Gene
KWMTBOMO15918
Pre Gene Modal
BGIBMGA013392
Annotation
PREDICTED:_inositol_1?4?5-trisphosphate_receptor_isoform_X3_[Bombyx_mori]
Full name
Inositol 1,4,5-trisphosphate receptor
+ More
Inositol 1,4,5-trisphosphate receptor type 2
Inositol 1,4,5-trisphosphate receptor type 2
Alternative Name
InsP3 receptor
IP3 receptor isoform 2
Type 2 inositol 1,4,5-trisphosphate receptor
IP3 receptor isoform 2
Type 2 inositol 1,4,5-trisphosphate receptor
Location in the cell
Nuclear Reliability : 2.099
Sequence
CDS
ATGGGTGTCGTTGCATGGTGGGGGAGAGGAGAAGGCAAGAGGATGGGGGACAGCTTCTTGCACCTGGGGGACATTGTCTCCCTCTACGCGGAAGGGACTGTTGCGGGATTCCTCAGTACTTTAGGGTTGGTAGATGACAGGTGCGTGGTCTGTCCAGAGGCTGGCGACCTGACTGATCCACCCAAAAAGTTCCGAGATTGCCTGTTCAAAATATGTCCCATGAACCGGTACTCGGCTCAAAAGCAGTTCTGGAATACGGCCAAGCAGTCTGCGAACCCTAACGCGGACACCGGACTGCTGAAGAGGTTACACCATGCCGCTGAGATCGAGAAGAAGCAGAACGATTTGGAGAATAAGAAACTTCTGGGGACTGTCGTGCAGTACGGCAGCGTCATACAGCTGCTGCACGTCAAGTCTAACAAGTATCTTACGGTAAATAAGCGACTACCCGCATTGCTCGAGAAGAACGCGATGCGGGTTCATTTGGACGCTAACGGAAATGAGGGCTCCTGGTTTTACGTAATGCCTTTCTACAAATTGCGGTCGACTGGGGACAATGTGGTGGTCGGTGATAAAGTGATAATGAACCCGGTGAATGCGGGACAGCAAGTGTTGCACGTCTCTTCCAACCACGAGCTTCCGGACAACGCCGGCTGTATGGAGGTGAATGTAGTCAATTCCTCCACATCCTGGAAAGTCACCTTATTTCTCGAGCACAAAGAGAACCAGGAGGAGATATTGAAAGGTGGCGACGTGGTGAGGCTGTTCCATGCAGAGCAAGAGAAGTTCCTCACTATGGACGAGTACCAGAAACGGCAGCACGTGTTCCTGAGGACCACGGGTCGATCCAGCGCCACCGCCGCGACCAGCAGCAAAGCGCTGTGGGAGATTGAGGTGGTGCAGCACGACCCGTGCCGCGGCGGCGCTGGACACTGGAACTCCATCTTCAGGTTCAAGCACCTCGCCACCGGACACTACCTGGCGGCCGAGGCGTGCAACCGCCCACACGACGGGCCACTAGAAGCGGGCGAGCCGGCCTACCAGCTGGTCCCTGTCCCGCATTCATCGGAGATCGCAACACTTTTCGAACTGGACCCGACCACGATGACGCACTCTGACGCCCCCGTGCCGCAGAGTAGTTACGTTAGATTACAACATTTATGCACGCACACATGGGTCCACTCAACGTCGATACCAATTGACAAAGATGAAGAAAAACCGGTTATGTCAAAGGTGGGGTGCTCGTTGGTGAAAGAAGATAAGGAAGCGTTCGCCCTGATATCCGTGTCGCCGAGCGAGGTCCGGGATCTGGATTTCGCCAACGACGCCTGCAAGGTCCTCTCTGCGCTCTCCACCAAACTGCAGCAGGGCACCATAGAACCTAACGAGAGAAAAGCACTGACATGTCTGCTTCAGGACATAGTGTATTTCATAGCGGGCTTCGAAAACGAACCGAATAAGTCTGAAGCCTTGGACCTGGTCGTCGAGAACCCGCACAGAGACAGACAGAAGCTATTACGCGAACAATACATACTGAGACAGCTGTTCAAAATATTACAGGGTCCGTTCCAAGAGCCAGCCGACGGGGAGCCTTTCCTCAAGATCGAGGAGTTGAACGACACGCGCTACGCTCCATACAAGAACATCTTCCGGCTCTGCTACAGGATCCTGAGGCTCAGTCAGCAGGACTACAGGAAGAACCAGGAGTACATAGCGAAGCACTTCGGGTTCATGCAGAAGCAGATAGGGTACGACATCCTGGCTGAGGACACGATCACCGCCCTGTTGCACAACAATAGGAAGCTTCTGGAGAAACACATCACAGCATCCGAAATCGAGACCTTCGTAGGTCTCGTCCGGAAGAACATGCGCACCTGGCAGTCCCGGTTCCTGGACTACCTGAGCGACCTGTGCATCTCCAACAAGAAGGCTATTGCCGTCACGCAGGAGCTCATCTGCAAGAGCGTGCTCTGCGCCAACAACTCCGACATACTCATCGAGACCAGGCTGGTATCCATTAAATATAAAGAAAAAGGAAAGATGTCGGACCCCGATGAATCCAAGTGCAGCGTGGAGCAGAGAGTCATGCTGTTCTGGAACAACAAAAAGAATCAAAGATACCTGACGGACCTCGCGGCCGAGGCTCGCCTGGACCCCAACAGCGAGGCCGCCGCCATCCTGGACTACTATCGGCACCAGCTCGACCTGTTCTCGAACATGTGTCTCAACAGACAATACCTGGCGCTCAACACGCTGTCCCCACAGCTCCACATCGACCTCATATTGTTGTGCATGTCGAACTCGTCTCTGTCGTACGAGGTGCGCGCGTCGTTCTGCCGGCTGATGCTGCACCTGCACGCCGACCGCGACCCGCAGGAGCCGGTCACGCCCGTCAAGTACGCGCGCCTCTGGACCGAGGTCATCGACCGCATACACATCCACGATTACCAATGCGTGAAGGGGGGCCCGGACGCGAACAGAGAGAAGGTAAAGGAACAGTTCGCTCGCACGATACGTTTCGTCGAGAAGTACCTCTGCAACGTGGTCAGCAGGACCTGGTACTTCAGTGACCACGACCAGAACAAGTTGACCTTCGAAGTGGTAAAACTCGCCCGGGAACTCATTTACTTCGGATTTTACAGCTTCAGCGACCTACTCCGTTTGACGAAGACTCTGCTCAGCATCCTGGACTGCGTCACCGCCATGGATCTGCTCAACGAGACCAACGCTCTGTCCGGGGAGGTCGAATCCGAGGGCGGTGTACTCAGGAGCATAGGTGACATGGGAGCCGTTATGACTTCGATAACACTCGGATCTGTCGCTAGAAACCAAGTAGGAGGTACCGCGACAACCCCGGGAACGGGCACCGGGCTGCAGAGAAGCGCCTCCGCCCTGATGCTGGCCAGGGAACATCCCCTAGTCATGGACACGAAGCTCAAGATCATTGAGATATTGCAGTTCATCCTCGATGTAAGACTTGACTACCGCATCAGCTGTCTGCTGTCCATCTTCAAGAAGGAGTTCGAGCAGGCCGGGGATCAGCGTGCCGCCGACTCCCTGGGCCGGGCCGACGTGGAGGCCATAGGGCTGCAGGCCGAGGGCATCTTCAGCTGCCGGGACGGCTTAGACCTAGACGAATGCGGGGGACGCATGGTGTTACGCGTCCTCCTGCAGCTGTGCTCGCAGGGAGCCTCGGCGGCGCTCGTCTCCGGAGCCCTAGCGCTCCTGTTCCGACACTTCAGCCAAAGGCAGGAGGTTTTAGCTGCTTTCAAACAGGTCCAGCTCCTGGTTTCTGACGCTGATGTGGAATCGTACAAACAGATCAAAGCGGACTTGGACTTACTGCGGCAGAGCGTTGAGAAGTCCGAGCTCTGGGTCTTTAATAAGGGACGAGCTGTCTTACTCGATGAACTTGCCGGTGTGTGCCGCGCTTATGTTACCTTCTGCGTGTGTCCGTCGGGCGCGGTGGGGCCGGGCGGGGCGGTGCTCGAGCGTAACGCGTCGCTCGACAACGTTCTGGACACTTCGAGAACAGCCAAACACGACCACAACGAATATAAGAAGATTAAAGAGATCCTACAGCGCATGATCAAGTACTGCACGCACGGCAACAGCGGCGCCGGCGACTGCGGCCGCCCGCGCCGCCACGAGCAGCGCCTGCTGCGCAACATCGGCGTGCACAACATCGTGCTGGACTTGCTGCAGGTGCCGCACGACGAGGACGACGCAGCTATGGACGAGCTGCTGTCGCTAGCTCACGAGTTCCTCCAGCACTTCTGCCACGGAAACCAGCAGAACCAGACGATCCTCCACAAACATCTCGACTTGTTCCTCAACGCGGGAATCCGAGAGGCGCAGACGGTCTGCGCGATCTTCAAGGACAACGCGTCGCTGTGCGGGCACGAGGGCAACGAGAAGGTGGTGGCGCACTTCGTGCACTGCGTGGAGTCCCGCGGCAGGAAGCCCGACTACCTGCGCTTCCTGCAGACCATCGTCCACGCCGACAAGCAGTACATACGGAAGAGCCAGGACTTGGTCATGCAAGAGATGGTGAACGCCGGCGAGGATGTCTTGGTCTTCTACAATGACAAAGTTTCGTTCAATTACTTCATACAGATGATGAAACAGTACAAAGAGAAAGGGGAAATGCCCGAAGCTCTTACATACCACATCCAGCTCGTGAAGCTGCTGACGTGCTGCACTATGGGGAAGAACGTGTACACGGAGATCAAGTGCCACTCGCTGCTGCCGCTGGACGACATCGTGTCCGCCATCACCAACCCGCACTGCATCCCCGAGGTGAAAGAAGCGTACGTGGGCTTCCTGAACCACTGCTACATCGACACGGAGGTGGAGATGAAGGAGATCTACAGCAGCAACTACATGTGGGACCTGTTCGAGCGCTCCTTCCTCCAGGACATGCACGCCATCCTGCAGAGCGGCGCCGCCTGGTCGGACGTGCCGTCGTCGTCGCACAAGCCGTCCACCACCAGCACGCACCGCGCCTGGGTCAACTACGTCACCGACGTGCTCATGCACACCATATGCACGTTCTTCAACTCGCCCTTCAGCGACCAAAGCACAACCGTGCAGACCCGTCAGTCGATCTTCGTGAAGCTACTCCAGACGACGTTCAGTATATACCAGTGTCCGTGGCTCACGCCGCCGCAGAAGCTGAACGTGGAGAAGTGTATACGGACGCTCAGCGAGGTCGCGAAATCTCGCAGTATCGCGATCCCGCTGGAGCTCGAGGCTAAAATACAGACCGTGTTCGAGAAGGCTGCCGCGCTGTCCCGCCAGACCAGCAAGTGGCTGCAGGCCTCGAAGACTTCGAAACTTGAGAAGATGGCTTCGCAGTTGAACTTGCAGAACGATAGGTCGGTGATGGAGGGTCTACAGGAGATCGTGTCCCTACTGGAGGAACAGCTCCGGCCGCTGCTGCAGGCGGAGCAGTCGCTCCTGGTGGACATCCTGTACAAGCCGCACCTCCTGTTCACCAGCCCCGCCCAGCCCGACGCCAGCGGGATCTTTATATCACGATTAATACGTCACACCGAGAAGCTTCTAGAAGAAAAAGAAGAAAAACTGTGCGTGAAAGTCTTACGCACGTTGAGAGAGATGATGGCCGTGGACCCGGAATATGGCGAGAAGGGCAACCAACTGAGGAACAAGTTGCTGTCTCAATATTTCGTGAACCGCAAGTCCGAGCCGAAGGTGCAGCCCCCGCCGCCCCCCGCCCCCGCCACGCACGGGCCCGGCGCTAAAGTCTTGATGCGGACCGGCCAAACTCTGGCGCAAGTCCAAGCACACCTGGACAAGGAAGGCGCCTCTGACCTGGTCGTGGACCTCGTCATCAAAAGCACCAACCGCCCCGCCATATTCCTTGAGGCCATACAGCTGGGAATCGCTCTTCTAGAAGGGGGCAACCCTATAATACAGCAAAGCATTTACACTAAACTACAAAACGGAGAAATATCTCAAGCATTTTTGAAGGTGTTCTATGATAAAATGCGTGAAGCACAACAAGAGATCAGGTCGCTCGCGGCCAGCAGCACCACCGCCGCCGGCGCCGACAAGCAGCGGGCCCCGCACGCGGACGCCAAGAAGCCGCTTGAAAACGGGGTGAAGTCGAGTCCGGGGCCGCTGGTGGTGGGCGAGGAGATGGATGAGGAGGTGAACAGCGCGTGCGGCACCGCGGTGCACGCCTACTCCGACGTGCACACCATATCGCACGGTAGCACGGCGCTGGAAGAGATCATGTGCGAAAAGAAGCGGGAGTCCAGCAACTCGGACGTGCTGCCCCCCAAGGTGGCCGTCATGAAGCCCATACTCCGCTTCCTCCAGCTCTTGTGTGAAAACCACAACCCTGATCTACAGAACCTACTAAGAAACCAAAACAACAAATCGAACTACAACCTCGTGTCGGAGACGTTGATGTTCTTGGACTGCATCTGCGGCTCTACGACCGGCGGCCTCGGACTCCTCGGACTCTACATCAACGAGGGGAACGTCTCCCTTATCAACCAGACGTTGGAAACTCTTACTGAATACTGTCAAGGACCGTGTCACGAAAACCAGAATTGCATAGCGACGCACGAGAGCAACGGGCTGGACATCATCACGGCCCTGATCCTGAACGACATCAACCCGCTCGGCCGGACGCGCATGGACCTCGTGCTGGAGCTCAAGAACAACGCGTCCAAGCTGCTGCTCGCCATCATGGAGTCCAGGAACGACTCCGAGAACAACGCCGAGCGGATACTGTACAATATGAACCCCAAACAGCTGGTTGATGTTGCGTGCTCAGCCTTCCACCAGGAGCACGGCGCGGACTCGGACTCGGAGAGCGAGGACGACGCGCCCGTGCAGGCCGTCTCCCCCAAGGAAGTGGGCCACAACATCTACATACTGTGCCACCAGCTGGCGGCGCACAACAAGGAGCTGGCGGCGCTGGTGCGAGCCTCGCCCGCCGGCCCGCACGCGCTCGCGCTGCAGTACTACCGGACTCACACGGCGCAGATCGAGATCGTCCGCACGGACAGGAGCATGGAGCAGATCGTGTTCCCGATCCCGGAGATGTGCGAGTACCTGCCGGCCGACAGTAAGCACAGGGTGCTGCAGAGCGCCGAGCGCGACGACCAGGGCAGCAAGGTCGCGGACTTCTTCGCGAGGCTCGACCACCTCTTCCACGAAATGAAGTGGCAGAAGAAATTACGAGGACAACCTCTTCTGTTCTGGGTTTCATCTTACATGTCGCTGTGGAGTAACATATTGTTCAACTTCGCCGTTCTGATCAACGTCATCGTGGCCTTCTTCTACCCGTTTTCAGACGAGAACCCTCGTCTGGGCCAGCACGTGTCGCTGGCGGTGTGGGCGGCGAGTGGCGCGGCGGGCGCGCTGGTGGCGTGGGTGCCGCGGGGCGCGGGGGTGCGCGCGCTGCTCGCCTGCGCCATAGTGCGCGTGCTCTGCTCCGCCGGCCCCGAACCCACGCTCTGGGCGTTGGCTATGCTCACGATAATAGTAAAAGGTATCCATCTAGTCAGCATAATGGGTAACCAGGGTACGCTGTCCAAGTCGACGCGCAACGTCCTCACCGACCCTGAGCTCCTCTACCACACCGTCTACTTGTTGTTCTGCTTTCTCGGGATATGCTGCCACCCGTTCTTCTTTTCTGTCCTATTGCTGGACATCGTGTACCGAGAAGAGACGCTGCTTAACGTGATGCGGTCAGTGACTCGCAACGGGCGGTCCATCCTCCTGACGGCCGTGCTGGCGCTTGTCCTGGTCTACATGTTCTCCATCGTAGGCTACATGTTCTTCAGAGACCACTTCCTGGTCAACGTCGATCGGTTGGACGACGACGACGACCCCCGCTTCGAGGCCGACAGCTGCGGGCGCGACCCCGCCGACAAGTACCGAGGGGCGGGCGGGTGCCGCGCGGCGCCGCGCCTGGTGTTGGTGGGGGGCGAGCTGCGGGAGCGGAGCTGCGACTCGCTGCTCATGTGCATCGTCACCACGCTCAACCAGGGCCTGCGCAACGGGGGAGGCATCGGGGACATCCTGCGGGCGCCGGCCAGCTTCGAGCCGCTGTTCGTGGCGCGCGTGGTGTACGACCTGTTGTTCTTCTTCGTGGTGATCATCATAGTTCTCAACTTGATATTCGGCGTGATCATCGACACGTTCGCGGACCTGCGTAGCGAGAAGCAGCAAAAGGAATTAATACTTAAGAGCACCTGTTTTATATGTGGGTTGAACAGGTCAGCCTTTGACAATAAGACAGTGTCCTTCGAGGAACATATAAAGAGTGAGCATAACATGTGGCACTACCTGTACTTCATGGTGCTCGTGAGGGTCAAGGACCCCACAGAGTTCACCGGCCCCGAGAGTTACGTGCACTCTATGATAAAGTCCAACAACTTGGACTGGTTTCCGAGACTGCGGGCGCTGTCCCTGATGGGCGGCGTCGAGGGCGAGGGTGGGGAGCTGGAGCTGCGCGCGCTGCAGGCCCAGCTGGACCGCGCGCACCGCGCCGTGGCCACGCTCACCGAACTGCTCACCGACCTCAGGGACCAGATGACCGAGCAGCGGAAACAAAAGCAACGCATCGGCTTACTGAACTCGACCTCGGCGTACCTCCAGAACTTGCAATTGAACCTGCCACCGTGA
Protein
