Gene
KWMTBOMO12335 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA009184
Annotation
putative_peptidase_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.519
Sequence
CDS
ATGACGCGAACCGCGCTGCTGCTTGGCCCGCTACTGTGTCTGCTCTGGGGAAGTCGTGCGGCGCCAGGGGAGCTGCGCCCCGCCCCAGAACTGGAGCCCCCCGCACAGGGCGGCACCGGACTCGAGCGCTCCGTCCGCGCGAGCGCCTCCGCTTCCTGGCTCAACCTCATTGCAGAGTACGCGGACCGCTCGGAGAGTGACTCCGCCGAGGACGACGACTGGTTCCCGAAGCCAATCCCCATCACTATCCCTCTGGGTCGCAAGAAGTCGATGCCGCTGCTGGTGCTGCCGATACCGGTCCCCGCCTCCTCTTCCAAAGGTTGCGCCGCTGATGTGAGAGAGTCGAGCAGCGCAAGGCCGCCGTGGAGCCGACCGCTGGAGGGGTCCAGTGCCGAGCTGGACGAGCAGCTGCGGAGCGACGTCGCCGAGCCCCGCCCGCATGCGCCCCCCGCCCTCCCGCACAGGGCGACCCCCTCCCCCGGGAGCCGCGCGCCTCAGGAAGACCAGCACGTCGACGTGCCGCGCATACACAACATCGGTTCCTCACAAGAGCTCGTGAAGCTGTTCCACGATCAGAAGCCGGACAATCCTAATCTACCGCCTCTGCTGCTACCCGAATACGACAAGGAGGAGGCGACAGACGAACAGAGTGTATCCGGAAGCGAGGAGCAGCGCGGCCGGGGGCGCGGGGCGCCGGCGCCGGACGTCGCGCAGCCCGCGCGGCCACGCTTCGACCGCTCCATGCTGATGCGGGGGACGCTCACCGTGCCGCGCTCCGACTACACAGAGACCTTCACCGTCTGGTGGGACGCCTCGAGCGGTGCGGCCCGAGTAGACTTCTTCGACGGTGCCACGTCCACGTACCGCGTCGTCCTCCCCGACGGACACGTCCAGGGCGTCGAGATGCACGTGGACCGCACCGAGGAGTTCGACGTGCTGCGCTGCGTGCAGACGGCCCCCCGCCGCGCCGCGCCCCCGGACCGCGCCCCGCCCGCCCTCCCCGACCTCGACCTCTTCTCCTTTGGCGGCTACACCGAGACGCCGCAAGGCAGGGCCGAGCGGTGGAAGCTGACTGCGGCGGGGCGCGGGGGCGAGCTGGGCGGCGTGCGGGGGGAGGCGCTCACCTTCCGACACGAGCTGCTCCTGGTCCGCGCGCCAGACAACTACACCGCCGTACCGCTGCAGTACACAGTGTCTGTGGACAGCTCGGTGCTGGGCTACAACGTGGAGGGCTACGAGTTCCGCTACCAGGAGCTCCGCTACGAGACTCCGGACCCCGCCCTCCTCCAGCCCAACACAGCGGACGTGTGCGAGGAGCTGTCGCAGACAGACAAGATCGAAGTGGTGGAGCCGCTTCGGGAGTACACCATGCCCTACAGAGACCCGCGCTACGACGCCGAGTTGATACGACTCAAGACCAAGTTTTATAGACAGTACTCGGACGATGTTGAAGAAGCTTTGCGTAAGACTCTGCTGATCGGAGCGAGTCGCTTCATATCGGCAGCGAACCGGCAGAGCGGTCCCTCTTTGCTGGAGGTGAACTTTCTCGCGGACAGGCTAGAGGCCGAGCAGCGCCTGCTACTGGGGGCCGGCGAGGCTCCAGGTCCGTCCTCTGCAGAGGCGGCTCCAACCTCCCAACGACGCGCTCGTCGCGACGCGGAGCGCCTACCAAGAAACTTCGACTGGCGCAGGCACGGAGCCGTCACACCCGTTAGATTCCAAGGCTCGTGCAGCTCGTGCTGGGCCTTCGCGGTGGTGGGCGCCGTGGAGGGCGCGCTGTTCCTGCGCACCTCCCGCCTCGTGCCCCTCAGCGAACAGGATCTCATCGACTGCGCTCACCCGTACGGCGGACACGGGTGCTCGGGCACGTGGCCGCGCGCAGCTTACGACTACATCCAGGACCAGGGGTTGCGGGCCCTGGACGAGTATCTACCCTACGAAGCAAAGGTGCTGCAGTGCGCGGCGCGGCAGACGCGGCCGGTGACGCACATCAGCGGGCACGTGAACGTGACGCGGAACAGCGAGCTCGCGCTCAAGGCGGCCATCAGACGGAACGGACCCAACGTCGTGCTCGTCGATGGACAGTCCAAGGGGTTCATATACCACAAGAAAGGCGTCCTGTACGACAACCGATGCAAAAAGCGGTCACGCAACCACGCCGTACTCGCTGTAGGATGGGGAGAACGTCGTGGAGAGTCCTTTTTCGTGGTGAAGAACTCGTGGTCGTCGAATTGGGCGAATGAGGGCTACGGATGGCTTCACGCGCCCTCCAACACGTGCGGTGTGCTGACGGAGCCCTCGTACCCTGTGCTCCGGGACCCCGACGTGGACCGCTTGCCGCGGGAGTCTTCCTCCACTGACCCCGCCCCTCCATTATCATCTTCACCAGCTCCACCAGTGGCCCCCGTGCCACAGCGCTCTAAAAGAACCTCCAGGAGGAGAAAACGCTCACGCGACAATGCTCCAGTGGGAGATGGGTCGGTGGATCTGTCCTCAGATGAGGAAGGCTTGCTGCCCCCCAAGAAATTACCGACCACGAGGAGAGGTCGGCAGGCTTCGAGAGGAGTGAGTGCTTCACGGCCGCGGAGGAACGCACAGGGTAGGTTCGTGTGCTCCAATACTCCGGCTGCCAGCAAAGCAGATAGTGACATGGGGGTCACTACCGAGGACCCTGGTGGCGAGAGCTGTGCCTCGCTAGGGAGCTCAAAGGCGGAGATCAACGCCGCCCGAAGAGAGCAACGCAAAGCTGTCGCGGCCGACGAAGTGTCGGAAATGGCCCGACGCGCTCGCGAGCGACGCGCTACTCTAGCGGCGGAAGGGGGGGAACCATCTGCGGTGGCCCTAAGTCAGCTTGCCTTGGACGGGGTGGACTTAGTCCTGAAGGTTGCCACCAAATCCGGCAGCCTTAAGGGCACGTTTACCCGCGGTCTGAAAGAAGCTGCCGCGGACATTAAGGAGGCGATTGGCATCCTCCTCAACAGGACGGCCTCTGACGAGGTTGCGAAGTTGCAGGAGGAAAACAGCCGTCTCCGAAATGATATGGAGGACCTCCGGCGACGAGTCACTGCGTTGAGCGAGCAGCAGCAGCGGCGTACGTCCACTGATGCCGCATCGGTAGTGGCCCCGGCTCCCGCACCGAGACCGACAAGCACTCATACCGACGACGAGGTCGAGCGCATTGTCCGGCTCTGTATGCTCCAGTGCGGGAGCATGGTCAATGCTCGTATGGAGGCAATTTCTCGGCGCCTCCCTGCGGAAATCCTCCGTCCGCCACTAGCGGCCGATACACGGCGGAGGGCTGAGGAGCCGCCGAGACCTAAGCCTAGGGAGGGGAAGCCCGCGGAGGGTGTTAAAAAGCCCGTCGAGGGAGCCCCATCGAGCGATCAGCCCACGACTGCTGGGTCTAAGGGTGAGACCTGGGTTACAGTCGTGGGCCGCAAGAAGGCACGCAGGGTCGCCAAGGCGGCCTCAGCAGCAACGCATGCCCCCGGCCAAACCGCAAAGGCGGTTGCGCAGCCTGCGCGGCGGGCTGCCAAAGGCGGTCGCAAAGGACCGGCGATACGTGCTCCGCGTTCCGAAGCTGTGACGCTCACGCTACAGCCTGGAGCTGCGGAGCGCGGCGTAACGTACCAGTCGGTCATCGCCGAAGCAAAGGCCAAGATCAAATTATCAGATCTTGGTCTTCAGGCCGTCACCCACAGGCAGGCTGCCACGGGTGCACGGCTAGTAGCTCCGTAG
