Pre Gene Modal
BGIBMGA007196
Annotation
PREDICTED:_AP-3_complex_subunit_beta-2_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.801
Sequence
CDS
ATGACGAGTACGACTTCTTACAACAACGACAAGGTCGTTACCGGCGAGGTGGAGTACCCGGCAAGCGATCCCGCATCAGGGGCGTTCTTTCAACCAGATTTCAAAAAAAACGATGACCTGAAATTAATGCTTGATGGATCAAAGGACTCCCTTAAACTGGAGGCGATGAAGAGAATTATTGGCATGATTGCTAAAGGAAGAGATGCTTCTGATTTATTCCCAGCAGTAGTCAAGAATGTTGTATCTAAGAACATAGAAGTGAAGAAATTAGTTTATGTTTATCTGGTGAGGTATGCTGAAGAACAACAAGACCTAGCTTTGCTGTCGATCAGCACTTTCCAGAGAGCTTTAAAGGATCCTAATCAACTAATAAGAGCGAGCGCCCTAAGAGTGTTATCCTCAATCCGCGTGCCCATGATAGTTCCAATTGTGATGTTGGCCATCAGAGACTCAGCTGCCGACATGAGTCCGTATGTAAGGAAGACTGCTGCCCACGCAATACCCAAACTTTATAGCTTGGATCCAGAACAGAAGGAGGAATTGGTTGCCATAATAGACAAGCTGCTATCGGACAAGGCGCCGCTTGTGGTCGGCTCTGCTGCGATGGCCTTCTCGGAGGTGTGCGGCGACCGGATGAGCCTCATACACAGGAGCTACAGGAAATTGTGCGGCTTGCTGGCCGATGTGGACGAGTGGGGACAGCTGGCCATCCTGAATGTGCTGACGGTGTACGCCAAAACCTTCTTCCCCGACCCAAACAGTGAGGAGTACTCGAGCGACAGCGAATCAGAGAAGCCGTTCTACGAGTCGGACAGCGACGAGGACAGTCCCCGGAAGCACTCCCGCTCCCCCACCGTGGACCCCGACCTCAGGCTGCTGCTGCGCGCGGCCAAACCCTTGCTGCAGAGCAGGAACTCCGGAGTCGTGATGGCTGTGGCGCAACTGTTCTACCACTGTGCTCCCGCCCAGGAGCTGCCGCCGGTGGCGAAGGCCATGATACGGCTGCTGCGCGCCCCGGTGGAGGTGCAGAGCGTGGTGCTGAACTGCATCGCCGCCCTCACGGTCTCCAGGCGGGCGCTGTTCGACCCGTACTTAAAGTCGTTTCTCATTCGGAACTCGGATCCGAGTCACATCAAGCTGCTGAAGCTGGAGATCCTGACGAACCTGGCGACGGAGAGCAGCGCGGCCGGCGTCATCCGGGAGCTGCAGGCGCACGCGGGCGGCGGGGAGCGGGGGGTGCGCGCCGCCACGCTGCACGCGCTGGGCCGCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCTCCCCCGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCCTGTCCCTCTACCGGCTCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCCTGTCCCTCTACCGGCTCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCTCCCCCGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCCTGTCCCTCTACCGGCTCCCTCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCCTGTCCCTCTACCGGCTCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCTCCCCCGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCCTGTCCCTCTACCGGCTCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCCTGTCCCTCTACCGGCTCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCCTGTCCCTCTACCGGCTCCCTCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCTGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCTGTCCCTCTACCGGCTCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCTGTCCCTCTACCGGCTCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCGTCCCTCTACCGGCTCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCGTCCCTCTACCGGCTCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCTGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCCCCCCCACTGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCGTCCCTCTACCGGCTCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCCGTCCCTCTACCGGCTCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCGCCCCCCCTGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCCCCCCCACTGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCCCCCCCACTGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCCCCCCACTGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCCCCCCCACTGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCCCCCCCACTGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCCCCCCCACTGTCCCTCTACCGCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGGTACGCAGCCCCCCCACTGTCCCTCTACCGCCCCCCTCCCTCGCGCTCGCCGTGCGCCCGCACACCGACGCCTGCCTCGCCTCGCTGCTGCACCTGCTCTCCAGCAAGGACGAGTGGGTGGTGTGCGAAGCCGTGGTGGTGGTGAAGAGAGTGGTGGGAGGCGGCGCTGCGTCCGCCAAGGCCGCCGTGGCCCGGGCCGCCAAGCTGCTGCGGTCTGACCGATTGGCGGCCAACGCCCGCGCCGCCGCCGTGTGGCTGGTGGCGGAGCACGGCGCCCACCACCCCCGCGCCGCCGCCGTGCTCGCGCACATGGCCGCCAGCTTCGCCGACCAGGAGGAGCTGGTGAAGCTGCAGGTGCTGTCGCTGGCGGCCAAGCTGTGGGTGACGCAGGCGGACACGGCGCCGGTGTGCCGCTACGCGGTGGCGCTGGCGCGGTACGACGCCAGCTACGACGTGCGCGACCGCGCCCGCATGCTGCGCCGCCTGCTGCTGCCCGCGCCAAGCGCCCGCCTGCCCGCGCACGCCGCGCTCATCTTCTGTCCCGACAAGCCGAAGCCCACCATCGAGAGCAGCTTCAAAGAGCGCCAACAGTACACAGTGGGCACGCTGTCGCAGTACCTGGGCAGCGCGGCCACCGGGTACCGGCCGCTGCCCACCGCGCCCGCCGCCACCAGCGGCGCCGAGCTGCGCGACCAGCACGACCGCGCGCCCCACGACCAGGCCGACACCAAGCAGCTGCAGCAGAAGAACAAAGAATTCTATTCGGAGCCCGAGAGCAGCGGGTCCGGCTCCTCGTCGGGGTCCTCGTCTTCCTCCTCGTCAGGCTCCGAGTCCAGCGGCTCCGAACACTCTTCTGAAGAGGACGAGAGCTCGAACGAAGAGAAACCGTCGAATCAAGAGAAGAAGTCGGTCAAGAAAACAAAAGAAATCAATGATTATGAGTCGTCCAGCCCCGGCACGTCGGACAGCGAGCCCGACAGCGACGCGTCCTCCAGCGACGGCGAGGAGTCCTCCGAGGAGAAAGAAACAGAAATCAAAGAGAAACCGTCCGAACAAAAGCGCAAGGAGCAATCCAACTTGGAGCTGCTGCTGCAGCTGGACGAGGTGGCCAGCACACTGCCCACCATGACCCCCACCTGCGGGGGGCTACTGTCCCCGCCCGCTGCCGCCACTGCCCCAGGACTTGCTGATGACTCGATAACGCCGGTGGGGCCGTCCCTGGTGCCCCCCATATCGACCGAGCTGGTCTCCAGGGTGCTGAGCGGGGGGCTGTCGGCCTCCCGGCGCTGGACCCGGGCCCCGCACCTCTACTCCAACAACATGTGCACCTTGGAGATCAGCTTCACAAACTGCGCCGGGGTCGAGGTCCAGAACATCCACATCAGTAAGAAGTTCCTGTCGGGGTCCCGGAGCGTCCACGAGTTCTCCCCGATCCCGTCGTTGGGCCCGGGGGCATCAGCGACCGTCACGCTCGGCATCGACTTCGCCGACAGCATCCAGCCGGTCGAGCTCGCGGTGTCCAGCTCCCTGGGTGAGGTGACGGTGACCATCAAGCCGCCGGTGGGGGAGCTCATGCGCGCCGTCTCCATGTCTGAGTCGCGCTGGGACGCAGAGTTCGACAAGCTGCGGGGCCTCACGGAGTGCGAGCGGGAGGGTGCGCCGCTGGAGGACGACGCGCTGGTCTGCCGGAGGGTGTTCGAGACCGCCAACCTGGCCGCCGTCGGAGCCCCCGGGGACCCGCTCAGGTTCGCGGGGCGGCTGCTGTCGTCCCAGGAGCTGGTGCTGGTGGCGGTGCGGCGCGGGCGGGGGGGCGGCGCCCGGCGGGTGTGCGCGCGCTGCCCCAACATGGCGGCCGCCTCCATACTCGCCAACGACATCGCGCAGGCCTTCCACAAGCTGCACGCGGTCTAG
Protein