MGVVAWWGRGEGKRMGDSFLHLGDIVSLYAEGTVAGFLSTLGLVDDRCVVCPEAGDLTDPPKKFRDCLFKICPMNRYSAQKQFWNTAKQSANPNADTGLLKRLHHAAEIEKKQNDLENKKLLGTVVQYGSVIQLLHVKSNKYLTVNKRLPALLEKNAMRVHLDANGNEGSWFYVMPFYKLRSTGDNVVVGDKVIMNPVNAGQQVLHVSSNHELPDNAGCMEVNVVNSSTSWKVTLFLEHKENQEEILKGGDVVRLFHAEQEKFLTMDEYQKRQHVFLRTTGRSSATAATSSKALWEIEVVQHDPCRGGAGHWNSIFRFKHLATGHYLAAEACNRPHDGPLEAGEPAYQLVPVPHSSEIATLFELDPTTMTHSDAPVPQSSYVRLQHLCTHTWVHSTSIPIDKDEEKPVMSKVGCSLVKEDKEAFALISVSPSEVRDLDFANDACKVLSALSTKLQQGTIEPNERKALTCLLQDIVYFIAGFENEPNKSEALDLVVENPHRDRQKLLREQYILRQLFKILQGPFQEPADGEPFLKIEELNDTRYAPYKNIFRLCYRILRLSQQDYRKNQEYIAKHFGFMQKQIGYDILAEDTITALLHNNRKLLEKHITASEIETFVGLVRKNMRTWQSRFLDYLSDLCISNKKAIAVTQELICKSVLCANNSDILIETRLVSIKYKEKGKMSDPDESKCSVEQRVMLFWNNKKNQRYLTDLAAEARLDPNSEAAAILDYYRHQLDLFSNMCLNRQYLALNTLSPQLHIDLILLCMSNSSLSYEVRASFCRLMLHLHADRDPQEPVTPVKYARLWTEVIDRIHIHDYQCVKGGPDANREKVKEQFARTIRFVEKYLCNVVSRTWYFSDHDQNKLTFEVVKLARELIYFGFYSFSDLLRLTKTLLSILDCVTAMDLLNETNALSGEVESEGGVLRSIGDMGAVMTSITLGSVARNQVGGTATTPGTGTGLQRSASALMLAREHPLVMDTKLKIIEILQFILDVRLDYRISCLLSIFKKEFEQAGDQRAADSLGRADVEAIGLQAEGIFSCRDGLDLDECGGRMVLRVLLQLCSQGASAALVSGALALLFRHFSQRQEVLAAFKQVQLLVSDADVESYKQIKADLDLLRQSVEKSELWVFNKGRAVLLDELAGVCRAYVTFCVCPSGAVGPGGAVLERNASLDNVLDTSRTAKHDHNEYKKIKEILQRMIKYCTHGNSGAGDCGRPRRHEQRLLRNIGVHNIVLDLLQVPHDEDDAAMDELLSLAHEFLQHFCHGNQQNQTILHKHLDLFLNAGIREAQTVCAIFKDNASLCGHEGNEKVVAHFVHCVESRGRKPDYLRFLQTIVHADKQYIRKSQDLVMQEMVNAGEDVLVFYNDKVSFNYFIQMMKQYKEKGEMPEALTYHIQLVKLLTCCTMGKNVYTEIKCHSLLPLDDIVSAITNPHCIPEVKEAYVGFLNHCYIDTEVEMKEIYSSNYMWDLFERSFLQDMHAILQSGAAWSDVPSSSHKPSTTSTHRAWVNYVTDVLMHTICTFFNSPFSDQSTTVQTRQSIFVKLLQTTFSIYQCPWLTPPQKLNVEKCIRTLSEVAKSRSIAIPLELEAKIQTVFEKAAALSRQTSKWLQASKTSKLEKMASQLNLQNDRSVMEGLQEIVSLLEEQLRPLLQAEQSLLVDILYKPHLLFTSPAQPDASGIFISRLIRHTEKLLEEKEEKLCVKVLRTLREMMAVDPEYGEKGNQLRNKLLSQYFVNRKSEPKVQPPPPPAPATHGPGAKVLMRTGQTLAQVQAHLDKEGASDLVVDLVIKSTNRPAIFLEAIQLGIALLEGGNPIIQQSIYTKLQNGEISQAFLKVFYDKMREAQQEIRSLAASSTTAAGADKQRAPHADAKKPLENGVKSSPGPLVVGEEMDEEVNSACGTAVHAYSDVHTISHGSTALEEIMCEKKRESSNSDVLPPKVAVMKPILRFLQLLCENHNPDLQNLLRNQNNKSNYNLVSETLMFLDCICGSTTGGLGLLGLYINEGNVSLINQTLETLTEYCQGPCHENQNCIATHESNGLDIITALILNDINPLGRTRMDLVLELKNNASKLLLAIMESRNDSENNAERILYNMNPKQLVDVACSAFHQEHGADSDSESEDDAPVQAVSPKEVGHNIYILCHQLAAHNKELAALVRASPAGPHALALQYYRTHTAQIEIVRTDRSMEQIVFPIPEMCEYLPADSKHRVLQSAERDDQGSKVADFFARLDHLFHEMKWQKKLRGQPLLFWVSSYMSLWSNILFNFAVLINVIVAFFYPFSDENPRLGQHVSLAVWAASGAAGALVAWVPRGAGVRALLACAIVRVLCSAGPEPTLWALAMLTIIVKGIHLVSIMGNQGTLSKSTRNVLTDPELLYHTVYLLFCFLGICCHPFFFSVLLLDIVYREETLLNVMRSVTRNGRSILLTAVLALVLVYMFSIVGYMFFRDHFLVNVDRLDDDDDPRFEADSCGRDPADKYRGAGGCRAAPRLVLVGGELRERSCDSLLMCIVTTLNQGLRNGGGIGDILRAPASFEPLFVARVVYDLLFFFVVIIIVLNLIFGVIIDTFADLRSEKQQKELILKSTCFICGLNRSAFDNKTVSFEEHIKSEHNMWHYLYFMVLVRVKDPTEFTGPESYVHSMIKSNNLDWFPRLRALSLMGGVEGEGGELELRALQAQLDRAHRAVATLTELLTDLRDQMTEQRKQKQRIGLLNSTSAYLQNLQLNLPP
Summary
Description
Receptor for inositol 1,4,5-trisphosphate, a second messenger that mediates the release of intracellular calcium (PubMed:1322910). Together with MCU, has a role in oxidative stress-induced ER-mitochondria calcium transfer (PubMed:28726639). May be involved in visual and olfactory transduction, and myoblast proliferation (PubMed:1322910). May be involved in ethanol tolerance (PubMed:29444420).
