Gene
KWMTBOMO14721
Annotation
reverse_transcriptase_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.743
Sequence
CDS
ATGGAAAGCAGTCGACGTCGCCCTAAACACGTCATCTCGGATCCTCCTGATCCACTAACGGTGCTTTTAGGGGACTCGTCTTTCGGCGAGTGTGCCTTAAGTCCCGGGGACGCCCGCCCCGGGCAAGACAACCAACATGAACACGAACAGCGCGCTATTCGCGCAGTTCGTGCAATATGCCCGGACATTATGTCCCGTTTTGAGGCCTACAAGGCCACGCTAGAATCGAACCCCGATGGTTCATCCGCCGCCGCCGCGATTATCATCCGCGACTCGCCGTTATCGCCTCCCGCGCCGGCACTCCGCGACTCGCCGATGTCGCCCCCCACCCCCGCGCCCGCGTCGATCGCGTCTTGCGCGGCATCGAGCTCCGGCTCCGACTCCGAGTCGGAAATGGAGTTCGAGTCGGCCGCCAGCCCTGAACCCGGAACCTCCGATGGGTTCAAAACCGTCACGCGCGGGAAAAAACGCGCCCGCGCCGTGGAACCGTCCGCGGCGCCGAAACAACCCAAGGCCGCGAACGCGTCGCGGCCTAAAGTCGTGGTCTCACCCGACTCCCCTCGCCGCGCAACCCCGTCGCCGCGCCCCGGGCCCGCGCCCGTCCGAAAAGTTCCCGCGCCGCCGCCGGTCATCCTGCGGGAAAAGTCTTCTTGGGATCGCGTGTCCCTGGCCCTTAAGGCCCAAAAGATCAATGTCGTCCATGCGAGGAATATCCCGCATGGAATTCAGATCAAGGTAGAAACATCCGACGACCATAGGTCGTTGACCGCGTACCTCCGCAAGGAACGCATAGGGTATCATACCTATGCGCTCCAGGAGGAGCGTGAACTCCGCGTCGTAATACGCGGAGTCCCCAAAGAGCTCGACGTCGAGCAAATTAAGAATGACCTGGTAGGTCAGTCCTACCCCGTCATAAGTGTGCACCGGATGCACAGCGGGCGCGACAAATTCGCGTACGATATGGTGCTCGTAGCACTAGAAGCCACACCGGAGGGCAAGAAAATTGCCTCATGTCTCCGCACCGTGTGCGGCCTATCGGGGGTCACCGTAGAGGCCCCCTACAAACGCGGCACTCCCGGGCAGTGCCACCGTTGCCAACTCTATGGCCACTCCGCGCGTAACTGCAACGCGCGACCGCGTTGCGTGAAGTGCTTAGACGATCACGCGACCACCGATTGCTCGCGCGTTAAGGAGACAGCGACGGAGCCGCCGAGCTGTGTACTCTGCCGCAAGCAGGGACACACGGCCAACTACCGTGGATGCCCCAAGGCTCCACGGAAGCGCCCGGCAAACGCGCCCCCTAAAACCGCTGGCCCAAAGACTTCGGCGCCCCGCGCGCCGAAACCGGCTTTCGTACCGGCTCCGGTGCCCACCGTCTCCGCGTGGGCGAAACCCCGTTGCCGTTCACGAAGGCAGGAACGACACCGGCACCCCAACCGCGCATTCTACAATGCTAACGGACTCGCGCGTCAGCGCGACCAGGTTTATGAGTTTCTACGTGACAATCTCATCGACATCCTTCTGGTGCAGGAGACCTTCCTAAAGCCCTCGCGTCGCGACCCCAAAGTCGCGAATTACGTCATGGTTAGGAATGACAGACTCTCCACCCGCAAGGGCGGGACTGTCATTTACTATAGGAGGGCCCTGCACTGCGTCCCTCTCGATACTCCCTCGCTCTTACATATCGAGGCGTCAGTGTGCCGCATCGCGCTGACGGGACACCAGCCGATCGTCATCGCATCCGTATATCTCCCTCCTGACAAACCCCTCCTGAGCAGTGACCTCGAGACACTGCTCGGTATGGGGGACGCGGTCATTCTGGCAGGCGATTTAAATTGCCACCACACTAGGTGGAACTGCCATCGCACGAATGTGAACGGTAGGCGTCTCGACGCGTTCATAGACGACCTCACATTCGAGATATTCAACCCCCCGACCCCCACGTGCTATCCGTACAACGCCGCGCGTCGTCCGAGCACAATAGATCTGGCACTGCTGAGGAACGTAACTCTGCGCTTGCGCTCCATCGAGGCAATGTCAGAACTCGACTCAGACCACCGACCTGTCGTCATGCAGCTCGGTCGCCCACTCAACCGCGAACCAGATACGAGGACCATGGTGGATTGGAAGAAGCTGGGCACGTGCTTAGCTGACACCGCTCCACCAATCCTCCCTTGCGGCCCGGATTCAACTCCATCCCCCGAGGACACCGTCGAATCCATAAATATCTTCACTGATCACGTCTCGACGGCGATCACAAGATCTTCAAAGCAAGTTGATGTGGAGGACTGCTTCCACCGCATCGGACTTTCCCCCGATCTTAGGGACCTCGTTAGAATCAGAAACGCGGCAATCCGGGCCTACGATCGATATCCCACGGATTCAAACCGGACTCGGATGCGTCGCTTACAGCGAGAGGTCAAATCCCGCTTGAGCGACGCCCGAAACGAAAACTGGGATAGTTATTTAGAAGAGCTCGCGCCCACTCACCAAGCATACTGGCGACTAGCTAGGACCCTCAAGTCCGAAACTATCGTCACTATGCCGCCTCTCGTACGCCCCTCAGGCCAATCACCGGCTTACGATGACGATGACAAGGCAGAGTTGCTGGCCGATGCACTGCAAGAGCAGTGCACCACCAGCACTCAACACGCGGACCCCGAACACACCGAGTTCGTCGACAGGGAGGTCGAGCGCAGAGCTTCCCTGCCGCCCTCGGACGCGTTACCCCCCATTACCACTTCCGAGGTCAAGGAGGCGATCGATAGCCTGCAACCACGGAAAGCTCCCGGCTCCGACGGCATCCGCAACCGCGCGCTTAAACTGTTACCAGCCCAACTGATAACGATGTTGGCCACCATATTAAATGCTGCTATGACGAATTGCATCTTTCCCGCGGCGTGGAAAGAAGCGGACGTTATCGGCATACACAAGCCGGGCAAACCGAAGAACGAAACCGCGAGTTACCGCCCCATCAGTCTCCTCCCGGCGATAGGCAAACTATACGAACGGCTCCTTCGTAAACGCCTCTGGGACTTCGTATCCGCGAATAAAATTCTTATAGACGAGCAGTTTGGATTCCGCGCCAGACACTCGTGCGTCCATCAAGTGCACCGCCTCACGGAGCACATCTTACTAGGGCTGAACAGGCGGAAACTCATTCCGACAGGAGCCCTCTTCTTCGATATAGCGAAGGCGTTCGACAAAGTCTGGCACAACGGTTTGATATACAAACTGTATAACATGGGAGTGCCAGACAGACTCGTGCTCATCATACGAGACTACTTGTCGAACCGTTCGTTCCGATATCGAGTCGAGGGAACGCGTTCCCGACCCCGTCACGTCACAGCCGGAGTCCCGCAAGGCTCCGCCCTCTCCCCGTTACTATTCAGTTTGTATATCAACGATATACCCCGGTCTCCGGAGACCCATCTGGCGCTCTTCGCCGATGACACCGCCATCTACTACTCGTGTAGGAAGAAGGCGTTGCTTCATCGACGACTTCAGACCGCAGCTACCACCATGGGACAGTGGTTCCGGAAGTGGCGCATCGACATCAACCCCACGAAAAGCACAGCGGTGCTCTTCAAAAGGGGTCGCCCTCCGAACACCACGCTGAGCATCCCCCTCCCGACTAGGCGCGTCAATAACCCCGCCCCCGCCGTTCGCCCAATCACGATGTTCGACCAGCCCATACCGTGGGCCCCGAAGGTCAAATATTTAGGCGTCACCCTCGACAGTAGGATGACATTCCGCCCCCACATCAAGACGGTACGCGACCGTGCCGCCTTCCTTCTAGGACGTCTCTACCCGATGATATGTAGGCGAAGTAAAATGTCCCTTAGAAATAAGGTGACACTCTACAAAACTTGCATACGCCCCGTCATGACCTATGCAAGTGTAGTGTTCGCTCACGCGGCCCGCATACACTTAAAATCATTCCAAGTCATTCAATCCCGTTTTTGCAGGATAGCCGTCGGAGCCCCGTGGTTCGTCAGGAACGTCGACCTCCATGACGACCTGGACTTAGAGTCCACCAGTAAGTATATGCAGTCGGCGTCTACGCGCCACTTCGATAAAGCGGCACGACACGAGAACCCTCTCATCGTGGCCGCCGGTAACTACATTCCCGATCCTGCGGACAGAATGGAAAGCAGTCGACGTCGCCCAAAACACGTCATCTCGGATCCTCCCGATCCACTAACGGTGCTTTTAGTTTGCTTTAAGTCCCGGGGACGCCCCCCCCGGGCACACGTCACCATGAGTGACGCCAACGGCGCGCTCTTTTTAAAATTCGTCCGCGACTTCTGTCCGGACATCATCGCACGGTTCGAAGTCTACAAGGTCGGCCTTGACGCGCCGGCACTCCGCGACTCGCCGCTATCGCCCCCCGCGCCGGACCTCCGTGACTCGCCGATGTCGCCCCCCACCCCCGCACCCGCGTCGATCGCGTCTTCCGAAGCTAGCTCCGGCTCCGACTCCGAGTCGGAAATGGAGTACGAGTCCGCCGCAAGTCCCCAACCGGGAACCTCGGAAGGGTTCACCACCGTCGCGCGCGGCAAAAAACGCGCCCGCGCTGTGGACCCGCCCACGGCGCCTAAACAACCCAAGGCCGCGAACGCGTTGCGGCCTAAGACCGTCATAACCCCGGACTCCCCTCGCCGCGCCCCGGGCCCGCGCCCGTCCGAAAAGTTCCCGCGCCGCCGCCGGTCATCCTGCGGGAAAAGTCTTCTTGGGATCGCGTGTCCCTGGCCCTTAAGGCCCAAAAGATCAATGTCGTCCATGCGAGGAATAATCCCGCATGGAATTCAGATCAAGGTTGAAACATCCGACGACCATAGGTCGTTGACCGCGTACCTCCGCAAGGAACGCATAGGTTATCACACCTATGCGCTCCAGGAGGAGCGTGAACTCCGCGTCGTAATACGCGGAGTCCCAAAAGAGCTCGACGTCGAGCAAATTAAGAATGACCTGGTAGGTCAGTCCTACCCCGTCATAAGTGTGCACCGGATGCACAGCGGGCGCGACAAATTCGCGTATGATATGGTGCTCGTACCACTAGAACCCACACCGGAGGGCAAGAAAATTGCCTCATGTCTCCGCACCGTGTGCGGCCTATCGGGGGTCACCGTAGAGGCCCCCTACAAACGCGGCACTCCCGGGCAGTGCCACCGTTGCCAACTCTATGGCCACTCCGCGCGTAACTGCAACGCGCGACCGCGTTGCGTGAAGTGTCTAGACGATCACGCGACCACCGATTGCTCGCGCGTAAAGGAGACAGCGACGGAGCCGCCGAGCTGTGTACTCTGCCGCAAGCAGGGACACACGGCCAACTACCGTGGATGCCCCAAGGCTCCACGAAAGCGCCCGGCAAACGCGCCCCCCAAAACCGCTGGCCCAAAGACTTCGGCGCCCCGCGCGCCGAAACCGGCTTTTTGTACCGGCTCCGGTGCCCACCGTCTCCGCGTGGGCGAAACCGTTGCCGTTCACGAAGGCAGGAACGACACCGGCACCCCAACCGCGGGCGGGACTGTCATTTACTATAGGAGGGCCCTGCACTGCGTCCCTCTCGATACTCCCTCGCTCTTACATATCGAGGCGTCAGTGTGCCGCATCGCGCTGACGGGACACCAGCCGATCGTCATCGCATCCGTTTATCTCCCCCCTGACAAACCCCTCCTGAGCAGTGACCTCGAGACACTGTTCGGTATGGGGGACGCGGTCATCCTGGCAGGCGATTTAAATTGCCACCACACTAGGTGGAACTGCCATCGCACGAATGTGAACGGTAGGCGTCTCGACGCGTTCATAGACGACCTCACATTCGAGATATTCAACCCTCCGACCCCCACGTGCTATCCGTACAACGCCGCGCGTCGTCCGAGCACAATAGATCTGGCACTGCTGAGGAACGTAACTCTGCGCTTGCGCTCCATCGAGGCAATGTCAGAACTCGACTCAGACCACCGACCTGTCGTCATGCAGCTCGGTCGCCCACTCAACCGCGAACCAGATACGAGGACCATGGTGGATTGGAAGAAGCTGGGCACGTGCTTAGCTGACACCGCTCCACCAATCCTCCCTTGCGGCCCGGATTCAACTCCATCCCCCGAGGACACCGTCGAATCCATAATCATCTTCACTGAACACGTCTCGACGGCGATCATAAGATCTTCAAAGCAAGTCGATGTGGAGGACTGCTTCCACCGCATCAGACTTTCCCCCGATCTTAGGGACCTCTCTTCATCATAA
Protein
MESSRRRPKHVISDPPDPLTVLLGDSSFGECALSPGDARPGQDNQHEHEQRAIRAVRAICPDIMSRFEAYKATLESNPDGSSAAAAIIIRDSPLSPPAPALRDSPMSPPTPAPASIASCAASSSGSDSESEMEFESAASPEPGTSDGFKTVTRGKKRARAVEPSAAPKQPKAANASRPKVVVSPDSPRRATPSPRPGPAPVRKVPAPPPVILREKSSWDRVSLALKAQKINVVHARNIPHGIQIKVETSDDHRSLTAYLRKERIGYHTYALQEERELRVVIRGVPKELDVEQIKNDLVGQSYPVISVHRMHSGRDKFAYDMVLVALEATPEGKKIASCLRTVCGLSGVTVEAPYKRGTPGQCHRCQLYGHSARNCNARPRCVKCLDDHATTDCSRVKETATEPPSCVLCRKQGHTANYRGCPKAPRKRPANAPPKTAGPKTSAPRAPKPAFVPAPVPTVSAWAKPRCRSRRQERHRHPNRAFYNANGLARQRDQVYEFLRDNLIDILLVQETFLKPSRRDPKVANYVMVRNDRLSTRKGGTVIYYRRALHCVPLDTPSLLHIEASVCRIALTGHQPIVIASVYLPPDKPLLSSDLETLLGMGDAVILAGDLNCHHTRWNCHRTNVNGRRLDAFIDDLTFEIFNPPTPTCYPYNAARRPSTIDLALLRNVTLRLRSIEAMSELDSDHRPVVMQLGRPLNREPDTRTMVDWKKLGTCLADTAPPILPCGPDSTPSPEDTVESINIFTDHVSTAITRSSKQVDVEDCFHRIGLSPDLRDLVRIRNAAIRAYDRYPTDSNRTRMRRLQREVKSRLSDARNENWDSYLEELAPTHQAYWRLARTLKSETIVTMPPLVRPSGQSPAYDDDDKAELLADALQEQCTTSTQHADPEHTEFVDREVERRASLPPSDALPPITTSEVKEAIDSLQPRKAPGSDGIRNRALKLLPAQLITMLATILNAAMTNCIFPAAWKEADVIGIHKPGKPKNETASYRPISLLPAIGKLYERLLRKRLWDFVSANKILIDEQFGFRARHSCVHQVHRLTEHILLGLNRRKLIPTGALFFDIAKAFDKVWHNGLIYKLYNMGVPDRLVLIIRDYLSNRSFRYRVEGTRSRPRHVTAGVPQGSALSPLLFSLYINDIPRSPETHLALFADDTAIYYSCRKKALLHRRLQTAATTMGQWFRKWRIDINPTKSTAVLFKRGRPPNTTLSIPLPTRRVNNPAPAVRPITMFDQPIPWAPKVKYLGVTLDSRMTFRPHIKTVRDRAAFLLGRLYPMICRRSKMSLRNKVTLYKTCIRPVMTYASVVFAHAARIHLKSFQVIQSRFCRIAVGAPWFVRNVDLHDDLDLESTSKYMQSASTRHFDKAARHENPLIVAAGNYIPDPADRMESSRRRPKHVISDPPDPLTVLLVCFKSRGRPPRAHVTMSDANGALFLKFVRDFCPDIIARFEVYKVGLDAPALRDSPLSPPAPDLRDSPMSPPTPAPASIASSEASSGSDSESEMEYESAASPQPGTSEGFTTVARGKKRARAVDPPTAPKQPKAANALRPKTVITPDSPRRAPGPRPSEKFPRRRRSSCGKSLLGIACPWPLRPKRSMSSMRGIIPHGIQIKVETSDDHRSLTAYLRKERIGYHTYALQEERELRVVIRGVPKELDVEQIKNDLVGQSYPVISVHRMHSGRDKFAYDMVLVPLEPTPEGKKIASCLRTVCGLSGVTVEAPYKRGTPGQCHRCQLYGHSARNCNARPRCVKCLDDHATTDCSRVKETATEPPSCVLCRKQGHTANYRGCPKAPRKRPANAPPKTAGPKTSAPRAPKPAFCTGSGAHRLRVGETVAVHEGRNDTGTPTAGGTVIYYRRALHCVPLDTPSLLHIEASVCRIALTGHQPIVIASVYLPPDKPLLSSDLETLFGMGDAVILAGDLNCHHTRWNCHRTNVNGRRLDAFIDDLTFEIFNPPTPTCYPYNAARRPSTIDLALLRNVTLRLRSIEAMSELDSDHRPVVMQLGRPLNREPDTRTMVDWKKLGTCLADTAPPILPCGPDSTPSPEDTVESIIIFTEHVSTAIIRSSKQVDVEDCFHRIRLSPDLRDLSSS
Summary
Uniprot
ProteinModelPortal
PDB
6AR3
E-value=0.00164467,
Score=105
Ontologies
GO
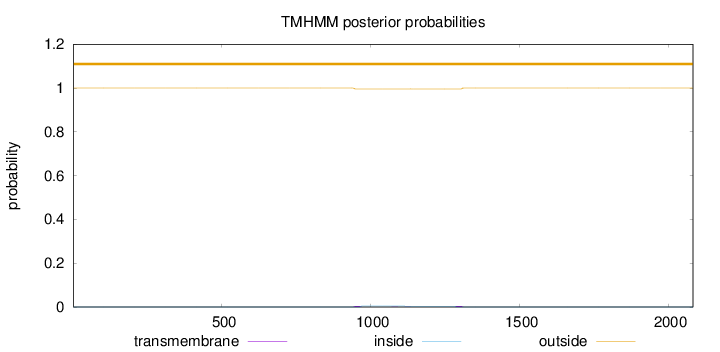
Topology
Length:
2083
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.19248
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00002
outside
1 - 2083
Population Genetic Test Statistics
Pi
194.352171
Theta
121.628984
Tajima's D
2.891225
CLR
0.200184
CSRT
0.974951252437378
Interpretation
Possibly Balancing Selection
