Pre Gene Modal
BGIBMGA007162
Annotation
PREDICTED:_nucleolar_protein_6_[Amyelois_transitella]
Full name
Nucleolar protein 6
Location in the cell
Cytoplasmic Reliability : 1.451 Nuclear Reliability : 1.88
Sequence
CDS
ATGGTGAAACGAAAAAATGTCTCAATTTCCGAAGACGACGGGGAAAGTGGATTGATTAATGAAAATGGAAAAGTAATTTTTGAAGACAAGGAAAAGAAGAAACGTATAAAAACAAAAAGCTTATATCGACAGCCCACTGTGAATGAACTGAATCGGCTCCAGGAGACGGAGACTTTGTTTAACTCTAATTTGTTCCGACTGCAGGTAGAGGAAATACTACAGGAGGTTAAAGTTAAAGAGAAAGTTGAAAAACGGTTTCTACAATGGTTCACAGACTTTAAGAACCACTTAGACAGTATACCTACGGATGATACAGAGTATGACTTAACTGAACACACATTAACAAAAAAAATTAAAGTCAAACTACCTATCAGTGAAGAATTGAAGAAGACAAAATGCGTCTTCAAATTTCATAAGTTTGAAACTGTTGATATTGTTGGATCTTACGCATTAGGATGTGCGATTAATTCGAAATTAGTAGTTGACTTACAGATTACTGTACCGTCACAAACATATACCAAGAATGACTCAATTAATTACAGATATCACAAAAAACGTGCAGCCTACTTAGCTTATATAGCATCTTATTTGTCCAAAAGCGATATAATTGTAGATTTAAATTATTCATTCATTAATGGGTGCGAAACAAAACCTATATTAATATTAAAACCAGCCGGTAAACTGCAAAACCATTTATCGGTTCGAATAAATTTAGTATGTGACACTGACACATTTAAGTTACATAGATTCAGCCCTAAACGGAACAATTTACGGCAATCTTGGTTGTTCTCGACAACAGAAAGTGAAGAAACTGATTCCCCAACACCATATTACAATAGCAGCATATTATATGACGTTACAGCTTTAAATAACGAAAAGCTGTTGAGAGATACTTTACTGAACAGTGAGAATTTGAAGCAGGCTGTGGTGCTACTGAAGATTTGGTTGCGTCAAAGAAACATACCTATTTCAGGCCAAATAGTTAATAACATTGTTGTATATTACGTGCAAACAAAAAGAGTAAATAACATCATGAGCAGTTATCAGATTGTAAGGAATATTTGGATAGCATTGAAAACATCAGAATGGGACAAGAAAGGTATCTCACTATGCAAAGCCGCAGATGCTACTCCATCCCTTGAAGAATTCCACCAAAATTTTCCTATAGTATTTATAGACAGCACAGGATACTACAATATATGCTGGCAAATTTGTAAAGGGACATATTACGCACTGAAGAGAGAATGTGCCTTAGCTGTGGAAATGCTTGATAATGTGAAAATAAATAGTTTTATACCACTGTTTATGACACCAGTTAAAATGCTCATGAAATTTGATCATATATTGAGATTTAAAAATATGGAACTTCTTAAAACATCAGTCCTTGATAAAGTATCGAAGGATGACAAATTAAATTATGGCTTGGATCGACTCATGCTTGTCACGGACACAGTGTATTCATTACTTGCTAAAGGACTCGGGGATAGAGTTCATTTGATACTGCAGATGGTAGAAGCTGACTTCACATGGCCTGTAAAGAAAGTATTGAGTGCAGCTAAAACTGACAGCTGTTATGAAGAAAAATTAGCATTTGGTCTGATATTGAATAAAGATAATGCTTTAAATCCTGTTGAAAAAGGTCCCCCGGCCAATTTGCCTGAAGCATTGGAATTTAGGGCGTTCTGGGGAGACAAATCCGAACTACGTCGGTTCCAAGACGGCTCTATAACCGAGACCTGCGTGTGGGAAGGAGAGGCCACAGCAGAAAGGAGAGGCATCACTAAACAGATAATTAACTATCTAATGGATTTGAAGTATGGTGTGAAAGGTTCAGATTTGTTTCACGTGATGGATCAACTGGACAGCGTGCTGGTCCGCAAGCAGTACGCCGGGGAGTCCAGCGCCCATTGCGAAGAAGCCTGCCTCGATGTGCTCAGAGCATTCGACGAGCTCAGGAGGGACCTCAGGCAGCTCACCGAGCTGCCCTTGGACATCAGTGCTGTTTACGGCACGTCGTCAGTGTTCAGCTACAGCAGGCCGGTGCCCCCGGTGGCCCGGCCCGCGCCCCGCCAGCCCTACCGGCGCGCCGGGGCCTGTCTGCTGAAGCAGGCCAGCAGGAGGGACGGGCTGCCCTCGCTGCCGCACTACACGCCCGTCTCCAGAGCCGTCATCGAACTTGGACACAGCGGCAAGTGGCCCGGCGACATTGAAGCCTTCCGCTGCCTGAAAGCCGCCTTCCACCTCCAGATATCCGACCGCCTCACCGAGCAGTACTCGTTGATAACGCACGCGTATCCCTCCCACGTGGACGTGCTGAAGAACGGCCTGGTCTTCCGCTTGGCCATCGCTCATCCCAAAGAAATAACTCTTCTGAAGAGGGAGATAGAAAACGGAGTGGTGAAGCACAAGGACAGCGAGGAGAGTGCGCGGCTGCAGAGGGACACGCAGCTGATGCCGCGGCTCAGGGGCGCTCTGCACGGGTTGCACCAGAAGTACCCGGCCTTCGGTCCGACGGCGTGTCTGTTCAAGCGCTGGCTGTCCTCCCACCTGCTCTCCCCCCCGCACTTCCCCTCCGTGACGGCGGAGCTGATGGCGGCGACCGTGTTCCTCCACCCCCAACCCTTCACGCCCCCCACTCAACCCACCATCGGCCTGTTCCGGGTCCTAAGGCTGCTGGCTGCAACCGACTGGACGAGCGAGGTCTTCGTGCTGGACTTCAATGATGATCTGACCCGTGAACAGATAACAGAGTTGGAGCAGGCGGCTCGCGCCGACCCGCGCGGTCGGAGCGTGTGCATAGTGACGGCACAGGAGCGCGAGGTGGGACTCGCGTGCGAGCCCGGGCCTCCGCCCCCGGCGCTCCGCAGGGCGCAGGCGCTGGCCGCGAGCGCCCTCGCCTACCTCGAGAACAGCCTGCTCAATGAATTCAATGACAATCTGCTTCCCATGTTCGTCCCGAGTCTGTCGGAGTACGACGTGCAGATCGTGCTGCACCCCAGCCTGGTCCCCGAGTGGGCGGAGCGGGTGTGCGCCCCCCCGCGCCGCCGCCCCCCCACACCGCACGTGGGGGACGAGCTCATACCGGTCGTGGACTTCCATCCCGTGCTCACATACCTGGATGACTTGAGGAGCGCCTACGGTGACTTCGCTGTGTTCTTCCACGACCTGTACGGCGGCGAGGTTATCGCTGTCTTGTGGAAGCCCGATGTCGACGAGTACGAAGATTTCCAGGCTCTGAACGCGAACGCTTTAATACCGGAGACAGTGGACGGCGAGACGAGATACAAAGTGAACAAAGAAGCTATAATTGAGGACTTTAGAATCCTAGGACAAGGCCTGGTCAAGAGTGTTAATGTTTTGTGA
Protein
MVKRKNVSISEDDGESGLINENGKVIFEDKEKKKRIKTKSLYRQPTVNELNRLQETETLFNSNLFRLQVEEILQEVKVKEKVEKRFLQWFTDFKNHLDSIPTDDTEYDLTEHTLTKKIKVKLPISEELKKTKCVFKFHKFETVDIVGSYALGCAINSKLVVDLQITVPSQTYTKNDSINYRYHKKRAAYLAYIASYLSKSDIIVDLNYSFINGCETKPILILKPAGKLQNHLSVRINLVCDTDTFKLHRFSPKRNNLRQSWLFSTTESEETDSPTPYYNSSILYDVTALNNEKLLRDTLLNSENLKQAVVLLKIWLRQRNIPISGQIVNNIVVYYVQTKRVNNIMSSYQIVRNIWIALKTSEWDKKGISLCKAADATPSLEEFHQNFPIVFIDSTGYYNICWQICKGTYYALKRECALAVEMLDNVKINSFIPLFMTPVKMLMKFDHILRFKNMELLKTSVLDKVSKDDKLNYGLDRLMLVTDTVYSLLAKGLGDRVHLILQMVEADFTWPVKKVLSAAKTDSCYEEKLAFGLILNKDNALNPVEKGPPANLPEALEFRAFWGDKSELRRFQDGSITETCVWEGEATAERRGITKQIINYLMDLKYGVKGSDLFHVMDQLDSVLVRKQYAGESSAHCEEACLDVLRAFDELRRDLRQLTELPLDISAVYGTSSVFSYSRPVPPVARPAPRQPYRRAGACLLKQASRRDGLPSLPHYTPVSRAVIELGHSGKWPGDIEAFRCLKAAFHLQISDRLTEQYSLITHAYPSHVDVLKNGLVFRLAIAHPKEITLLKREIENGVVKHKDSEESARLQRDTQLMPRLRGALHGLHQKYPAFGPTACLFKRWLSSHLLSPPHFPSVTAELMAATVFLHPQPFTPPTQPTIGLFRVLRLLAATDWTSEVFVLDFNDDLTREQITELEQAARADPRGRSVCIVTAQEREVGLACEPGPPPPALRRAQALAASALAYLENSLLNEFNDNLLPMFVPSLSEYDVQIVLHPSLVPEWAERVCAPPRRRPPTPHVGDELIPVVDFHPVLTYLDDLRSAYGDFAVFFHDLYGGEVIAVLWKPDVDEYEDFQALNANALIPETVDGETRYKVNKEAIIEDFRILGQGLVKSVNVL
Summary
Subunit
May be associated with rRNA.
Similarity
Belongs to the NRAP family.
Keywords
Nucleus
RNA-binding
Complete proteome
Reference proteome
Feature
chain Nucleolar protein 6
Uniprot
H9JCB7
A0A2A4JMG6
A0A2W1BL72
A0A2A4JM19
A0A194QFY9
A0A3S2NEG0
+ More
A0A0N0PBL8 A0A0L7LAE4 A0A067R2J6 A0A2J7QV51 A0A2J7QV56 A0A151X9I9 A0A151J9F3 A0A026W434 F4X896 A0A195FDC9 E9IJG4 A0A158NBU1 A0A088AV91 A0A195BG38 E2AYW8 A0A195CBH0 A0A0M8ZW75 A0A0L7QLE0 E0VHG7 A0A1B6GXA5 A0A0J7N6B7 A0A154NXG4 A0A232EL17 A0A1B6E3J3 A0A2J7QV49 K7IX79 A0A093PKA1 L5M7B9 H0YTW4 A0A091RYY3 G1NZP0 A0A2H8TIL2 A0A2S2Q4D4 A0A250Y6X6 A0A0A0AJU1 J9K0G8 F1SE91 A0A1V4J7G3 A0A2Y9EY93 W5PI53 A0A131YG99 A0A1U7UK97 L8I733 D2HUA1 A5PJU0 G1LLI8 A0A341C5K3 A0A341C566 A0A2I0TWB2 L9L5B9 A0A3Q7XI36 A0A2U3VCF9 A0A2Y9LF73 A0A2Y9J8H1 A0A3Q7T5T6 A0A2Y9LCJ5 A0A1S3JJB4 A0A1S3G260 A0A452SM50 Q6NRY2 F1PEI3 A0A383ZP98 A0A384CET7 A0A2K6FM98 A0A3L8SDB2 I3MQH5 A0A091TSU9 M3W6B5 A0A2U3XT86 A0A3B3BL61 A0A1D5PT04 A0A091GDG8 A0A2K5Q034 A0A1D5PIN3 L5KE66 A0A093J512 G1U998 A0A340XUT0 A0A3Q7MNL2 W5UDZ4 F6ZJX2 A0A2U3ZF19 A0A310TMU2 A0A401T2T6 A0A1E1X2L1 A0A091I6R1 A0A2J8XIR5 Q5M7P5 A0A2D0PPB6 A0A452SM36 A0A2Y9DD55 H3CDV3 A0A224Z2V3
