Gene
KWMTBOMO13317 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA004674
Annotation
PREDICTED:_proteasome-associated_protein_ECM29_homolog_[Bombyx_mori]
Full name
Proteasome-associated protein ECM29 homolog
+ More
Proteasome adapter and scaffold protein ECM29
Proteasome adapter and scaffold protein ECM29
Alternative Name
Proteasome-associated protein ECM29 homolog
Location in the cell
Nuclear Reliability : 2.104
Sequence
CDS
ATGTCCGAGATGGATGTATCTGAGAGTGGAAGTGATTACTCAAATGACTTGTTGTTACTGGATAGAGTCTTTTTGCGACTTGGTAATGCTGATACTGATGAGCAGCTCGAAAGTTGCCTTAATAGATTCCTGCCGCCTGTTATATTGAAGTTATCATCTTCACATGAACAGGTCCGCACTAAAGTGATGGAGCTACTGGTGCATGTAAATAAGAGGGTGAAATGTCGTGCTGAAGTAAAATTACCTGTACAAACACTTCTGCAACTTTACATGGATCGTAATTCCAACAGTTTTATAATTAATTTTTCCATCATTTACATTACAATGGGGTTTCCGAGATTACCCCATGAACAACAAATTATATTAGCTCCATCACTGATAGAAGCAATGGATAATAAGCCCCAGGGACATCAAGACGGCCTTCTAATGTTGGTAATGCCTCTGTTGGGTGAAATTAAGGAAACGGATCTAAATTTGAAAGAGAAGCCAAAGCTGGCCACATTAATAGTAAAATTTGCCACAGATATACTTCTGTTGCCCTACAGAGCATTGCCAAATCAAGGAGAGACTGAGTTTCAAGTTCCACCAGGAATGAGTATGAAATCTTACAAGAGATTGGTTGAGAAAAATCTTTTGAATCCAAATCAACTAGAACAGATAAAGTTGTCTATTGTGAAATTTATAAGCAAAGACGTCTTCAATGACAACGATGTGCTTTTACCATTGATTGTCGCCGCAGCTGACTCACGATTCAGCGTTGCCAATCACGCGAACAGCCCCCTCATAAGAGTGAACAGCTCTGTAGACTGGTCGCAGCCATCAGTGGTATTCCCCTTATACTCTCTATATTTAGGCACTTGGGGAGGTTCCAAAGTGCCTCCAGACGATCGCAAGGTACCGGCTTGTACGCGCCTGCGATTGAAATTAATACAATATTTGATTAAGGCCACCGGTCCGGCGGTTTTGTTTCCGCATTGTGTTCAGGTGGTATTCGTGTCGTTGTTCGATCCGAACACAAACTCGCGTTTACGCAACCAAGGACTCGTGTTCTTGTCGAACGTGATCAGTTCCGGCGATCTTCTCCAGCTACAGAAAGTATCGACAGTATTCCTACAAGGTCTGCTGAAGATAATCAGATCTGAAGAGCATCCTGAACATCAACCCAAAGCCTACGTCTGTCTGGGTCGTCTAGCGATAAAGTGTCCGGACTGCGTGAGCAGCGGCCAGTTCTCGTTGCTCGAAGAGTTAATAAAGAAAATCCCAGAAGCCCCGCCCGAGATCAAAACGGCCATACGAGACGCGCTACTCGACATGGCCGTAGCTTACAAGACAAGTTTTGCAGAGAAGCAAAATTCTAAAGCCACGACACCGACTGAAGTCCCGTGCTCATCTCAAGATAAGATGGATGTCGATGAATCTGCTGAGGCTAAACCGAATTCCGTATTCGATGAAACGCAAGCACTAGTCTTGTTCGCTTTGTTGGACCATTACATGCAAAACGAGGAGTCGATGATACGCTATATAGCGATGCGCTACGCTTCGACCGTGTTCCCGCCCAAGTATATACCGGCGCGGTACTTGTTGCTGTTGGCCAGCGGAGACAGCAAAGACGAAATTTCGACGGAGGCCCTGAAATGTTTATACGGGACATCACGACCGAGCGAGATAGAGGATGTCGTAAACAATGTGGCGAAGAAAGAGACAAAAATCGTTATTTTCGACGGAGAGTCGCCCGATGAAAACAAAGACGTGTCTTCGGAAGGCGTCGACTTGGCCGTGCCGAAGTTCAAAGATATGGTCAACTACATATGGAAACAAATGCAGAAGAGGAAGAAGGGCTCGAACGCTAAGCATAGGTTCGTGATCAACAACCAGGTGCTGCAGTTTCATCCGCTGACTTATCAAGAGATACTAAGGTATCTTCGCATGTGTCTGAACCGCGACGCCGGCCTGAAGGATTGCTCGGATCACCCGAACGCGACGTCCCCGCTGCTCGCTAAGTACTTCTACGAGAACCTGCTCGACACGGAGCTGCTCGACCGATACCTCACGCTGATCACTTCGGTGCTGAACGCTAGTCCAGATTTAATGGCACTAACTTGCTTCTTGGACATTATCGGATGTATACCGGAGAAGATGGCCTCAAAGTACACAAATCTACTGCCTTTCTTGAGAAATTTGTTCACGACTAGCACCAAAGAACACATCAGGGACACGTCCGCGGTCATATATGCTATAATCTTCGTTCACACCAGCGAAAAAACGGCCATAGATAAGGAGATCTCCGAATTCGTTACGCAAGGAAAAAACAACAAGTCCCTAGAGAGTCAATGCGGATATTTGAGCGCCTTCGCGAATGTTTGCGAGAGGGCGGTCGTTTTGTCGACGCGCGGCAAGTTTGGCGGGAAAGGGTTTAGCGCCGCCGACTGGGAACCTTACCAAGAGGCCGCGTTGTGCTTGGCTAATTTCCTTATCAGTCCCCAAACGCTATTAGTGAGCGCCTCGTGTACTGCGATATCGCTGCTGGCTCGATGTTCCGGCCTGCCTTTACCCAATACATCGCCCAAAGAGGACACTCTCATACAGTCGGACAACCCGTTCAACGTAAACAAAACTATGGATGATTCGAACGACGTCGTGACTAAGTTCACCGTCGCTCAGAGACTGTTCAAGATCGTTGGAAACGCCAAGTTGCCGTCGAAGATCAAAGAGAGGGCGCTGTATACGCTAGGCCTTATGTGCTGCGGGGAAAGGTTGAGTTTCGCCAAACAAATCGTAATGGGATTCCTTGAGATGGCCAAAGATAGCAAGGAGTTTGAGATTCATTTACAAATAGGCGAGTCGTTGGTACTGTGCGTCGAAGGCGTGAATTCGAACGAAAATCGAGATCTTTGGACCGAATTACCGAAAGAGGGTGCAGATAAAGTCAAAGATTCAGAGGCTCTGAAGGAAAACGACGAGTTATTGGAATGGTTGTTAGAAGAATTGTTCAAGATTGCGAAACATCCGCATCCGCATTCGAGACAGGCCACAAGTATATGGTTACTCGCCTTGTTAAAGAACTGCCCAGAACGTTTCCCCATTAAGAACAAGGTGCAGGAGTTGCAGGACGCATTCATGGACTTCTTGTCGGAAAACAGCGACACAATACAAGACGTGGCCAGTAAGGGCCTGAGTCTCGTGTATCAGAACTCTGACGAAACCCAAAAGAAGTCGTTGGTCGGTCAAATCATAGAACAACTCACGAGCGGCAAGCGATCTGTGGCCCAAGTTACGGACGACACGAAGATATTTGAAGAGGGACAACTCGGAAAAGCCCCTACAGGAGGAAATCTTTCTACGTACAAGGAACTCTGCTCACTCGCTTCTGACTTGAACAAGCCAGATCTTTTGTACAAGTTCATGCATCTGGCGCATCACAACTCTATTTGGAATTCAAAGAAAGGGGCAGCATTTGGCTTCCACTCCATAGCGTCGCAAGCCGGGGCCCAGCTGTCCGAGCACCTGCCCCGGATAGTGCCGCGCCTGTACCGCTACCGGTTCGACCCCACGCCGCGCATACAGACCTCCATGACCAGCATATGGCACGCCATCGTGCCCAACACTCAGGCCACTGTTCAAAAATATCACAAGGAAATTCTGGACGATCTTGTAGCGAACATGACGTCGAATCAGTGGCGGGTGCGAATGGCCTGTTGCACTGCTCTGGCTGAACTGTTACGCGGTGCAAAAAGTCTTCACGATTCGTCGGAGCAGCTGTCGACGATCTGGTCGCAACTGTTCCGCGTCATGGACGACGTGCACGAGGGCACGCGCCAGGCCGCCGCCTCCACCGCCAACACGCTCTCCAAGCTCTGTATTCGCGCGTGTGACGTCAGTCAAGGAAAAGACGGCAAAGAAATCGTCGCGATCATACTGCCCGTCCTGTTGGACACCGGTATCACTAACGTAGTGAAGGAAGTCAGGGCTGTGTGCTTACAAACTGTATCGAAGCTGGTCGCTTCAGCGGGAGAGAGCCTAAAGCCGTTCCTGCCGAAGTTGATCCCCGCACTGGTGGGGGCGGCGGGGGAACTGGAGTCCGCCAAGCTGTCGTACCTCAGCACCGCGCTCGCGGACTCCGGCTCGCGGGACGTGCTCGACGACATGAGGGCCAGCGCCGCCAAACAGCACTACACCACCGACACAGTTGTCAAGTGTATGCCATACGTCGATATCGAGATCATGAAAGAGATGCTCCCTCAAATCTTGGAGCTGATGAAGTCACCGCAGCTCGGCACGAAGGTCTCCTGCTGCCACTTCATAGTGCTGACCGCGCACTATCTGAGGGCGGACCTCGAGCCGGTCGCGGGGAAGCTCATGAACAATCTACTGAACGGAGCCTTCGATAGGAACGTCACGGTGCGGAAGAATTATGCCGATGCCCTCGGTCAGGTTGCCGCTTTCGCCAAGCCCCAATCGGTCGAGAAACTGATGAAGAAGCTAGTGTCGCTGTACGAGACGAAGGAGGACGACGTGTCGCGCTCGGCCATCGCGCTCACCCTCAAAGCCGTGTCCAAGGCCAAGCTCGAACACATCAAGGACAACGAGGCCGTGCTGGCTCCCATGGTGTTCCTCGCCATGCACGGGCTGGAGGACGACGCGGAGATATTCGAAGACCTATGGATGGACATCAGCCCGGGCCGAGAGACCGGCATCAAACAGCATCTGCCCCTCATACGCACTGAGATAGAGCGGGCTCTCAACCTGAGCAGCTGGACCAAGAAGATACAGGCGGCGAACGCCATAAAGACAATATGCAAGGTGCTGTCGGCGGGGCTGGGCGAGCAGAGGGAGCAGTTCGTGCGCTCGCTGCTGGCCGCCATACACGGCAAGACCTACAGCGGCAAGCACAACGTGGTGCAGGCGCTCGCCGCACTGTGCGCGATAAAAGACAAGGAATCTCCATTATCTCCGGCGCTGGCCAACGAGTGCGTGAACGCGCTGCTGGCGGAGTGCCGCAAGCAGGACATGGTGTACAAGAAGCACGCCATCACGGCGCTGGGCGAAGCGCTCTCCGTCGTGCACTGCGATCGGTTCAGTCAAGTCTATGAGATTGTTAAAGTTATACTCTCCAAGGACGAATCGTCGGTGGGTAAAGATTCGGACGACGACGACATAGAGGGCGTGAGGCAGCGACGCGAACAGTTGTCCGAGCTCAAGGAGGCGGCCTACGAGCTGCTCGGCAAGGCCTGGCCAAAGGACTACGAGACACAGGAGAAATATCAAAACGAATTCTTCGAGCATTGTTCGTCAACGTTCCCCGCGTGCTCGCGCACCACCCAGCTGTCCATACTGATGTCCATCAACTACGTGGTGGAGCGGCTCGTCGTGCTGAACGGCAACGAGCCCATGGACACCGACGCCGATGACGTCACGCCAGCTGACCGCGACAAGGCCGTCAGTGCCGTCATCGGACACGTCGGCGCTGTCATCGACCACACTCTCACAAACATCAACCAGGTGCGCCACCGACGGGACGCCCTTAAAATTATGGAAATACTTATCAAACAATTAAAAGATCTCAAAAAACCCGAAGAACTCAATAGGCTAAGGAAAATATACCAGAACTACTCGAAAAATCTATCGAAGGATTCATCACACGAAATCAGAACCAATGCCGACAGTATTAAGGTTCTTCTGGAAAACTGGCCTTAG
Protein
MSEMDVSESGSDYSNDLLLLDRVFLRLGNADTDEQLESCLNRFLPPVILKLSSSHEQVRTKVMELLVHVNKRVKCRAEVKLPVQTLLQLYMDRNSNSFIINFSIIYITMGFPRLPHEQQIILAPSLIEAMDNKPQGHQDGLLMLVMPLLGEIKETDLNLKEKPKLATLIVKFATDILLLPYRALPNQGETEFQVPPGMSMKSYKRLVEKNLLNPNQLEQIKLSIVKFISKDVFNDNDVLLPLIVAAADSRFSVANHANSPLIRVNSSVDWSQPSVVFPLYSLYLGTWGGSKVPPDDRKVPACTRLRLKLIQYLIKATGPAVLFPHCVQVVFVSLFDPNTNSRLRNQGLVFLSNVISSGDLLQLQKVSTVFLQGLLKIIRSEEHPEHQPKAYVCLGRLAIKCPDCVSSGQFSLLEELIKKIPEAPPEIKTAIRDALLDMAVAYKTSFAEKQNSKATTPTEVPCSSQDKMDVDESAEAKPNSVFDETQALVLFALLDHYMQNEESMIRYIAMRYASTVFPPKYIPARYLLLLASGDSKDEISTEALKCLYGTSRPSEIEDVVNNVAKKETKIVIFDGESPDENKDVSSEGVDLAVPKFKDMVNYIWKQMQKRKKGSNAKHRFVINNQVLQFHPLTYQEILRYLRMCLNRDAGLKDCSDHPNATSPLLAKYFYENLLDTELLDRYLTLITSVLNASPDLMALTCFLDIIGCIPEKMASKYTNLLPFLRNLFTTSTKEHIRDTSAVIYAIIFVHTSEKTAIDKEISEFVTQGKNNKSLESQCGYLSAFANVCERAVVLSTRGKFGGKGFSAADWEPYQEAALCLANFLISPQTLLVSASCTAISLLARCSGLPLPNTSPKEDTLIQSDNPFNVNKTMDDSNDVVTKFTVAQRLFKIVGNAKLPSKIKERALYTLGLMCCGERLSFAKQIVMGFLEMAKDSKEFEIHLQIGESLVLCVEGVNSNENRDLWTELPKEGADKVKDSEALKENDELLEWLLEELFKIAKHPHPHSRQATSIWLLALLKNCPERFPIKNKVQELQDAFMDFLSENSDTIQDVASKGLSLVYQNSDETQKKSLVGQIIEQLTSGKRSVAQVTDDTKIFEEGQLGKAPTGGNLSTYKELCSLASDLNKPDLLYKFMHLAHHNSIWNSKKGAAFGFHSIASQAGAQLSEHLPRIVPRLYRYRFDPTPRIQTSMTSIWHAIVPNTQATVQKYHKEILDDLVANMTSNQWRVRMACCTALAELLRGAKSLHDSSEQLSTIWSQLFRVMDDVHEGTRQAAASTANTLSKLCIRACDVSQGKDGKEIVAIILPVLLDTGITNVVKEVRAVCLQTVSKLVASAGESLKPFLPKLIPALVGAAGELESAKLSYLSTALADSGSRDVLDDMRASAAKQHYTTDTVVKCMPYVDIEIMKEMLPQILELMKSPQLGTKVSCCHFIVLTAHYLRADLEPVAGKLMNNLLNGAFDRNVTVRKNYADALGQVAAFAKPQSVEKLMKKLVSLYETKEDDVSRSAIALTLKAVSKAKLEHIKDNEAVLAPMVFLAMHGLEDDAEIFEDLWMDISPGRETGIKQHLPLIRTEIERALNLSSWTKKIQAANAIKTICKVLSAGLGEQREQFVRSLLAAIHGKTYSGKHNVVQALAALCAIKDKESPLSPALANECVNALLAECRKQDMVYKKHAITALGEALSVVHCDRFSQVYEIVKVILSKDESSVGKDSDDDDIEGVRQRREQLSELKEAAYELLGKAWPKDYETQEKYQNEFFEHCSSTFPACSRTTQLSILMSINYVVERLVVLNGNEPMDTDADDVTPADRDKAVSAVIGHVGAVIDHTLTNINQVRHRRDALKIMEILIKQLKDLKKPEELNRLRKIYQNYSKNLSKDSSHEIRTNADSIKVLLENWP
Summary
Description
Adapter/scaffolding protein that binds to the 26S proteasome, motor proteins and other compartment specific proteins. May couple the proteasome to different compartments including endosome, endoplasmic reticulum and centrosome. May play a role in ERAD and other enhanced proteolyis (By similarity). Promotes proteasome dissociation under oxidative stress (PubMed:26802743).
Subunit
Associated with the proteasome.
Non-stoichiometric component of the proteasome; associates with the 26S proteasome. Interacts (via N-terminus) with VPS11, VPS26A, VPS36, RAB11FIP4 and RABEP1. Interacts (via C-terminus) with DCTN1, DCTN2, KIF5B, MYH7, MYH10, MYO10 and ARF6.
Non-stoichiometric component of the proteasome; associates with the 26S proteasome. Interacts (via N-terminus) with VPS11, VPS26A, VPS36, RAB11FIP4 and RABEP1. Interacts (via C-terminus) with DCTN1, DCTN2, KIF5B, MYH7, MYH10, MYO10 and ARF6.
Similarity
Belongs to the cytochrome P450 family.
Belongs to the ECM29 family.
Belongs to the ECM29 family.
