Gene
KWMTBOMO16035
Annotation
PREDICTED:_uncharacterized_protein_K02A2.6-like_[Amyelois_transitella]
Location in the cell
Nuclear Reliability : 2.545
Sequence
CDS
ATGGAACACGCCCGACCACCGTCAGAATTGAGTCTGGAAGGCAACTCCGTCAGCCGGGCTGACGCATGGAAGCGTTGGAGGAAACAATTTCATGTATTTTTGAAAGCATCAGGGGTGCATAAAGAAGAAGGCAGTGTGCAAGCCAGCTTGCTCATCAATTTAATTGGAACGGAAGGTTTCGATGTGTACGAGACGTTTAAGTTTTCAAATGACACTGAAAAAGATGACGTAACGGTTTTGTTAAAAAAATTCGACGAATACTTCGGCGTCAAACCAAATGTTACGTTGGCGAGATATAATTTCTACATGAGAAACCAGGAAGGCGGCGAATCCATAGATCAGTATGTGACGGCTTTGAAACTGCTGAGCAAAACCTGTGAATTTAAAACCTTAGAAGACGAATTCATTCGCGATCGGATCGTATGCGGCGTAAAAAATACGATAGTTCGCGATCGTTTACTGAGAACGGACGACTTGACGATGGACAAAGCTATTAAAATATGCCAAGTCGACGAGGTATCGGCGGACAGCAGTCGCGTATTGCAGGAGTCGCGCGGAGCGAGCGCGGAGCCGGTGCGCGTGGACGCTGTGGGCGCGCGGGTGGTGCTGGGCCACGTGCGGCGCGGGGCCGAGCCGGCGGCGCGCGAGCAGCTCGCGGCGGCCGCGGCGGTCACCGGCTGCGTGCGGTCCCGGATGGCGCGGGGCGCCCGCCGCCTCTTTCCAGTTCATCTGCGTCCAGTACTTGTCTCAGAGGACGAAAATAAATACGAGCCGGAACTGGACGATGACTGGGAGTCGTTTTATATATCTACTTTAATTGATGGTTCCAAAATCGACTCGGTGTCGCAGGATTGGTTTGAGGTCCTCCGAGGAGAATGGGGCTCGGAAAATTTTAAACTAGACTCGGGTGCAGATATCAATGTCTTATCTTTTAAGCGATTTGTGCAGTTAGGCAATAACCCTAATAACATTGTTGTAAATCATAAGGTTAAACTGCAATCTTACAGTGGCGATTTCATTCCTATTAAGGGAATTTGTAATATTAAATGGTGGTATAAAAATGTTCAATATGATCTTAAGTTTGCGATAGCTGATATTGATTGTCAAAGTGTACTGGGACTGCAGGCGTGCTTATTATTAGGGTTAATAAAAAGAATTCACGATATAAATTTCTCTAAAAATAGTGATTTGTTCACTGGGTTAGGTTGTTTACCGGGGGAATATCATATAACGGTAGATAGGGATGTGACGCCGGTGGTGTGCGCTCCGCGGAAAGTACCGTTAAGCCTTCGTGATAACTTGAAGGACGAGCTCGATAGGATGACAGAGTTAGGTGTGATTAGGAAGGTGACTCATCCGACACCTTGGGTCAACTCGTTAGTAGTAGTGGCCAAGACAAATGGTAAAATGCGCATATGCCTAGACCCGAGGCCTCTCAATAAGGCGATTCAACGTGCTCATTTTCAACTACCCACCATAAATGAGTTGGCTACCAAATTGAATGGGGCTAAATATTTTTCGGTATTGGATGCCAATTCAGGATTTTGGTCCGTAAAGCTAGATAAGGAGAGTGCCGATTTATGCACATTTATTACGCCGTTTGGGCGATATCAATATCTAAGATTACCGTTCGGACTGAACTGCGCACCGGAGGTATTCCACGCTAAATTAAAACAATTGTTAGAAGGTTTAGACGGTGTTGAGTCGTTTATTGATGATATTATTGTCTGGGGGTCCACTAGGCGAGAACATGATGTAAGACTAAATGCGTTATTTCAAAAAGCGCGAGATATTAATTTAAAGTTTAACAAAGATAAGTGTCGCATTTGTGTCGATGAGGTGACATATTTGGGACATATTTTTAATAAAGACGGAATGAAAGTAGATACGGAAAAAGTGCGGGCTGTAATCAATATGCCGGAACCTACGGATTGTAAAAGTTTAGAAAGGTTCTTGGGTGCAATTAATTATTTATCAAAGTTTATACCTAACTACTCGCAACACATATTTCCATTGACTAGATTATTGAAAAAAGATGTCGAGTGGTGTTGGGAAATAGGTCACAAAAACGCCTTTGATAAATTAAAGAAACTGATATGCGAGGCTCCGGTATTATCGTTGTTTGACGTAGGCAGTGAGGTATTGTTGTCGGTGGACGCAAGCAGCGTCGCACTTGGCGCGGTGCTGATGCAGCGCGGCCGCCCGGTCGAGTACGCGTCGCGCACACTCACCGACACACAACAGAGATACGCTCAGATTGAAAAAGAAATGTTAGCTATTGTCTTTGCTTGTGAAAAATTTCACCAGTACATTTATGGAAAAAGGTATATAGTCATAGAAACTGACCATAAACCTCTTGAAAGTATTTTTAAAAAGCCGCTCAATTCAGTCCCAGCACGCTTGCAGCGTATGATGTTAAAATTACAAGGGTACGATCTGAAAATTACTTATAAACCGGGGAAGTATATGTATATACCCGACACGTTATCACGTGCGCCTCTTCCGGATTTATATGACGATAAAATTAGTAAGGCAGTATTGAACCAATTGAAAATGGTAATTAACAATGTACCGATGTCTCAAAGCAAACTGACATTAGTTAAGAAAGAAACTAGTAAAGATGAGTATTTGAAACGTTTGTTAGTTTACATTAATGAAGGTTGGCCCGTTCATAAATATAATGTTGATAGTGATTTAAAGTATTTTTGGTCCATGAGAGACGAGCTGTACTCTGTTGACGGAGTAATTTTTAAAGATAAACAGCAACAGCATAAAACAATAATAGAAAAACAATTAAAAAGTAAAATGTATTATGACCAACATTGTAAAGAGCAGCCGGAGCTAAGTGTCGGCGATGATGTAATTATGTTAGAACATAATAATGAACGAATGCGCGGCACTGTCGTAGGCAAGGCATCTGCACCGCGTTCATACATTGTAAAAAACAAATTAGGTATATATCGACGTAATCGCCGACATTTAATTAAAAATATGCCTGATGAGAAACCTAATGTTGTGGAAAAGCTGAAGAATGATCGGCGCGACACAATAGTGATCGTATCAGACGAGTCAAGTGGGGGAGAATATGAGATGAGTGTGGATGAGGATGGTTCAGTGTACGAACCGAGTACTTTGTCATCACCTTCATCACCTCATATTTATCCGCCTACTACTCGTAGTAGAACTAAGCAGAATGCAATTAATAATAATTAA
Protein
MEHARPPSELSLEGNSVSRADAWKRWRKQFHVFLKASGVHKEEGSVQASLLINLIGTEGFDVYETFKFSNDTEKDDVTVLLKKFDEYFGVKPNVTLARYNFYMRNQEGGESIDQYVTALKLLSKTCEFKTLEDEFIRDRIVCGVKNTIVRDRLLRTDDLTMDKAIKICQVDEVSADSSRVLQESRGASAEPVRVDAVGARVVLGHVRRGAEPAAREQLAAAAAVTGCVRSRMARGARRLFPVHLRPVLVSEDENKYEPELDDDWESFYISTLIDGSKIDSVSQDWFEVLRGEWGSENFKLDSGADINVLSFKRFVQLGNNPNNIVVNHKVKLQSYSGDFIPIKGICNIKWWYKNVQYDLKFAIADIDCQSVLGLQACLLLGLIKRIHDINFSKNSDLFTGLGCLPGEYHITVDRDVTPVVCAPRKVPLSLRDNLKDELDRMTELGVIRKVTHPTPWVNSLVVVAKTNGKMRICLDPRPLNKAIQRAHFQLPTINELATKLNGAKYFSVLDANSGFWSVKLDKESADLCTFITPFGRYQYLRLPFGLNCAPEVFHAKLKQLLEGLDGVESFIDDIIVWGSTRREHDVRLNALFQKARDINLKFNKDKCRICVDEVTYLGHIFNKDGMKVDTEKVRAVINMPEPTDCKSLERFLGAINYLSKFIPNYSQHIFPLTRLLKKDVEWCWEIGHKNAFDKLKKLICEAPVLSLFDVGSEVLLSVDASSVALGAVLMQRGRPVEYASRTLTDTQQRYAQIEKEMLAIVFACEKFHQYIYGKRYIVIETDHKPLESIFKKPLNSVPARLQRMMLKLQGYDLKITYKPGKYMYIPDTLSRAPLPDLYDDKISKAVLNQLKMVINNVPMSQSKLTLVKKETSKDEYLKRLLVYINEGWPVHKYNVDSDLKYFWSMRDELYSVDGVIFKDKQQQHKTIIEKQLKSKMYYDQHCKEQPELSVGDDVIMLEHNNERMRGTVVGKASAPRSYIVKNKLGIYRRNRRHLIKNMPDEKPNVVEKLKNDRRDTIVIVSDESSGGEYEMSVDEDGSVYEPSTLSSPSSPHIYPPTTRSRTKQNAINNN
