Gene
KWMTBOMO15615
Annotation
PREDICTED:_uncharacterized_protein_LOC106710892_[Papilio_machaon]
Location in the cell
Nuclear Reliability : 4.063
Sequence
CDS
ATGCTAGCCCTAAGCCCACTACCGTCACATTTGATAGAAAACAGTCAGAAGTACGAAATTAACAAAATTGAGACGGAAACTGACATAGATAAAGAACTTTGTGAAAATTTAAAGAAAATTCGTACCAGCCACATGAACGAGGAAGAAAAACGGGAAATTACTAAAATCTGCTATCAGTACCGTGACATATTCTACTCGGAAAACATTCCTTTATCGTTTACCCATACAGTAAAACACGAATTAAGACTAACCGACGACACCCCCATCTTTGTACGAAGTTATAGACAGGCTCCCCAACAACGAACAGAGATACAGAAACAGGTAGATAGTCTGTTAAAACAAGGAATCATTAGGGAAAGTATCTCCCCTTGGTCGTGCCCGGTACACATTGTTCCAAAAAAACCGGATGCATCAGGAAAAGTTAAATGGAGACTTGTTATTGACTATAGAAGACTTAATGACAGAATTATAGAAGACAAGTACCCCTTACCAAACATTAACGACATCCTTGACAGATTAGGGCGCGCACAATATTTCACGACCATAGATTTAGCAAGCGGTTACCATCAATTAGAAATGCACCCTAAAGACGTAGAGAAAACAGCGTTTACTACTGAAAGAGGCCACTATGAGTTCCTAAGAATGCCTTTCGGACTAAAAAATGCCCCGAGCACTTTCCAGCGTCTTATGGACCATATACTCCGAGGTATAGACAACGTATTTACGTACTTAGATGACGTCATAATAGCCGCGACGTCCCTACAAAACCACAATGAAAAACTGAAATTAGTATTTCAGCGATTCAAAATGCATAATCTGAAAGTTCAGTTAGACAAATCAGAATTTCTACAGAAGCACGTTAACTTTCTAGGACATGAATTGACTGACCAAGGACTAAATCCTAACAAGGACAAAATTAAAGCAGTATTAAATTTCCCTATACCACAAACGCAAAAAGACATAAAAGCTTTCTTAGGACTAGTAGGGTACTATAGGAAGTTTATAAAGGACTTTGCGAAGTTGACGAAACCTTTAACAGCATGTCTAAAAAAGAACGCAAAGGTTGAACATACAAACGAATTTTTAGACGCAGTTGATAAATGCAAACAAATTCTAACAAACGCCCCAATCCTGCAATACCCTGACTTCGACAAACCGTTTATTTTAACGACAGACGCATCTGACTTTGCTTTAGGAGCAGTACTTTCCCAAGGCAATGTGGGCTCAGATAAACCAGTAGCCTATGCCTCAAGGACATTATCAGATACTGAGACCCGTTACTCTACCATAGAGAAAGAACTGTTAGGGATAGTATGGGCAATTAAGTATTTTAGACCTTACTTATATGGCCGTAAATTTACAATTTATACGGACCATAGACCCCTTACATGGTTAATGAGTCTAAAGGACCCTAACTCTAAATTAACACGATGGAAACTAAAGTTAGCAGAGTATGATTACAAAGTTGTTTATAAAAAGGGCAAACAAAACACTAACGCAGATGCACTATCCCGAGCAAAAATTTTTCATAATAGTATAGATTCTCTAGCTGTTAATGTTGATGACAATAGTGACGACAACATAATAAATAGAATATTCGAAAACGCCCGTAGACAGGCAGAGATAGAAACTGATGACCCGAATAACCAAGACAATGAACGTAACAATACTGACAATAACGACCAACCTTATAACAATAATGACGTAGAAATGACCAGTATCTATCCCTCTCAAATTGACGAAGAGACAGACACAAGGAGTGCAACAACAGTAGACCCCGATCAATTAGTTTCTACAAATCATACCCAACCTGATAATGAAAATAACGGTATCCCTATAATATCCGACGCTATTGATAGACAGTTGAAACAATTTTACGTTAGGTCCACACCAGGTTCTACATACAGAGTAGAGGACAGATCAACAAACTCTAGGACAGTTATTAAGGATGTTTTCATCCCAGTAAATAACACTGAATCAGAAATTATCAAATTTTTAAAAGAACACACAATAGCTGACCGTGTTTTTCATTGCTATTTTTACGACGAAAATCTATACTTAGCCTTTTCAAGAGTGTATACTACGATATTTAATGACAGAGGACCTAAATTAATAAGATGTACTTCGCGGGTCACACTTGTTGAAAATAAAACTGAACAACAAGAACTCATTAAGCGATATCACGAAGGTAAATCATCGCATCGCGGTATCCAAGAGACCTTTAAGCATCTGCATAGGAATTATCACTGGCCTAATATGTTATTGACAGTTCAAAGGTTCATTAATCAATGCGACCTTTGCCTAAAGGCCAAATATGAAAGAAATCCCTTAAAACCTCCATTGATTATAACAGAGACACCTACGAAGCCATTTCAACACTTGTTCATGGATCTCTATAGTACTGGAGGTGCAACGTTTTTAACAATTATCGACAATTTCTCTAAATTTGCCCAGGCGGTACCTCTGAATGCTTCTAGTAGTGTTCACATCGCAGAAGCTCTATTACAAGTATTTTCTGTACTAGGACTACCTCTTAAAATCACCACAGACTCAGATACAAAGTTCGATAATGACGTCATAAAAGAGATATGTGCTTCGCATGATATCCACATTCACTTCACGACGCCTTACAACCCAAACTCTAACTCACCCATTGAACGATTTCATTCAACCATCGCAGAAATAATAAGAATTCAAAGAATGACAAATAAAGACGACCCCATACAATTGATCATGAAATACGCTATAATCGCCTATAACAACGCTATTCATTCTACTACAGGCTATACACCACGTGAGCTTTTATTCGGTCATACGGCATCCCGAAATCCATTAGAGCTATATTATCCTAAAGAATTTTATCAAGATTATGTCCTCCATCACCGCAAGAATGCAGAAGCAGTACAGGAATGTATAGCAGCCCACGTGTCTAAGAACAAAGAGCAGGTAATAGAAAAGAGAAACCAGGCAGCGGAAACAATCACGTTTAAGGTAGGTGAAACCGTTTACAAACAGGTCGCCAAAACCACCAGGAGCGACAAGACAAAACCAGTATTTAAAGATAAACAAAACCTCACCATTATTCCTAAATCCAAATACCTAGCACTGGGAACCAACGAGTACTCATACCTGGAGGAAGATTGCAAAAAGATCACACAAGACGTCCAACTCTGCACATCGCTGAACACCCAACCTGTGGAGAACTCTGAAGACTGCATAGTAACTCTTATAAAACACGAGAGCACAAACTGCACCCGTGCCAGGATGAACCTGAAACAAGGCAAGATCCAGAGACTAGAAGACAACAAATGGCTTATCATCTTGAAAGACGAACAAATCCTGAAATCTCGCTGCGGAAGGAAATCTGACTATAAAAAGATGTCAGGAATATACATCGCCAGCATTACAAGCGATTGTCAAGTGGAAATATTCAACCGAACACTGAAGACAAACACGGATACTATTACAGCTGATGAAATCGTACTCATTCCCAGCGAAACCACTATTCTAGAAGGGAATATTCGCTATAACCTACAACTGAAAGATATATCTCTGGATAGCATCCACGAACTGATGGACCGGGTTGAAAACATTCAACAACCTGTCATCGACTGGCAGACTATGATGACTACCCCAAGTTGGTCAACACTGGGACTCTACCTCATTCTGATAGCAATAATCATCTGGAAGCTGAGGCAGTGGAGACAGCGACGACTACAATCAAAGAACGAGAGCCCCGAGAACACTAGCACCGAGGACGCTGCTGGAAGCTGCGGGACGCGCTTCTATCTTAAGGAGGGAGGAGTTAGGCAATCGCCCGATGCCCGTATTTGCTGA