Receptor for inositol 1,4,5-trisphosphate, a second messenger that mediates the release of intracellular calcium. This release is regulated by cAMP both dependently and independently of PKA (By similarity).
Receptor for inositol 1,4,5-trisphosphate, a second messenger that mediates the release of intracellular calcium. This release is regulated by cAMP both dependently and independently of PKA (By similarity).
Subunit
Homotetramer.
Homotetramer. Interacts with CABP1 (PubMed:12032348). Interacts with BOK; regulates ITPR2 expression.
Homotetramer. Interacts with CABP1 (PubMed:12032348). Interacts with BOK; regulates ITPR2 expression.
Similarity
Belongs to the InsP3 receptor family.
Keywords
Alternative splicing
Calcium
Calcium channel
Calcium transport
Complete proteome
Developmental protein
Endoplasmic reticulum
Ion channel
Ion transport
Ligand-gated ion channel
Membrane
Olfaction
Phosphoprotein
Receptor
Reference proteome
Repeat
Sensory transduction
Transmembrane
Transmembrane helix
Transport
Vision
Polymorphism
Feature
chain Inositol 1,4,5-trisphosphate receptor
splice variant In isoform A.
splice variant In isoform A.
Uniprot
H9JV29
A0A3S2PDM3
A0A212FL15
A0A0N1IGP3
A0A0N1PF50
A0A097P7A8
+ More
A0A1B6EDM6 A0A1B6CLM5 A0A222AFM6 V9IA65 A0A1W4W984 A0A1W4WKF8 V9I9P7 V9I8A8 A0A1W4WJH4 A0A1W4WKP9 V9IAK4 A0A2A3ES56 A0A088A5K3 T1HK15 D6W7E2 A0A310SI82 A0A0L0CKU0 A0A2J7QR08 A0A0B4LGN1 B3P2E7 B4QWW9 P29993-2 P29993 B4PVB2 A0A1B0FD97 A0A147BQD7 A0A3B3QY67 A0A1W5A8G0 A0A3Q2EE34 A0A1W5AFB9 A0A1W5AFC4 A0A3Q1I0C3 A0A3B4WPP2 A0A3P8QSH9 A0A3Q3CHG1 A0A3B4EZY1 A0A1L8GPF1 A0A1L8GHJ0 A0A3P8SU81 A0A3Q1BXN9 Q91908 A0A3P9BR01 A0A3P8U0Q1 A0A1S3LB41 A0A3B5B4U3 A0A3Q1BHL7 A0A3B4UEJ4 A0A3Q4I9V8 A0A3Q3XN87 A0A2U9BG26 A0A3B4XIV1 A0A3Q3T285 H2TJZ1 A0A3Q3JRN7 A0A3Q3BBT2 A0A3B4E065 A0A096LQ05 A0A2U9BH53 A0A3B4CG39 A0A3P9JM70 A0A1S3P2Y3 A0A3Q4HW68 A0A1S3P2R8 A0A1A8EUD0 A0A1A7ZSM2 W5KHY9 A0A1S3P2N8 H2MBM2 F8W4B1 A0A3B4TQG1 A0A1S3P2X8 A0A2R8QHB5 A0A2R8QJM5 I3KSK9 A0A1S3P2Y1 A0A1S3P2R3 A0A1S3P2M9 A0A1S3P2X6 A0A1W5AGI2 A0A218UI34 A0A146VD63 M3YG40 A0A2Y9KZA0 Q6W3E4 M3W202 A0A3Q2H6V9 A0A1S2ZE43 R0JNL4 G1QZX2 A0A151MPL6 G1KLX9 P29995 H2NGU6 A0A3Q2H0L4
A0A1B6EDM6 A0A1B6CLM5 A0A222AFM6 V9IA65 A0A1W4W984 A0A1W4WKF8 V9I9P7 V9I8A8 A0A1W4WJH4 A0A1W4WKP9 V9IAK4 A0A2A3ES56 A0A088A5K3 T1HK15 D6W7E2 A0A310SI82 A0A0L0CKU0 A0A2J7QR08 A0A0B4LGN1 B3P2E7 B4QWW9 P29993-2 P29993 B4PVB2 A0A1B0FD97 A0A147BQD7 A0A3B3QY67 A0A1W5A8G0 A0A3Q2EE34 A0A1W5AFB9 A0A1W5AFC4 A0A3Q1I0C3 A0A3B4WPP2 A0A3P8QSH9 A0A3Q3CHG1 A0A3B4EZY1 A0A1L8GPF1 A0A1L8GHJ0 A0A3P8SU81 A0A3Q1BXN9 Q91908 A0A3P9BR01 A0A3P8U0Q1 A0A1S3LB41 A0A3B5B4U3 A0A3Q1BHL7 A0A3B4UEJ4 A0A3Q4I9V8 A0A3Q3XN87 A0A2U9BG26 A0A3B4XIV1 A0A3Q3T285 H2TJZ1 A0A3Q3JRN7 A0A3Q3BBT2 A0A3B4E065 A0A096LQ05 A0A2U9BH53 A0A3B4CG39 A0A3P9JM70 A0A1S3P2Y3 A0A3Q4HW68 A0A1S3P2R8 A0A1A8EUD0 A0A1A7ZSM2 W5KHY9 A0A1S3P2N8 H2MBM2 F8W4B1 A0A3B4TQG1 A0A1S3P2X8 A0A2R8QHB5 A0A2R8QJM5 I3KSK9 A0A1S3P2Y1 A0A1S3P2R3 A0A1S3P2M9 A0A1S3P2X6 A0A1W5AGI2 A0A218UI34 A0A146VD63 M3YG40 A0A2Y9KZA0 Q6W3E4 M3W202 A0A3Q2H6V9 A0A1S2ZE43 R0JNL4 G1QZX2 A0A151MPL6 G1KLX9 P29995 H2NGU6 A0A3Q2H0L4
