Gene
KWMTBOMO12463 Validated by peptides from experiments
Annotation
peritrophin_1_[Mamestra_configurata]
Location in the cell
Nuclear Reliability : 2.499
Sequence
CDS
ATGAAAGGTACATTGCTCACATTGCTCTGTGCAATATTCTTTGCACAGGGGCGTGAGTTTTTAGGTAGCGATGGCAGATTAGTATGCAACTGCGATCCCGAAGAAGCAAACAACATTTGCAGTGCATTAGGCTCTGCAAATCTGCACGTAGCGCACGAACGTTGTGACAAATTCTACAAATGCGCCAATAGAAAGCCTGTTCCATTTTGTTGTTCTGAAGGACTCTTCTACAATCCGGTCATCGAAGTGTGCGATTGGCCTCACAACGTTGATTGTGGAAATAGAATAACAAATCAAGTCCACAATCGCACCGAATGTAACGACAATGAAGGCGATTGGGAAGGTGAAGACAACGGCAATGAAAATGAAAACACTTGCGACTGGGCCCCTAGTGATGCGCCATCACTTTGTGCCCTCCCAGCTAATAATGGTGGTCTCGTTCCGCACGAAAATTGCAATCAATTTTATCAGTGTGCGCACGGAAGGCCAGTGGCACAAACTTGTGCCGGCAATCTTCTATTCGATACTTGCGCTAGGCGTTGTGATTACCCTCACAATGTAAAGTGCGGAAACCGGGCTATCCCTGAAAAGGATGAAAACCCTGGTAACAATGAGAGTAAGGAAAGCGATGACAATGAGCAGACTTGTAATTGCGATCCAGCGGAGGCACCAGAGATTTGTGCGCGACCTGGGTCTGATAGTATTCTCATAGCTCATGAAATTTGCCATAAATATTACATTTGTCTTCACGGTCGTCCAAGGACTATGGTTTGTAATAACAATCTTTTATTTAACCCTTATACAAACCAATGTGATTGGCCGCATAATGTTGAATGTGGTGACAGACTACTTTGTAATTGCGAAGATGGAAATAACGATAAAGAATGTGATGAAACTAAAAGTGAGGAAAGTAGCCCTGGCGATGATGGATCTGGCGGTGGCGGAGGTGGAGGTGGTGGTGGCGGCGGAAGTGAAGGTGGAGAAGGTGGCGGCGGTGGAGGCGGTGGTGGTGGTGGCGGCGGCGGTGGAGGAGGCGGAGGTGGAGGTGGTGGTGGCGGAGATGGCTCTTGCAACTGCAACCCTGGTGAAGCTCCAAGTATTTGCGCTGCCGACGGCTCTGATGGTGTTTTAATCGCTCACGAATATTGCAATAAGTTCTATAAATGTGACCATGGACTACCAGTAGCATTGAAGTGCCCAGGAAATCTACTTTATGATCCGCATCTAGAAAGATGCGAATGGCCTGATACTGTCGATTGTGGAGACAGAATAATTCCCGATCCAGAAGACGGAGGCAATGGTGGCGATGAGGGATCTGGTGGTGGAGGAGGAGGCGGCGGCGGTGGCGGCGGCGGAGGCGGCGGTGGTGGCGGAAGTGAAGGTGGGGAAGGCGGTGGCGGTGGAGGCGGTGGTGGTGGTGGCGGCGGAGGCGGAGGTGGAGGTGGTGGTGGCGGAGGTGGCTCTTGCAACTGCAACCCTGGTGAAGCCCCAAGTATTTGCGCTGCCGACGGCTCTGATGGTGTTTTAATAGCTCACGAATATTGCAATAAGTTCTATAAATGTGACCATGGACTACCAGTAGCATTGAAGTGCCCAGGAAATCTACTTTATGATCCGCATCTAGAAAGATGCGAATGGCCTGATACTGTCGATTGTGGAGACAGAATAATTCCCGATCCAGAAGACGGAGGCAATGGTGGCGATGAGGGATCTGGTGGTGGAGGAGGAGGCGGTGGCGGTGGCGGCGGCGGTGGCGGCGGCGGTGGCGGCGGCGGTGGTGGCGGCGGTGGCGGTGGAGGCGGTGGTGGTGGTGGCGGCGGAGGCGGAGGTGGAGGTGGTGGTGGCGGAGGTGGCTCTTGCAACTGCAACCCTGGTGAAGCTCCAAGTATTTGCGCTGCCGACGGCTCTGATGGTGTTTTAATAGCTCACGAATATTGCAATAAGTTCTATAAATGTGACCATGGACTACCAGTAGCATTGAAGTGCCCAGGAAATCTACTTTATGACCCGCATCTAGAAAGATGTGAATGGCCTGATACTGTCGATTGTGGAGACAGAATAATTCCCGATCCAGAAGACGGAGGCAATGGTGGCGATGAGGGATCTGGTGGCGGCGGTGGAGGCGGCGGCGGTGGCGGCGGCGGTGGCGGCGGTGGTGGTGGCGGAAGTGAAGGTGGAGAAGGCGGCGGCGGTGGAGGCGGTGGTGGTGGTGGCGGCGGAGGTGGAGGTGGTGGCGGCGGAGGTGGAGGTGGTGGTGGCGGAGGTGGCTCTTGCAACTGCAACCCTGGTGAAGCTCCAAGTATTTGCGCTGCCGACGGCTCTGATGGTGTTTTAATCGCTCACGAATATTGCAATAAGTTCTATATATGTGACCATGGACTACCAGTAGCATTGAAGTGCCCAGGAAATCTACTTTATGATCCGCATCTAGAAAGATGCGAATGGCCTGATACTGTCGATTGTGGAGACAGAATAATTCCCGATCCAGAAGACGGAGGCAATGGTGGCGATGAGGGATCTGGTGGTGGAGGAGGAGGCGGTGGCGGTGGCGGCGGCGGTGGCGGCGGCGGTGGCGGCGGCGGTGGTGGCGGCGGTGGCGGCGGAAGTGAAGGTGGAGAAGGCGGCGGTGGTGGAGGCGGTGGTGGTGGTGGCGGCGGAGGTGGAGGTGGAGGTGGCGGAGGTGGCTCTTGCAACTGCAACCCTGGTGAAGCCCCAAGTATTTGCGCTGCCGACGGCTCTGATGGTGTTTTAATCGCTCACGAATATTGCAATAAGTTCTATAAATGTGACCATGGACTACCAGTAGCATTGAAGTGCCCAGGAAATCTACTTTATGATCCACATCTGGAAAGATGTGAATGGCCTGATACTGTCGATTGTGGAGACAGAATAATTCCCGATCCAGAAGACGGAGGCAATGGTGGCGATGAGGGATCTGGTGGCGGCGGTGGAGGCGGCGGCGGTGGCGGCGGCGGTGGCGGCGGTGGTGGTGGCGGAAGTGAAGGTGGAGAAGGCGGCGGCGGTGGAGGCGGTGGTGGTGGTGGCGGCGGAGGTGGAGGTGGTGGCGGCGGAGGTGGAGGTGGTGGTGGCGGAGGTGGCTCTTGCAACTGCAACCCTGGTGAAGCCCCAAGTATTTGCGCTGCCGACGGCTCTGATGGTGTTTTAATCGCTCACGAATATTGCAATAAGTTCTATAAATGTGACCATGGACTACCAGTAGCATTGAAGTGCCCAGGAAATCTACTTTATGATCCGCATCTAGAAAGATGCGAATGGCCTGATACTGTCGATTGTGGAGACAGAATAATTCCCGATCCAGAAGACGGAGGCAATGGTGGCGATGAGGGATCTGGTGGCGGCGGTGGAGGCGGCGGCGGTGGCGGCGGCGGTGGCGGCGGTGGTGGTGGCGGAAGTGAAGGTGGAGAAGGCGGCGGCGGTGGAGGCGGTGGTGGTGGTGGCGGCGGAGGTGGAGGTGGTGGCGGCGGAGGTGGAGGTGGTGGTGGCGGAGGTGGCTCTTGCAACTGCAACCCTGGTGAAGCTCCAAGTATTTGCGCTGCCGACGGCTCTGATGGTGTTTTAATCGCTCACGAATATTGCAATAAGTTCTATATATGTGACCATGGACTACCAGTAGCATTGAAGTGCCCAGGAAATCTACTTTATGATCCGCATCTAGAAAGATGCGAATGGCCTGATACTGTCGATTGTGGAGACAGAATAATTCCCGATCCAGAAGACGGAGGCAATGGTGGCGATGAGGGATCTGGTGGTGGAGGAGGAGGCGGTGGCGGTGGCGGCGGCGGTGGCGGCGGCGGTGGCGGCGGCGGTGGTGGCGGCGGTGGCGGCGGAAGTGAAGGTGGAGAAGGCGGCGGTGGTGGAGGCGGTGGTGGTGGTGGCGGCGGAGGTGGAGGTGGAGGTGGCGGAGGTGGCTCTTGCAACTGCAACCCTGGTGAAGCCCCAAGTATTTGCGCTGCCGACGGCTCTGATGGTGTTTTAATAGCTCACGAATATTGCAATAAGTTCTATAAATGTGACCATGGACTACCAGTAGCATTGAAGTGCCCAGGAAATCTACTTTATGATCCGCATCTAGAAAGATGCGAATGGCCTGATACTGTCGATTGTGGAGACAGAATAATTCCCGATCCAGAAGACGGAGGCAATGGTGGCGATGAGGGATCTGGTGGTGGAGGAGGAGGCGGCGGCGGTGGCGGCGGTGGTGGTGGCGGAGGCGGCGGTGGAGGTGGTAGTGGCGGTGGAGGTGAAGGTGGAGAAGGCGGTGGCGGTGGAGGCGGTGGTGGTGGTGGCGGCGGAGGCGGAGGTGGAGGTGGTGGTGGCGGAGGTGGCTCTTGCAACTGCAACCCTGGTGAAGCTCCAAGTATTTGCGCTGCCGACGGCTCTGATGGTGTTTTAATCGCTCACGAATATTGCAATAAGTTCTATAAATGTGACCATGGACTACCAGTAGCATTGAAGTGCCCAGGAAATCTACTTTATGACCCGCATCTAGAAAGATGCGAATGGCCTGATACTGTTGATTGCGGAGACAGAATAATACCTGATTGCAATGAAGAAGACGGCAGTGGAGGTGGAGGCAGTGGCGGTGGCGGCGGAGGTGGTGAAGGCTCTTGCAAATGCAACCCCAGTGAAGCCCCAAGTATTTGTGCTGCTGAAGGATCTGACAGTATTCTAATAGCACATGAACATTGCAATAAGTTCTATAAATGTTTCAATAAGCGACCGGTTCCATTAAATTGCCCTGAAGACCTTCTTTATGATCCACATTTAGAAAGATGCGAATGGCCTGGTACTGTTGAATGTGGAGATAGAATAATTCCTGATAAGAGTGATGATCTTAACTTTTGTATTACAATAGAACCGAATGATGTTAACAACAACACCAACACTAGCCCCAGTGAAGTAAAAGCTATTTGTGCAAGAGGTAATTCAGAAGGCACGTTCATTCCTCATGAAAATTGCAATCAATTCTATACGTGCTCCAATGCTATTCCCGTTACTTTGACTTGTCCGAGCACTCTACTCTATAACTTGCTTACCGAAAAATGTGATTGGCCACGCTACGTTGATTGTGGAGATAGAAAGCTCCAGGGAGACAACGGTAACGGAAACAACAAAGACGAAGATACAACAGCTGTGATCTGCTCGAAAAAAGAATCCGAAGGAGTTTTAGTGGCTCACGAAGACTGCGATAAATTTTACATGTGCTCATCTGGAAATCCCGTAACTCTTAAATGTCCTTCGAACTTATTCTTTAGCCCAATCACCCAAACTTGTGAATGGTCCAAGAATGTCGAATGTGGCACTAGAGTCGTTCCAGGTGAGGAAAACGTCAATACTGGTCCTTGTAACTGTGATCCGAAACAGGCATTATCTTTATGTGCTCAAGAAGGTTCGAACGGCAAACTTGTAGCCCATAATGTGTGTAGCCACTATCACATGTGCGTCAGCGGTAAAACATTATCACTCGCTTGTCCGTCTAATCTTTTCTATGATCCTCAAAAGGAACGATGCGATTTTCCTGCTAATGTCAGCTGCGAAGGCCGTGTTGCACCAGTGTTCCTACCCCCACTCAACAAACATTTGGAAGCACGACAAAACATCAGACACTACTTTTAA
Protein
MKGTLLTLLCAIFFAQGREFLGSDGRLVCNCDPEEANNICSALGSANLHVAHERCDKFYKCANRKPVPFCCSEGLFYNPVIEVCDWPHNVDCGNRITNQVHNRTECNDNEGDWEGEDNGNENENTCDWAPSDAPSLCALPANNGGLVPHENCNQFYQCAHGRPVAQTCAGNLLFDTCARRCDYPHNVKCGNRAIPEKDENPGNNESKESDDNEQTCNCDPAEAPEICARPGSDSILIAHEICHKYYICLHGRPRTMVCNNNLLFNPYTNQCDWPHNVECGDRLLCNCEDGNNDKECDETKSEESSPGDDGSGGGGGGGGGGGGSEGGEGGGGGGGGGGGGGGGGGGGGGGGGGDGSCNCNPGEAPSICAADGSDGVLIAHEYCNKFYKCDHGLPVALKCPGNLLYDPHLERCEWPDTVDCGDRIIPDPEDGGNGGDEGSGGGGGGGGGGGGGGGGGGGSEGGEGGGGGGGGGGGGGGGGGGGGGGGGSCNCNPGEAPSICAADGSDGVLIAHEYCNKFYKCDHGLPVALKCPGNLLYDPHLERCEWPDTVDCGDRIIPDPEDGGNGGDEGSGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGSCNCNPGEAPSICAADGSDGVLIAHEYCNKFYKCDHGLPVALKCPGNLLYDPHLERCEWPDTVDCGDRIIPDPEDGGNGGDEGSGGGGGGGGGGGGGGGGGGGGSEGGEGGGGGGGGGGGGGGGGGGGGGGGGGGGGGSCNCNPGEAPSICAADGSDGVLIAHEYCNKFYICDHGLPVALKCPGNLLYDPHLERCEWPDTVDCGDRIIPDPEDGGNGGDEGSGGGGGGGGGGGGGGGGGGGGGGGGGGGGSEGGEGGGGGGGGGGGGGGGGGGGGGGSCNCNPGEAPSICAADGSDGVLIAHEYCNKFYKCDHGLPVALKCPGNLLYDPHLERCEWPDTVDCGDRIIPDPEDGGNGGDEGSGGGGGGGGGGGGGGGGGGGGSEGGEGGGGGGGGGGGGGGGGGGGGGGGGGGGGGSCNCNPGEAPSICAADGSDGVLIAHEYCNKFYKCDHGLPVALKCPGNLLYDPHLERCEWPDTVDCGDRIIPDPEDGGNGGDEGSGGGGGGGGGGGGGGGGGGGGSEGGEGGGGGGGGGGGGGGGGGGGGGGGGGGGGGSCNCNPGEAPSICAADGSDGVLIAHEYCNKFYICDHGLPVALKCPGNLLYDPHLERCEWPDTVDCGDRIIPDPEDGGNGGDEGSGGGGGGGGGGGGGGGGGGGGGGGGGGGGSEGGEGGGGGGGGGGGGGGGGGGGGGGSCNCNPGEAPSICAADGSDGVLIAHEYCNKFYKCDHGLPVALKCPGNLLYDPHLERCEWPDTVDCGDRIIPDPEDGGNGGDEGSGGGGGGGGGGGGGGGGGGGGGGSGGGGEGGEGGGGGGGGGGGGGGGGGGGGGGGGSCNCNPGEAPSICAADGSDGVLIAHEYCNKFYKCDHGLPVALKCPGNLLYDPHLERCEWPDTVDCGDRIIPDCNEEDGSGGGGSGGGGGGGEGSCKCNPSEAPSICAAEGSDSILIAHEHCNKFYKCFNKRPVPLNCPEDLLYDPHLERCEWPGTVECGDRIIPDKSDDLNFCITIEPNDVNNNTNTSPSEVKAICARGNSEGTFIPHENCNQFYTCSNAIPVTLTCPSTLLYNLLTEKCDWPRYVDCGDRKLQGDNGNGNNKDEDTTAVICSKKESEGVLVAHEDCDKFYMCSSGNPVTLKCPSNLFFSPITQTCEWSKNVECGTRVVPGEENVNTGPCNCDPKQALSLCAQEGSNGKLVAHNVCSHYHMCVSGKTLSLACPSNLFYDPQKERCDFPANVSCEGRVAPVFLPPLNKHLEARQNIRHYF
Summary
Uniprot
ProteinModelPortal
PDB
6G9E
E-value=2.68303e-06,
Score=129
Ontologies
GO
Topology
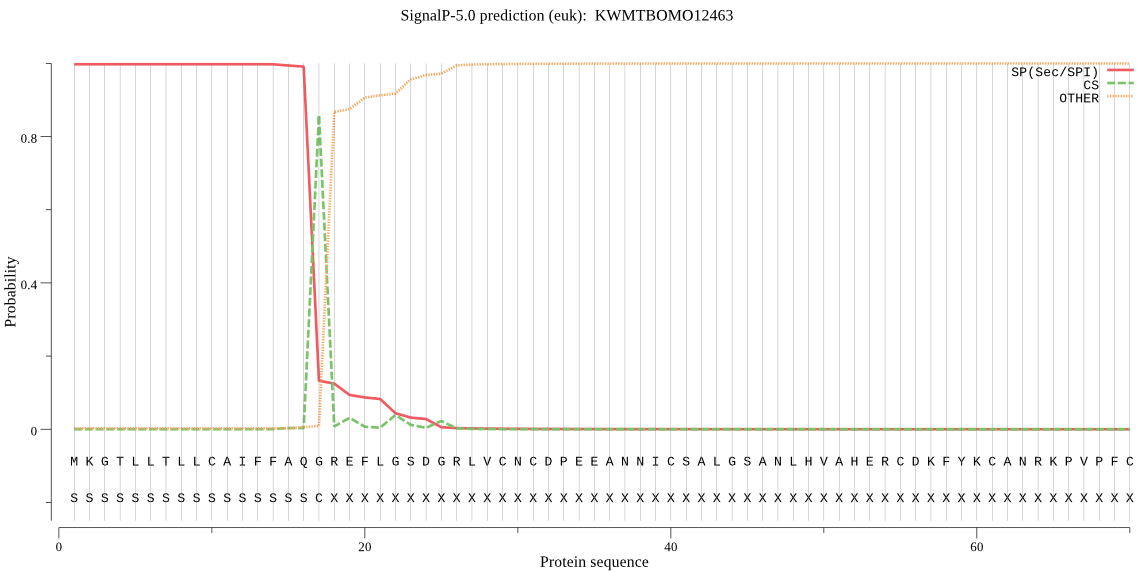
SignalP
Position: 1 - 17,
Likelihood: 0.997440
Length:
1878
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.0354
Exp number, first 60 AAs:
0.02705
Total prob of N-in:
0.00153
outside
1 - 1878
Population Genetic Test Statistics
Pi
205.359826
Theta
135.525742
Tajima's D
1.317825
CLR
0.394138
CSRT
0.742962851857407
Interpretation
Uncertain