A0A0N0PBL8 A0A0L7LAE4 A0A067R2J6 A0A2J7QV51 A0A2J7QV56 A0A151X9I9 A0A151J9F3 A0A026W434 F4X896 A0A195FDC9 E9IJG4 A0A158NBU1 A0A088AV91 A0A195BG38 E2AYW8 A0A195CBH0 A0A0M8ZW75 A0A0L7QLE0 E0VHG7 A0A1B6GXA5 A0A0J7N6B7 A0A154NXG4 A0A232EL17 A0A1B6E3J3 A0A2J7QV49 K7IX79 A0A093PKA1 L5M7B9 H0YTW4 A0A091RYY3 G1NZP0 A0A2H8TIL2 A0A2S2Q4D4 A0A250Y6X6 A0A0A0AJU1 J9K0G8 F1SE91 A0A1V4J7G3 A0A2Y9EY93 W5PI53 A0A131YG99 A0A1U7UK97 L8I733 D2HUA1 A5PJU0 G1LLI8 A0A341C5K3 A0A341C566 A0A2I0TWB2 L9L5B9 A0A3Q7XI36 A0A2U3VCF9 A0A2Y9LF73 A0A2Y9J8H1 A0A3Q7T5T6 A0A2Y9LCJ5 A0A1S3JJB4 A0A1S3G260 A0A452SM50 Q6NRY2 F1PEI3 A0A383ZP98 A0A384CET7 A0A2K6FM98 A0A3L8SDB2 I3MQH5 A0A091TSU9 M3W6B5 A0A2U3XT86 A0A3B3BL61 A0A1D5PT04 A0A091GDG8 A0A2K5Q034 A0A1D5PIN3 L5KE66 A0A093J512 G1U998 A0A340XUT0 A0A3Q7MNL2 W5UDZ4 F6ZJX2 A0A2U3ZF19 A0A310TMU2 A0A401T2T6 A0A1E1X2L1 A0A091I6R1 A0A2J8XIR5 Q5M7P5 A0A2D0PPB6 A0A452SM36 A0A2Y9DD55 H3CDV3 A0A224Z2V3
Pubmed
19121390
28756777
26354079
26227816
24845553
24508170
+ More
21719571 21282665 21347285 20798317 20566863 28648823 20075255 20360741 21993624 28087693 30723633 20809919 26830274 22751099 20010809 19393038 23385571 16341006 24813606 30282656 17975172 29451363 15592404 23258410 23127152 17495919 30297745 28503490 15496914 28797301
21719571 21282665 21347285 20798317 20566863 28648823 20075255 20360741 21993624 28087693 30723633 20809919 26830274 22751099 20010809 19393038 23385571 16341006 24813606 30282656 17975172 29451363 15592404 23258410 23127152 17495919 30297745 28503490 15496914 28797301
EMBL
BABH01031586
BABH01031587
NWSH01001097
PCG72623.1
KZ150013
PZC75031.1
+ More
PCG72624.1 KQ458981 KPJ04463.1 RSAL01000164 RVE45335.1 KQ460882 KPJ11465.1 JTDY01001960 KOB72442.1 KK853055 KDR11961.1 NEVH01010479 PNF32459.1 PNF32461.1 KQ982373 KYQ57033.1 KQ979433 KYN21583.1 KK107459 EZA50366.1 GL888932 EGI57170.1 KQ981673 KYN38386.1 GL763802 EFZ19280.1 ADTU01011325 KQ976500 KYM83169.1 GL444015 EFN61369.1 KQ978068 KYM97551.1 KQ435850 KOX70863.1 KQ414929 KOC59379.1 DS235170 EEB12823.1 GECZ01002714 JAS67055.1 LBMM01009293 KMQ88240.1 KQ434778 KZC04307.1 NNAY01003650 OXU19050.1 GEDC01004796 JAS32502.1 PNF32456.1 AAZX01006551 KL669617 KFW76861.1 KB103229 ELK34286.1 ABQF01020569 ABQF01020570 KK937313 KFQ47931.1 AAPE02037196 GFXV01001303 MBW13108.1 GGMS01003394 MBY72597.1 GFFV01000567 JAV39378.1 KL872051 KGL94426.1 ABLF02023358 AEMK02000074 DQIR01279817 HDC35295.1 LSYS01008655 OPJ68096.1 AMGL01048335 GEDV01010288 JAP78269.1 JH882068 ELR51092.1 GL193390 EFB29188.1 BC142238 AAI42239.1 ACTA01018097 KZ506871 PKU38085.1 KB320502 ELW70261.1 BC070577 AAEX03007940 QUSF01000029 RLW00010.1 AGTP01043493 KK404453 KFQ81439.1 AANG04001372 AC213332 KL448108 KFO80415.1 KB030846 ELK09076.1 KL217143 KFV74079.1 AAGW02033462 JT413292 AHH40188.1 KV467282 OCT56411.1 BEZZ01000910 GCC36924.1 GFAC01005714 JAT93474.1 KL218307 KFP04284.1 NDHI03003365 PNJ81947.1 BC088522 GFPF01013001 MAA24147.1
PCG72624.1 KQ458981 KPJ04463.1 RSAL01000164 RVE45335.1 KQ460882 KPJ11465.1 JTDY01001960 KOB72442.1 KK853055 KDR11961.1 NEVH01010479 PNF32459.1 PNF32461.1 KQ982373 KYQ57033.1 KQ979433 KYN21583.1 KK107459 EZA50366.1 GL888932 EGI57170.1 KQ981673 KYN38386.1 GL763802 EFZ19280.1 ADTU01011325 KQ976500 KYM83169.1 GL444015 EFN61369.1 KQ978068 KYM97551.1 KQ435850 KOX70863.1 KQ414929 KOC59379.1 DS235170 EEB12823.1 GECZ01002714 JAS67055.1 LBMM01009293 KMQ88240.1 KQ434778 KZC04307.1 NNAY01003650 OXU19050.1 GEDC01004796 JAS32502.1 PNF32456.1 AAZX01006551 KL669617 KFW76861.1 KB103229 ELK34286.1 ABQF01020569 ABQF01020570 KK937313 KFQ47931.1 AAPE02037196 GFXV01001303 MBW13108.1 GGMS01003394 MBY72597.1 GFFV01000567 JAV39378.1 KL872051 KGL94426.1 ABLF02023358 AEMK02000074 DQIR01279817 HDC35295.1 LSYS01008655 OPJ68096.1 AMGL01048335 GEDV01010288 JAP78269.1 JH882068 ELR51092.1 GL193390 EFB29188.1 BC142238 AAI42239.1 ACTA01018097 KZ506871 PKU38085.1 KB320502 ELW70261.1 BC070577 AAEX03007940 QUSF01000029 RLW00010.1 AGTP01043493 KK404453 KFQ81439.1 AANG04001372 AC213332 KL448108 KFO80415.1 KB030846 ELK09076.1 KL217143 KFV74079.1 AAGW02033462 JT413292 AHH40188.1 KV467282 OCT56411.1 BEZZ01000910 GCC36924.1 GFAC01005714 JAT93474.1 KL218307 KFP04284.1 NDHI03003365 PNJ81947.1 BC088522 GFPF01013001 MAA24147.1
Proteomes