Keywords
Complete proteome
Cytoplasm
Phosphoprotein
Proteasome
Reference proteome
Repeat
Alternative splicing
Cytoplasmic vesicle
Cytoskeleton
Endoplasmic reticulum
Endosome
Isopeptide bond
Nucleus
Ubl conjugation
Feature
chain Proteasome-associated protein ECM29 homolog
splice variant In isoform 2.
splice variant In isoform 2.
Uniprot
H9J584
A0A2H1VCY3
A0A3S2M257
A0A212FFD3
A0A2W1BP77
A0A194R5V3
+ More
A0A067QU84 A0A2J7QCG9 A0A2J7QCH5 D6X1U0 A0A1Y1KYA0 A0A195FVI6 F4WJT6 E2BPU0 A0A1W4WAW0 A0A158NS36 E0W1F4 A0A026W6B8 A0A2A3E5A8 A0A088ALS7 A0A232EX64 A0A195C0X2 A0A0C9PT13 A0A0N0BGA1 A0A1B6FFT6 N6UEA3 A0A151WGW1 B0WTH1 A0A1Q3F7U2 Q16ME7 A0A195DE56 A0A1S4FW64 A0A182S5G9 A0A182W1W8 A0A182RYY5 Q7PV57 A0A182YL94 A0A182L4W9 A0A182JSK2 A0A182P7H4 A0A182USN4 B4KTL6 A0A182LVJ6 A0A182XGR7 A0A1W4U603 A0A3B0JP65 B3MC86 B4LJS2 A0A1I8MU05 B3NS63 T1PGS3 A0A151NEB9 A0A3Q0GZ51 A0A286XPV3 A0A286Y3L2 Q292C8 A0A336L3V3 B4P5M3 B4G9W3 H0VD83 G1SLF8 A0A1I8PQ69 V4B4F0 A0A3Q2LTI2 Q9V677 F6RFP4 F6S581 A0A182UK46 H0X4Q7 A0A091D6R6 A0A3Q7QDG1 A0A3Q0DFP7 A0A3Q7QNM5 F7GF15 A0A3Q7QDM5 Q6PDI5-2 F1SNC6 A0A287ARA7 K1RL00 A0A336LCJ9 Q6PDI5 I3LXT5 A0A3Q7SS55 A0A287AH75 G3I5Z8 B4MY90 G1MI18 A0A2Y9H718 A0A250YMF2 A0A1U7TUR5 B4JW68 W5P9T6 W5P9U2 M3W6P6
A0A067QU84 A0A2J7QCG9 A0A2J7QCH5 D6X1U0 A0A1Y1KYA0 A0A195FVI6 F4WJT6 E2BPU0 A0A1W4WAW0 A0A158NS36 E0W1F4 A0A026W6B8 A0A2A3E5A8 A0A088ALS7 A0A232EX64 A0A195C0X2 A0A0C9PT13 A0A0N0BGA1 A0A1B6FFT6 N6UEA3 A0A151WGW1 B0WTH1 A0A1Q3F7U2 Q16ME7 A0A195DE56 A0A1S4FW64 A0A182S5G9 A0A182W1W8 A0A182RYY5 Q7PV57 A0A182YL94 A0A182L4W9 A0A182JSK2 A0A182P7H4 A0A182USN4 B4KTL6 A0A182LVJ6 A0A182XGR7 A0A1W4U603 A0A3B0JP65 B3MC86 B4LJS2 A0A1I8MU05 B3NS63 T1PGS3 A0A151NEB9 A0A3Q0GZ51 A0A286XPV3 A0A286Y3L2 Q292C8 A0A336L3V3 B4P5M3 B4G9W3 H0VD83 G1SLF8 A0A1I8PQ69 V4B4F0 A0A3Q2LTI2 Q9V677 F6RFP4 F6S581 A0A182UK46 H0X4Q7 A0A091D6R6 A0A3Q7QDG1 A0A3Q0DFP7 A0A3Q7QNM5 F7GF15 A0A3Q7QDM5 Q6PDI5-2 F1SNC6 A0A287ARA7 K1RL00 A0A336LCJ9 Q6PDI5 I3LXT5 A0A3Q7SS55 A0A287AH75 G3I5Z8 B4MY90 G1MI18 A0A2Y9H718 A0A250YMF2 A0A1U7TUR5 B4JW68 W5P9T6 W5P9U2 M3W6P6
Pubmed
19121390
22118469
28756777
26354079
24845553
18362917
+ More
19820115 28004739 21719571 20798317 21347285 20566863 24508170 30249741 28648823 23537049 17510324 12364791 25244985 20966253 17994087 25315136 22293439 21993624 15632085 17550304 23254933 19892987 10731132 12537572 17372656 18327897 26319212 28071753 18464734 19468303 15489334 16141072 14621295 15496406 21183079 26802743 22992520 21804562 20010809 28087693 20809919 17975172