Summary
Uniprot
A0A3P8Q6C6
A0A3B3HLX7
A0A3P8S414
A0A3B1JKR1
A0A023EY30
A0A3P9HT22
+ More
A0A2G8JDW4 A0A2G8LMB1 A0A2S2N8I3 A0A3B3C9X5 A0A1S3DNR0 A0A3Q2XZ76 A0A1S3DH71 A0A1S3DM37 X1WTY2 A0A3P9LZF9 A0A3P9K9H2 A0A0A9Z4Y4 A0A146LC45 A0A3P8Q2Q2 A0A1A8S1T9 A0A1A8DQM9 A0A3P8RKT7 A0A1A8L2U7 A0A3P9AYU2 A0A3P8RHF8 A0A146TAZ6 A0A3P9HXP1 A0A3B3H7E4 A0A3P8R8M6 A0A1S3JEC7 A0A3B3I1S4 I3KYE2 A0A267GLM4 A0A1S3DJN8 A0A147BKH7 A0A3Q0JJE3 A0A3Q2DE46 A0A1Y1M671 A0A3P8QAD1 A0A1A8N8J3 A0A1Y1MCJ7 A0A0P5XDK7 A0A146SN99 A0A3Q0JK14 A0A1Y1KVT8 A0A1S3HHB2 A0A147BIE4 A0A1Y1NDC5 A0A147BJX4 W4Y1E4 W4YGV7 A0A146L0H7 A0A0A9VTL5 A0A2S2NI46 A0A075EIL5 W4ZHL7 J9LYD2 W4XLW6
A0A2G8JDW4 A0A2G8LMB1 A0A2S2N8I3 A0A3B3C9X5 A0A1S3DNR0 A0A3Q2XZ76 A0A1S3DH71 A0A1S3DM37 X1WTY2 A0A3P9LZF9 A0A3P9K9H2 A0A0A9Z4Y4 A0A146LC45 A0A3P8Q2Q2 A0A1A8S1T9 A0A1A8DQM9 A0A3P8RKT7 A0A1A8L2U7 A0A3P9AYU2 A0A3P8RHF8 A0A146TAZ6 A0A3P9HXP1 A0A3B3H7E4 A0A3P8R8M6 A0A1S3JEC7 A0A3B3I1S4 I3KYE2 A0A267GLM4 A0A1S3DJN8 A0A147BKH7 A0A3Q0JJE3 A0A3Q2DE46 A0A1Y1M671 A0A3P8QAD1 A0A1A8N8J3 A0A1Y1MCJ7 A0A0P5XDK7 A0A146SN99 A0A3Q0JK14 A0A1Y1KVT8 A0A1S3HHB2 A0A147BIE4 A0A1Y1NDC5 A0A147BJX4 W4Y1E4 W4YGV7 A0A146L0H7 A0A0A9VTL5 A0A2S2NI46 A0A075EIL5 W4ZHL7 J9LYD2 W4XLW6
Pubmed
EMBL
GBBI01004745
JAC13967.1
MRZV01002352
PIK33923.1
MRZV01000033
PIK61397.1
+ More
GGMR01000868 MBY13487.1 ABLF02013930 ABLF02013934 GBHO01004090 JAG39514.1 GDHC01013957 JAQ04672.1 HAEH01020882 SBS11479.1 HADZ01002490 HAEA01007842 SBQ36322.1 HAEF01001580 SBR38962.1 GCES01096219 JAQ90103.1 AERX01070080 NIVC01000291 PAA86189.1 GEGO01004116 JAR91288.1 GEZM01041944 JAV80090.1 HAEH01000697 SBR65395.1 GEZM01035137 JAV83383.1 GDIP01073678 JAM30037.1 GCES01104253 JAQ82069.1 GEZM01074317 JAV64601.1 GEGO01004841 JAR90563.1 GEZM01011167 JAV93617.1 GEGO01004317 JAR91087.1 AAGJ04066141 AAGJ04164197 GDHC01017753 JAQ00876.1 GBHO01044535 JAF99068.1 GGMR01004179 MBY16798.1 KF319019 AIE48224.1 AAGJ04068764 ABLF02041541 AAGJ04172695