Protein
MLALSPLPSHLIENSQKYEINKIETETDIDKELCENLKKIRTSHMNEEEKREITKICYQYRDIFYSENIPLSFTHTVKHELRLTDDTPIFVRSYRQAPQQRTEIQKQVDSLLKQGIIRESISPWSCPVHIVPKKPDASGKVKWRLVIDYRRLNDRIIEDKYPLPNINDILDRLGRAQYFTTIDLASGYHQLEMHPKDVEKTAFTTERGHYEFLRMPFGLKNAPSTFQRLMDHILRGIDNVFTYLDDVIIAATSLQNHNEKLKLVFQRFKMHNLKVQLDKSEFLQKHVNFLGHELTDQGLNPNKDKIKAVLNFPIPQTQKDIKAFLGLVGYYRKFIKDFAKLTKPLTACLKKNAKVEHTNEFLDAVDKCKQILTNAPILQYPDFDKPFILTTDASDFALGAVLSQGNVGSDKPVAYASRTLSDTETRYSTIEKELLGIVWAIKYFRPYLYGRKFTIYTDHRPLTWLMSLKDPNSKLTRWKLKLAEYDYKVVYKKGKQNTNADALSRAKIFHNSIDSLAVNVDDNSDDNIINRIFENARRQAEIETDDPNNQDNERNNTDNNDQPYNNNDVEMTSIYPSQIDEETDTRSATTVDPDQLVSTNHTQPDNENNGIPIISDAIDRQLKQFYVRSTPGSTYRVEDRSTNSRTVIKDVFIPVNNTESEIIKFLKEHTIADRVFHCYFYDENLYLAFSRVYTTIFNDRGPKLIRCTSRVTLVENKTEQQELIKRYHEGKSSHRGIQETFKHLHRNYHWPNMLLTVQRFINQCDLCLKAKYERNPLKPPLIITETPTKPFQHLFMDLYSTGGATFLTIIDNFSKFAQAVPLNASSSVHIAEALLQVFSVLGLPLKITTDSDTKFDNDVIKEICASHDIHIHFTTPYNPNSNSPIERFHSTIAEIIRIQRMTNKDDPIQLIMKYAIIAYNNAIHSTTGYTPRELLFGHTASRNPLELYYPKEFYQDYVLHHRKNAEAVQECIAAHVSKNKEQVIEKRNQAAETITFKVGETVYKQVAKTTRSDKTKPVFKDKQNLTIIPKSKYLALGTNEYSYLEEDCKKITQDVQLCTSLNTQPVENSEDCIVTLIKHESTNCTRARMNLKQGKIQRLEDNKWLIILKDEQILKSRCGRKSDYKKMSGIYIASITSDCQVEIFNRTLKTNTDTITADEIVLIPSETTILEGNIRYNLQLKDISLDSIHELMDRVENIQQPVIDWQTMMTTPSWSTLGLYLILIAIIIWKLRQWRQRRLQSKNESPENTSTEDAAGSCGTRFYLKEGGVRQSPDARIC
Summary
Uniprot
EMBL
PRIDE
Pfam
Interpro
Gene 3D
ProteinModelPortal
PDB
4OL8
E-value=2.51974e-77,
Score=740
Ontologies
KEGG
GO
Topology
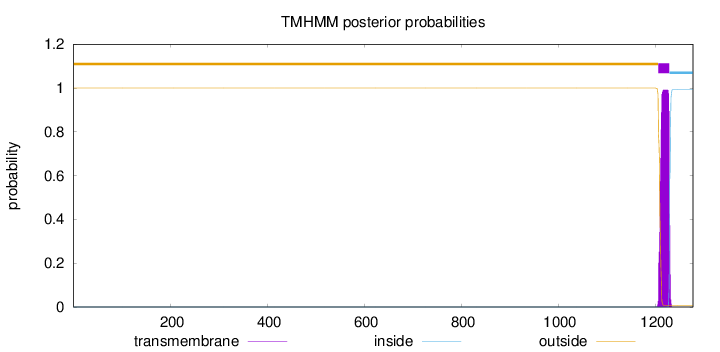
Length:
1278
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
20.516
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00000
outside
1 - 1206
TMhelix
1207 - 1229
inside
1230 - 1278
Population Genetic Test Statistics
Pi
207.155282
Theta
185.130821
Tajima's D
1.620307
CLR
0.249531
CSRT
0.812059397030149
Interpretation
Uncertain
