Gene
KWMTBOMO14333
Pre Gene Modal
BGIBMGA007097
Annotation
PREDICTED:_uncharacterized_protein_LOC105841862_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.76
Sequence
CDS
ATGAGTCATCATCATGAAAGTAATAACTGTGACGTCAGCAATGCTGACGTCACACTTTTTAAAAACAATACGGAGGTTAATGTTCCGTCATCAGAAGTGGGATCACATGCTGCCTCCGCTCAGCAACAACCTGAAGCTACATCACAAATAGAACCACACCATGGATTAAATACTACAGGCAATGCTGGGAGTTCCTTGGAACAGGAACAGGAACAGCCACAATCAGCATTGCTTAACGCACCGATGAGCAGCGTACCGCCACAATTCATCATGCAGATGATGCATGTGATGCAGCAAATGTCGGAACGCTTAAGTACACCAGCAGAAACTAAGATACGTATAAATGATATTTACCTACCATCATTTGACCCCGACACTAGTGTGGGAGTACGTGAGTGGTGTCAACATATCGACAAAGCCATTGAGACTTATCGACTCAACGACTTTGACATACGCATGAAAGTTGGCAGCCTCCTAAAGGGAAGAGCGAAGATGTGGGTTGACGATTGGATGGTCACTGCAGCTTCGTGGGCTGAGCTGCGCAACAATCTTATCACGACATTCGAGCCAGAAAATCGCTATTCTCGAGACATAGCTCGATTTAGAGAACATATGTACGACTCTTCAAAGGACATCTCGGAGTTCTTGTCACGAGCTTGGGTCTTGTGGAGGAGGATCACCAAAGACAAACTACCTAATGAAGATGCAGTTGAAGCAGTTATTGGTTGCGTGAATGACGAGAAACTTAGGATCGAGCTACTGAACACAAGAGCCACAACAGTACCAGAATTGATATCTGTTGCATCATCAGTAAGAGCCATGAAGCGTTTTCACCAGGGCTCAAATAAGCTGAGTACAAATAAGCGTCCCCGTTTTTTGAATTCTACTTCATCAAATTCATCTTACCATATCTGTAAAAGAACTAATCACACCACCAACGAATGCTACTACAAAATGGTTACCGAATCAAAGCCCGAACAAAGAAACAAAACAACAACTGAGACAACGAAGGAAGTAACCTCCTACCAGAACGATAAAACAACAATCTGTTCATTCTGCAAAATACCAGGACACAGTTTTGAAACATGCTTCAAACGTGAACGAGCATTGACATCAAACGTAAATTACGTTGCTGGATCAAAACTAGCTCCGATTCAGGTGAAGTTTGGATCAAAGAGTTTTCAGGCAATCTTTGATAGTGGCGCAGAATGCTCACTTATGCGGGAATCCGTAGCAGCTCAAATACCCGGAAAAAGACTACAAACGGCAGATTACTTGAAAGGAATTGGACAATTTCCTGTACTATCAATAGCTACACTCGTAACGGTAGGTGTCATCGATAACATCAACGTTGAATTACAGTTTCACATAGTGGCAGATTACGAGATGACTACAGATATTTTAGTGGGTATGAACTTGATAAACAATACGAACCTAACTATGACGATCACTTCGGGCGGGACGAGGCTAGCACGTCAGCCACATGTTAATCAAGTTCAGTGTATAAATCCAATTTTCGATAAACTGGATTGTGATCTCACAAATGAAGAAGATATCGCAAAATTACGCACCCTTCTAAACAAATATCAGCACCTGTTTATCAGAGGGTATCCAACAACTCGTGTCAAGACAGGTGAACTGGAAATCCGCCTGAAGAATCCAAACAAATATGTAGAACGAAGACCTTACAGGCTCAGTCCAATCGAACGAGAAAGGGTGCGAGCCATTGTGAAAGAGTTGATGGAGCATGGCATTGTACGCGAAAGCAAGTCTCCATACTCCAGTCCCATCATCTTGGTGAAGAAGAAGAATGTCTATCAACGATGCATCAACAGAGCTCTGAGCTCGTTAATGGGGAATGCAGCTCAAGTCTACGTCGATGACGTATTAAGCAGATGTGAAAATATCGCAGAAGGGCTGTCAAACATAGAACGTATTCTAATAGCACTACAAGATGCGGGTTTTTCCATTAATGCTGATAAATGCAGTTTTTTTAAGCGTTCAATCGAATATTTGGGTAACGTAGTATCAAATGGACAAGTCTGGCCAAGCCCACGGAAAATAGATGCTCTGGTAAAATCGCCGGTACCAACAACACCCAGACAAGAGGAAGCACCTATTCAATTGTACACAGATGCAAGTAGTTTGGGATTCGGAGCAGTACTGGTACAAGTAATTGCGGGACGACAACATGCAGTTGCCTTTATGAGCATGAGAACTACTGAAACAGAAAGTCGCTATCACTCTTATGAATTAGAGACCTTGGCAGTAGTCCGAGCGATAAAACACTTTCGGCAGTATCTTTATGGACGTAAGTTTACAGTTATCACAGACTGTAATGCACTAAAAGCATCCAAACACAAAAAGGACTTACTCCCTAGAATCCACCGTTGGTGGGCATTTTTACAAAATTATAATTTTGAGGTTGAATACCGCAAGGGTCAACAGCTTCAACACGCAGACTACTTCAGTAGGAACCCAGTCGAACTCACAGTGAATATAATGACCAGAGATCTAGACTGGCTGAAAATTGAACAGCGACGTGATGAAACACTACGAGCTATAATGGATGGTATGAATAATAACAATCCAAGTAACGGCTATATGCTAGAAAACGATGTCCTCAAGCATATCGTACAAGATCCAACCTTCGGACACCGATACTGCACAGTGGTACCCAGGTCCTTTCAGTGGAGTTTAATAAACTCCTTCCACACCGCACTGAAGCACCCTGGCTGGGAAAAGACGTTGCAGAAAATTAAGGACAGCCACTGGTTTAACAACATGAGCACGAAGGTACGAAAATTTGTTGATAATTGCGTGGTCTGCAGGACATCGAAAGGAGCATCTGGTGCGGTACAAGCTCAAATGCACCCGATTCAGAAACCGTCTGCTGCTTTTCAAGTAATACACATGGATATAACAGGCAAGATGGGAACATCCAACGACCAACAGTATGTGATTATCACCATAGATGCTTTTACGAAATACGTGCTATTCTATTATGCAACTAACAAAAATCCACCCAGCACATTAGCTGCCTTAAAGCGTACGGTTCATCTATTCGGTACTCCTGTCCAAATAATAGTCGACGGTGGAAGAGAGTTCCTCGGTGAATTCAAGACCTACTGCGATAGGGTAGGTATTGACATTCATGCTATAGCACCAGGAGTCAGCCGAGCAAATGGACAAGTAGAACGCGTCGTAGCTACACTAAAAAATGCTCTTACTATGATCAAGAATTACGAAACAGAAGAGTGGCACACAACGATTGCAGAACTTCAGCTAGCAATAAATTGCACTCCGCATCGTGTGACAGGCGTAGCTCCACTTACATTACTCACTCAGCGAAAGCATTGTGTTCCTCCAGAGCTACTTAAATTAGTAAATATTGACGAGCAGACTATTGATATTGAAGCACTCACTAACCATGTTCAACACAAGATGTCACAAAATGCAGAACAGGACAGGCAACGTTTCAATTCAAAAAAAGCTAGGATCCATCATTTCCAGCGTGGTGATTATGTGCTCATAAAAAATAATCCTCGTAATCAAACTTCGTTGGATCTCAAATTCAGCGAGCCATATGAGATAACAAAAATCCTGGACAACGACCGCTATTTAGTAAAAAAGGTGGTTGGTTCAGGGCGTTCAAGAAAAGTAGCTCATCATCAACTCCGTCGGGCACCGCAACCTGGAGACCAGATAGCCGTATCGGCGGAAGAAAACGACCCTCCAGCATCAGCCGATGAACCTATATGA
Protein