GGMR01000868 MBY13487.1 ABLF02013930 ABLF02013934 GBHO01004090 JAG39514.1 GDHC01013957 JAQ04672.1 HAEH01020882 SBS11479.1 HADZ01002490 HAEA01007842 SBQ36322.1 HAEF01001580 SBR38962.1 GCES01096219 JAQ90103.1 AERX01070080 NIVC01000291 PAA86189.1 GEGO01004116 JAR91288.1 GEZM01041944 JAV80090.1 HAEH01000697 SBR65395.1 GEZM01035137 JAV83383.1 GDIP01073678 JAM30037.1 GCES01104253 JAQ82069.1 GEZM01074317 JAV64601.1 GEGO01004841 JAR90563.1 GEZM01011167 JAV93617.1 GEGO01004317 JAR91087.1 AAGJ04066141 AAGJ04164197 GDHC01017753 JAQ00876.1 GBHO01044535 JAF99068.1 GGMR01004179 MBY16798.1 KF319019 AIE48224.1 AAGJ04068764 ABLF02041541 AAGJ04172695
Proteomes
Interpro
Gene 3D
ProteinModelPortal
A0A3P8Q6C6
A0A3B3HLX7
A0A3P8S414
A0A3B1JKR1
A0A023EY30
A0A3P9HT22
+ More
A0A2G8JDW4 A0A2G8LMB1 A0A2S2N8I3 A0A3B3C9X5 A0A1S3DNR0 A0A3Q2XZ76 A0A1S3DH71 A0A1S3DM37 X1WTY2 A0A3P9LZF9 A0A3P9K9H2 A0A0A9Z4Y4 A0A146LC45 A0A3P8Q2Q2 A0A1A8S1T9 A0A1A8DQM9 A0A3P8RKT7 A0A1A8L2U7 A0A3P9AYU2 A0A3P8RHF8 A0A146TAZ6 A0A3P9HXP1 A0A3B3H7E4 A0A3P8R8M6 A0A1S3JEC7 A0A3B3I1S4 I3KYE2 A0A267GLM4 A0A1S3DJN8 A0A147BKH7 A0A3Q0JJE3 A0A3Q2DE46 A0A1Y1M671 A0A3P8QAD1 A0A1A8N8J3 A0A1Y1MCJ7 A0A0P5XDK7 A0A146SN99 A0A3Q0JK14 A0A1Y1KVT8 A0A1S3HHB2 A0A147BIE4 A0A1Y1NDC5 A0A147BJX4 W4Y1E4 W4YGV7 A0A146L0H7 A0A0A9VTL5 A0A2S2NI46 A0A075EIL5 W4ZHL7 J9LYD2 W4XLW6
A0A2G8JDW4 A0A2G8LMB1 A0A2S2N8I3 A0A3B3C9X5 A0A1S3DNR0 A0A3Q2XZ76 A0A1S3DH71 A0A1S3DM37 X1WTY2 A0A3P9LZF9 A0A3P9K9H2 A0A0A9Z4Y4 A0A146LC45 A0A3P8Q2Q2 A0A1A8S1T9 A0A1A8DQM9 A0A3P8RKT7 A0A1A8L2U7 A0A3P9AYU2 A0A3P8RHF8 A0A146TAZ6 A0A3P9HXP1 A0A3B3H7E4 A0A3P8R8M6 A0A1S3JEC7 A0A3B3I1S4 I3KYE2 A0A267GLM4 A0A1S3DJN8 A0A147BKH7 A0A3Q0JJE3 A0A3Q2DE46 A0A1Y1M671 A0A3P8QAD1 A0A1A8N8J3 A0A1Y1MCJ7 A0A0P5XDK7 A0A146SN99 A0A3Q0JK14 A0A1Y1KVT8 A0A1S3HHB2 A0A147BIE4 A0A1Y1NDC5 A0A147BJX4 W4Y1E4 W4YGV7 A0A146L0H7 A0A0A9VTL5 A0A2S2NI46 A0A075EIL5 W4ZHL7 J9LYD2 W4XLW6
PDB
4OL8
E-value=6.53074e-53,
Score=528
Ontologies
KEGG
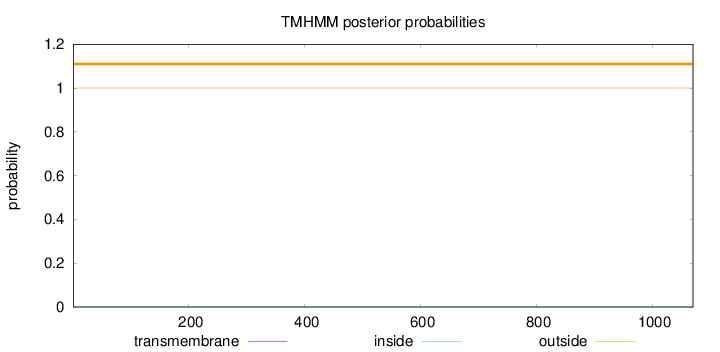
Topology
Length:
1070
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00134
Exp number, first 60 AAs:
0.00015
Total prob of N-in:
0.00003
outside
1 - 1070
Population Genetic Test Statistics
Pi
135.435752
Theta
144.512157
Tajima's D
-0.636986
CLR
402.793268
CSRT
0.213489325533723
Interpretation
Possibly Positive selection