19820115 28004739 21719571 20798317 21347285 20566863 24508170 30249741 28648823 23537049 17510324 12364791 25244985 20966253 17994087 25315136 22293439 21993624 15632085 17550304 23254933 19892987 10731132 12537572 17372656 18327897 26319212 28071753 18464734 19468303 15489334 16141072 14621295 15496406 21183079 26802743 22992520 21804562 20010809 28087693 20809919 17975172
EMBL
BABH01039721
BABH01039722
BABH01039723
BABH01039724
BABH01039725
BABH01039726
+ More
ODYU01001882 SOQ38710.1 RSAL01000068 RVE49284.1 AGBW02008829 OWR52441.1 KZ150103 PZC73483.1 KQ460883 KPJ11246.1 KK852936 KDR13581.1 NEVH01016289 PNF26281.1 PNF26284.1 KQ971371 EFA09963.2 GEZM01070671 JAV66344.1 KQ981208 KYN44655.1 GL888186 EGI65578.1 GL449658 EFN82291.1 ADTU01024454 ADTU01024455 ADTU01024456 DS235870 EEB19460.1 KK107374 QOIP01000010 EZA51595.1 RLU18101.1 KZ288391 PBC26359.1 NNAY01001792 OXU22910.1 KQ978457 KYM93818.1 GBYB01003103 GBYB01004513 JAG72870.1 JAG74280.1 KQ435789 KOX74488.1 GECZ01020700 JAS49069.1 APGK01038495 KB740960 KB631698 ENN76982.1 ERL85476.1 KQ983136 KYQ47083.1 DS232085 EDS34409.1 GFDL01011405 JAV23640.1 CH477863 EAT35512.1 KQ980989 KYN10709.1 AAAB01008986 EAA00430.5 CH933808 EDW09599.1 AXCM01000489 OUUW01000001 SPP75116.1 CH902619 EDV36186.1 CH940648 EDW60581.2 CH954179 EDV56365.1 KA647904 AFP62533.1 AKHW03003207 KYO35156.1 AAKN02049958 CM000071 EAL24934.2 UFQS01001622 UFQT01001622 SSX11653.1 SSX31218.1 CM000158 EDW90820.1 CH479181 EDW31715.1 AAGW02033961 KB199650 ESP05333.1 AE013599 AY069224 AAQR03034373 AAQR03034374 AAQR03034375 AAQR03034376 AAQR03034377 AAQR03034378 AAQR03034379 AAQR03034380 AAQR03034381 KN123095 KFO26732.1 AL805972 AL806535 AL929394 BC025035 BC058684 AK030369 AK038775 AK129127 AEMK02000005 JH816112 EKC42290.1 SSX11654.1 SSX31219.1 AGTP01059010 AGTP01059011 JH001327 EGW11193.1 CH963894 EDW77079.1 ACTA01050229 ACTA01058229 ACTA01066229 ACTA01074229 GFFW01000024 JAV44764.1 CH916375 EDV98206.1 AMGL01047197 AMGL01047198 AMGL01047199 AANG04004382
ODYU01001882 SOQ38710.1 RSAL01000068 RVE49284.1 AGBW02008829 OWR52441.1 KZ150103 PZC73483.1 KQ460883 KPJ11246.1 KK852936 KDR13581.1 NEVH01016289 PNF26281.1 PNF26284.1 KQ971371 EFA09963.2 GEZM01070671 JAV66344.1 KQ981208 KYN44655.1 GL888186 EGI65578.1 GL449658 EFN82291.1 ADTU01024454 ADTU01024455 ADTU01024456 DS235870 EEB19460.1 KK107374 QOIP01000010 EZA51595.1 RLU18101.1 KZ288391 PBC26359.1 NNAY01001792 OXU22910.1 KQ978457 KYM93818.1 GBYB01003103 GBYB01004513 JAG72870.1 JAG74280.1 KQ435789 KOX74488.1 GECZ01020700 JAS49069.1 APGK01038495 KB740960 KB631698 ENN76982.1 ERL85476.1 KQ983136 KYQ47083.1 DS232085 EDS34409.1 GFDL01011405 JAV23640.1 CH477863 EAT35512.1 KQ980989 KYN10709.1 AAAB01008986 EAA00430.5 CH933808 EDW09599.1 AXCM01000489 OUUW01000001 SPP75116.1 CH902619 EDV36186.1 CH940648 EDW60581.2 CH954179 