTFPTSKDDLETFFSVPVELWNNTRYEVILYAVTFSIAKEGSLVMGKPSAAQEVSSESCVERGGEQGAVGAAGAGAEVGDAPQGDAKTKALLAILPLALLAAVGLALVYCRCRSRLSKCISAAYNYLEEGGERGARAPLNSYKKPVGIGMAPGSGGCAAADGGPAGGRGGPPPRIAGTHHPALSATAFPRHVAALHADGDIGFSKEYEIVVSRSNALGHTSHHSHRPENRLKNRYLNITAYDHSRVCVSEGGRCGAAGCAGGGGAGAPCDYVNANFIDGVLPQLGADHLARIKAKLRKRDKPDRPPSIKQSKPPPLLAEGIESAFLNIEFSGIVESEDREDYDSDRSDDSELDDVYVDIDGVRTRIKLEWALWKRRYIATQGPTPATLDAFWRMIWQHRVHTLVMITNLVERGRRKCDMYWPAGGRGSAAQFGPVRVTLLHEDVRAAYTVRHMSVRVPDSEPSTPGGGGAERAVVQYHYTVWPDHGTPRHPLAVLPFVRAASAHPSTVLVHCSAGVGRTGTYIVLDAQLNQLKLTGTLSPLGFLCRARTQRNHLVQTEEQYVFVHDALLEHVRSGNTEVEFSNTRQYLLKLLEDITEEELAVLDLNPGKNKVENESPPTNVIDETNNDTGSQESVRTVDLDSEPKSSSESEEKEIVNGDEKEGERETREGEGEGVYDLAPRTGVTYGDKMAAYNNMCEEEKEEIRRVNRAENYALLERMRALANRHYTFQGPAPVNLLEKQFMLITHGCACAGGGACGGAGGGAGAALGPHNAHKNRPRGALPADAARVLLLPKPGVEGSEYVNASWVCGRRRLREYAVAQHPPPAPAAPAAPADLPDQAQLWRLLWDHTAQLVLVLSDTTDPECKVFWPTEEEKELFVANFRASFVSKDTLVARRKEERRGERGAEREGERGVSADSPPPPNGEAEGGGRRDPGDCADDERLIPERGSPLSDAEPAYRFDRADLRLERLSGHRDLSARKSIANGDLFSSISEKKNGPKSPRSPSKMSLKNFKLSSPTKFKFPDWGTNRTAGSPPDTAPPPPPVAPALSVEEEAELRRPCYYFEKVDSVPEGVPTDRVIEVTNVSVHSLQDDYQLSVKFIQCSGWLEGDTTRYTTGRPEDNEYIRAVRRASSDCEREQALDRLVQPYEDSFALLEFVAGCQMEYKNGPVVVVDKYGGWKAMTFCSLSAASGGARAADANDPFRPFRPPADDTADLYCWSALAAHSRILAPIPPSSPCASPSSSPGSPAVPPRPTEAIPHTPSALLAAYCALASYGPRLHAPSIR
Summary
Catalytic Activity
H2O + O-phospho-L-tyrosyl-[protein] = L-tyrosyl-[protein] + phosphate
Uniprot
Pubmed
Proteomes
Pfam
PF00102 Y_phosphatase
Interpro
Gene 3D
CDD
ProteinModelPortal
PDB
2NLK
E-value=3.58537e-60,
Score=593
Ontologies
GO
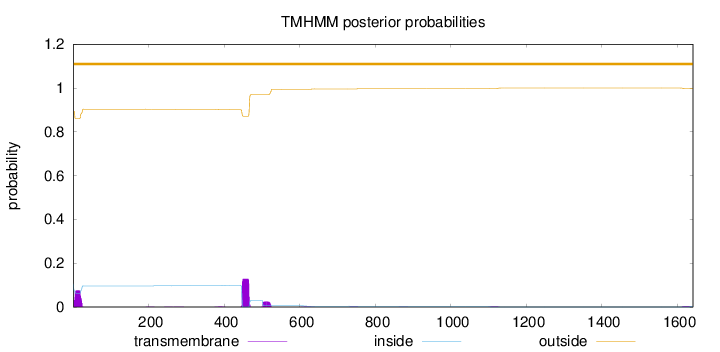
Topology
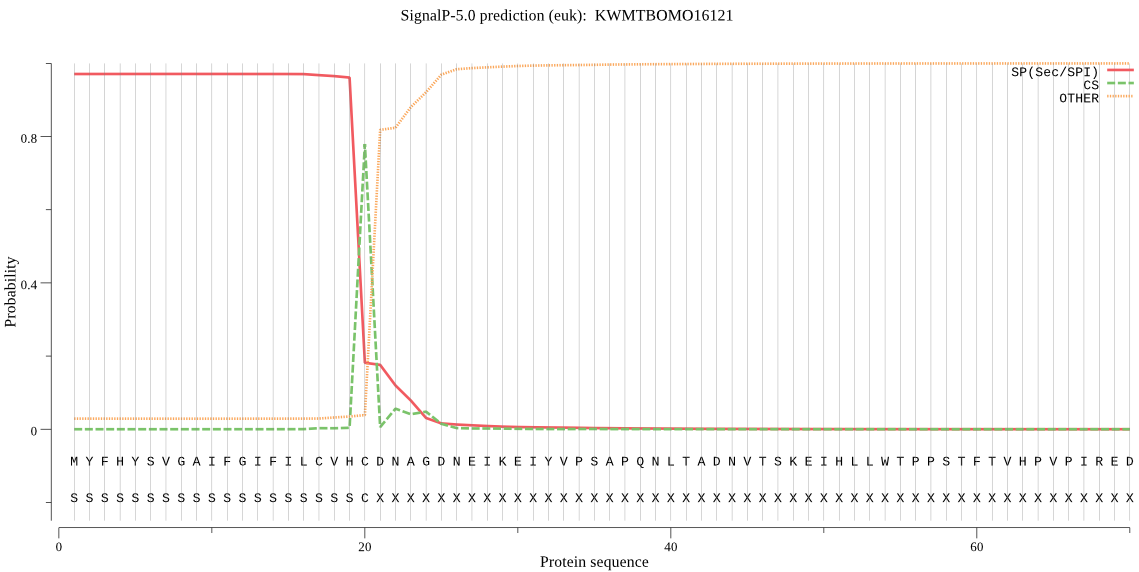
SignalP
Position: 1 - 20,
Likelihood: 0.971173
Length:
1641
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
4.71343999999998
Exp number, first 60 AAs:
1.40689
Total prob of N-in:
0.10548
outside
1 - 1641
Population Genetic Test Statistics
Pi
237.610444
Theta
168.447122
Tajima's D
1.527645
CLR
0.130108
CSRT
0.791410429478526
Interpretation
Uncertain