Pubmed
19121390
22118469
26354079
25330781
18362917
19820115
+ More
26108605 10731132 12537568 12537572 12537573 12537574 16110336 17569856 17569867 17994087 1322910 10375644 1338312 28726639 29444420 17550304 29652888 29240929 27762356 8387895 25186727 21551351 17554307 25329095 23594743 17975172 19892987 22293439 1655411 12032348 23884412
26108605 10731132 12537568 12537572 12537573 12537574 16110336 17569856 17569867 17994087 1322910 10375644 1338312 28726639 29444420 17550304 29652888 29240929 27762356 8387895 25186727 21551351 17554307 25329095 23594743 17975172 19892987 22293439 1655411 12032348 23884412
EMBL
BABH01026287
BABH01026288
BABH01026289
BABH01026290
BABH01026291
RSAL01000085
+ More
RVE48356.1 AGBW02007905 OWR54438.1 KQ459933 KPJ19289.1 KQ458883 KPJ04581.1 KM216387 AIU40167.1 GEDC01001277 JAS36021.1 GEDC01023107 JAS14191.1 KY290442 ASO75059.1 JR036746 AEY57366.1 JR036747 AEY57367.1 JR036743 AEY57363.1 JR036744 AEY57364.1 KZ288189 PBC34595.1 ACPB03006495 ACPB03006496 KQ971307 EFA11212.2 KQ767803 OAD53290.1 JRES01000249 KNC32983.1 NEVH01012081 PNF31015.1 AE014297 AHN57179.1 CH954181 EDV47897.1 CM000364 EDX11731.1 D90403 AJ238949 Z18535 CM000160 EDW95781.2 CCAG010014354 GEGO01002672 JAR92732.1 CM004472 OCT85738.1 CM004473 OCT83302.1 D14400 BAA03304.1 CP026248 AWP02975.1 AYCK01011154 AYCK01011155 AYCK01011156 AWP03365.1 HAEB01004223 SBQ50750.1 HADY01007284 SBP45769.1 BX957338 BX548005 AERX01006755 AERX01006756 AERX01006757 MUZQ01000306 OWK53070.1 GCES01071085 JAR15238.1 AEYP01089101 AEYP01089102 AEYP01089103 AEYP01089104 AEYP01089105 AEYP01089106 AEYP01089107 AEYP01089108 AEYP01089109 AEYP01089110 AY313846 AAQ82910.1 AANG04001751 KB743435 EOA98746.1 ADFV01029449 ADFV01029450 ADFV01029451 ADFV01029452 ADFV01029453 ADFV01029454 ADFV01029455 ADFV01029456 ADFV01029457 ADFV01029458 AKHW03005564 KYO26340.1 X61677 AF329470 ABGA01014346 ABGA01014347 ABGA01014348 ABGA01014349 ABGA01014350 ABGA01014351 ABGA01014352 ABGA01014353 ABGA01014354 ABGA01014355 NDHI03003395 PNJ67165.1
RVE48356.1 AGBW02007905 OWR54438.1 KQ459933 KPJ19289.1 KQ458883 KPJ04581.1 KM216387 AIU40167.1 GEDC01001277 JAS36021.1 GEDC01023107 JAS14191.1 KY290442 ASO75059.1 JR036746 AEY57366.1 JR036747 AEY57367.1 JR036743 AEY57363.1 JR036744 AEY57364.1 KZ288189 PBC34595.1 ACPB03006495 ACPB03006496 KQ971307 EFA11212.2 KQ767803 OAD53290.1 JRES01000249 KNC32983.1 NEVH01012081 PNF31015.1 AE014297 AHN57179.1 CH954181 EDV47897.1 CM000364 EDX11731.1 D90403 AJ238949 Z18535 CM000160 EDW95781.2 CCAG010014354 GEGO01002672 JAR92732.1 CM004472 OCT85738.1 CM004473 OCT83302.1 D14400 BAA03304.1 CP026248 AWP02975.1 AYCK01011154 AYCK01011155 AYCK01011156 AWP03365.1 HAEB01004223 