Pre Gene Modal
BGIBMGA011326
Annotation
PREDICTED:_uncharacterized_protein_LOC101746443_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.709
Sequence
CDS
ATGACACGAACAGCGAGCTGGTTACCCCCCGCCGAGAGCTGGTCGTCGCCGCGGGACTGTCAGGAGCCGGATACAGAAGAACTGCCTTATGGCTGGGAACAGGCTTTGGACAATCGAGGGAAATCTTATTATGTCAACCACATCAACAAGACTACAACATACGTGGCTCCGGAAGGCTGTTCCTGCGAATCTCCCCCGGCACCCAGGGACATTGTGCTCGAGCGAGACCCAGAGCTGGGCTTCGGATTCGTGGCCGGCTCCGAGAAGCCTGTCTTAGTCCGATTCGTCACTGATAATTCACCTAGTGTTGGAAAATTGGAACCCGGTGATCAGATCCTATGCGTGAATGGGGAAGACGTGAGTATGGCTGCCCGCGAGCACGTCATATCCGCAGTCAGGGCCTGTACGGAGAAGGTCACCCTTCGCGTATGCCAACCGGCCAGAGCTGGGAATCCCACGAGAAGATCCGCGCTGCTATCAGCTGCCAAGAGAGCCAGGCTACGAGCCAGACCGCCGAGGGTTCGATTCGCCGACTCAGTTCAATTGAATGGAGCTCCCATGTATCCGCCCTCAGCATTCTCGCTGGGCGACTTGTGCCTTCCGCCGATGGCGAACGTCCTCAAAGTCTTCCTGGAAAACGGTCAAACGAAATCCTTCAAATACGACACTACAACTACAGTCGCGGACGTGGTGACGAATCTTAAAGAGAAACTCTGCATCATTGCTGAAGAGCATTTCAGTCTGGTGGTGGAGCACGTGAAAAGCTTAAGAAGGAATAAACTGACTCTGCTCGATCCTAAGGAGTCTTTGGCAAGGATAGCAGCCCGTCCCGGTTCGCATAAGATGCGATGCCTGTACCGAGTGGTCTTCATGCCGACGTCTGCCGCCGACCTGGCCCAGCAGGACCTGGCGGCGCTGGACTATTTGTACCTGCAGTGCTGCAACGACGTGGCCCAGGAGAGGTTCGCCCCGGAGCTCCAGCCCGAGGTGGCCCTCCGACTAGCGGCCCTGCACATGCACCAACACGCCCTGGCCAACAATCTCTCGCCGGCCAAGTTGACTGTTAAAGCCGTCGAAAGAGAATTCGGACTGGAAAGGTTCGTGCCGAGCAGTCTATTGGAGAGCATGAAACGCAAAGAGCTCAGGAGGTTGATCGCTCATTTCCTGAAACTGAACTCGCAGATGACCGGCAGCCAGCGGCATCTGACGCAGCTGCAGGCCAAGCTTCACTATCTCGATATAGTGGGAGGACTGCCGAGCTACGGAGCGAAATGTTTCAGCAGCAGCAGACCAGAACGAGTGCTGCTGGTCTCTCCGAGGTTCGGTCTCAGTCAGATCGTGGGGAGAACTAACTCTGTGCCACAGCAAATAGCGTCCATAGACGAAGTGGAGTGCGTGCGGGTGCGGCGCGCGGGCGCATGCGCGGAACTGGCCGTGTTCCTGCGCCGCGACCGCGTGCTGGCGCTGCTCATGGATGATAGGGACGCCGCGGAGATGCCGCTCGTCATCGCCGGATATTACAAGCTGGCGACCGGTAAAGAGCTGAATGTGGAAATTGAACGGGAACCCATCACGGAGGATATAGCTCCACCCTACTTGTCCCAGCACAACGTAGTCCCAGCGAAATGGAGCTACTTACACCACGACGATCCCAACGTTTTATCGAAAAAGCATTATGCGATCTTCAGTATGCCTCCGCCCTACCATTCCACTCCGGACCAAGCTAAGAATAGCTTAGATTCCAATATGAACGCGAATATAACGAACAAAAATAGCAGCAATAACTCCAGTCCTTTGATTGGTTTTGATAATAAGTCCAGTCTACTTGGACACGATGTGCACTTCGAGAAGTGTAAGAGAGGTGAAGACTTTAGACTCTTCGATCCAAACGATCCTTGCTATCTCGACGACGGTATGGGTTTCGATCTTCAGAGCATACTCTCTATAGAGCTCTTGGAAAACGCCAGCAATAACCCAAGACTAGTCGAAGCCAAGAATGAAGAGGTGCACAGGAGAGTGGCAGAAATGCAGAAATTGGTCGAGAATTCTGAACAGTATTTAACTGAAAACTGTGATGTTTATAGTGAGGATTTATATCATGATGCGTTTATAAGAGATGAGTTAGTTGGTAGAGAGACCAGTGTCGATAATTTGGAAAGCGATACTGAGTCTAATAATAGTAGAATGTCTATGGCTGATGACGCTCCTGGCATCTTAAAACACAGCGATTCGCTTTTGCTTCTAACTGAAACTATAAATCAGGGTTTGAGTGTACTGCCTGTGTCAGAAAATGACAATAATGTTAGTGGCTTGACGGCGCGACAGTCTCAAGGGCTTAGTACCATATTAAATAATTGTGGTCTCACAGACGCTTTAATAGCTTTAAATAATGATATTTGTCATTCAGAAAGTGATAATGATTCATTATACACTCCTACGAACAGCCCCATACGGAGACATCAGAACAAAACGCCAAATAAAGCAGTTAGAACTAGTTTTGGTTTGCACAGCCCAGAGGCAATACAAGAAAATAAAGAACCGAATTTGAAAGATTACTTGAAGCAACTAAGAGAAAAGAGCAATAGAGATGAAGCGGCAAGTACAGAGTATCATCCATTTTATTATCAGGAGAGCCTAGTTGATAGTGACGTCGAGCTTATAGATTTAACTTTAATACCACCCCCACAAACTCCTGATGAATTGGATTGCGCCACACAAGTGCCTCAAATTCTCCCAGTCGTACCACCCTCTTTCGCAGATGAAAAAACAAGTTCAACAGAAAATATTTCGGATGCACCAAAAACTAGTGATTTGGAAGAATTCATCGCCAATGTTACAATACAACCGCCCACTGTTAAAGTCACGCCTGCAATAGAACTGACGCCAGAAGAGATAATGTCTTACATCATTCCGCCACCCCCAGGGTCCAATACATCTACTCTAGACAGAGATGAAGTAGGATACGCGAACCAAACCCAGATCTTAGAAGCAAAACTTGCACAAAACGTAAACGATAACACCAAAACATCAAATGGAGATGTAGTTAAGGGACAGCTGAGTGTCAGTGAAATTAGGAATATGTTTGCAGCTAAAAGTCTGAGTGAAGCTAGGAATAGTTTGTTGCTCAAAGATAAAAGTAAAACTACAACACAAACGAAATCTGATTCCCCTAAAGGTAAACGGAAGAGCGTCTCAGGTGATAAACAAGCAAACGGTAACATACACGTTATAGAATACCCGACAGTCGAAAGAAAAGGCATGTTCTCCTGCTGCAGTAAAGATAAAAATAAGTCAGATGATAGCAACGATGAGGGAGAAAAAGTTGAAACTCAAATACAGAACTCTGATTCAATGCCCGACGTGTGCGAAATCAGGCCTCCTCCGAGAAGAAAAAGTTCTGATTGCAAAAAACCTCCTGAAAGACCTCCGAAGACAGCTCCAATACCTCCTCCGAGACCTCGGTCCAATTCTTTCACGTGTCTCAATAACGAATTGACTGCGGTCGAAATCAGCACCAATCATTTCAACACGCTAAATAATAGACAATTGAACTACAAGGTTATCTGCGATATTAATGAAAAAAGTGTACAAAATCCACCCCAAGTACCTCCTAGATTAGAGAACAAGGTTCTGTCACCACCCCCACCTATATTACTACCTCCAAAGAAGCCACCTCTCCCACCAGTTCCGAGCATCGAGGTACTCAGACTGAAGACATTACAAAAAAGTTCTCCAATCAGGAACCAAGAGCAAAGACTGGCCAGTATCGGATCGCCACATTTTCAGAGAAATTTAAATAGTTATAAGAACCTTGAGAACGAAAGCCGTGCGGATGACGAAGTGCACATCCGATCGACCCCAAACTACAGTTCCATGACGCTGCAGAGTCGACACGTTAGATCGAATTCAGAAACGAAAACCACAATCTTGAAGAACAAGGAAATGTCGACAGCTTTATCTTTGTGCTCACCTCAGATGAATCGGAGGTTTAGCAATAGACCAGATATATTGAACGGCGCTCCGTGCGACCAAAAAGTCTTCAGCCCTCCTCTAGACAGAAAGACTTTTAGCTCAAGTCCTACACCAAAAGTGAATCATGTTAGGTTTAAAGAAGACGTAGTGGATGACATTCCGACTCCTCCGTCGCCGCCGACGGTGAAGTTTCCAGAGTTCCAGGCGGGGAACAATGGGCACGTGTCCATAGAGAACTTGCTATGTAAAACGGAGGTGGCCGTCGACGGGTTGCTGCAGAGGCTGCATCAGGTAGCACAGAAATGTTCGCATCAACACGCGCACGGAGGCGGAGAAGATATTGATGAAGCCAAGTTTCAGCGAGCGCGCAGCGAATTGACTTCGTGCGCTGTGTCGTTGGTTGGGGCTTCACGGACACTAGTGGGGGCGCTGGGGGTCGCGCGGGGAGGTGCGGCTCCTACTGCACTAGCCGACTGCTTGACGCCTCTCCGACGACTGACCGATCTCGCTCAGGCGCTTGGAAGGCACACATCCTCACCGCTTCAAACAAGGAATTTGGTGCTCCGTGTTCATGACGTCACGGCAGCTTTTAAGGAACTAGCCGGGCAGGAAATGGCACAAATAATTCACGAGCACAACAATAAATCTAACAAGCAGCAAAATCAAGACACGGCGTCCACTCTAGAAGGGCAGTTAGCCCTGAGGGCAGAATGCTTAGCGAACGTTCTGGCAACATTACTAAGAAGTCTGAGGGTGTTTTCGCCGTGA
Protein
MTRTASWLPPAESWSSPRDCQEPDTEELPYGWEQALDNRGKSYYVNHINKTTTYVAPEGCSCESPPAPRDIVLERDPELGFGFVAGSEKPVLVRFVTDNSPSVGKLEPGDQILCVNGEDVSMAAREHVISAVRACTEKVTLRVCQPARAGNPTRRSALLSAAKRARLRARPPRVRFADSVQLNGAPMYPPSAFSLGDLCLPPMANVLKVFLENGQTKSFKYDTTTTVADVVTNLKEKLCIIAEEHFSLVVEHVKSLRRNKLTLLDPKESLARIAARPGSHKMRCLYRVVFMPTSAADLAQQDLAALDYLYLQCCNDVAQERFAPELQPEVALRLAALHMHQHALANNLSPAKLTVKAVEREFGLERFVPSSLLESMKRKELRRLIAHFLKLNSQMTGSQRHLTQLQAKLHYLDIVGGLPSYGAKCFSSSRPERVLLVSPRFGLSQIVGRTNSVPQQIASIDEVECVRVRRAGACAELAVFLRRDRVLALLMDDRDAAEMPLVIAGYYKLATGKELNVEIEREPITEDIAPPYLSQHNVVPAKWSYLHHDDPNVLSKKHYAIFSMPPPYHSTPDQAKNSLDSNMNANITNKNSSNNSSPLIGFDNKSSLLGHDVHFEKCKRGEDFRLFDPNDPCYLDDGMGFDLQSILSIELLENASNNPRLVEAKNEEVHRRVAEMQKLVENSEQYLTENCDVYSEDLYHDAFIRDELVGRETSVDNLESDTESNNSRMSMADDAPGILKHSDSLLLLTETINQGLSVLPVSENDNNVSGLTARQSQGLSTILNNCGLTDALIALNNDICHSESDNDSLYTPTNSPIRRHQNKTPNKAVRTSFGLHSPEAIQENKEPNLKDYLKQLREKSNRDEAASTEYHPFYYQESLVDSDVELIDLTLIPPPQTPDELDCATQVPQILPVVPPSFADEKTSSTENISDAPKTSDLEEFIANVTIQPPTVKVTPAIELTPEEIMSYIIPPPPGSNTSTLDRDEVGYANQTQILEAKLAQNVNDNTKTSNGDVVKGQLSVSEIRNMFAAKSLSEARNSLLLKDKSKTTTQTKSDSPKGKRKSVSGDKQANGNIHVIEYPTVERKGMFSCCSKDKNKSDDSNDEGEKVETQIQNSDSMPDVCEIRPPPRRKSSDCKKPPERPPKTAPIPPPRPRSNSFTCLNNELTAVEISTNHFNTLNNRQLNYKVICDINEKSVQNPPQVPPRLENKVLSPPPPILLPPKKPPLPPVPSIEVLRLKTLQKSSPIRNQEQRLASIGSPHFQRNLNSYKNLENESRADDEVHIRSTPNYSSMTLQSRHVRSNSETKTTILKNKEMSTALSLCSPQMNRRFSNRPDILNGAPCDQKVFSPPLDRKTFSSSPTPKVNHVRFKEDVVDDIPTPPSPPTVKFPEFQAGNNGHVSIENLLCKTEVAVDGLLQRLHQVAQKCSHQHAHGGGEDIDEAKFQRARSELTSCAVSLVGASRTLVGALGVARGGAAPTALADCLTPLRRLTDLAQALGRHTSSPLQTRNLVLRVHDVTAAFKELAGQEMAQIIHEHNNKSNKQQNQDTASTLEGQLALRAECLANVLATLLRSLRVFSP
Summary
Uniprot
EMBL
Proteomes
PRIDE
Interpro
Gene 3D
ProteinModelPortal
PDB
6QJD
E-value=0.000139607,
Score=113
Ontologies
GO
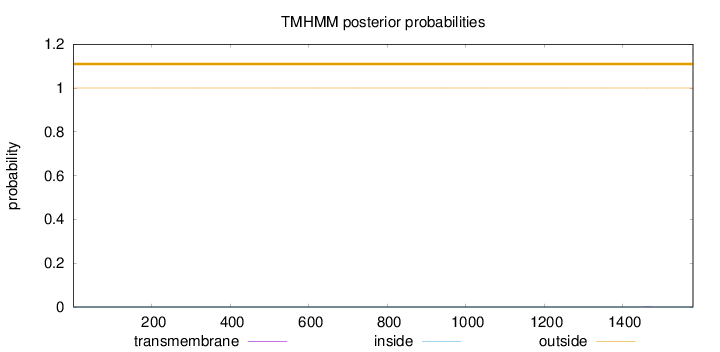
Topology
Length:
1579
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00662
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00004
outside
1 - 1579
Population Genetic Test Statistics
Pi
246.406051
Theta
168.985912
Tajima's D
0.85694
CLR
1.078369
CSRT
0.622668866556672
Interpretation
Uncertain
