Gene
KWMTBOMO15892 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA013342
Annotation
apolipophorin_precursor_protein_[Bombyx_mori]
Full name
Apolipophorins
+ More
Vitellogenin
Apolipoprotein B-100
Vitellogenin
Apolipoprotein B-100
Alternative Name
Retinoid- and fatty acid-binding glycoprotein
Location in the cell
Cytoplasmic Reliability : 1.793 Nuclear Reliability : 1.658
Sequence
CDS
ATGCTCGTTGGCGTGCAAAGGATCACCTGCCGGCCCAACCTTTCAAGCTGGGCAGACGAGACCGGCGTCAAGCTTTTAGGTCAGGTTTCAGTGACAGCACTGGATAACTGCAACTACCAGTTGGATGTGCAAAAGCTGAGCATCTCTGGGCCTGATGGAAAGAAATACGAGAGCCCATCCGGTATCAAAAAACCGGTCAAGTTCGGTTACCAAGACGGCAAGATCCAGCCACAGATCTGCGCGGAGGAAGACGACACACGCCAATCGTTGAACATTAAAAGAGCCATCATCTCGTTGCTGCAGAATGAACAAAAACCATCAACACAGGTGGACGTGTTTGGGATTTGTCCGACTGAAGTGTCGACCTCACACGAAGGCGGAGCAGTTATTGTGCACCGCAGCCGCGACCTGTCCCGGTGCTCCCATCGAGAACAGGGCAAATCTGACATCATCATTTCCAACGTCAATCCTAATGCCGGCGTTAAGGATATGCAAGTCCTTCAGTCGACGCTGAACGTAGAGTCCAAGGTTATTAACGGTGTACCAGAGAAGGTGGCCGCCACTGAAGAATATCTTTACAAGCCTTTCTCCATTGGAGAGAACGGAGCTAGAGCTAAAGTTCACACCAAGTTAACTTTAACTGGCAAAGGAAAAGCTGTCGCTCCTTCGAGCAAATGCACTGACGTTAACAGCATTATCTTCGAGAACCCTCACAGTGGAGAGAAAGTCCCTAAGAACGACCACGCTTGTCTCGGAGCAGTTAAAGAAGTTGCCAAGAGTGTTACCAATAACGTCGGAGCAAACTCAGCATCGAGTTTTGCTCAATTAGTCAGAATCTTGCGTAGAACCGAAAAGGAAGATCTGGTGAAAGTTTTCAACCAAGTCAAAGGGAATACTTTAGAAAAACGCGTGTTCCTTGATGCCCTACTCCGCGCTGGTACCGGCGATAGCATCGAAGCATCCATCCTGATTCTAAAGACTAGACAACTGTCGCAACTAGAACAGCAGCTGGTCTTCTTGTCTCTCGGGAACGCAAGACACGTCAACAACGATGCCCTAAAAGCTGCTGCGGGTCTTTTGGATCTACCGAACTTACCAAAAGACGTCTACCTTGGTGCTGGAGCTCTCGCTGGTGCGTACTGCCGTGAACATGAATGCCATAGCTCGAAGGCTGACGGAGTAGTGGCTATTAGCCAGAAATTCGGCTCCAAACTCCACTGCAAGCCTAAGAGTAAAACAGAAGAAGATACAGTCGTGGCCGTGCTTAAAGGTATCCGCAATATTAGACACTTGGAGAATTCTTTGATTGAGAAGCTGGTACGGTGTGTCAATGACAACAATGTCAAACCAAGGATTCGGGCTGCGGTCCTCGAAGCGTTCCATGCTGACCCTTGCAGTCCAAAGGTCAAGAAAATTTCTCTGGACATTTTGAAGAACCGTCAACTCGACTCAGAGATTCGTATCAAGGCTTATTTGGCTGTGATCGAATGTCCTTGCGGCCATTCAGCTAACGAGATCAAGAACTTGCTTGACAACGAGCCGGTCCACCAAGTTGGCAATTTTATTTCGTCGTCACTCCGTCACATCAGATCCTCGGCTAATCCTGACAAACGCCTTGCGCGCGAGCACTACGGTCTCATCCGTACTCCAAAGAAGTTCAACTCTGATGACAGAAAGTACTCCTTCTACCGGGAGATGTCGTATAACATAGACGCTCTTGGTGCCGGTGGAAGCGTCGACGAAACAGTAATATACTCCCAAGACTCGTACCTACCAAGATCAGTCAACTTTAACTTAACAGTTTCGTTATTCGGTCACGACTTCAATGTCTTGGAGTTTGGAGGTCGCCAAGGTAACTTGGACCGCGTTCTTGAACATTTCTTGGGTCCCAAGAGCTTCCTGCGTACGGAAAGCCCTCAAGCTATTTACGATAGTCTGGTCAAGAGGTTCGAAGAAGCTAAGAAGAAGGTGGAAGATGGACTAACGAGAGGACGTAGATCTGTCAAGACGGAAATTGATTCGTTTGACAAAAATCTCAAAGCGGAAGCAGCTCCATACAACAATGAGTTGGATCTGGACATTTTCGTGAAACTGTTCGGTACTGACGCCGTCTTCTTATCCTTCGGTGACGACAAAGGATTCGACTTCAATAAGATCCTGGATGATATCCTTGGCACGTGTAGCAGTGGTATTAGCAAGCTAAAGCATTTCCAGACTGATTTCCGGACTCATCTCTTATTCCTCGACGCTGAACTAGCATACCCAACTTCAACTGGTCTTCCTCTCCACCTCAACTTGGTTGGTTCGGCCACTGCCAAATTAGATCTGGCCACTAACATCGATGTACGTCAAATCATATACTCCCCACAAAACGCCAAAATTGACGTCAAATTCATTCCTAGCACTGACCTAGAGATCGCAGGAGCGTTTTTGGTAGACGCTTACGCTGTCACTACTGGACTAAAAGTTTCGACTACATTGCGTTCTTCAACCGGGGTCCATGTCATAGCAAAAATTTTGGAAAATGGTCGTGGATTCGATTTGCAACTGGCCCTGCCTGTCGACAAGCAAGAGCTTCTAGTTGCCTCCAACGATCTGCTTTACGTAACCGCCGAGAGGGGACAGAACGAGAAATATGTTCCTATTAAAATAGGAACAGCCCCGAAGGAATATCCAGCCTGTTTCGATCAACTTTCAAGCGTTCTTGGACTCACACTTTGCACTGAATTCACAACACCATTCGCTATTTCAAAAGACACACGAGGGCCTAGCGACGACTCCATCGCGCAGTTCCTGGCTCGGTTCCCGCTTTCCGGTTCTGCTAAGGTTAAGGTGGTCTTAGAGAAGAATGATCTTCGTGGATATCACATCAAGGGTGTCGTAAGAGAAGACAAAGGCGCTGGTAAACGCAGCTTCGAATTGCTTTTCGATGCCGAAGGATCTCGAAATCGTCGCACACAATTAACCGGAGAGGTAGTCTACAACGACCACGAGGTTGGCCTGCAAATAGCTCTAGACTCACCAATTAAGGTCCTGCATGCTCAAATCTCGGCTTACAACAAGCCCAACGAGATGGTCGCCTTAGTTAAGGCCAAAATCGATAATCTGGAGTACTACGCTAAGGCCGGATTCGCTGTTCAAGGCAATGCCCAACGCAGCATCTACAAACCAATTTTAGAGTACCAATTGGCAGAAGATGGAGGTAAAAAGCATGAGATCAAAGTTGATGGTCAAATGGTCAAGGAATCCAACGGGCAAATCACTCGGTACAGCTTAGAAGGAGTACAGATTAATCTACCGAATACTGAGGAGCCTTTACAGATAACTGGTCATGCAGCCAACCAGCCTCAGACAAGGGAATTCGACTTTGATGTAGCTGTTAAGAATTTCGCGTCTCTCAAAGGTGGAGTTAAGGGAACTAATATCAATCTGGAGTTTGAGAACAAACTAAATCCCGTCATCAACTTCAAGCTCAAAGGAATTTTCGAGTTTACCGATACGATTCACAACGAAATTGACTTGCAATACGGACCAAACTTTAAAGACCCCAACTCGAGGATATTCTTATCTCAGCTGCTGAAGTACCACATTAAATCAGCTGAAGACTTCAATATTATCACCAAAAATAAGTTTGAAATCCGCGCTATTCCATTCAAAATTGTAGCCGAAGCAGATATAGACCCTAAAAAGGTGATTGTGGAAATAGGGGGACAAGTCGAGCAGCGAAGCGCTGCGTTTGAACTTGAAGCTAGAACTCAAATAGAGAAACCAGGAGATTACAGTGTAAAAATTAAAGGAAATGTCGACAAATTCTGTGTCGAGGTTTTAGCCAAAAGAAATATACTAAATGCTGATAAATCCAACCTAGAAAACTACGTTGATATCAAAGGTTATGGAAGATACGAACTGTCCGGTGTGCTTTTACATAAGAATAAACCAAACGATGTGAATCTTGGAGCTATAGGTCACCTCAAAATCAGCAGCAGTGGAAAGAGTGATGATATTAAATTCGATGTTGGCGTGGTAGAGAATACTCATTTTTACTCGTCGCACGCCGTTATCTCTAATTCCAAGGGTACTCTATTGGATTACCTATTGAAGATCAGCAGAGGGGGTACCCCAAGTGGCCAATTGAAATTCGTCCTGAAAGACACAATCGCTGCTAACGGAGAATACAAAGTTACAGGAAACGATGGAAAAGGCAACGGAGTTGTCATTGTCGATTTTAAAACGTTACAACGCAAATTTAAAGCTGATGTAAGCTTTTTGGCGAAGGAACCCGTGTTTAATGCAAACATCGACTTATATTTGGACTTTGACAAGAACAAAAATGACAAAATCTGTTTCTCTACGAATACCAAGAAAACCGATAAACTACTGGAATCCAAAAACAAATTGGAATACGGCGGAAAGAACTTCGAACTAAATATCCATTTGGAAGGTAATTTCGATTTAACCGGAGCAACTCGTGCCAAAGTGGAAATCGTTCTGCCAAATGAAAGGTGTCTGTCTTATGAAGTTAATCGCAATATAGCCGTCAACAATGCCGGGCTCTATAACGGCTTCGCCAAAGTACTGATCTCGGATGAAGAGAAACGTGGAGCGGCCGCTTCTACGATCAAATACGAAGCTAAAATACGCGACACGAACATCGAAAAGCAAATCATCAGCTATGAGGGTCAACTGGAATTCCAATTTAAGAATAAAGGTCAAAGTAAAGACCTTAAAAATACATTCACCCTTAGGAACTTCCCCGATGGAGACAAGTTATACAATTTCGACTTCAAGACTGACGTCCGAGGCAACTTGATCCCGAAGCCAGCGTCTTTGGTGGCAAGCGTGACTTATGCCAATTCAGTGAGCGTTCTCGATGATAAATACAGGTTCAAGGGTAACTATGGTGATGATATCTCGTTCGAGCTCGCTGGTGTACGGGAGATCAAACTTATTGAAAAGGGCGAGAAGAAATTCAATGATAATTTCATATTAACTGTAATATTGCCATTCGAAAAAGCTCACGATATTAAATGGGTTTCTACGATATTCTTCCTCCAGCCTGAAGGCAAAGATTTTGCTGAGTACACGCTGGTAGAATCTGTGCAGATTAATGCAGATCTATACAAAATCGACGTGAATGGCAAGAAAAGTCTTAAGGATGGAACTGGAACCATCAAGTTCTTAGTCCCTCATGTTGATCCATTCATATTGGAGTATAAATACAAGAATGGACTTGAAGGGGAGAAAAAGAGCCACGAAGTCGAAGCGAAAGCGAAATATGGTAAAGGCAAAAGCGCTACAATATCCTTGGATACTGCGTTCTCGCCACACGAAAACTATCTCCAGTTCAAAGGGCAAGCTCCCCAAGCCGAGAACCTGAAGAAACTGGAGTTCACTATAAACTCCAAGAATCCGTCTCCGGACTCATACAGTAGCACGCTCATCGTAGATGCTGATGGAAGGGTCTACAAATTGGAGAACAATGTAGTACTATCTAAGGCCCATCCAGTATTGGACCTCAAATACTCCAGTCCAAGCTCGAACAGACCAAGAAAGATTTTCATCAAGGGCACCTCTCTTAGTTCTACTCAAGGCAAAATCGAAGTGAACCTACAGGATATCAACGGCATTTGCCTTGATGCCGTTTCTGAAGGAAACATCCAGAAGGACAACATTGCCATTAAATTCCAGGGTAACTCCAAGGAATTGGGCATGAAAAACTATATCGTCGAGATCAGCAGTAAAGACGCTGGTAGTGGAAAGAGATTGGAATTCCATGCGACTAATGACAACAAGAACGTATTGAGTGGAAGTACCTCGTTCATTAGCAAACAAGAAGGCCAAGGAACTATCATAGAAGGTTCTGGAACTGTCAAAGTTAAGGAAGAACAGAAATCGGCTAACTTCAAGTACATTCGCACCGTTCTGACCGAGGGCAACGAGAAGGGAGTGGAGACATTCTTGAAGCTGAGCCTCGGTGATAGGAGCTACGCGGCTGAATCCCGGGTCACGAACCTGGAGTACAAGAACTCTTACATTTACTGCGAGGAGAAAAAGCAGTGCGCGGCCATTGAGATCCAATCCAAGATTGATTTGTCGAAACCCGGAGTCATCGTCAACGTGGTTAACGCCGGATTCGATCTTCGTACGCTTGGTATCTTACCTGAAATTGGCTTCCAAATGCGTGACGAGGTCTCCGACAATCGCTTCCCGAGATTCACCTTAGATCTTCACGTCAACACCAAGGAGAAGAAGTACCATCTCAACGCTTATAATACACCTGAGTTCGGAAACTATGCTTCGGGAGTCGTTTTCTATCTTCCGTCCAGGGTTATGGCTCTAGAGACCACTGTAACGTACCCAACCAGCAGTGACTCTCCGTATATATTCAGCGGAGAGGCCTGCCTCGACCTGGATAAGAAGAAACAGGGACACAAGACCTCTGTTAGATACCTCATCAACATCTCCAATAATAGGAATCAGGAAGCTATTGCAGCCGAAATCGGATTCTTCCACCCAAGACTTGATAAGGAGGTAGTCATCAAGTCGAACGCAGTCTTCAAGGTCCCGGAACCAAATCGATATATTCTCGAATCATCAGTCAGCCTATGTCACTCCTCTCTCGGCGCTGATCGCGTCTCCAAACTGTTGTTAGATGTTTCACCAACCAAATTCGTTTTCTTGGCCCAAACACCATTTGTAAAGGTTATAGACTTAGAAGGAACAGTGGACGTGCAAAGCAAGGCGAAGACCCAGCAGGCCAAGTTGAGGTTCAAGCTTCTAGAGGGCAAGGAGGTCAGCGTCCAGGCTCTGGCGAAAGACTTCCAGTATTTCGAGTTCACAACAGGTTATCTTGAAGAGGCAGACCGCAAGCTCTCTATCGTCGGTCATTTGGTCCCGGAAAAGAGAGTAGATATAACCGCTGATATCATCCTATCTGGTGACAAGAAAAACATCGCCCACGGGGCACTTTTCCTGCAAGATAACCTGGTCAAAAGCGACTACGGACTATCGAAAGAAAACTTCAACTATTTCTTGAACGCTCTGAAAAACGACCTAGACACATTAGCTGAGCGCATCAAAGAAAAAAGTGAAAAGGCCGGCCAGGAAATTTCAACGATATCCCAAAAAACAGCTCCTTACTTCAAGAAAATCGATGAAGACTTCCGCAGAGAATGGAGCAAGTTTTACCAGGAAGTCACTGATGATAAGACCCTGAAGGAACTATCGCATGCTTTCAACGAAATAGTCCAGTTCTTCGCTAAGATATTCGACACCATCTACAAAGGTACTGAGCCGATTGTGGATAGCATCATTAACACGTACGTCGAGACAGTGAAGAAGATTGCGGAATTATATGAGAAACAGCTGGAACCTCAAGTGAGACAGTTATACGAAACCTTGGCGGCCTTACTCAAGGAGTATTTAGATGGCTTGATCGACCTCGTGGCGCACTTCGCGGCTCTGATCACAGATTTCTTCGAAAAACACAAGCCTGAACTGCAGGAGTTCACGAATGTGATCACCGATATATTCAAAGATCTAACCCGAATAATTGTCGCTCAAGTAAAGGAACTTCCTTCTCTAATAGCGCAGAGCTACAGAAACATTGTCGAACAAATCAGCGCGCTGCCTATATTGTCTAATTTGAAAGAGAAGTGGAACGATCTGGTAGTTCCCGAGAAGATTCTAGAAGTGACCCAGATACTGTACAGCAATATCCAGAAACTGTTGCCAACGCAGGAAAGCAGAGATCTGGCCGAAGCGATCCACTCCTACGTTCAGAAGAAACTCCGTAACCAGAAATGCGATGATGAGAAGGAGCTGCGTGTGGTCTATCAGAAGTTGATCACAGCTGTTACATCTCTCGTCCAGTTCTTGAGGACTCAGCTGAACGAATTTGGCATTATCAACACGACGCCCGACTTTGCGAACTTCTTCGCTGCCCCAAGCTCAATTAAGTCCGCTCCGTCTCTTGCTGGAGAGGCAACGTGGAGCTTCTTCAAACAGTTGTACTCCGGTGATTTCCCTGACATCCTGGCCCTTCTCAGAGCCTACAGACCTCGTAGCATCAACCCACTAGATGAAGTGCCGTCTAAGCTCCGCGCTGTTGTTGTGAACGGTCAACACATCTTCACGTTCGACGGTCGCCACCTCACCTTCCCAGGAAACTGTCGCTACGTATTGGCGCACGACCACGTCGATAGAAACTTCACGCTGCTAATCCAACTTCAAAACGGAAAGCCCAAGGCTCTTATTTTGGAAGATAAGAGCGGAGCTATCATCGAATTGAAAGAAAATGGACAGGCTATTCTAAACGGAGCTTCCAAAGGATTCCCGATCATCGAAAAGGATGTGTTCGCTTTCCGTCAACCAAGCAACAGAATCGGTGTTGGCTCATTGTACGGTCTCATGGTCTTCTGCACATCTAAACTTGAGGTGTGCTACATTGAAGCTAACGGCTTCTACTTGGGTAAACTTCGCGGTCTTCTCGGAGACGGTAACAACGAGCCTTACGATGACTTCAGGCTACCTAATGGAAAGATCTGCACTTCGGAAAGCGAGTTCGGTAACGCGTACCGTCTGGCCCGCAGCTGTCCACAGGTGCAAGCGCCCGAACACTCCCATCACCAGCTGCACGATGCATCCCTCCCCCCCGCCTGCGAACAGGTCTTCGGGGGAATATCGCCGCTCAGGACCCTGTCATTGTTCATGGACATGTCGCCTTTCAGACAAGCGTGTATTCACGCCGTCACCGGCACAGACGCCGCTAAAGATTTGCACGAAGCTTGTGATTTGGGACGAGGAATGGCAGCTCTGGCCCTGACCGGCCTTCTCCCTGCCGTACTTCCGAACGTATGCGTCAAGTGTACTGATGCAGATAAGCCGAGGGACATCGGAGATAGCTATGAATTCAAAGTTCCCAACAAACAGGCTGATATTATCCTATCAGTTGAGACAACTGAATCCAATGCAAAGACTTACAAGGATATCGTGGTACCGCTCGTGTCACATTTGATTGACAGTCTAAAGAGTAAACACATTACTGACGTCAAAGTGTTCCTTGTAGGACACACCTCCAAATATCCATATCCGATCTTGTATGACACTGACCTCAAACTGAAAAACGCCCACGTACACTTCGACGACAAGGAACGCTACAATAACATCCCCACCATCAAGACTGGGTATGAATCCTTCGACAAATACGAGGACCAAATCATCAGTATCATCAATGACTTGAAGAACACATATGGATTCAACAACATCGAAGCCAGCAAGCAATCGTTGTTCGATCTTCCTGTCAGACCGGGTGCTATCAAACACTTGGTCTTCGCTATTGGTGAACCGTGTATCGGACGATGCTTCCTGCTCGACGCAATCGAGTCAGCCATTTACGATGTGATCTTCAAGAACATGGCGGTTACGACATCGCTGATCACGGCCACACCCGACCTCAAGATTGGAGGTGGAAAGAATTTGAATCAAGTCGTTGGATTCAGTGAGCATTCCGTCGTGCTGCTTGGCGAGAAGAAACAAACTAAAGATTCTGAAACTTTGAGAGGAACGCTCCAGAAGACAGACGATTCATGCGTGAACTTTGTTGAAGGCACCGGTGGCTACGTTTTCTCGTCGACCAACTTCGAGAAGTTGAATGCGCCACAGCAAAAGCAGTTCATCCAGACGGCCGCCAACACGATCACGCACAAGCTCCTCAGCGAACAGCTATCTCAGCTATGTACCTGCACCTACGTGGATCCGTTTAGGGTTCGCTCTGTCTGCGTAAACAAGGATAAGAAAGACGCTAGCTATTAA
Protein
MLVGVQRITCRPNLSSWADETGVKLLGQVSVTALDNCNYQLDVQKLSISGPDGKKYESPSGIKKPVKFGYQDGKIQPQICAEEDDTRQSLNIKRAIISLLQNEQKPSTQVDVFGICPTEVSTSHEGGAVIVHRSRDLSRCSHREQGKSDIIISNVNPNAGVKDMQVLQSTLNVESKVINGVPEKVAATEEYLYKPFSIGENGARAKVHTKLTLTGKGKAVAPSSKCTDVNSIIFENPHSGEKVPKNDHACLGAVKEVAKSVTNNVGANSASSFAQLVRILRRTEKEDLVKVFNQVKGNTLEKRVFLDALLRAGTGDSIEASILILKTRQLSQLEQQLVFLSLGNARHVNNDALKAAAGLLDLPNLPKDVYLGAGALAGAYCREHECHSSKADGVVAISQKFGSKLHCKPKSKTEEDTVVAVLKGIRNIRHLENSLIEKLVRCVNDNNVKPRIRAAVLEAFHADPCSPKVKKISLDILKNRQLDSEIRIKAYLAVIECPCGHSANEIKNLLDNEPVHQVGNFISSSLRHIRSSANPDKRLAREHYGLIRTPKKFNSDDRKYSFYREMSYNIDALGAGGSVDETVIYSQDSYLPRSVNFNLTVSLFGHDFNVLEFGGRQGNLDRVLEHFLGPKSFLRTESPQAIYDSLVKRFEEAKKKVEDGLTRGRRSVKTEIDSFDKNLKAEAAPYNNELDLDIFVKLFGTDAVFLSFGDDKGFDFNKILDDILGTCSSGISKLKHFQTDFRTHLLFLDAELAYPTSTGLPLHLNLVGSATAKLDLATNIDVRQIIYSPQNAKIDVKFIPSTDLEIAGAFLVDAYAVTTGLKVSTTLRSSTGVHVIAKILENGRGFDLQLALPVDKQELLVASNDLLYVTAERGQNEKYVPIKIGTAPKEYPACFDQLSSVLGLTLCTEFTTPFAISKDTRGPSDDSIAQFLARFPLSGSAKVKVVLEKNDLRGYHIKGVVREDKGAGKRSFELLFDAEGSRNRRTQLTGEVVYNDHEVGLQIALDSPIKVLHAQISAYNKPNEMVALVKAKIDNLEYYAKAGFAVQGNAQRSIYKPILEYQLAEDGGKKHEIKVDGQMVKESNGQITRYSLEGVQINLPNTEEPLQITGHAANQPQTREFDFDVAVKNFASLKGGVKGTNINLEFENKLNPVINFKLKGIFEFTDTIHNEIDLQYGPNFKDPNSRIFLSQLLKYHIKSAEDFNIITKNKFEIRAIPFKIVAEADIDPKKVIVEIGGQVEQRSAAFELEARTQIEKPGDYSVKIKGNVDKFCVEVLAKRNILNADKSNLENYVDIKGYGRYELSGVLLHKNKPNDVNLGAIGHLKISSSGKSDDIKFDVGVVENTHFYSSHAVISNSKGTLLDYLLKISRGGTPSGQLKFVLKDTIAANGEYKVTGNDGKGNGVVIVDFKTLQRKFKADVSFLAKEPVFNANIDLYLDFDKNKNDKICFSTNTKKTDKLLESKNKLEYGGKNFELNIHLEGNFDLTGATRAKVEIVLPNERCLSYEVNRNIAVNNAGLYNGFAKVLISDEEKRGAAASTIKYEAKIRDTNIEKQIISYEGQLEFQFKNKGQSKDLKNTFTLRNFPDGDKLYNFDFKTDVRGNLIPKPASLVASVTYANSVSVLDDKYRFKGNYGDDISFELAGVREIKLIEKGEKKFNDNFILTVILPFEKAHDIKWVSTIFFLQPEGKDFAEYTLVESVQINADLYKIDVNGKKSLKDGTGTIKFLVPHVDPFILEYKYKNGLEGEKKSHEVEAKAKYGKGKSATISLDTAFSPHENYLQFKGQAPQAENLKKLEFTINSKNPSPDSYSSTLIVDADGRVYKLENNVVLSKAHPVLDLKYSSPSSNRPRKIFIKGTSLSSTQGKIEVNLQDINGICLDAVSEGNIQKDNIAIKFQGNSKELGMKNYIVEISSKDAGSGKRLEFHATNDNKNVLSGSTSFISKQEGQGTIIEGSGTVKVKEEQKSANFKYIRTVLTEGNEKGVETFLKLSLGDRSYAAESRVTNLEYKNSYIYCEEKKQCAAIEIQSKIDLSKPGVIVNVVNAGFDLRTLGILPEIGFQMRDEVSDNRFPRFTLDLHVNTKEKKYHLNAYNTPEFGNYASGVVFYLPSRVMALETTVTYPTSSDSPYIFSGEACLDLDKKKQGHKTSVRYLINISNNRNQEAIAAEIGFFHPRLDKEVVIKSNAVFKVPEPNRYILESSVSLCHSSLGADRVSKLLLDVSPTKFVFLAQTPFVKVIDLEGTVDVQSKAKTQQAKLRFKLLEGKEVSVQALAKDFQYFEFTTGYLEEADRKLSIVGHLVPEKRVDITADIILSGDKKNIAHGALFLQDNLVKSDYGLSKENFNYFLNALKNDLDTLAERIKEKSEKAGQEISTISQKTAPYFKKIDEDFRREWSKFYQEVTDDKTLKELSHAFNEIVQFFAKIFDTIYKGTEPIVDSIINTYVETVKKIAELYEKQLEPQVRQLYETLAALLKEYLDGLIDLVAHFAALITDFFEKHKPELQEFTNVITDIFKDLTRIIVAQVKELPSLIAQSYRNIVEQISALPILSNLKEKWNDLVVPEKILEVTQILYSNIQKLLPTQESRDLAEAIHSYVQKKLRNQKCDDEKELRVVYQKLITAVTSLVQFLRTQLNEFGIINTTPDFANFFAAPSSIKSAPSLAGEATWSFFKQLYSGDFPDILALLRAYRPRSINPLDEVPSKLRAVVVNGQHIFTFDGRHLTFPGNCRYVLAHDHVDRNFTLLIQLQNGKPKALILEDKSGAIIELKENGQAILNGASKGFPIIEKDVFAFRQPSNRIGVGSLYGLMVFCTSKLEVCYIEANGFYLGKLRGLLGDGNNEPYDDFRLPNGKICTSESEFGNAYRLARSCPQVQAPEHSHHQLHDASLPPACEQVFGGISPLRTLSLFMDMSPFRQACIHAVTGTDAAKDLHEACDLGRGMAALALTGLLPAVLPNVCVKCTDADKPRDIGDSYEFKVPNKQADIILSVETTESNAKTYKDIVVPLVSHLIDSLKSKHITDVKVFLVGHTSKYPYPILYDTDLKLKNAHVHFDDKERYNNIPTIKTGYESFDKYEDQIISIINDLKNTYGFNNIEASKQSLFDLPVRPGAIKHLVFAIGEPCIGRCFLLDAIESAIYDVIFKNMAVTTSLITATPDLKIGGGKNLNQVVGFSEHSVVLLGEKKQTKDSETLRGTLQKTDDSCVNFVEGTGGYVFSSTNFEKLNAPQQKQFIQTAANTITHKLLSEQLSQLCTCTYVDPFRVRSVCVNKDKKDASY