EDV56365.1 KA647904 AFP62533.1 AKHW03003207 KYO35156.1 AAKN02049958 CM000071 EAL24934.2 UFQS01001622 UFQT01001622 SSX11653.1 SSX31218.1 CM000158 EDW90820.1 CH479181 EDW31715.1 AAGW02033961 KB199650 ESP05333.1 AE013599 AY069224 AAQR03034373 AAQR03034374 AAQR03034375 AAQR03034376 AAQR03034377 AAQR03034378 AAQR03034379 AAQR03034380 AAQR03034381 KN123095 KFO26732.1 AL805972 AL806535 AL929394 BC025035 BC058684 AK030369 AK038775 AK129127 AEMK02000005 JH816112 EKC42290.1 SSX11654.1 SSX31219.1 AGTP01059010 AGTP01059011 JH001327 EGW11193.1 CH963894 EDW77079.1 ACTA01050229 ACTA01058229 ACTA01066229 ACTA01074229 GFFW01000024 JAV44764.1 CH916375 EDV98206.1 AMGL01047197 AMGL01047198 AMGL01047199 AANG04004382
Proteomes
UP000005204
UP000283053
UP000007151
UP000053240
UP000027135
UP000235965
+ More
UP000007266 UP000078541 UP000007755 UP000008237 UP000192223 UP000005205 UP000009046 UP000053097 UP000279307 UP000242457 UP000005203 UP000215335 UP000078542 UP000053105 UP000019118 UP000030742 UP000075809 UP000002320 UP000008820 UP000078492 UP000075901 UP000075920 UP000075900 UP000007062 UP000076408 UP000075882 UP000075881 UP000075885 UP000075903 UP000009192 UP000075883 UP000076407 UP000192221 UP000268350 UP000007801 UP000008792 UP000095301 UP000008711 UP000050525 UP000189705 UP000005447 UP000001819 UP000002282 UP000008744 UP000001811 UP000095300 UP000030746 UP000002281 UP000000803 UP000075902 UP000005225 UP000028990 UP000286641 UP000189706 UP000002279 UP000000589 UP000008227 UP000005408 UP000005215 UP000286640 UP000001075 UP000007798 UP000008912 UP000248481 UP000189704 UP000001070 UP000002356 UP000011712
UP000007266 UP000078541 UP000007755 UP000008237 UP000192223 UP000005205 UP000009046 UP000053097 UP000279307 UP000242457 UP000005203 UP000215335 UP000078542 UP000053105 UP000019118 UP000030742 UP000075809 UP000002320 UP000008820 UP000078492 UP000075901 UP000075920 UP000075900 UP000007062 UP000076408 UP000075882 UP000075881 UP000075885 UP000075903 UP000009192 UP000075883 UP000076407 UP000192221 UP000268350 UP000007801 UP000008792 UP000095301 UP000008711 UP000050525 UP000189705 UP000005447 UP000001819 UP000002282 UP000008744 UP000001811 UP000095300 UP000030746 UP000002281 UP000000803 UP000075902 UP000005225 UP000028990 UP000286641 UP000189706 UP000002279 UP000000589 UP000008227 UP000005408 UP000005215 UP000286640 UP000001075 UP000007798 UP000008912 UP000248481 UP000189704 UP000001070 UP000002356 UP000011712
Interpro
Gene 3D
ProteinModelPortal
H9J584
A0A2H1VCY3
A0A3S2M257
A0A212FFD3
A0A2W1BP77
A0A194R5V3
+ More
