Gene
KWMTBOMO13101 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA000387
Annotation
PREDICTED:_uncharacterized_protein_LOC101739891_isoform_X2_[Bombyx_mori]
Location in the cell
PlasmaMembrane Reliability : 3.124
Sequence
CDS
ATGGATGGAGTTATTATGTGGCCGATTCCAGTGTCTGAAAGTATCTTAGATACACACACTGGATACGTGCTCGACAGAGGCACAACTGACATCGAAGACATCACCACAATAAGGTACGGCGAGGGCTTAAACGCTGGACCCTACTTAGAAGTTTCCCACGCTCAGAACCGATTCCAAATGTGGGTTAACGATGCTTATAGAAACTACGAGGAGAACGAAGTCGCCCAGTCAATGTCAATGACCGTGACATTCAGATGTACCGGAGGCACAACCAATACTCTGGTGTTTTTGATAAACGTGATCGATACTAATAACAATGCACCACAGTTCAGGCCAAATGACATATTTGAATACGTTATAACGACACCTCTCGCTCCCGGCTTCCTTGTAACGGGCTGCTTCAATAACATTGTCGTCAGAGACATAGACCTTACAACGCAAAGAATAGATTTCGGAATCGAAGAAAATCCATATATTGACATCGCATATGATTCCTCGCTTTCCACAACACCAAAAGAATTTAAGGCCGTTCTAAGAACTAAAACCTTCATTAGAACGATACCTGAACTTCTCACACTTAAAATTAGCGCAACGGACGTAGATTTGACTGGAGACCCTCCCAGAACAACATACGCCACGGTGCATATCAAGAGTGATCCAGAATTCGAATTCCCTGAGGAACCGGTATTCTCTCGAGCATTTTATTTGGCGAATTACGATGAAGGGAAAATTACACATGATGCTATATCTTTGAGACAAGGTTTCGATGACCAAGTCCAGTTTTCCCTAGACGGTGATTACGCAACTAATTTCCAATTGAACCAAAACGGTAACCAAATAACTTTAACTGTTAGAACACCACTATCTAATATAGACGTGAGTCAAATTTTACTGATTGTCAAAGCCGAAAGGGAATATACGAGCGGAGCATCAGCCACGGTCATAGTGCAATTACCTGAAGAAGTGAATTTGGAATTTGAAAGGGCTCACTATAGTGGACAGATCGAGAACAACATCTTACGGCTGTCACAGCTGACACTAATACAAGGCTTTGAAGGGTCAATTTCCGCTCGAATTATTGGCGAACACGCATCATACTTTAGCGTTACAGTACAAGGAAATTCTGTGACAATAACAATGGCCCCTCTAACAGAAAATATTATTCGAGACAACAACTTTATTTATTTAGAAGTCATAGTTTCCGCAGAGCGTGGCTTAGGCTCTGCAGTTGTTACATTAGAAATTATTAAGGATGATAATACAACACCAGTTTTTAGTAGTAAAATTTACACGGGAAATTATGACGTCGTCAATGGACTAAACATAGAGCCTATATATTTCGTCCAAGGATATGATGATTCAGTATCCTTAAAATTAGATGGAGATTCCTCTGAACTGTTTGAAGTAGAAAGAGACGGTGCTATCATAAAGATTACTTCTTCAGCGTTGCCAGTAGAAATACATAGCCGATCGAATTTAATTCTCTCATTAGAAGCAACTAAACCAAGAACTGTTGGAGCGAATGCAGCGATTGTAATCAATCTTCCTGAAGAACCCAGTGATGGAATGAGTCTCCTCGGATTTGAGAGGGTCACATACGTGGGATCCATAGAAGATAACACTGTAGCTCTGGGCTCAATAGCTTTGACGGAAGGGTTCTCAACCAGCGTTTCCTTTACTTTGTTTGGCGAACTCGTCGATTTCTTCACCGTGACGGCGTCTGGTTCGACTGTAACAGTTGGGCTCCATAGGACCATCCCAGAAGATTTGATCCCCGCTAACCGAGTTATTGTCCTAGAGCTCCGAGCTTCAGCCCCACAAGCTGTGTCAGCTTACACTACTATCGTTCTTACAATCGCTAGGGATGAGGATTCGGCAGCTCCAGTCAACGATCTTGTTTTTGCTTCACCACATTATACTGGATCGTATAGCGAAATGAGTGGTTTGGTATTCGAAACTCCCATCTCTTTGTCTCAGGGATACGATACCGCAGTTCAATTTTCATTAGAAGGAGATAATGCGCAATGGTTTAGCCTAATCCAAAATCAAAATTCAGTTTCGTTGACATTAAGGACTCCAATACCGACAGCAGTTATTGCTAACAACCGTAAACTCATTTTCTCTGTCGCTGCACAAAGACCTGGCAGTATCACGATAAGAACCACAATCATCATTTCCCTGATCGACGAACCCAGTGATGGAATGAGTCTCCTCGGATTTGAGAGGGTCACATACGTGGGATCCATAGAAGACAACACTGTAGCTCTGGACTCAATAGCTTTGACGGAAGGCTTCTCAACCAGCGTTTCCTTTACTTTGTTTGGCGAACTCGTCGATTTCTTCACCGTGACGGCGTCTGGTTCGACTCTAACAATCGGGCTCCATAGGACCATCCCAAAAGATTTGATCCCCGCTAACCGAGTTATTGTCCTAGAGCTCCGAGCTTCAGCCCCACAAGCTGTGTCAGCTTACACTACTATCGTTCTTACAATCGCTAGGGATGAGGATTCGGCAGCTCCAGTCAACGATCTTGTTTTTGCTTCACCACATTATACTGGATCGTATAGCGAAATGAGTGGTTTGGTATTCGAAACTCCCATCTCTTTGTCTCAGGGATACGATACCGCAGTTCAATTTTCATTAGAAGGAGTTTCGTTGACATTAAGGACTCCAATACCGACAGCAGTTATTGCTAACAACCGTAAACTAATTTTCTCTGTCGCTGCACAAAGACCTGGCAGTATCACGATAAGAACTACAATCATCATTTCCCTGATCGACGAACCCAGTGATGGAATGAGTCTCCTCGGATTTGAGAGGGTCACATACGTGGGATCCATAGAAGACAACACTGTAGCTCTGGACTCAATAGCTTTGACGGAAGGCTTCTCAACCAGCGTTTCCTTTACTTTGTTTGGCGAACTCGTCGATTTCTTCACCGTGACGGCGTCTGGTTCGACTGTAACAATCGAGCTCCATAGGACCATCCCAGAAGATTTGATCCCTACTAACCGAGTTATTGTCCTAGAGCTCCGAGCTTCAGCCCCACAAGCCGTGTCAGCTTACACTACTATCGTTCTTACAACCGCTAGGGATGAGGATTCGGCAGCTCCAGTCAAAGATCTTGTTTTTGATTCACCACATTATACTGGATCGTATAGCGAAATGAGTGGTTTGGTATTCGAAACTCCCATCTCTTTGTCTCAGGGATACGATACCGCAGTTCAATTTTCATTAGAAGGAGTTTCGTTGACATTAAGGACTCCAATACCGACAGCAGTTATTGCTAACAACCGTAAACTCATTTTCTCTATCGCTGCACAAAGACCTGGCAGTATCACGATAAGAACCACAATCATCATTTCCCTGATCGACGAACCCAGTGATGGAATGAGTCTCCTCGGATTCGAGAGGGTCACATACGTGGGATCCATAGAAGATAACACTGTAGCTCTGGGTTCAATAGCTTTGACGGAAGGCTTCTCAACCAGCGTTTCCTTTACTTTGTTTGGCGAACTCGTCGATTTCTTCACCGTGACGGCGTCTGGTTCGACTGTAACAATCGGGCTACATAGGACCATCCCAGAAGATTTGATTCCTACTAACCGAGTTATTGTCCTAGAGCTCCGAGCTTCAGCCCCACAAGCCGTGTCAGCTTACACTACTATCGTTCTTACAATCGCTAGGGATGAGGATTCGACAGCTCCAGTCAACGATCTTGTTTTTGATTCACCACATTATACTGGATCATATACCGAAATAAACGGCTTAGTGTTTGATACGCCAATCTCTTTATCTCGGGGTTATGATGAAATGGTTATTTTTTATTTGGAAGGAGATAATACGCAATGGTTCAACCTGGTAAAAAAAGAGAATATTATTTCCCTAACATTAGCGATACCGATACCCTCAACGGTCCTCGCAAACAACCGAAAACTAATTTTTAATATCGCAGCACAAAGACCTGGCAGTGTCACCGCGAGGGCCACAATCATCATTTTATTATTAGAGGGTGAAGAGGTACCATCAAATGAATATTTCGATAAAGTTCTTTATGAGGGTCTGATTCAGGGAAATATTGTGCGGCACGAGCAGATAAATCTTTTTGGGTTTCTCGGAGAGAACATTCGATTGATTGGAGAGTATGCAAGTCTGTTCGGCGCGAACGTTAACAATGGTGTCATCACTATTCAGTTATCCGGATCGATACCAGTGCCGACTGACGTTACACTCATAGCTCTAGAACTACATGCCTTACGCGCAAGATCAGTGCTACTACTCACAGTGGAATCTACAGAAAACCCGAATCCGCCTCTGGTTGTTTTCGGGTCGTCGTCCTATGCTCTGCGCGTCGAAATTACACGGACCGGTCTCATCGGTCGTGTTCACGCAAGCGCCGATAATGGAGAAGCGGTCACCTATTCGCTCCGAACTGAAAACGTTCACTTGGTGGATCGTTTGTCAGTGAACAACGACGGTGAATTGCATCTGTCCGCACCCGCTAGCTCCGGGGTTTACACTTTCGAAGTCGTCGCTACTACAGTCTTCACACGGGCTTCAGCTCTTGCTATAGTACATTTGACAGTTGATGCAGCAACGATATGCGGTGATGATCTTGTTATGCCGCCTCTTTTAGTTATAGACAGAGATGAAGAATCACCTCACCGCGATTTAGTTGCTTTAAACCCAGAGAAACACGAAGGATGTCGTTACACCTTAACAAACCGGTGGCCGGTCGACCAAACTTGGCTATATGTTGATGATACAGGACTACACACAAGAGCCATCGACAGAGAACATGAATCTATAGCGTTCATGAAAGTATCACAAGTACAAGTTGAACTTATCCTTCATTGCGCGAACGATAAGGTCCGATCGAAGCGATCTATTGACCAAAAGACAAATTCAATTGCCGATTATGGGTCTAAGCATTGGATACTAACAGATTCGATCCTATACAACTCTAGGCGTAGTTTTGTGAATTTGATCGTGAATGATATAAATGACAACGCACCCGTGTTTGTTGGAAAGGAAAATGAACCGATCGCTGTGGGCTACCCGATCTCCGATTTAGAAGAAGTCTTGCTACCACGCTCTTTGGCCGAGTTAAAGGCCTCGGACGCAGATATAGGCGAGAATGCAGTCCTTCGTTACTGGAGCCATGAACCCGCGGTGGTGGTTTCTCCTACAACAGGATTCGTTCACGTACGCTCCGGAGCTCGCCTACATGATAACAAAGAGTTTACAGTGCACGCTACAGACAGAAACGGAGAAGGACTCACCGGACATATAAAACTACTTGTGAAATTACTGAATGTGAACAACATAGCGGTTGTTACAGTTCAGAATTCATTCCTAGATGATGAAATAAAAATTATTTCACAACTAAGCACCGGTGTTGGATACGAAGTTAAAGCACTGAGGTCCGATATAATATCAGATGCCGCCCAACCTAGCGACGACACAAGGAAGGAACGTGATGCGGGTGTGGCTGGAACTACCATGCAGCTCTATATTTATGGATTAAACGAACGGCAACCGGTTTCAGTGAAAAGACTAATAACTGACATAAATAACATTGCAATTATCGTGGACATCGTGGCGAATGCCATATCTCTTGAAGATCATCTAGAAGGTCGAGAGATATGCGTCATTGCGGAACGTGATACCGGCTTGTTGATCGCGTGCATACTCCTTAGTATCCTGCTCTTCATAATAATAGTTGTAGCTGTTGTCTGGTCCATACTTAAAAGAAGAAAAAGTCCGCATTATTCACAATTCAGTGACAAAAATAGCATAGCGTCACGAACTAACTCACTGGGTCAGCTACCGAAAACGGAAGCAGAACAAAAGCCGAGACTTTATATAGAAGATTTAAGAAAAAGTGAACGAAAACTTCAGGAAATATTAGATGCTCCTCCTCTTGAGGAAGTTAAAGCCTCGACATCGACAGAAAAACTGAGTGAGCCTCCAACAGAATCAATAATAGATATACCTGTAATGGAACCCAGCTTGCCCATAGTAATTCAATCAATAGATAAACTTAAAGATGCAACGGATGAATCTGATGACGATGAATTTGGCGAAAATAAAAAGAACAGAAGAAAATCTGTAGTAACCTTTAACGAAAACGTTGAAAAGATAATTCATGTGGAAGATGATGATGATTCTACCTCGGTTCCGGGACAAAACCGTTAA
Protein
MDGVIMWPIPVSESILDTHTGYVLDRGTTDIEDITTIRYGEGLNAGPYLEVSHAQNRFQMWVNDAYRNYEENEVAQSMSMTVTFRCTGGTTNTLVFLINVIDTNNNAPQFRPNDIFEYVITTPLAPGFLVTGCFNNIVVRDIDLTTQRIDFGIEENPYIDIAYDSSLSTTPKEFKAVLRTKTFIRTIPELLTLKISATDVDLTGDPPRTTYATVHIKSDPEFEFPEEPVFSRAFYLANYDEGKITHDAISLRQGFDDQVQFSLDGDYATNFQLNQNGNQITLTVRTPLSNIDVSQILLIVKAEREYTSGASATVIVQLPEEVNLEFERAHYSGQIENNILRLSQLTLIQGFEGSISARIIGEHASYFSVTVQGNSVTITMAPLTENIIRDNNFIYLEVIVSAERGLGSAVVTLEIIKDDNTTPVFSSKIYTGNYDVVNGLNIEPIYFVQGYDDSVSLKLDGDSSELFEVERDGAIIKITSSALPVEIHSRSNLILSLEATKPRTVGANAAIVINLPEEPSDGMSLLGFERVTYVGSIEDNTVALGSIALTEGFSTSVSFTLFGELVDFFTVTASGSTVTVGLHRTIPEDLIPANRVIVLELRASAPQAVSAYTTIVLTIARDEDSAAPVNDLVFASPHYTGSYSEMSGLVFETPISLSQGYDTAVQFSLEGDNAQWFSLIQNQNSVSLTLRTPIPTAVIANNRKLIFSVAAQRPGSITIRTTIIISLIDEPSDGMSLLGFERVTYVGSIEDNTVALDSIALTEGFSTSVSFTLFGELVDFFTVTASGSTLTIGLHRTIPKDLIPANRVIVLELRASAPQAVSAYTTIVLTIARDEDSAAPVNDLVFASPHYTGSYSEMSGLVFETPISLSQGYDTAVQFSLEGVSLTLRTPIPTAVIANNRKLIFSVAAQRPGSITIRTTIIISLIDEPSDGMSLLGFERVTYVGSIEDNTVALDSIALTEGFSTSVSFTLFGELVDFFTVTASGSTVTIELHRTIPEDLIPTNRVIVLELRASAPQAVSAYTTIVLTTARDEDSAAPVKDLVFDSPHYTGSYSEMSGLVFETPISLSQGYDTAVQFSLEGVSLTLRTPIPTAVIANNRKLIFSIAAQRPGSITIRTTIIISLIDEPSDGMSLLGFERVTYVGSIEDNTVALGSIALTEGFSTSVSFTLFGELVDFFTVTASGSTVTIGLHRTIPEDLIPTNRVIVLELRASAPQAVSAYTTIVLTIARDEDSTAPVNDLVFDSPHYTGSYTEINGLVFDTPISLSRGYDEMVIFYLEGDNTQWFNLVKKENIISLTLAIPIPSTVLANNRKLIFNIAAQRPGSVTARATIIILLLEGEEVPSNEYFDKVLYEGLIQGNIVRHEQINLFGFLGENIRLIGEYASLFGANVNNGVITIQLSGSIPVPTDVTLIALELHALRARSVLLLTVESTENPNPPLVVFGSSSYALRVEITRTGLIGRVHASADNGEAVTYSLRTENVHLVDRLSVNNDGELHLSAPASSGVYTFEVVATTVFTRASALAIVHLTVDAATICGDDLVMPPLLVIDRDEESPHRDLVALNPEKHEGCRYTLTNRWPVDQTWLYVDDTGLHTRAIDREHESIAFMKVSQVQVELILHCANDKVRSKRSIDQKTNSIADYGSKHWILTDSILYNSRRSFVNLIVNDINDNAPVFVGKENEPIAVGYPISDLEEVLLPRSLAELKASDADIGENAVLRYWSHEPAVVVSPTTGFVHVRSGARLHDNKEFTVHATDRNGEGLTGHIKLLVKLLNVNNIAVVTVQNSFLDDEIKIISQLSTGVGYEVKALRSDIISDAAQPSDDTRKERDAGVAGTTMQLYIYGLNERQPVSVKRLITDINNIAIIVDIVANAISLEDHLEGREICVIAERDTGLLIACILLSILLFIIIVVAVVWSILKRRKSPHYSQFSDKNSIASRTNSLGQLPKTEAEQKPRLYIEDLRKSERKLQEILDAPPLEEVKASTSTEKLSEPPTESIIDIPVMEPSLPIVIQSIDKLKDATDESDDDEFGENKKNRRKSVVTFNENVEKIIHVEDDDDSTSVPGQNR
Summary
Uniprot
EMBL
KQ460883
KPJ11412.1
RSAL01000111
RVE47086.1
KQ459586
KPI97872.1
+ More
AGBW02011240 OWR46956.1 JTDY01000671 KOB76273.1 GDQN01007910 JAT83144.1 GFDL01007320 JAV27725.1 AXCM01003684 GFDL01007325 JAV27720.1 CH477631 EAT38078.1 AXCN02000946 ATLV01024034 ATLV01024035 KE525348 KFB50370.1 AAAB01008900 EAL40462.3
AGBW02011240 OWR46956.1 JTDY01000671 KOB76273.1 GDQN01007910 JAT83144.1 GFDL01007320 JAV27725.1 AXCM01003684 GFDL01007325 JAV27720.1 CH477631 EAT38078.1 AXCN02000946 ATLV01024034 ATLV01024035 KE525348 KFB50370.1 AAAB01008900 EAL40462.3
Proteomes
Interpro
Gene 3D
CDD
ProteinModelPortal
PDB
4ZPQ
E-value=0.0121723,
Score=98
Ontologies
GO
PANTHER
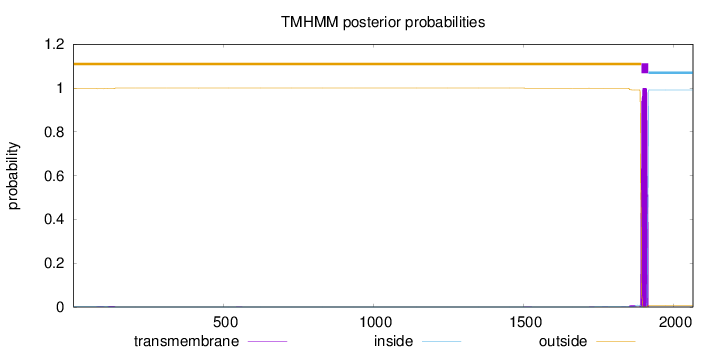
Topology
Length:
2065
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
23.20969
Exp number, first 60 AAs:
0.00021
Total prob of N-in:
0.00281
outside
1 - 1893
TMhelix
1894 - 1916
inside
1917 - 2065
Population Genetic Test Statistics
Pi
203.339489
Theta
175.891618
Tajima's D
0.727559
CLR
0.406103
CSRT
0.582070896455177
Interpretation
Uncertain
