Gene
KWMTBOMO12367
Pre Gene Modal
BGIBMGA012369
Annotation
PREDICTED:_probable_GPI-anchored_adhesin-like_protein_PGA55_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 2.239 PlasmaMembrane Reliability : 1.736
Sequence
CDS
ATGACAGTGAGTAGTGCTTTGTCACAATCGACACAAAGCACGGCCAATGACGAAAAGCTCTCCAGATACAACGGATTAAATCAAACGTCGTGGATTCGTAGCTCTGATGCATCGAATGAACTGAACCCTAAGGACAACTCCGAAGAGCATACAGACAAAAACGCTAAATACAAAGACAGGGGAAGGATCAAATTTCATTCTCTTTTCAAATCGACTACAGCAAGTCCGTTGCGCAAAGCAAGTTCTACAGAGTCAGGCGATTTTGTAATAGTGACGCCAGCAACGGAAATAAAAAAAACATCAAGATATACAGAAGTTGCTAAAAGTGCTAAAAAAGACAATTCTCCTGTTAGTAGTACGACACCGGTTGCTGTAAAAAATGGAGAAGAGAGCATTGAAGAATATGATGACGAAGACGAGGAAGAAGAAAGGGAAACGCTGCAAAAGTTTTCTTCGAACAAATTCCATGAAAGCTTTTTTAAAATACCGAGCTTCGGCGACGACAACAACGAGAGTTCCAACAATAAAGTAAGAGAAGATTTCAGCAGTCCCTCCTATGGATTTTCTAGTTTCTTCCCAAAAGAAACTTCATTCGGCTATGGGCACAATGATAACAAAAATAATTTCAAATCGGAAAGTTTCTTTGATTTCGACAGTGATCTGACTACGCCGAAGAACGATTTCTTTGATAAAAAATACCAAGAGATCTCAGGTAGTATTATAAAAAAATTAGAAACTATTAAAGCTAAATCTCCACCGCCTAACATCACTAATGTACACAAGATCGTCAAAGAGAATGTTGGCCTAGAGAGGTTAGGGAATAACACACCGACTAACAAATCTACTGTTTTCATAAAAAATACCAAAGAGATACGTGTTTTAGACAACGAAGGAGCTGGTAGTGCTAACGAACAATTATCAGATGTACACGGCACCAGTATTTATTATGAAATGTCTGTACTGTCAACAGAAACCTACGCGATCAATCATTCTAATGATGATGATTGTGATAATGATACGTTACCAGCAGAACCCACCATGAGCACATCATCTGAAGAAGAATTGGCATCAATAAAAACAACTACGCCGACACCGATTCAAGTTTCTACTAGACCACCGTTTCCAGATCCAACAGTTGAAAACGTCTCAACGCTTTCATCAAATTACGTGCCCATTTCGACTGCTTTGCCAATATTTAACTCAATAATTCCGGTTTCGACGCAAAACTACATATCTTCAACAGAGAGAGTAACCAGAGTATTCTCAAGCAGTTTTAGTAGGAACAGAAATTACTCAAAGAGGCTTAATCTGAACGGTGTTAATGATTCACCAAATAGTGTGACATTGAAGACCGGCACATCAACTCATAAACCTCTAACTAGGAAGTTCCACTACACTACACAACGAGTCAGGCCAGTTTGGATGGCACCAAAAAGAAATGTTACCAAGCCAGCTTATCAGCGTCTGACGACTCCGACAACGATTTACTCGGAGCATTTCAACATCAAAGACAAATATACAACTACACCCAGACCGCGGCCGTCTAATAAAGTAACACTTACTACAGTCACGTCTGAAATAGACCCTGTGCTTCAAAGTGATGTAGGGGGCTTCAAAAAAGTGGTACACTCTCATTCAATATCCGATAATACGATTCCATCATTATGGAAAAGGGGATCCACAAAGTATAGAACATCAACTGCCACTTCAGACGAAGTTTCTAATGTGAGTGAAATGGAAATACCACCTACTTCTATAGTGTGGGCTCTGGCTAGCTTACGAAGCCCCTCCAGAAACTCAACAGGGTACAAAACTGACGACGAAAATGAGTTACAAAAAGTAGGAGAATTATTAGAAAAGAATGAAACAAAAACATCGACGACCACGATTGCAACAACCATGGAAATCAGCGAAGATATTACTAATAAAACAATAACAGAAGTTGAACAAAATAAACTTCCTTGGCAGTCTGTGCAAGCTTCGACACCACCCATCAACGACATGCAAAACGAAACCATTATAGAAAATAAAACAGAAAGGGTCACAGCTGAAAGCAATATTTCAGTTCAGAGCAGCCCCGAACCAAGTACCACGGAGACGGACACCACTAAGTCAACCACTAAAGCATTCAAACCGGCTTGGGTTTCAGCTACAACAGAAACGGAACAAAATATGACGGAAAAAGATAATCTTGTCATTAAAAGAGGTTTTGAATCGATTACGAAATTACCTTCAGGGATAACTACACCACAAGACGAAACGGAAGATTTGAACCAAATTACGACAAAAACGCCAAAAACAAGAGATGATTTTGAAATAACAACAATCAGATTTTCGTACGTACCGACACAGACGACGGAGACGCCTGACGATTCGGAGTATGAGTTAACAACCTTCAATTGGCGGCCAGTATTTCCTACTAGAACCCAAGCGACAACTATAAAAGATGAGCCAATAACCACGTATCGTCCTAAGTTTATAACAACAACTGAGCTTCTAGAGGAATCTACTACTGTAGAAGATACAACACCTCCCGTAATAGAATTATCTTCTCATATTATTGAGAACGCAACAGAAGATATTGTCCAAACTACTGATATAAATGAACCTACTATTGTATCAACTAAAGCTATTGAAATTAATAAAGCTACCACTATACCTAATAAAATTACTGAAAATATTAAAACTACTACTATTTCTGCAACAACTGAAATTAATGAGCCTACTACAATTAAAACTACAACTACTGAAATTAATAAACCTTATAGTATGAAAACTAAAATTACTGAATTTATTGAACCTACTGTTGTATCAACCACAACTACTGAAATTAATGAACCTTATACTACCCCAACTACTCAAGTTCCTACAACCAAACAAATCACTACCGAAACCAGTACCACTACTACCACTGAAGCAGCCACTGAAGATGTAAGTGAAACACTCCCAATCACAGTTACAAAAACAATCACAACGTCAACAACCACTTCACCTACAACAACTATGACGACAACACCTCTAGAAGACACCACAACGATTATTATAGAAGTGGTAACTGAAATAAATACAGAAAAAGAACGTACCATAACTGCTCCAATGCCAACTGAAACACCAAAACCAACTGCCGAATACACTTCAGAAAATATAGATGATAATGAAGTGATAGATCAAACTACCGCTCCGAGCATGCCGTCTGTTGCACCGACTATAGTTGTATCCACATCAAAAGTACCAATTTGGACTACTACAACTGCAGCAATAGAATATACTACTGAAGCCGTGGAGACTTCACAAGAGAACGGTAAAATAGTATCCAGCACTGATAGCGAAATGGAAACGACAAGGGCCGTGAGCGATTTAGAGGATCTGACCAGTTACGCCGGTGAAATGACCACGGAAGCTTCCTCGAGGGTTCTGAATTCGGAGGACAGTGGAACAGGAGTAGCTGTCGCTATAGCCGTCAGCACCATCGGGGTCATCGCTTTGGTTCTGCTCATTGCATTGTTGCTTGTGGTTCGCCGTCGGGGCAGGAGAGGTATATACGCTCAGAGATGTACTCCTGTCTCGTTGGACGCATACAGTTTGGACAGTGTCAGTGTCGGGCACAGGAAGGGAAACCAGCGGCTGAGGGCCAGTAAGCGCAGTTACGGTAACCCTGCTTATGATGATGAGGTCACTTCTCATCCAATGCAGTACTCGGCGTTAGCTTCTTTCGCAATGGACATAGAATCTATAACGGCCGAATTCGTCGAGATACCATCGGTATCCGTGAGACCTGAGGAGGTGCCTCCAGGTTGCGAGGACAAGAACAGGTACTCCAACGTGCTGCCGCTGCCGGAGACCAGAGTCCCGCTGTGCAGGATTGGAAACGACCCCACCACTGAATACATCAACGCTAATTATATTACGGGTCCAGGTAATATAAAGAACTACTACATCGCGTGCCAGGCTCCCCTCGCCAACACCGTTGGAGACTTCTGGAGAATGATTTGGGAACAGAACTCAAGACTTGTAGTCATGCTCACTGAATATATGGAGAATGGAGTGGAAAAGTGTTACGAGTATCTTCCACCATCAGAGGTGTCCGATAACAAGAGGTCCTTCGGGGATTTCAAGATAATCCTGAAGAAACGCGAGCAAAAAGACAAATACGCCATCTCCAGCGTTCAACTGATCAACATGTCGACCAGAACGTGGCGGGAAATAATCCACCTGTGGTACTTCTGGCCGGCGAAAGGAGTTCCAGACGACTACGATTCAATATTAGACTTCCTGTCCGAAATGAGGAATTATATGAAGATCTCGCAAACGGCGAAGGAATATGACGAGGAAGGCGTGGAAGTCATCTACGAAGACCAGAACCGTTCATCGTTCAGCAACCTAACCAAGTTGCGGAGCGATGACAACGGCTCCGGAAACGGAGTGAACGTGTACTCACCGGCCAAGGCCGAGGAGATGATGAGGAGGCACACCAACGGAACCTTGGGCCGAATGAAAGCGGCTTCCGAAGTCGAAGGCGTCCGTCCGTGCGTGGTGACGTGCGCGTCGGGCGCGGGTCGCTCGGCGGTGCTGGTCGCGCTGGACGTGTGCGCGCGCGCGCTGGCGGCGGGCCGCGCCGACGTGCCGCGCGCCGTGCGACACCTGCGCGCCCAGCGACCGCACTCGCTCTCCAACAGACACCACTATATCCTGCTCTATAAGGTGCTTAGCGAATATGGGAACAAGTTGACGGGCGGCGGAATCGACACTATCTGA