MSHHHESNNCDVSNADVTLFKNNTEVNVPSSEVGSHAASAQQQPEATSQIEPHHGLNTTGNAGSSLEQEQEQPQSALLNAPMSSVPPQFIMQMMHVMQQMSERLSTPAETKIRINDIYLPSFDPDTSVGVREWCQHIDKAIETYRLNDFDIRMKVGSLLKGRAKMWVDDWMVTAASWAELRNNLITTFEPENRYSRDIARFREHMYDSSKDISEFLSRAWVLWRRITKDKLPNEDAVEAVIGCVNDEKLRIELLNTRATTVPELISVASSVRAMKRFHQGSNKLSTNKRPRFLNSTSSNSSYHICKRTNHTTNECYYKMVTESKPEQRNKTTTETTKEVTSYQNDKTTICSFCKIPGHSFETCFKRERALTSNVNYVAGSKLAPIQVKFGSKSFQAIFDSGAECSLMRESVAAQIPGKRLQTADYLKGIGQFPVLSIATLVTVGVIDNINVELQFHIVADYEMTTDILVGMNLINNTNLTMTITSGGTRLARQPHVNQVQCINPIFDKLDCDLTNEEDIAKLRTLLNKYQHLFIRGYPTTRVKTGELEIRLKNPNKYVERRPYRLSPIERERVRAIVKELMEHGIVRESKSPYSSPIILVKKKNVYQRCINRALSSLMGNAAQVYVDDVLSRCENIAEGLSNIERILIALQDAGFSINADKCSFFKRSIEYLGNVVSNGQVWPSPRKIDALVKSPVPTTPRQEEAPIQLYTDASSLGFGAVLVQVIAGRQHAVAFMSMRTTETESRYHSYELETLAVVRAIKHFRQYLYGRKFTVITDCNALKASKHKKDLLPRIHRWWAFLQNYNFEVEYRKGQQLQHADYFSRNPVELTVNIMTRDLDWLKIEQRRDETLRAIMDGMNNNNPSNGYMLENDVLKHIVQDPTFGHRYCTVVPRSFQWSLINSFHTALKHPGWEKTLQKIKDSHWFNNMSTKVRKFVDNCVVCRTSKGASGAVQAQMHPIQKPSAAFQVIHMDITGKMGTSNDQQYVIITIDAFTKYVLFYYATNKNPPSTLAALKRTVHLFGTPVQIIVDGGREFLGEFKTYCDRVGIDIHAIAPGVSRANGQVERVVATLKNALTMIKNYETEEWHTTIAELQLAINCTPHRVTGVAPLTLLTQRKHCVPPELLKLVNIDEQTIDIEALTNHVQHKMSQNAEQDRQRFNSKKARIHHFQRGDYVLIKNNPRNQTSLDLKFSEPYEITKILDNDRYLVKKVVGSGRSRKVAHHQLRRAPQPGDQIAVSAEENDPPASADEPI
Summary
Uniprot
EMBL
Proteomes
Interpro
IPR001878
Znf_CCHC
+ More
IPR036875 Znf_CCHC_sf
IPR012337 RNaseH-like_sf
IPR001584 Integrase_cat-core
IPR041577 RT_RNaseH_2
IPR001995 Peptidase_A2_cat
IPR001969 Aspartic_peptidase_AS
IPR018061 Retropepsins
IPR041588 Integrase_H2C2
IPR036397 RNaseH_sf
IPR000477 RT_dom
IPR021109 Peptidase_aspartic_dom_sf
IPR036875 Znf_CCHC_sf
IPR012337 RNaseH-like_sf
IPR001584 Integrase_cat-core
IPR041577 RT_RNaseH_2
IPR001995 Peptidase_A2_cat
IPR001969 Aspartic_peptidase_AS
IPR018061 Retropepsins
IPR041588 Integrase_H2C2
IPR036397 RNaseH_sf
IPR000477 RT_dom
IPR021109 Peptidase_aspartic_dom_sf
Gene 3D
ProteinModelPortal
PDB
4OL8
E-value=4.93399e-15,
Score=202
Ontologies
GO
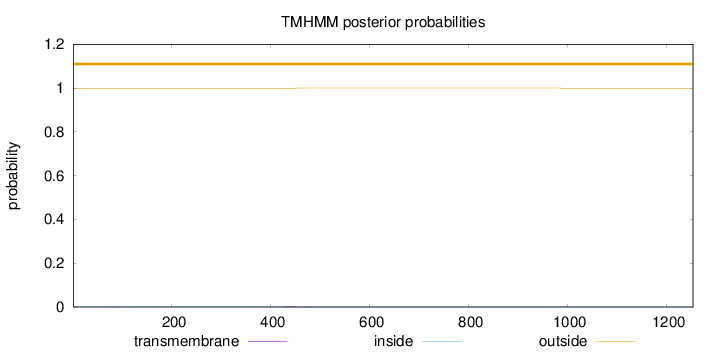
Topology
Length:
1253
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.06487
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00206
outside
1 - 1253
Population Genetic Test Statistics
Pi
203.515795
Theta
161.529815
Tajima's D
1.86584
CLR
3.102214
CSRT
0.859057047147643
Interpretation
Uncertain