UP000005204
UP000218220
UP000053268
UP000283053
UP000053240
UP000037510
+ More
UP000027135 UP000235965 UP000075809 UP000078492 UP000053097 UP000007755 UP000078541 UP000005205 UP000005203 UP000078540 UP000000311 UP000078542 UP000053105 UP000053825 UP000009046 UP000036403 UP000076502 UP000215335 UP000002358 UP000053258 UP000007754 UP000001074 UP000053858 UP000007819 UP000008227 UP000190648 UP000248484 UP000002356 UP000189704 UP000009136 UP000008912 UP000252040 UP000011518 UP000286642 UP000245340 UP000248483 UP000248482 UP000286640 UP000085678 UP000081671 UP000291022 UP000002254 UP000261681 UP000261680 UP000291021 UP000233160 UP000276834 UP000005215 UP000011712 UP000245341 UP000261560 UP000000539 UP000053760 UP000233040 UP000010552 UP000053875 UP000001811 UP000265300 UP000286641 UP000002280 UP000287033 UP000054308 UP000008143 UP000221080 UP000248480 UP000007303
UP000027135 UP000235965 UP000075809 UP000078492 UP000053097 UP000007755 UP000078541 UP000005205 UP000005203 UP000078540 UP000000311 UP000078542 UP000053105 UP000053825 UP000009046 UP000036403 UP000076502 UP000215335 UP000002358 UP000053258 UP000007754 UP000001074 UP000053858 UP000007819 UP000008227 UP000190648 UP000248484 UP000002356 UP000189704 UP000009136 UP000008912 UP000252040 UP000011518 UP000286642 UP000245340 UP000248483 UP000248482 UP000286640 UP000085678 UP000081671 UP000291022 UP000002254 UP000261681 UP000261680 UP000291021 UP000233160 UP000276834 UP000005215 UP000011712 UP000245341 UP000261560 UP000000539 UP000053760 UP000233040 UP000010552 UP000053875 UP000001811 UP000265300 UP000286641 UP000002280 UP000287033 UP000054308 UP000008143 UP000221080 UP000248480 UP000007303
Pfam
Interpro
ProteinModelPortal
H9JCB7
A0A2A4JMG6
A0A2W1BL72
A0A2A4JM19
A0A194QFY9
A0A3S2NEG0
+ More