SBQ50750.1 HADY01007284 SBP45769.1 BX957338 BX548005 AERX01006755 AERX01006756 AERX01006757 MUZQ01000306 OWK53070.1 GCES01071085 JAR15238.1 AEYP01089101 AEYP01089102 AEYP01089103 AEYP01089104 AEYP01089105 AEYP01089106 AEYP01089107 AEYP01089108 AEYP01089109 AEYP01089110 AY313846 AAQ82910.1 AANG04001751 KB743435 EOA98746.1 ADFV01029449 ADFV01029450 ADFV01029451 ADFV01029452 ADFV01029453 ADFV01029454 ADFV01029455 ADFV01029456 ADFV01029457 ADFV01029458 AKHW03005564 KYO26340.1 X61677 AF329470 ABGA01014346 ABGA01014347 ABGA01014348 ABGA01014349 ABGA01014350 ABGA01014351 ABGA01014352 ABGA01014353 ABGA01014354 ABGA01014355 NDHI03003395 PNJ67165.1
Proteomes
UP000005204
UP000283053
UP000007151
UP000053240
UP000053268
UP000192223
+ More
UP000242457 UP000005203 UP000015103 UP000007266 UP000037069 UP000235965 UP000000803 UP000008711 UP000000304 UP000002282 UP000092444 UP000261540 UP000192224 UP000265020 UP000265040 UP000261360 UP000265100 UP000264840 UP000261460 UP000186698 UP000265080 UP000257160 UP000265160 UP000087266 UP000261400 UP000261420 UP000261580 UP000261620 UP000246464 UP000261640 UP000005226 UP000261600 UP000264800 UP000261440 UP000028760 UP000265200 UP000018467 UP000001038 UP000000437 UP000005207 UP000197619 UP000000715 UP000248482 UP000011712 UP000002281 UP000079721 UP000001073 UP000050525 UP000001646 UP000002494 UP000001595
UP000242457 UP000005203 UP000015103 UP000007266 UP000037069 UP000235965 UP000000803 UP000008711 UP000000304 UP000002282 UP000092444 UP000261540 UP000192224 UP000265020 UP000265040 UP000261360 UP000265100 UP000264840 UP000261460 UP000186698 UP000265080 UP000257160 UP000265160 UP000087266 UP000261400 UP000261420 UP000261580 UP000261620 UP000246464 UP000261640 UP000005226 UP000261600 UP000264800 UP000261440 UP000028760 UP000265200 UP000018467 UP000001038 UP000000437 UP000005207 UP000197619 UP000000715 UP000248482 UP000011712 UP000002281 UP000079721 UP000001073 UP000050525 UP000001646 UP000002494 UP000001595
Pfam
Interpro
IPR000493
InsP3_rcpt
+ More
IPR016093 MIR_motif
IPR005821 Ion_trans_dom
IPR035910 RyR/IP3R_RIH_dom_sf
IPR014821 Ins145_P3_rcpt
IPR000699 RIH_dom
IPR013662 RIH_assoc-dom
IPR036300 MIR_dom_sf
IPR001254 Trypsin_dom
IPR018114 TRYPSIN_HIS
IPR009003 Peptidase_S1_PA
IPR033116 TRYPSIN_SER
IPR016024 ARM-type_fold
IPR016093 MIR_motif
IPR005821 Ion_trans_dom
IPR035910 RyR/IP3R_RIH_dom_sf
IPR014821 Ins145_P3_rcpt
IPR000699 RIH_dom
IPR013662 RIH_assoc-dom
IPR036300 MIR_dom_sf
IPR001254 Trypsin_dom
IPR018114 TRYPSIN_HIS
IPR009003 Peptidase_S1_PA
IPR033116 TRYPSIN_SER
IPR016024 ARM-type_fold
CDD
ProteinModelPortal
H9JV29
A0A3S2PDM3
A0A212FL15
A0A0N1IGP3
A0A0N1PF50
A0A097P7A8
+ More