Summary
Description
Constitutes the major component of lipophorin, which mediates transport for various types of lipids in hemolymph. Acts by forming lipoprotein particles that bind lipoproteins and lipids. May be required for morphogens wingless (wg) and hedgehog (hh) function, possibly by acting as vehicles for the movement of wg and hh (By similarity).
Constitutes the major component of lipophorin, which mediates transport for various types of lipids in hemolymph. Acts by forming lipoprotein particles that bind lipoproteins and lipids. Also involved in the transport of hydrophobic ligands like juvenile hormones, pheromone hydrocarbons and carotenoids. Required for morphogens wingless (wg) and hedgehog (hh) function, probably by acting as vehicles for the movement of wg and hh, explaining how covalently lipidated wg and hh can spread over long distances. May also be involved in transport and/or metabolism of heme.
Precursor of the egg-yolk proteins that are sources of nutrients during embryonic development.
Apolipoprotein B is a major protein constituent of chylomicrons (apo B-48), LDL (apo B-100) and VLDL (apo B-100). Apo B-100 functions as a recognition signal for the cellular binding and internalization of LDL particles by the apoB/E receptor.
Constitutes the major component of lipophorin, which mediates transport for various types of lipids in hemolymph. Acts by forming lipoprotein particles that bind lipoproteins and lipids. Also involved in the transport of hydrophobic ligands like juvenile hormones, pheromone hydrocarbons and carotenoids. Required for morphogens wingless (wg) and hedgehog (hh) function, probably by acting as vehicles for the movement of wg and hh, explaining how covalently lipidated wg and hh can spread over long distances. May also be involved in transport and/or metabolism of heme.
Precursor of the egg-yolk proteins that are sources of nutrients during embryonic development.
Apolipoprotein B is a major protein constituent of chylomicrons (apo B-48), LDL (apo B-100) and VLDL (apo B-100). Apo B-100 functions as a recognition signal for the cellular binding and internalization of LDL particles by the apoB/E receptor.
Subunit
Interacts with PCSK9. Interacts with MTTP.