MTSTTSYNNDKVVTGEVEYPASDPASGAFFQPDFKKNDDLKLMLDGSKDSLKLEAMKRIIGMIAKGRDASDLFPAVVKNVVSKNIEVKKLVYVYLVRYAEEQQDLALLSISTFQRALKDPNQLIRASALRVLSSIRVPMIVPIVMLAIRDSAADMSPYVRKTAAHAIPKLYSLDPEQKEELVAIIDKLLSDKAPLVVGSAAMAFSEVCGDRMSLIHRSYRKLCGLLADVDEWGQLAILNVLTVYAKTFFPDPNSEEYSSDSESEKPFYESDSDEDSPRKHSRSPTVDPDLRLLLRAAKPLLQSRNSGVVMAVAQLFYHCAPAQELPPVAKAMIRLLRAPVEVQSVVLNCIAALTVSRRALFDPYLKSFLIRNSDPSHIKLLKLEILTNLATESSAAGVIRELQAHAGGGERGVRAATLHALGRLALAVRPHTDACLASLLHLLSSKDGTQRLPRPSTAPLPRARRAPAHRRLPRLAAAPALQQGRYAAPPPCPSTGSLPRARRAPAHRRLPRLAAAPALQQGRYAAPPPCPSTGSLPRARRAPAHRRLPRLAAAPALQQGRYAAPPPSLYRPPPSRSPCARTPTPASPRCCTCSPARTVRSAPPLSLYRLPPRARRAPAHRRLPRLAAAPALQQGRYAAPPPCPSTGSLPRARRAPAHRRLPRLAAAPALQQGRYAAPPPSLYRPPPSRSPCARTPTPASPRCCTCSPARTVRSAPPLSLYRLPPSRSPCARTPTPASPRCCTCSPARTVRSAPPVPLPPPSLALAVRPHTDACLASLLHLLSSKDGTQRPPPVPLPAPSLALAVRPHTDACLASLLHLLSSKDGTQRPPRPSTAPLPRARRAPAHRRLPRLAAAPALQQGRYAAPPPCPSTGSLLALAVRPHTDACLASLLHLLSSKDGTQRPPCPSTAPLPRARRAPAHRRLPRLAAAPALQQGRYAAPPPVPLPAPSLALAVRPHTDACLASLLHLLSSKDGTQRPPRPSTAPLPRARRAPAHRRLPRLAAAPALQQGRYAAPPPVPLPAPSLALAVRPHTDACLASLLHLLSSKDGTQRPPRPSTGSLPRARRAPAHRRLPRLAAAPALQQGRYAAPPPSLYRLPPSRSPCARTPTPASPRCCTCSPARTVRSAPPVPLPPPSLALAVRPHTDACLASLLHLLSSKDGTQPPHCPSTAPLPRARRAPAHRRLPRLAAAPALQQGRYAAPPPSLYRLPPSRSPCARTPTPASPRCCTCSPARTVRSAPPVPLPAPSLALAVRPHTDACLASLLHLLSSKDGTQRPPCPSTAPLPRARRAPAHRRLPRLAAAPALQQGRYAAPPLSLYRPPPSRSPCARTPTPASPRCCTCSPARTVRSPPTVPLPPPSLALAVRPHTDACLASLLHLLSSKDGTQPPTVPLPPPSLALAVRPHTDACLASLLHLLSSKDGTQPPHCPSTAPLPRARRAPAHRRLPRLAAAPALQQGRYAAPPLSLYRPPPSRSPCARTPTPASPRCCTCSPARTVRSPPTVPLPPPPSRSPCARTPTPASPRCCTCSPARTVRSPPTVPLPPPSLALAVRPHTDACLASLLHLLSSKDEWVVCEAVVVVKRVVGGGAASAKAAVARAAKLLRSDRLAANARAAAVWLVAEHGAHHPRAAAVLAHMAASFADQEELVKLQVLSLAAKLWVTQADTAPVCRYAVALARYDASYDVRDRARMLRRLLLPAPSARLPAHAALIFCPDKPKPTIESSFKERQQYTVGTLSQYLGSAATGYRPLPTAPAATSGAELRDQHDRAPHDQADTKQLQQKNKEFYSEPESSGSGSSSGSSSSSSSGSESSGSEHSSEEDESSNEEKPSNQEKKSVKKTKEINDYESSSPGTSDSEPDSDASSSDGEESSEEKETEIKEKPSEQKRKEQSNLELLLQLDEVASTLPTMTPTCGGLLSPPAAATAPGLADDSITPVGPSLVPPISTELVSRVLSGGLSASRRWTRAPHLYSNNMCTLEISFTNCAGVEVQNIHISKKFLSGSRSVHEFSPIPSLGPGASATVTLGIDFADSIQPVELAVSSSLGEVTVTIKPPVGELMRAVSMSESRWDAEFDKLRGLTECEREGAPLEDDALVCRRVFETANLAAVGAPGDPLRFAGRLLSSQELVLVAVRRGRGGGARRVCARCPNMAAASILANDIAQAFHKLHAV
Summary
Uniprot
ProteinModelPortal
PDB
2XA7
E-value=3.45786e-36,
Score=387
Ontologies
GO
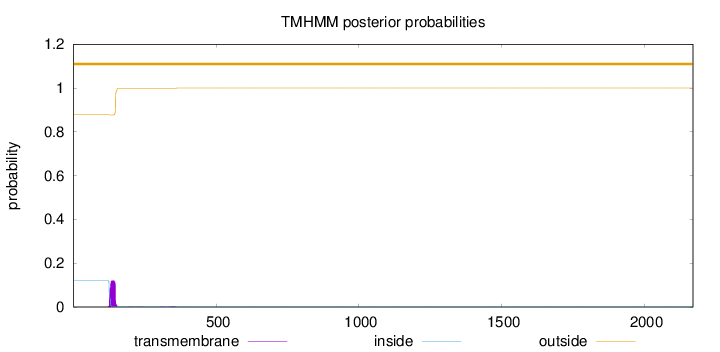
Topology
Length:
2170
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
2.62601
Exp number, first 60 AAs:
0.00043
Total prob of N-in:
0.12252
outside
1 - 2170
Population Genetic Test Statistics
Pi
2.832302
Theta
5.07133
Tajima's D
-1.870586
CLR
164.330314
CSRT
0.0178991050447478
Interpretation
Possibly Positive selection
