Gene
KWMTBOMO13100
Pre Gene Modal
BGIBMGA000388
Annotation
Collagen_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 2.124
Sequence
CDS
ATGGGACCCGGAATAATGATTAAATTTTGTATCTTGGCGGTGCTAGCATTGTCACTGGTTAGCGCCGATAAGCCAAAAACTGAGACAACTTCAACGACCGCGAAAAAGGCAACTGAAGTACCCGCGAAGAAGACAGTCGAAGTACCTTTGAAGAAGGCATCTGAAGTGCCCGTGAAGAAGGCATCAGAAGTGCCAACAAAGAAGCCCCATGTAGAACCCGCGCGTGAAGGAAGGCAGTTGAGTCCTTACCCTGGACAACAAGACAACGAAGTGGTGGTCGACATTCAGGACGACGAAAAGAAGCAGTACTACGAAACCAACTATGACACAAGTGCGTATGGTTTCGGATACGATGTCGGCCCAAACGGACAGTTTCATCACGAGAACCGCGGTCCCGATGGTGTCGTCTACGGATGTTATGGTTACGTCGACACCGAGGGCTACCTCCGCGCCACCCACTACGTTGCCGACAGCCACGGCTACCGAGTCGTAGAACCAGAAAAACCTGTCGAAGTTTTCCCCGATGAGAAATACGAATATGACGAAAATTACGAACCCACGCCATCCGCGACGGGTCAAACCATTCCGTGGAATAAGTTATTCTTCCCCCAGGGATGCGGTCGCACTCCTGGCGGAGTTCCACCCCAACCGTTCAAACCAAAACCTAAACCTAAACCCCCTGTAGATAGCACCGGACAAACTAGCAACCCCAGTCCTGGCGTCGCATACCCTGGTCAAGGCCCTAATGGCCCTTACGGTCCTGGCGGCTCCGGCGGCTCCGGCGGCCCTGGTGGTCCCGGAGGACCAAATGGACCTTACGGACCTGGTGGTCCCGGAGGACCAAATGGACCTTACGGACCCGGCGGTACTGGCGGACCTAATGGTCCTTATGGCCCAGGTGGTCAAGATGGCTCATACAGACCAGACGGCTCCTACGGTCCAGACGGATCTTATCAACCGGAAGGTTCCTACGGACCCGACGGATCATGGCAAGGTGGTTACTATCCTGGCACTCCTGGATCGCCTGGAACTCCTGGGTCGCCTGGCAGCCCTGGATCCCCTGGTAGCCCGGGTACTCCTGGTTCTCCAGGCACACCAGGAACACCTGGTTCAGGCGGTGGATACTATCCTGGACAAGACGGAACAGGGGGACCGACTGGTCCTTCAGGCGGGGGAGGTGGCTACTATCCAGGTAGTCCCGGCAGTCCTGGAACCCCCGGCACTCCAGGCACACCCGGAACACCAGGTGGCCCTGGGGGTCCAGGTGGACCAGGTGGACCAGGTGGTCCAGGAGGGCCAAACGGTCCAAATGGGCCTGGAGGATCTGACGGCGGTCAATATTATCCTGCACTGCCCGGTAGTCCCGGTACACCCGGCTCCCCAGGCACTCCTGGTGGACCTGGTGGACCTGGTGGTCCCGGAGGCCCTGGGGGACCAGGCGGCCCAGGCGGCCCGGGAGGTCCAGATCAACCAAGCTACCCTGGACAGCCAGGACAGCCTGGTACACCAGGATATCCAGGACAACCAGGATACCCAGGACAACCCGGTACACCAGGACAACCAGGAACACCAGGCCAGCCAGGCTATCCAGGACAAGGTGGACAACCTATAAATCCTGGTCAACCAGGATACCCAGGCCAGCCCGGACAACCAGGATACCCGGGACAACCAGGTCAGCCAGGAACACCAGGACAACCCGGAACGCCTGGACAACCAGGAACGCCAGGACAACCAGGACAACCCGGCTATCCAGGAACTCCTGGGCAACCAGGGCAATCCGGATATCCAGGACAGGGTGGACCACAACAGGGAGGTCAGCCTATAAATCCTAGTCAACCCGGATACCCAGGTCAACCAGGACAACCTGGATATCCAGGCCAGCCCGGACAACCAGGAACACCAGGTCAACCCGGAACACCAGGTCAGCCTGGAACACCAGGACAACCAGGACAGCCCGGAACACCAGGACAACCAGGAACACCAGGACAACCAGGACAAGGTGGACAACCGATAAAACCTGGTCAGTCTGGATACCCAGGCCAGTCAGGTCAACCAGGATATCCAGGACAACCAGGACAGCCAGGAACACCAGGCCAGCCCGGAACACCAGGGCAGCCAGGTCAACCGGGACAGCCAGGGACTCCAGGCCAGCCCGGAACACCAGGGCAGCCAAGCTATCCAGGACAAGGTGGACAACCTATAAAGCCTGGTCAGCCAGGATACCCAGGTCAGCCAGGCCAGCCGGGATACCCAGGACAAGCAGGACAGCCAGGAACACCAGGATACCCAGGACAGCCAGGGACTACAGGCCAGCCCGGAACACCAGGGCAGCCAAGCTATCCAGGACAAGGTGGACAACCTATAAAGCCTGGTCAGCCAGGATACCCAGGTCAGCCAGGCCAGCCGGGATACCCAGGACAACCAGGACAGCCAGGAACACCAGGACAGCCAGGAACACCAGGACAGCCAGGAACACCAGGCCAGCCCGGAACACCAGGACAACCAGGTCAACCAGGCTACCCAGGACAAGGTGGACAGCCTGTAAATCCTGCTCAGCCGGGATACCCAGGACAGCCAGGTCAGCCAGGATACCCAGGACAACCAGGACAGCCAGGAACTCCAGGACAGCCCGGAACACCAGGACAGCCCGGAACACCAGGACAACCAGGTCAACCAGGCTACCCAGGACAAGGTGGACAGCCTGTAAATCCTGCTCAGCCGGGATACCCAGGTCAGCCAAGTCAGCCGGGATACCCAGGACAACCAGGACAGCCAGGAACACCAGGACAGCCAGGAACACCAGGACAACCAGGGCAGCCCGGAACACCAGGACAACCAGGTCAACCAGGCTACCCAGGACAAGGTGGACAGCCTATAAAGCCTGGTCAGACAGGATACCCAGGTCAGCCAGGCCAGCCGGGATACCCAGGACAACCAGGCCAGCCAGGAACACCAGGACAGCCAGGAACACCAGGACAGCCAGGCCAACCAGGCTACCCAGGACAAGGTGGACAGCCTATAAAGCCTGGTCAGACAGGATACCCAGGTCAGCCAGGCCAGCCGGGATACCCAGGACAACCAGGACAGCCAGGAACACCAGGACAGCCAGGCCAACCGGGACAACCCGGTACACCAGGCCAGCCCGGAACACCAGGACAACCAGGTCAACCAGGCTACCCAGGACAAGGTGGACAGCCTGTAAATCCTGCTCAGCCGGGATACCCAGGACAGCCAGGTCAGCCAGGATACCCAGGACAACCAGGACAGCCAGGAACTCCAGGACAGCCCGGAACACCAGGACAGCCCGGAACACCAGGACAACCAGGTCAACCAGGCTACCCAGGACAAGGTGGACAGCCTGTAAATCCTGCTCAGCCGGGATACCCAGGTCAGCCAAGTCAGCCGGGATACCCAGGACAACTAGGACAACCAGGAACTCCAGGACAACCAGGACAGCCCGGAACACCAGGACAGCCCGGAACACCAGGACAACCAGGTCAACCAGGCTACCCAGGACAAGGTGGACAGCCTATAAATCCTACTCAGCCGGGATCCCCAGGTCAGCTAGGTCAGCCAGGATACCCAGGACAACCAGGACAGCCAGGTACTCCAGGACAACCAGGTCAACCAGGAACACCAGGACAACCAGGAACACCAGGACAACCAGGACAAGGTGGACAACCGATAAAACCTGGTCAGTCTGGATACCCAGGCCAGCCAGGTCAACCAGGATACCCAGGACAATCAGGACAGCCAGGTACACCAGGCCAGCCCGGAACACCAGGGCAGCCAGGACAACCGGGGCAGCCAGGAACACCAGGACAGCCAGGTCAACCGGGACAGCCCGGTACACCAGGACAACCAGGCTATCCAGGACAAGGTGGACCACAACAGGGCGGTCAACCCATGAATCCTAGTCAACCTGGATACCCCGGCCAACCAGGGCCACCCGGATACCCAGGACAACCAGGTCAACCAGGACAACCAGGGCAGCCCGGAACACCAGGACAACCAGGTCAACCAGGCTACCCAGGACAAGGTGGACAGCCTATAAAGCCTGGTCAGACAGGATACCCAGGTCAACCAGGCCAGCCGGGATACCCAGGACAACCAGGCCAGCCAGGAACACCAGGACAGCCAGGAACACCAGGACAGCCAGGCCAACCAGGCTACCCAGGACAAGGTGGACAGCCTATAAAGCCTGGTCAGACAGGATACCCAGGTCAGCCAGGCCAGCCGGGATACCCAGGACAACCAGGACAGCCAGGAACACCAGGACAGCCAGGCCAACCGGGACAACCCGGTACACCAGGACAGCCAGGACAACCAGGCTATCCAGGACAAGGTGGACCACAACAGGGCGGTCAACCCATGAATCCTAGTCAACCTGGATACCCCGGCCAACCAGGACAACCAGGATACCCAGGACAACCAGGACAACCAGGCCAGACCGGAACACCAGGACAACCAGGTCAACCAGGCTACCCAGGACAAGGTGGACAACCTATAAAGCCTGGTCAGCCAGGATACCCAGGTCAGCCAGGACAAGGTGGACCACAACAGAGCGGTCAACCAATGAATCCTAGTCAACCTGGATACCCCGGCCAACCAGGACAACCAGGATACCCAGGACAACCAGGTCAACCAGGACAACCTGGACAACCGGGTCAACCGGGGCAGCCCGGTACAGCAGGACAACCAGGCTATCCCGGACAAGGTGGACAACAACAGGGCGGTCAGCCCATTAATCCTAGTCAACCTGGATACCCCAGCCATCCAGGACAACCAGGATACCCAGGACAACCAGGTCAACCAGGACAACCAGGCCAGCCCGGAACACCAGGACAACCAGGTCAACCAGGCTACCCAGGACAAGGTGGACAGCCTATAAAGCCTGGTCAGCCAGGATACCCAGGTCAGCCAGGCCAGCCGGGATACCCTGGACAACCAGGACAGCCAGGAGCACCAGGCCAACCGGGTCAGCCAGGACAACCAGTGCAGCCCGGAACACCAGGACAAGCAGGTCAACCAGGCTACCCAGGACAAGGTGGACAACCTATAAAGCCTGCTCAGCCGGGACACCCAGGCCAGCCTGGACAACCAGGGCAGCCCGGAACACCAGGACAACCAGGTCAACCAGGATACCCAGGGCAACCGGGTCAGCCAGGACAACCAGGGCAACCAGGACAACAAGGCTATCCAGGACAAGGTGGACCACAACAGGGCGGTCAGCCTATTAATCCTAGTCAACCTGGTTACCCAGGCCAGTCAGGACAACCAGGTTACCCTGGACAACCGGTTCAGCCAGGACAACCAGGGCAGCCCGGAACACCAGGGGAACCGGGACAGCCCGGTACACCAGGACAACCTGGCTATCCAGGACAAGGTGGACCACAACAGGGCGGTCAGCCTATGAATCCTAGTCAACCCGAATACCCAAGCCAGCCAGGACAACCAGGACAGCCAGGAACACCGGGACAAGCAGGACACCCAGGACAACCTGGACACCCAGGCGCACCAGGACAACCAGGTTACCCAGGACAACCCGGACAGCCGGGCGCACCAGGACAAGCAGGTTACCCAGGACAAGGTGGACCGCAACAGGGCGGTCAGCCTATAAATCCTAGTCAACCAGGACATCCAGGGCAGCCAGGACAGCCGGGTCAACCAGGGCAGCCAGGAAAACCCGGGCAACCTGGTACACCAGGGCAGCCTGGAGCTCCAGGGCAACCTGGAACACCAGGACAACCAGGCTATCCAGGACAAAATGGACCACAACAAGGCGGTCAGCCTATTAAACCTGATCAACCCGGATACCCAGGCCAACCGGGAGCACCAGGGCAGCCTGGAACACCAGGACAACCCGGACAGCCAGGAACACCAGGACAACCCGGATATCCAGGACAAGGCGGACCACAACAGGGCGGTCAGCCTATCAATCCCGATCAGCCCGGACAGCCAGGTCCACCAGGATATCCAGGGCAAGGCGGACAACCCATAAATCCTAGTCAATCAGGCTACCCGGGACAACCAGGACAAGGAGGCGATTCCGTCTCGTCGGGAACTGGTGTGCAGCCACCGACATATGTTCCATCAACTCAAATGCCACCTTTCCCAATTTATGTCATACCTTTTCCATTGCCTATCGTACCAAGTCCAGGATCATGTCCCTGCTATTTATTAAATCCTGGAAATAACGGTACAGCAACGAACGAAATGCAAGCATCCTCACATCCCGCAAATGGACAGAGTCAAGGATATGCTCCGTACGGTATTATAGGATTCATACCTGTTGTTTTCGTTCCCTATTGTCCAGGAAATGGGAGTGCGATGAACACTGCACAACAAAACTTCCCTCAAGCAGTACCGGTGCAATACAATTGTGCCCAATGTCAGGCCAATCGAGATGTCTACAGATTCGCAGGCCGACACAATGGCGCCAGAGCGTTCAAAGAGCTTAAAGAACTTAAATCGCTGGACGAACTTAACGATCTCATTCGAAATAGAATAAAACCTACCAAGAGGACATTACGTCAAATTGCAGCACATCCAAAAATACTTGAAACAAAACACTAG
Protein
MGPGIMIKFCILAVLALSLVSADKPKTETTSTTAKKATEVPAKKTVEVPLKKASEVPVKKASEVPTKKPHVEPAREGRQLSPYPGQQDNEVVVDIQDDEKKQYYETNYDTSAYGFGYDVGPNGQFHHENRGPDGVVYGCYGYVDTEGYLRATHYVADSHGYRVVEPEKPVEVFPDEKYEYDENYEPTPSATGQTIPWNKLFFPQGCGRTPGGVPPQPFKPKPKPKPPVDSTGQTSNPSPGVAYPGQGPNGPYGPGGSGGSGGPGGPGGPNGPYGPGGPGGPNGPYGPGGTGGPNGPYGPGGQDGSYRPDGSYGPDGSYQPEGSYGPDGSWQGGYYPGTPGSPGTPGSPGSPGSPGSPGTPGSPGTPGTPGSGGGYYPGQDGTGGPTGPSGGGGGYYPGSPGSPGTPGTPGTPGTPGGPGGPGGPGGPGGPGGPNGPNGPGGSDGGQYYPALPGSPGTPGSPGTPGGPGGPGGPGGPGGPGGPGGPGGPDQPSYPGQPGQPGTPGYPGQPGYPGQPGTPGQPGTPGQPGYPGQGGQPINPGQPGYPGQPGQPGYPGQPGQPGTPGQPGTPGQPGTPGQPGQPGYPGTPGQPGQSGYPGQGGPQQGGQPINPSQPGYPGQPGQPGYPGQPGQPGTPGQPGTPGQPGTPGQPGQPGTPGQPGTPGQPGQGGQPIKPGQSGYPGQSGQPGYPGQPGQPGTPGQPGTPGQPGQPGQPGTPGQPGTPGQPSYPGQGGQPIKPGQPGYPGQPGQPGYPGQAGQPGTPGYPGQPGTTGQPGTPGQPSYPGQGGQPIKPGQPGYPGQPGQPGYPGQPGQPGTPGQPGTPGQPGTPGQPGTPGQPGQPGYPGQGGQPVNPAQPGYPGQPGQPGYPGQPGQPGTPGQPGTPGQPGTPGQPGQPGYPGQGGQPVNPAQPGYPGQPSQPGYPGQPGQPGTPGQPGTPGQPGQPGTPGQPGQPGYPGQGGQPIKPGQTGYPGQPGQPGYPGQPGQPGTPGQPGTPGQPGQPGYPGQGGQPIKPGQTGYPGQPGQPGYPGQPGQPGTPGQPGQPGQPGTPGQPGTPGQPGQPGYPGQGGQPVNPAQPGYPGQPGQPGYPGQPGQPGTPGQPGTPGQPGTPGQPGQPGYPGQGGQPVNPAQPGYPGQPSQPGYPGQLGQPGTPGQPGQPGTPGQPGTPGQPGQPGYPGQGGQPINPTQPGSPGQLGQPGYPGQPGQPGTPGQPGQPGTPGQPGTPGQPGQGGQPIKPGQSGYPGQPGQPGYPGQSGQPGTPGQPGTPGQPGQPGQPGTPGQPGQPGQPGTPGQPGYPGQGGPQQGGQPMNPSQPGYPGQPGPPGYPGQPGQPGQPGQPGTPGQPGQPGYPGQGGQPIKPGQTGYPGQPGQPGYPGQPGQPGTPGQPGTPGQPGQPGYPGQGGQPIKPGQTGYPGQPGQPGYPGQPGQPGTPGQPGQPGQPGTPGQPGQPGYPGQGGPQQGGQPMNPSQPGYPGQPGQPGYPGQPGQPGQTGTPGQPGQPGYPGQGGQPIKPGQPGYPGQPGQGGPQQSGQPMNPSQPGYPGQPGQPGYPGQPGQPGQPGQPGQPGQPGTAGQPGYPGQGGQQQGGQPINPSQPGYPSHPGQPGYPGQPGQPGQPGQPGTPGQPGQPGYPGQGGQPIKPGQPGYPGQPGQPGYPGQPGQPGAPGQPGQPGQPVQPGTPGQAGQPGYPGQGGQPIKPAQPGHPGQPGQPGQPGTPGQPGQPGYPGQPGQPGQPGQPGQQGYPGQGGPQQGGQPINPSQPGYPGQSGQPGYPGQPVQPGQPGQPGTPGEPGQPGTPGQPGYPGQGGPQQGGQPMNPSQPEYPSQPGQPGQPGTPGQAGHPGQPGHPGAPGQPGYPGQPGQPGAPGQAGYPGQGGPQQGGQPINPSQPGHPGQPGQPGQPGQPGKPGQPGTPGQPGAPGQPGTPGQPGYPGQNGPQQGGQPIKPDQPGYPGQPGAPGQPGTPGQPGQPGTPGQPGYPGQGGPQQGGQPINPDQPGQPGPPGYPGQGGQPINPSQSGYPGQPGQGGDSVSSGTGVQPPTYVPSTQMPPFPIYVIPFPLPIVPSPGSCPCYLLNPGNNGTATNEMQASSHPANGQSQGYAPYGIIGFIPVVFVPYCPGNGSAMNTAQQNFPQAVPVQYNCAQCQANRDVYRFAGRHNGARAFKELKELKSLDELNDLIRNRIKPTKRTLRQIAAHPKILETKH
Summary
Uniprot
ProteinModelPortal
Ontologies
PATHWAY
GO
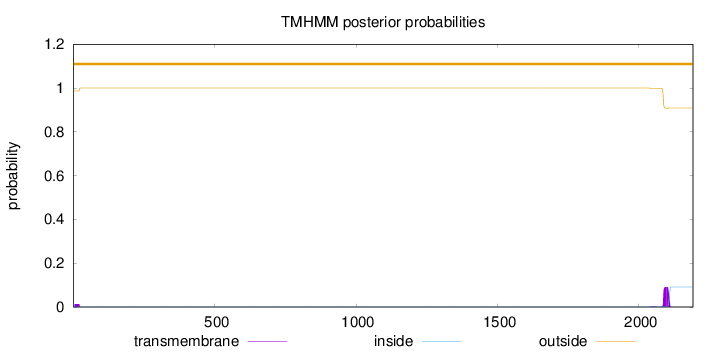
Topology
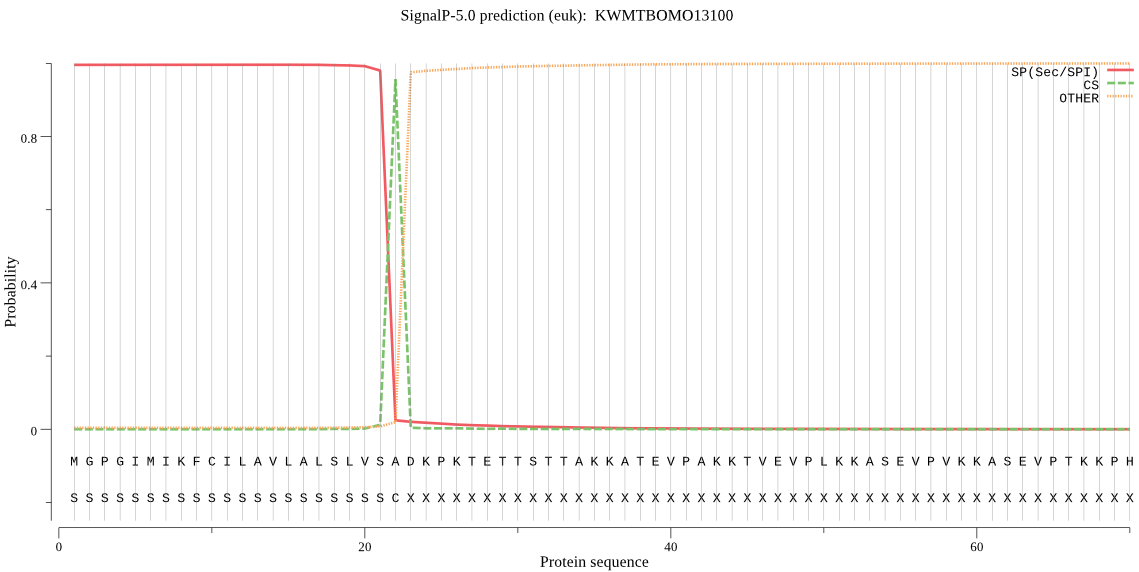
SignalP
Position: 1 - 22,
Likelihood: 0.995819
Length:
2191
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
2.21061
Exp number, first 60 AAs:
0.24668
Total prob of N-in:
0.01359
outside
1 - 2191
Population Genetic Test Statistics
Pi
207.835968
Theta
173.434135
Tajima's D
0.539605
CLR
0.09103
CSRT
0.523573821308935
Interpretation
Uncertain