Keywords
Cleavage on pair of basic residues
Glycoprotein
Lipid transport
Lipid-binding
Secreted
Signal
Transport
Wnt signaling pathway
Complete proteome
Direct protein sequencing
Heme
Iron
Lipoprotein
Metal-binding
Polymorphism
Reference proteome
Disulfide bond
Storage protein
Acetylation
Cholesterol metabolism
Chylomicron
Coiled coil
Cytoplasm
Heparin-binding
LDL
Lipid metabolism
Palmitate
Phosphoprotein
Repeat
RNA editing
Steroid metabolism
Sterol metabolism
VLDL
Atherosclerosis
Feature
chain Apolipophorin-2
Pubmed
EMBL
Proteomes
Pfam
Interpro
IPR009454
Lipid_transpt_open_b-sht
+ More
IPR015255 Vitellinogen_open_b-sht
IPR015816 Vitellinogen_b-sht_N
IPR015819 Lipid_transp_b-sht_shell
IPR011030 Lipovitellin_superhlx_dom
IPR001846 VWF_type-D
IPR001747 Lipid_transpt_N
IPR014853 Unchr_dom_Cys-rich
IPR015817 Vitellinogen_open_b-sht_sub1
IPR022176 ApoB100_C
IPR013763 Cyclin-like
IPR006671 Cyclin_N
IPR036915 Cyclin-like_sf
IPR015255 Vitellinogen_open_b-sht
IPR015816 Vitellinogen_b-sht_N
IPR015819 Lipid_transp_b-sht_shell
IPR011030 Lipovitellin_superhlx_dom
IPR001846 VWF_type-D
IPR001747 Lipid_transpt_N
IPR014853 Unchr_dom_Cys-rich
IPR015817 Vitellinogen_open_b-sht_sub1
IPR022176 ApoB100_C
IPR013763 Cyclin-like
IPR006671 Cyclin_N
IPR036915 Cyclin-like_sf
Gene 3D
CDD
PDB
1LSH
E-value=1.9184e-13,
Score=192
Ontologies
GO
GO:0005576
GO:0008289
GO:0005319
GO:0016055
GO:0019841
GO:0006869
GO:0045880
GO:0030139
GO:0020037
GO:0045178
GO:0046872
GO:0005504
GO:0005615
GO:0005102
GO:0008017
GO:0090263
GO:0045735
GO:0048477
GO:0034363
GO:0042953
GO:0012506
GO:0032496
GO:0030317
GO:0005737
GO:0006642
GO:0070971
GO:0008203
GO:0005829
GO:0043025
GO:0034364
GO:0001701
GO:0010886
GO:0034383
GO:0008201
GO:0048844
GO:0042632
GO:0010628
GO:0010744
GO:0010269
GO:0031983
GO:0033344
GO:0017127
GO:0019433
GO:0009615
GO:0050750
GO:0009743
GO:0045540
GO:0034361
GO:0042159
GO:0006629
GO:0016042
GO:0034359
GO:0071356
GO:0005543
GO:0071379
GO:0007283
GO:0010884
GO:0009566
GO:0042157
GO:0035473
GO:0034374
GO:0043231
GO:0034362
GO:0007399
GO:0042627
GO:0030301
GO:0032355
GO:0005783
GO:0009791
GO:0042158
GO:0010033
GO:0005488
GO:0007016
GO:0005891
GO:0043565
GO:0003677
GO:0003707
GO:0006281
GO:0006259
Topology
Subcellular location
Secreted
Cytoplasm
Cytoplasm
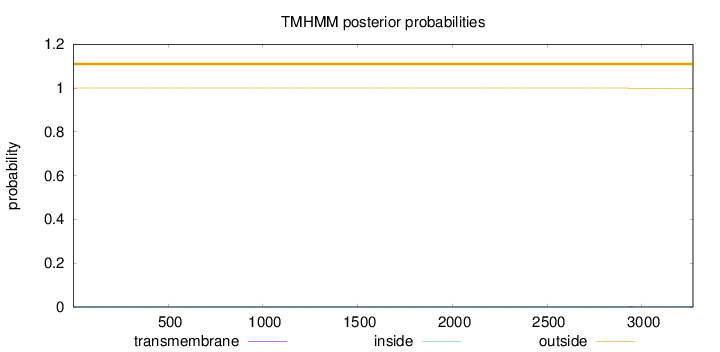
Length:
3270
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.03693
Exp number, first 60 AAs:
0.0002
Total prob of N-in:
0.00001
outside
1 - 3270
Population Genetic Test Statistics
Pi
206.272394
Theta
188.884708
Tajima's D
0.336743
CLR
1.159696
CSRT
0.460876956152192
Interpretation
Uncertain