A0A067QU84 A0A2J7QCG9 A0A2J7QCH5 D6X1U0 A0A1Y1KYA0 A0A195FVI6 F4WJT6 E2BPU0 A0A1W4WAW0 A0A158NS36 E0W1F4 A0A026W6B8 A0A2A3E5A8 A0A088ALS7 A0A232EX64 A0A195C0X2 A0A0C9PT13 A0A0N0BGA1 A0A1B6FFT6 N6UEA3 A0A151WGW1 B0WTH1 A0A1Q3F7U2 Q16ME7 A0A195DE56 A0A1S4FW64 A0A182S5G9 A0A182W1W8 A0A182RYY5 Q7PV57 A0A182YL94 A0A182L4W9 A0A182JSK2 A0A182P7H4 A0A182USN4 B4KTL6 A0A182LVJ6 A0A182XGR7 A0A1W4U603 A0A3B0JP65 B3MC86 B4LJS2 A0A1I8MU05 B3NS63 T1PGS3 A0A151NEB9 A0A3Q0GZ51 A0A286XPV3 A0A286Y3L2 Q292C8 A0A336L3V3 B4P5M3 B4G9W3 H0VD83 G1SLF8 A0A1I8PQ69 V4B4F0 A0A3Q2LTI2 Q9V677 F6RFP4 F6S581 A0A182UK46 H0X4Q7 A0A091D6R6 A0A3Q7QDG1 A0A3Q0DFP7 A0A3Q7QNM5 F7GF15 A0A3Q7QDM5 Q6PDI5-2 F1SNC6 A0A287ARA7 K1RL00 A0A336LCJ9 Q6PDI5 I3LXT5 A0A3Q7SS55 A0A287AH75 G3I5Z8 B4MY90 G1MI18 A0A2Y9H718 A0A250YMF2 A0A1U7TUR5 B4JW68 W5P9T6 W5P9U2 M3W6P6
A0A067QU84 A0A2J7QCG9 A0A2J7QCH5 D6X1U0 A0A1Y1KYA0 A0A195FVI6 F4WJT6 E2BPU0 A0A1W4WAW0 A0A158NS36 E0W1F4 A0A026W6B8 A0A2A3E5A8 A0A088ALS7 A0A232EX64 A0A195C0X2 A0A0C9PT13 A0A0N0BGA1 A0A1B6FFT6 N6UEA3 A0A151WGW1 B0WTH1 A0A1Q3F7U2 Q16ME7 A0A195DE56 A0A1S4FW64 A0A182S5G9 A0A182W1W8 A0A182RYY5 Q7PV57 A0A182YL94 A0A182L4W9 A0A182JSK2 A0A182P7H4 A0A182USN4 B4KTL6 A0A182LVJ6 A0A182XGR7 A0A1W4U603 A0A3B0JP65 B3MC86 B4LJS2 A0A1I8MU05 B3NS63 T1PGS3 A0A151NEB9 A0A3Q0GZ51 A0A286XPV3 A0A286Y3L2 Q292C8 A0A336L3V3 B4P5M3 B4G9W3 H0VD83 G1SLF8 A0A1I8PQ69 V4B4F0 A0A3Q2LTI2 Q9V677 F6RFP4 F6S581 A0A182UK46 H0X4Q7 A0A091D6R6 A0A3Q7QDG1 A0A3Q0DFP7 A0A3Q7QNM5 F7GF15 A0A3Q7QDM5 Q6PDI5-2 F1SNC6 A0A287ARA7 K1RL00 A0A336LCJ9 Q6PDI5 I3LXT5 A0A3Q7SS55 A0A287AH75 G3I5Z8 B4MY90 G1MI18 A0A2Y9H718 A0A250YMF2 A0A1U7TUR5 B4JW68 W5P9T6 W5P9U2 M3W6P6
Ontologies
KEGG
GO
GO:0043248
GO:0000502
GO:0042765
GO:0016255
GO:0016021
GO:0020037
GO:0016705
GO:0005506
GO:0004497
GO:0005634
GO:0005737
GO:0070628
GO:0005813
GO:0005793
GO:0005770
GO:0030433
GO:0005783
GO:0031410
GO:0030134
GO:0005771
GO:0030139
GO:0005769
GO:0032947
GO:0005488
GO:0008270
GO:0016881
GO:0031386
GO:0048869
GO:0003676
GO:0016491
GO:0015930
GO:0060090
PANTHER
Topology
Subcellular location
Cytoplasm
Endoplasmic reticulum
Endoplasmic reticulum-Golgi intermediate compartment
Endosome
Cytoskeleton
Microtubule organizing center
Centrosome
Nucleus
Multivesicular body
Cytoplasmic vesicle
Endoplasmic reticulum
Endoplasmic reticulum-Golgi intermediate compartment
Endosome
Cytoskeleton
Microtubule organizing center
Centrosome
Nucleus
Multivesicular body
Cytoplasmic vesicle
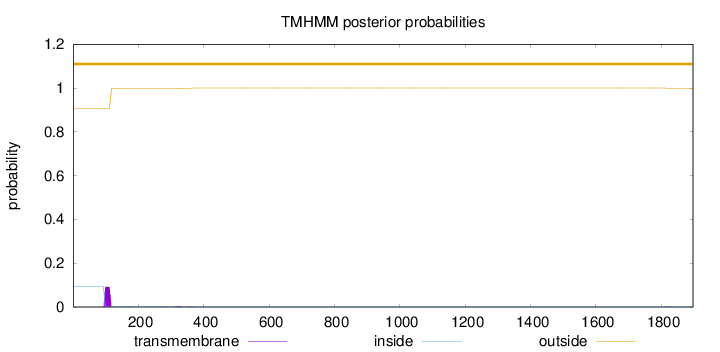
Length:
1897
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
1.80269000000001
Exp number, first 60 AAs:
0
Total prob of N-in:
0.09286
outside
1 - 1897
Population Genetic Test Statistics
Pi
183.917833
Theta
157.163797
Tajima's D
0.536603
CLR
0.144352
CSRT
0.525523723813809
Interpretation
Uncertain