A0A1B6EDM6 A0A1B6CLM5 A0A222AFM6 V9IA65 A0A1W4W984 A0A1W4WKF8 V9I9P7 V9I8A8 A0A1W4WJH4 A0A1W4WKP9 V9IAK4 A0A2A3ES56 A0A088A5K3 T1HK15 D6W7E2 A0A310SI82 A0A0L0CKU0 A0A2J7QR08 A0A0B4LGN1 B3P2E7 B4QWW9 P29993-2 P29993 B4PVB2 A0A1B0FD97 A0A147BQD7 A0A3B3QY67 A0A1W5A8G0 A0A3Q2EE34 A0A1W5AFB9 A0A1W5AFC4 A0A3Q1I0C3 A0A3B4WPP2 A0A3P8QSH9 A0A3Q3CHG1 A0A3B4EZY1 A0A1L8GPF1 A0A1L8GHJ0 A0A3P8SU81 A0A3Q1BXN9 Q91908 A0A3P9BR01 A0A3P8U0Q1 A0A1S3LB41 A0A3B5B4U3 A0A3Q1BHL7 A0A3B4UEJ4 A0A3Q4I9V8 A0A3Q3XN87 A0A2U9BG26 A0A3B4XIV1 A0A3Q3T285 H2TJZ1 A0A3Q3JRN7 A0A3Q3BBT2 A0A3B4E065 A0A096LQ05 A0A2U9BH53 A0A3B4CG39 A0A3P9JM70 A0A1S3P2Y3 A0A3Q4HW68 A0A1S3P2R8 A0A1A8EUD0 A0A1A7ZSM2 W5KHY9 A0A1S3P2N8 H2MBM2 F8W4B1 A0A3B4TQG1 A0A1S3P2X8 A0A2R8QHB5 A0A2R8QJM5 I3KSK9 A0A1S3P2Y1 A0A1S3P2R3 A0A1S3P2M9 A0A1S3P2X6 A0A1W5AGI2 A0A218UI34 A0A146VD63 M3YG40 A0A2Y9KZA0 Q6W3E4 M3W202 A0A3Q2H6V9 A0A1S2ZE43 R0JNL4 G1QZX2 A0A151MPL6 G1KLX9 P29995 H2NGU6 A0A3Q2H0L4
A0A1B6EDM6 A0A1B6CLM5 A0A222AFM6 V9IA65 A0A1W4W984 A0A1W4WKF8 V9I9P7 V9I8A8 A0A1W4WJH4 A0A1W4WKP9 V9IAK4 A0A2A3ES56 A0A088A5K3 T1HK15 D6W7E2 A0A310SI82 A0A0L0CKU0 A0A2J7QR08 A0A0B4LGN1 B3P2E7 B4QWW9 P29993-2 P29993 B4PVB2 A0A1B0FD97 A0A147BQD7 A0A3B3QY67 A0A1W5A8G0 A0A3Q2EE34 A0A1W5AFB9 A0A1W5AFC4 A0A3Q1I0C3 A0A3B4WPP2 A0A3P8QSH9 A0A3Q3CHG1 A0A3B4EZY1 A0A1L8GPF1 A0A1L8GHJ0 A0A3P8SU81 A0A3Q1BXN9 Q91908 A0A3P9BR01 A0A3P8U0Q1 A0A1S3LB41 A0A3B5B4U3 A0A3Q1BHL7 A0A3B4UEJ4 A0A3Q4I9V8 A0A3Q3XN87 A0A2U9BG26 A0A3B4XIV1 A0A3Q3T285 H2TJZ1 A0A3Q3JRN7 A0A3Q3BBT2 A0A3B4E065 A0A096LQ05 A0A2U9BH53 A0A3B4CG39 A0A3P9JM70 A0A1S3P2Y3 A0A3Q4HW68 A0A1S3P2R8 A0A1A8EUD0 A0A1A7ZSM2 W5KHY9 A0A1S3P2N8 H2MBM2 F8W4B1 A0A3B4TQG1 A0A1S3P2X8 A0A2R8QHB5 A0A2R8QJM5 I3KSK9 A0A1S3P2Y1 A0A1S3P2R3 A0A1S3P2M9 A0A1S3P2X6 A0A1W5AGI2 A0A218UI34 A0A146VD63 M3YG40 A0A2Y9KZA0 Q6W3E4 M3W202 A0A3Q2H6V9 A0A1S2ZE43 R0JNL4 G1QZX2 A0A151MPL6 G1KLX9 P29995 H2NGU6 A0A3Q2H0L4
PDB
6MU1
E-value=0,
Score=6993
Ontologies
PATHWAY
GO
GO:0016021
GO:0005783
GO:0070679
GO:0005220
GO:0004252
GO:0070588
GO:0051209
GO:0055089
GO:0005789
GO:0030322
GO:0042594
GO:0046000
GO:0051482
GO:0000280
GO:0007629
GO:0035071
GO:0009267
GO:0044295
GO:0006874
GO:0060259
GO:0030536
GO:0016319
GO:0005790
GO:0071361
GO:0050909
GO:0006979
GO:0007608
GO:0055088
GO:0007601
GO:0007591
GO:0006816
GO:0010888
GO:0016020
GO:0044325
GO:0071320
GO:0005634
GO:0005938
GO:0001666
GO:0033017
GO:0097110
GO:0005886
GO:0035091
GO:0043235
GO:0016529
GO:0005509
GO:0030667
GO:0030659
GO:0030424
GO:0071456
GO:0005737
GO:0043209
GO:0005262
GO:0005216
GO:0006811
GO:0000287
GO:0006281
GO:0006259
GO:0055085
Topology
Subcellular location
Endoplasmic reticulum membrane
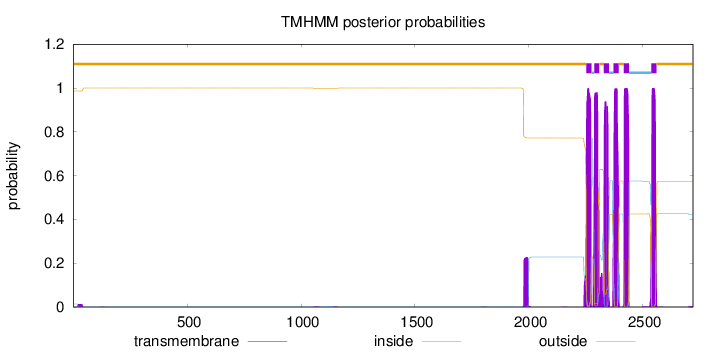
Length:
2721
Number of predicted TMHs:
6
Exp number of AAs in TMHs:
140.61187
Exp number, first 60 AAs:
0.30075
Total prob of N-in:
0.01375
outside
1 - 2252
TMhelix
2253 - 2275
inside
2276 - 2287
TMhelix
2288 - 2310
outside
2311 - 2329
TMhelix
2330 - 2352
inside
2353 - 2372
TMhelix
2373 - 2395
outside
2396 - 2417
TMhelix
2418 - 2440
inside
2441 - 2538
TMhelix
2539 - 2561
outside
2562 - 2721
Population Genetic Test Statistics
Pi
243.894192
Theta
165.102653
Tajima's D
1.384527
CLR
0.134645
CSRT
0.755462226888656
Interpretation
Uncertain