Protein
MTRTALLLGPLLCLLWGSRAAPGELRPAPELEPPAQGGTGLERSVRASASASWLNLIAEYADRSESDSAEDDDWFPKPIPITIPLGRKKSMPLLVLPIPVPASSSKGCAADVRESSSARPPWSRPLEGSSAELDEQLRSDVAEPRPHAPPALPHRATPSPGSRAPQEDQHVDVPRIHNIGSSQELVKLFHDQKPDNPNLPPLLLPEYDKEEATDEQSVSGSEEQRGRGRGAPAPDVAQPARPRFDRSMLMRGTLTVPRSDYTETFTVWWDASSGAARVDFFDGATSTYRVVLPDGHVQGVEMHVDRTEEFDVLRCVQTAPRRAAPPDRAPPALPDLDLFSFGGYTETPQGRAERWKLTAAGRGGELGGVRGEALTFRHELLLVRAPDNYTAVPLQYTVSVDSSVLGYNVEGYEFRYQELRYETPDPALLQPNTADVCEELSQTDKIEVVEPLREYTMPYRDPRYDAELIRLKTKFYRQYSDDVEEALRKTLLIGASRFISAANRQSGPSLLEVNFLADRLEAEQRLLLGAGEAPGPSSAEAAPTSQRRARRDAERLPRNFDWRRHGAVTPVRFQGSCSSCWAFAVVGAVEGALFLRTSRLVPLSEQDLIDCAHPYGGHGCSGTWPRAAYDYIQDQGLRALDEYLPYEAKVLQCAARQTRPVTHISGHVNVTRNSELALKAAIRRNGPNVVLVDGQSKGFIYHKKGVLYDNRCKKRSRNHAVLAVGWGERRGESFFVVKNSWSSNWANEGYGWLHAPSNTCGVLTEPSYPVLRDPDVDRLPRESSSTDPAPPLSSSPAPPVAPVPQRSKRTSRRRKRSRDNAPVGDGSVDLSSDEEGLLPPKKLPTTRRGRQASRGVSASRPRRNAQGRFVCSNTPAASKADSDMGVTTEDPGGESCASLGSSKAEINAARREQRKAVAADEVSEMARRARERRATLAAEGGEPSAVALSQLALDGVDLVLKVATKSGSLKGTFTRGLKEAAADIKEAIGILLNRTASDEVAKLQEENSRLRNDMEDLRRRVTALSEQQQRRTSTDAASVVAPAPAPRPTSTHTDDEVERIVRLCMLQCGSMVNARMEAISRRLPAEILRPPLAADTRRRAEEPPRPKPREGKPAEGVKKPVEGAPSSDQPTTAGSKGETWVTVVGRKKARRVAKAASAATHAPGQTAKAVAQPARRAAKGGRKGPAIRAPRSEAVTLTLQPGAAERGVTYQSVIAEAKAKIKLSDLGLQAVTHRQAATGARLVAP
Summary
Uniprot
ProteinModelPortal
PDB
3QT4
E-value=1.53784e-40,
Score=422
Ontologies
GO
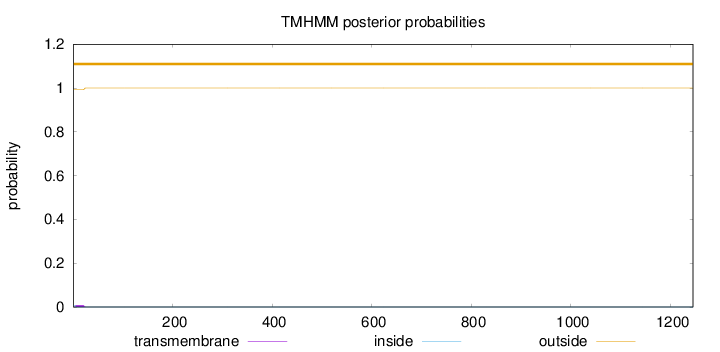
Topology
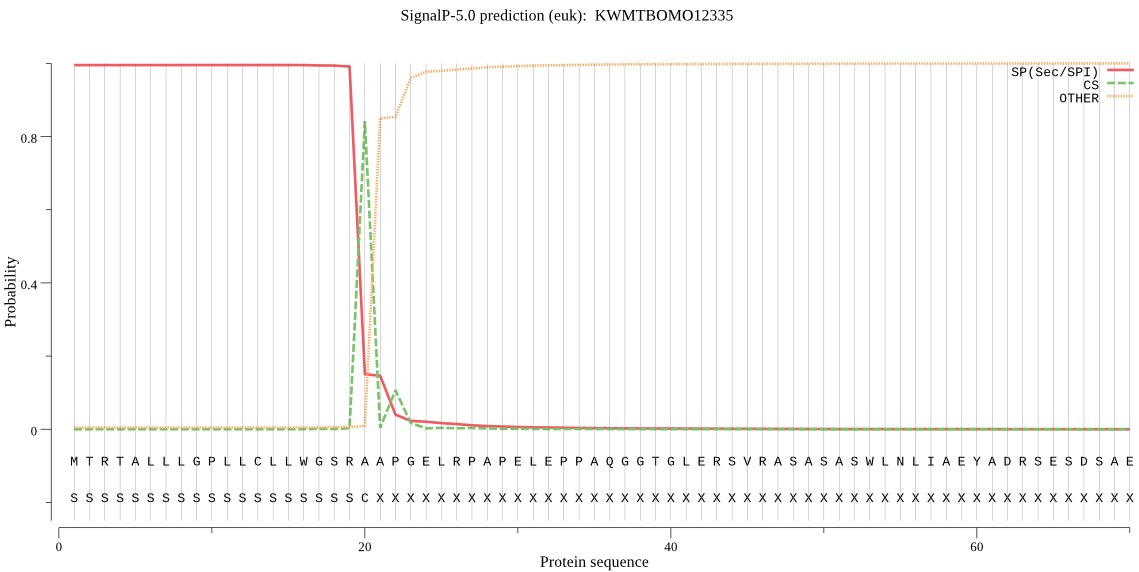
SignalP
Position: 1 - 20,
Likelihood: 0.995001
Length:
1245
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.1401
Exp number, first 60 AAs:
0.13977
Total prob of N-in:
0.00773
outside
1 - 1245
Population Genetic Test Statistics
Pi
2.655888
Theta
17.753349
Tajima's D
0
CLR
0.282665
CSRT
0.374781260936953
Interpretation
Uncertain