Protein
MTVSSALSQSTQSTANDEKLSRYNGLNQTSWIRSSDASNELNPKDNSEEHTDKNAKYKDRGRIKFHSLFKSTTASPLRKASSTESGDFVIVTPATEIKKTSRYTEVAKSAKKDNSPVSSTTPVAVKNGEESIEEYDDEDEEEERETLQKFSSNKFHESFFKIPSFGDDNNESSNNKVREDFSSPSYGFSSFFPKETSFGYGHNDNKNNFKSESFFDFDSDLTTPKNDFFDKKYQEISGSIIKKLETIKAKSPPPNITNVHKIVKENVGLERLGNNTPTNKSTVFIKNTKEIRVLDNEGAGSANEQLSDVHGTSIYYEMSVLSTETYAINHSNDDDCDNDTLPAEPTMSTSSEEELASIKTTTPTPIQVSTRPPFPDPTVENVSTLSSNYVPISTALPIFNSIIPVSTQNYISSTERVTRVFSSSFSRNRNYSKRLNLNGVNDSPNSVTLKTGTSTHKPLTRKFHYTTQRVRPVWMAPKRNVTKPAYQRLTTPTTIYSEHFNIKDKYTTTPRPRPSNKVTLTTVTSEIDPVLQSDVGGFKKVVHSHSISDNTIPSLWKRGSTKYRTSTATSDEVSNVSEMEIPPTSIVWALASLRSPSRNSTGYKTDDENELQKVGELLEKNETKTSTTTIATTMEISEDITNKTITEVEQNKLPWQSVQASTPPINDMQNETIIENKTERVTAESNISVQSSPEPSTTETDTTKSTTKAFKPAWVSATTETEQNMTEKDNLVIKRGFESITKLPSGITTPQDETEDLNQITTKTPKTRDDFEITTIRFSYVPTQTTETPDDSEYELTTFNWRPVFPTRTQATTIKDEPITTYRPKFITTTELLEESTTVEDTTPPVIELSSHIIENATEDIVQTTDINEPTIVSTKAIEINKATTIPNKITENIKTTTISATTEINEPTTIKTTTTEINKPYSMKTKITEFIEPTVVSTTTTEINEPYTTPTTQVPTTKQITTETSTTTTTEAATEDVSETLPITVTKTITTSTTTSPTTTMTTTPLEDTTTIIIEVVTEINTEKERTITAPMPTETPKPTAEYTSENIDDNEVIDQTTAPSMPSVAPTIVVSTSKVPIWTTTTAAIEYTTEAVETSQENGKIVSSTDSEMETTRAVSDLEDLTSYAGEMTTEASSRVLNSEDSGTGVAVAIAVSTIGVIALVLLIALLLVVRRRGRRGIYAQRCTPVSLDAYSLDSVSVGHRKGNQRLRASKRSYGNPAYDDEVTSHPMQYSALASFAMDIESITAEFVEIPSVSVRPEEVPPGCEDKNRYSNVLPLPETRVPLCRIGNDPTTEYINANYITGPGNIKNYYIACQAPLANTVGDFWRMIWEQNSRLVVMLTEYMENGVEKCYEYLPPSEVSDNKRSFGDFKIILKKREQKDKYAISSVQLINMSTRTWREIIHLWYFWPAKGVPDDYDSILDFLSEMRNYMKISQTAKEYDEEGVEVIYEDQNRSSFSNLTKLRSDDNGSGNGVNVYSPAKAEEMMRRHTNGTLGRMKAASEVEGVRPCVVTCASGAGRSAVLVALDVCARALAAGRADVPRAVRHLRAQRPHSLSNRHHYILLYKVLSEYGNKLTGGGIDTI
Summary
Uniprot
ProteinModelPortal
PDB
2C7S
E-value=1.56534e-24,
Score=285
Ontologies
GO
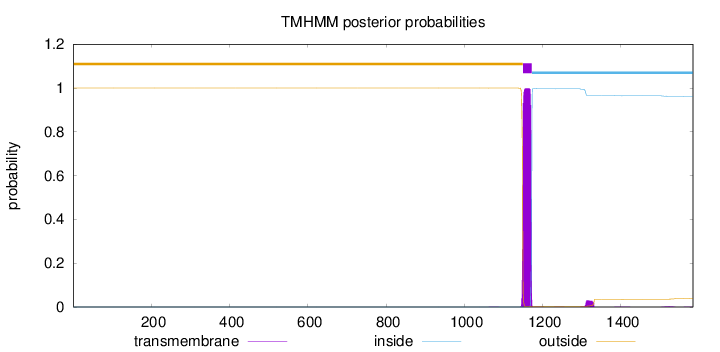
Topology
Length:
1584
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
23.84687
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00002
outside
1 - 1149
TMhelix
1150 - 1172
inside
1173 - 1584
Population Genetic Test Statistics
Pi
199.408738
Theta
151.326416
Tajima's D
1.308599
CLR
0.935472
CSRT
0.737663116844158
Interpretation
Uncertain