A0A0N0PBL8 A0A0L7LAE4 A0A067R2J6 A0A2J7QV51 A0A2J7QV56 A0A151X9I9 A0A151J9F3 A0A026W434 F4X896 A0A195FDC9 E9IJG4 A0A158NBU1 A0A088AV91 A0A195BG38 E2AYW8 A0A195CBH0 A0A0M8ZW75 A0A0L7QLE0 E0VHG7 A0A1B6GXA5 A0A0J7N6B7 A0A154NXG4 A0A232EL17 A0A1B6E3J3 A0A2J7QV49 K7IX79 A0A093PKA1 L5M7B9 H0YTW4 A0A091RYY3 G1NZP0 A0A2H8TIL2 A0A2S2Q4D4 A0A250Y6X6 A0A0A0AJU1 J9K0G8 F1SE91 A0A1V4J7G3 A0A2Y9EY93 W5PI53 A0A131YG99 A0A1U7UK97 L8I733 D2HUA1 A5PJU0 G1LLI8 A0A341C5K3 A0A341C566 A0A2I0TWB2 L9L5B9 A0A3Q7XI36 A0A2U3VCF9 A0A2Y9LF73 A0A2Y9J8H1 A0A3Q7T5T6 A0A2Y9LCJ5 A0A1S3JJB4 A0A1S3G260 A0A452SM50 Q6NRY2 F1PEI3 A0A383ZP98 A0A384CET7 A0A2K6FM98 A0A3L8SDB2 I3MQH5 A0A091TSU9 M3W6B5 A0A2U3XT86 A0A3B3BL61 A0A1D5PT04 A0A091GDG8 A0A2K5Q034 A0A1D5PIN3 L5KE66 A0A093J512 G1U998 A0A340XUT0 A0A3Q7MNL2 W5UDZ4 F6ZJX2 A0A2U3ZF19 A0A310TMU2 A0A401T2T6 A0A1E1X2L1 A0A091I6R1 A0A2J8XIR5 Q5M7P5 A0A2D0PPB6 A0A452SM36 A0A2Y9DD55 H3CDV3 A0A224Z2V3
A0A0N0PBL8 A0A0L7LAE4 A0A067R2J6 A0A2J7QV51 A0A2J7QV56 A0A151X9I9 A0A151J9F3 A0A026W434 F4X896 A0A195FDC9 E9IJG4 A0A158NBU1 A0A088AV91 A0A195BG38 E2AYW8 A0A195CBH0 A0A0M8ZW75 A0A0L7QLE0 E0VHG7 A0A1B6GXA5 A0A0J7N6B7 A0A154NXG4 A0A232EL17 A0A1B6E3J3 A0A2J7QV49 K7IX79 A0A093PKA1 L5M7B9 H0YTW4 A0A091RYY3 G1NZP0 A0A2H8TIL2 A0A2S2Q4D4 A0A250Y6X6 A0A0A0AJU1 J9K0G8 F1SE91 A0A1V4J7G3 A0A2Y9EY93 W5PI53 A0A131YG99 A0A1U7UK97 L8I733 D2HUA1 A5PJU0 G1LLI8 A0A341C5K3 A0A341C566 A0A2I0TWB2 L9L5B9 A0A3Q7XI36 A0A2U3VCF9 A0A2Y9LF73 A0A2Y9J8H1 A0A3Q7T5T6 A0A2Y9LCJ5 A0A1S3JJB4 A0A1S3G260 A0A452SM50 Q6NRY2 F1PEI3 A0A383ZP98 A0A384CET7 A0A2K6FM98 A0A3L8SDB2 I3MQH5 A0A091TSU9 M3W6B5 A0A2U3XT86 A0A3B3BL61 A0A1D5PT04 A0A091GDG8 A0A2K5Q034 A0A1D5PIN3 L5KE66 A0A093J512 G1U998 A0A340XUT0 A0A3Q7MNL2 W5UDZ4 F6ZJX2 A0A2U3ZF19 A0A310TMU2 A0A401T2T6 A0A1E1X2L1 A0A091I6R1 A0A2J8XIR5 Q5M7P5 A0A2D0PPB6 A0A452SM36 A0A2Y9DD55 H3CDV3 A0A224Z2V3
PDB
5WYK
E-value=3.2667e-29,
Score=324
Ontologies
GO
PANTHER
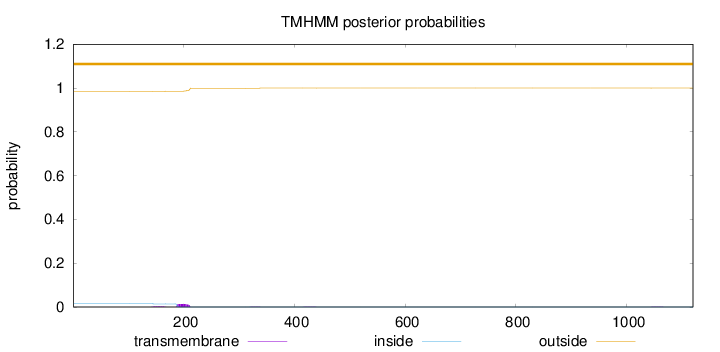
Topology
Subcellular location
Length:
1120
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.345000000000001
Exp number, first 60 AAs:
0
Total prob of N-in:
0.01536
outside
1 - 1120
Population Genetic Test Statistics
Pi
22.097349
Theta
19.599368
Tajima's D
-0.544928
CLR
11.257961
CSRT
0.234088295585221
Interpretation
Uncertain
