Gene
KWMTBOMO12052
Annotation
reverse_transcriptase_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.201
Sequence
CDS
ATGGAGGAAAAACTTTTCATCGACTTCATTCGGGAAAAATATCCGTCAATCGCGCCCGAATTCGAAGCCTATAGGGCCTCATTTGGTAATTATTCTCCCCCCGCATCTTTCGCCGCCGTCGCCAAACATGCCTCGCAGGCATGCCTCGCGTGCCCCGCCGCCGGTCCGTGTTCAAGCGCACGTACGCACGCCGCCGCCGTAGCGTCTAACGCCCCCGCCCCCGCTACCCCCGCGCCCGCGTCAATCACGTCAGTTTCGTCCGTCGCGACCTCAATAGCGTCTAGTTCAGGCTCCGATACCGAATCGGAGATGGACTTCGAGTCCGCGACTAGCCCTCAACCCGGAACCACGGATGGGTTCCAAACTGTAACGCGCGGTAAAAAGCGTACTCGCGTCGTGGAGTCCCGGAGCTCCATGACGAAGCAAACCAAGTCCGCGACCGCCTCCCGACCGCAGGTAGTCGTAACGCCGGAGTCGGACTCCGCCCGCCGCGTAATCCCACCGCCGCGCCCAAAAACCGCGCCCGCGCCTAAAACAGTTGTCCCGCCCCCGCTGATACTCCAGGAGAAGTCAGCGTGGAATCGCGTATCCCAGGCCCTTCAAGCCAACAAAATTAATTATACCCATGCGCGTAACGTCGCGCATGGGATTCAGATTAAGGTCGCAACGCCGGGCGACCATAGGGCCCTCTCTGCTTACCTCCGAAAGGAGAACATAGGTTATCACACCTATGCTCTTCAGGAGGACCGCGAACTCCGCGTAGTGATACGTGGAGTCCCCAAGGAACTCGACATAGACTACGTAAAGGAGGATCTGATCGGTCAGTCCCTCCCAATAATTAGTGTGCACCGGATGCACAGCGGACGCGGCAGACAGCCGTACAATATGATTCTCGTCGCGCTAGAATCAACCCCGGAGGCAAAGAAAAGAATCTCATGTCTCAAAACGATATGCGGCCTCTCCGGGTTCACCATCGAAGCCCCCATAAACGTGGTACTCCCAGGCAGTGCCACAGGTGCCAGCTCTATGGCCACTCAGCGCGAGGGAACACAAAACGTACCCCAGCTCCCGCCTGCGACACGTCACGCGCCTCAGCCCCTGCTCGCACCTCGCCCCGCGCCCGCGTACCGCCCCCCGCAACCCTCAGTCGTCAACGACTTCGCGCTCGTGCGCGACTTCGTCACCGCGGTAAACTTTGATCGTCTGCGATCGTTCGCAGATGCTATCCGTAGTGTGCCGTATCTCGCTGACGGAACACCAGCCGATCGTCATCGCATCCTTTTATCTCCCCCGGACAAGCCCCTCCTGAGCAGTGACATCGAGTCACTGTTTGGCATGGGAGACTCCGTCATCCTGGCAGGCGATTTAAATTGCCACCACACTAGGTGGAACTGCCATCGTACGAACGTTAACGGTAGGCGTCTCGACGCGTTTATAGACGACCTCACTTTTGAAGTAGTCGGTCCCCCAACTCCAACATGTTATCCGTATAACATCGCGCTCCGTCCGAGCACTATAGACCTGGCATTGCTTAGGAACGTAACTCTGCGCTTACGTTCCATCGAAGCACTGTCAGAGCTCGACTCAGACCACCGACCTGTCTTTATGCAGCTCGGTCGCCCTCACAACCCAGCCACTGTTACGAGGACCATGGTGGATTGGAATAAGCTGGGCACGTGCCTAGCCGAAGCCGCTCCGCCAATCCTCCCTTACGGCCCGGATTCGAATCTATCCCCCGAGGACACCGTCGAATCCATAAACATCATTACCGATCACATCTCTTCCGCGATCATTAGATCTTCAAAAGAAGTCGATGTGGAGGACAGCTTCCACCGCATCAGACTGTCCTCCGAACTTAGGAATCTCTTAAGAGTTAGGAACGCGGCAATCCGGGCCTACGATCGTCTTCCCACGCATTCAAACCGGATTCGGATGCGTCGTCTACAACGCGTAGTCCACTCCCGCCCAAGTGACGCGCGTAACGATAATTGGCATAGTTATTTACAACAACTCGCGCCCTCCCACCAAGCATACTGGCGACTAGCTAGGACTCTCAAATCCGAAACTACCGCTACTATGCCTCCCCTCGTACGCCCTTCAGGCCAACCACCGGCATTTGATGACGATGATAAGGCTGAGCTGCTGGCCGATGCACTGCAAGAGCAGTGCACCACCAGCACTCAACACGCGGACCCCGAACACACCGAGTTAGTCGACAGGGAGGTCGAGCGCAGAGCTTCCCTGCCGCCCTCGGACGCGTTACCCCCCATTACCACTGACGAAGTTAGAGACGCGATCCACAACCTCCAACCTAGGAAGGCACCCGGCTCCGACGGCATCCGCAACCGCGCGCTAAAACTCTTGCCAGTCCAACTGATAGCAATGTTGGCTACAATTTTAAATGCCGCTATGACGCACTGCATCTTTCCCGCGGTGTGGAAAGAAGCGGACGTTATCGGTATACATAAGCCGGGCAAACCGACAAACGAAACTTCTAGTTACCGTCCGATTAGTCTCCTCCCAACGATAGGAAAAATTTACGAACGGCTCCTTAGGAAACGCCTCTGGGATTTTGTTACCGCGAACAAAATTCTCATAGACGAACAGTTCGGATTCCGCTCTAAACACTCGTGCGTACAACAAGTGCACCGCCTCACGGAGCACATCCTGATAGGACTAAATAGGCGTAAACAAATCCCGACCGGCGCCCTCTTCTTCGACATCGCGAAGGCGTTCGACAAAGTCTGGCACAGCGGTTTAATTTACAAACTGTACAACATGGGAGTGCCAGACAGACTCGTGCTCATCATACGAGACTTCTTGTCGAACCGTTCGTTTCGATATCGAGTAGAGGGAACTCGTTCTCGTCCCCGTCAACTAACTGCCGGAGTCCCGCAAGGCTCCGCGCTCTCCCCGTTATTATTTAGTTTGTATATCAATGATATACCCCGGTCTCCGGAGACCCATCTAGCGCTCTTCGCCGATGACACGGCTATCTACTACTCGTGTAGGAAGATGTCGCTGCTTCATCGGCGACTCCAGATCGCAGTAGCCACCATGGGACAGTGGTTCCGGAAGTGGCGCATCGACATCAACCCCACGAAAAGCACAGCGGTGCTCTTCAAAAGGGGTCGCCCTCCGAATACCAATTCGAGCATCCCACTCTCTAATAGGCGCGCAAACACCTCCGCCGTTAGCCCCGTCACTCTCTTTGGCCAGCCCATACCGTGGGCCTCGCAGGTCAAATACCTAGGCGTCACCCTCGACAGAGGGATGACATTCCGTCCCCATATTAAAACGGTACGCGACCGTGCCGCCTTCATATTAGGACGTCTCTACCCTATGCTTTGCAAGCGAAGCAAACTGTCCCTCCGTAATAAGGTAACTCTCTACAAAACTTGCATACGCCCCGTTATGACGTATGCAAGCGTAGTGTTCGCTCACGCAGCCCGCACCAACTTGAAGCCCCTTCAGGTTATTCAATCCCGATTCTGCAGGATAGCCGTCGGAGCACCATGGTTCCTGAGGAACGTGGATCTCCACGATGACCTGAAGCTTGACTCTGTCAGTAAGTATCTACAGTCGGCATCGCTGCGCCATTTTGAGAAGGCGGCACGACATGAGAACCCTCTCATCGTAGCCGCTGGAAATTACATACCCGACCCAGTAGACCGAATGCACCCGTTCCGCGACAGCCACTGCGGCAATACTCGAGCCACCACGTTTGCCACGAGTAAGAAGTCTAAAAATCACACGTGGTGGCCGAAACCTGAGCGGTGGCCGTCCGGAATATTGGTCCTTCGAGAGCCGGATTCATTTGAGGAAGATCGAAGAAAATTGAAGATTGAAGAAATGGTGCTCACACGGTCCGAGAAGATGAGGTCGTCACGCCTTGACCGGCCCGGCAACGAAGCTGTCTCGGGCTCAACATCGCAAGACGCACAGCAACGAGCTGTGTCGGCCGCGCCGCGTTCGGGAGTGACGCAGGGACCGCCACCGTTGGCGGCAACCTCCTCCCAGTCAACCGCGCCGCGTTCGGGAGTGACGCAGGGACCGCCACCGATGGCGGCACCCTCCTCCCAAGTGGAAAAGTGTCCGGGAGTGCCGCGGGGCTCACAAGCGATGCCCCCCTCCCGCCAAATATTGCCTACGCAATACTCGCCGGCGTCGCCAACGGGACCGAACAGCGGGGTCTGTCGTCGAGTGGTCAGACCTCCCAGCACCGCGACACCGGCAACAACTTCAGGCGACGCAGCAACGGAGAGCGTCGTATCCGCGAGCCAGAACAAGAAGGAGTCAGCGCTCACGGCCAATCCAATAGTACACGGGTCCCACATCACGGACGCCGCTGCCAAAATCTCGACGACAGAAGAAGGCTCCACACTCCGCGACGGGATGGCGCCACCAGTACGAGGATCTTCAAGAAAGTCGAGTCAACAGTCACAACGGCTGTTGCTTATGGCGCGCCTCAAAGAAGAGCATCTTCGCGCCAAAGAAGAACAAGCCCGACTCCAAGCAGAGCTCGCCGCCGCCCGCATCTCAACATTAGAAGCCGAAGCGCTCGTTGAAGAGGAGGAAGATGCGCGCACAACACTCACGGAGGACGAGAACGAGCAATCGCAGCGCATCGATACATGGCTCAGTCAGCAACGATCGATCGCGCTACACGGAGTCGAAGAAAGAGTAATGCAGCCAACACACGGATCACCAGCCACCATCGAGCAACCGCAACTGGAACTTCCCGCACCAATAGAACAGCTGAAGCTACCGGCCCCTGCCGCGGCACCGATTGCCGCACCTGTCGCACCGAAGAGCGACATCGCCGAACTAGCAGCTGCCATCGCGACGGCCGCCCGCCAAGCCAGGCCCGGACCATCGCATCGGTACTACGGGGAGCTTCCAGTGTACAGTGGATCGCACCAAGAATGGCTCTCCTTCAAGGCCGCCTACGCCGAATCAGCGGACAGCTTCAGCGCCGCAGAGAACACTGCGAGACTTCGGCGTACGTTAAGAGGAAGAGCAAGAGAAGCGGTCGAAAACTTGTTGCTGCATTACACCGAGCCCGCCGAGATCATGCGGACTCTAGAATCGCGCTTCGGACGTCCAGAAGCAATCGCCGCAACGGAGCTGGAACGACTGCGCGCGCTGCCACGCTGCACGGACACACCGAGGGACATCTGCGTTTTCGCGAACAAGGTGAACAACGTCGTCGCCGCTCTGAGGGCCCTCGACCGCGTACATTATATGTACAACCCGGAGCTCACCAACATCACATCAGAGAAGCTGCCGTCCACTCTACGCCACCGCTGGTTCGAATTCTCAGCAACTCAACCGGCGGGAGAACCGGACCTCGTCAAGCTGTCGCGCTTCCTGCAACGCGAGGCGGACCTGTGCAGCCCATACGCACAGCCGGAGCCAGAGACGAGAGTGGAGAATACCAGCGGTCGGCGGAAGATGTTGAACACGCCTCAGAGGACGCACACCACGCAAGCGAAGGAAGAGAGGAAATGCGCAGCATGTCAGAAGCCGGGGCACATCCCACAAGATTGTCCCGAATTCAAGAGAGCAGCCGTCAGCGAGCGCTGGGATACGGCGAAGCGCGAGAATTTGTGTTTCCGGTGCCTACGGTTCCGGTCCCGGGGACACGTATGCAAAAAGAAGAAGTGCGGCGTCGACAGCTGTGAACGCACGCACCACGAGCTGTTGCATAAGAAGCCAGCATGGCAGAAACCGAAAGAAAAAGAAGAGGCGGTCACCTCGACGTGGGCCGCAAGAAGTGCGACAGCCTACCTAAAGATGGCGCCAATTACTGTTATCGGACCGGCGGGAGAAGCAGATACATGGGCCCTGCTGGACGACGGGTCAACGATCTCGCTGATTGACGAAGACTTCGCGAGACGAGTGGGCGCCAAAGGACCGATCGAACCCCTCTTCATCACTGCCATCGGAGACAATAAGATAGACGCAACACGCTCACGACGCGTCCCGCTGAAGCTATGCGGACGCACGGGGGAACCGCAAGAACTGAACCTACGGACAGTCAACGGCTTAAAATTAACACCACAGCGACTGAACATCGAAGTCCTCGCGTCGTGCCACCACCTCACCGACCTCCGCCATCACTTCAAAACGAGCTACGCCTCGCCGAAGATACTGATCGGCCAAGACAACTGGCACCTGCTGGTGACGGAGGAGATGCGGACGGGACGACGCGATCAACCAGTGGCGTCTCGTACTCCGCTCGGGTGGGTTGTGCACGGAGCACGCCCGGGAGGCAAGAGACAGCGCGTCAACTTCGTAGGACACGCGACGACGGCCGACGCGAACATGGACGAAGCCCTCAAACAGTACTTCGCGATCGAGGGACTCACCGTCGCCGCCAAGACACCGAAGAACAATCCAGAAGAGCGCGCGCTGAAGATCCTGCGAGAGACCACTCAACAGCGACCCGACGGCCGCTATGAGACCGCACTGCTGTGGCGTGAGGAGAGCCTGAAGATGCCCAACAATTTTGAAGCCGCGATGAATCGCCTGACGTCCGTAGAAAAGAAGCTGGAGAAGGATCCAAACTTGAAAGAGCGCTACAAGCAACGAACAAACGCGCTGGCAGCGAAAGGATACGCCGAAGTAACTCCGTCGACGGGTACGAAGAAGCGAACCCGGTACTTGCCGCACTTCGACGTGACGCATCCCAAGAAGCAGGAGAAGATTCGCATCGTGCACGACGCCGATGCGAAAAATAGAGGAAAGAAGCCCAAAAGACTTCCTGCTCACCGACCCGGACCTGCTGCAGTCGCTGCCCGGAGCGATGATGCGCTTCAGGCAGCACGCCGTCGCCGTGGACATCGCGGAGATAATCATACAGATAGGCGTCCGAAGCGAGGACCGCGACGCGCTCCGGTACTTGTGGAGGGAGGACCCTTCACGAGAGCCTATAGAATACCGGATGAGGTCCATCGTCTTCGGCGCGACAAGCGCACCTGCAACCGCCATCTGCGTGAAGAACCGACTGCAGTACCCGGACGCCGCCGACCTCAAGCTCCACACACACGAGTGTTCTGGACCGACAGCGCCACCATAGAGGAGAACAGCACTGTGGAGGAATGGCGCTGGGTCCCCACAAAGGAAAACGTCGCCGACGACGCCACTAGAGAACTACCCGTCGGCTTTGAAAGAAACCACCGCTGGTTCATAGGCCCGGAATACCTAAGACGGCATCCGGATGATTGGCCCGTACAACGGACTGCAAAAAGGGCAGAAGAGACGGGCGAAGAGAAGTGCGCAACGCTCGCCGTGAGCAGAGAGAGCCTCGGCGAAGCGATCCCGGACCCAAGACGCTTCTCCAAGTGGGAGAAAGCAAGCAGTCATTCAATGGAAGACTTTAGACGCCGACACGCTTCGACGCGCCGAGACGCTCATTTGGCGACAGAGCCAGCGGGCAGCCTTCGAGGAAGAGATTTGACGCTCCAGCGAGGGAAACAAATATCCCCAGCGAGCCGACTGCGAAACTTGTCCGTGACTTACGCGGACGGGACACTGAAAATAAACGGACGCATCGGCAACATAGAGGGTGCTGACGTCATCACCTCGCCTCTCGTGCTAGACGGATCCCGACGCGAAACGAGACTGATGATAGACTTCATCCATAGAAAGATGCACCACGCCGGAACCGAAGCTACGATCGCCGAGTGCCGACAGTCGTACTGGGTCTTACGCCTACGCCCAGTGACACGGAGCGTGATCCACAATTGTCTTCCGTGTCGTATCCGCAAGGACACTCCACCGCGTCCAGCCACAGGCGACCACCCACCGAGCAGACTGGCACACCATCGGCGACCATTCACATACGTGGGCCTCGATTACTTCGGGCCCTATCAAGTTACCACCGGCAGAAGCACCCAGAAGCACTACGTGGCCATCTTCACATGTCTCACTACGCGTGCGGTGCATTTAGAACCGGCAGCGAGCCTCAGCACGGACTCAGCGGTGATGGCACTCCGGCGCATGATCGCGCGCCGGGGAGCCCCGACGGAGATATGGAGCGACAACGGCACCAATTTACGAGGTGCCGACAAGGAGCTGCGCCAAGCTATGGACAAGGCGACTGAGCATGAAGCGAGCTTAAGACTTATCCAATGGCGCTTCATCCCACCGGGCGCGCCTTTCATGGGCGGCGCCTGGGAAAGAATGGTGCGGGCGGTAAAGGCCGCGCTCTCGGCCACGGAACAGCCGAGGCACCCGACGCCCGAAATATTTCACACTCTGCTAGCGGAGGCAGAGTTCACAGTGAACAGCCGACCTCTCACCCACGTATCGGTGAGCGCCGACGATCCCGACCCTCTAACGCCAAACCACTTCCTGCTAGGAGGCCCGGCGCGGGTCCCCGTGCCGTCTGGAGTCGCTGGCTCCGGGAGGGCCGACGGCATCACTCGAGTGGTCGACGTGCGCACCGCCGGCGGTATCCTGCGACGCCCGGCGAAGAAGATTATCGTGCTGCCCACGATGTCCGCCGCTCACCAAGGAGGATGCAGCGACGTGAACGACGCTGCACGGCGGGAGGATGTTCGCGACGGACATGAATAA
Protein
MEEKLFIDFIREKYPSIAPEFEAYRASFGNYSPPASFAAVAKHASQACLACPAAGPCSSARTHAAAVASNAPAPATPAPASITSVSSVATSIASSSGSDTESEMDFESATSPQPGTTDGFQTVTRGKKRTRVVESRSSMTKQTKSATASRPQVVVTPESDSARRVIPPPRPKTAPAPKTVVPPPLILQEKSAWNRVSQALQANKINYTHARNVAHGIQIKVATPGDHRALSAYLRKENIGYHTYALQEDRELRVVIRGVPKELDIDYVKEDLIGQSLPIISVHRMHSGRGRQPYNMILVALESTPEAKKRISCLKTICGLSGFTIEAPINVVLPGSATGASSMATQREGTQNVPQLPPATRHAPQPLLAPRPAPAYRPPQPSVVNDFALVRDFVTAVNFDRLRSFADAIRSVPYLADGTPADRHRILLSPPDKPLLSSDIESLFGMGDSVILAGDLNCHHTRWNCHRTNVNGRRLDAFIDDLTFEVVGPPTPTCYPYNIALRPSTIDLALLRNVTLRLRSIEALSELDSDHRPVFMQLGRPHNPATVTRTMVDWNKLGTCLAEAAPPILPYGPDSNLSPEDTVESINIITDHISSAIIRSSKEVDVEDSFHRIRLSSELRNLLRVRNAAIRAYDRLPTHSNRIRMRRLQRVVHSRPSDARNDNWHSYLQQLAPSHQAYWRLARTLKSETTATMPPLVRPSGQPPAFDDDDKAELLADALQEQCTTSTQHADPEHTELVDREVERRASLPPSDALPPITTDEVRDAIHNLQPRKAPGSDGIRNRALKLLPVQLIAMLATILNAAMTHCIFPAVWKEADVIGIHKPGKPTNETSSYRPISLLPTIGKIYERLLRKRLWDFVTANKILIDEQFGFRSKHSCVQQVHRLTEHILIGLNRRKQIPTGALFFDIAKAFDKVWHSGLIYKLYNMGVPDRLVLIIRDFLSNRSFRYRVEGTRSRPRQLTAGVPQGSALSPLLFSLYINDIPRSPETHLALFADDTAIYYSCRKMSLLHRRLQIAVATMGQWFRKWRIDINPTKSTAVLFKRGRPPNTNSSIPLSNRRANTSAVSPVTLFGQPIPWASQVKYLGVTLDRGMTFRPHIKTVRDRAAFILGRLYPMLCKRSKLSLRNKVTLYKTCIRPVMTYASVVFAHAARTNLKPLQVIQSRFCRIAVGAPWFLRNVDLHDDLKLDSVSKYLQSASLRHFEKAARHENPLIVAAGNYIPDPVDRMHPFRDSHCGNTRATTFATSKKSKNHTWWPKPERWPSGILVLREPDSFEEDRRKLKIEEMVLTRSEKMRSSRLDRPGNEAVSGSTSQDAQQRAVSAAPRSGVTQGPPPLAATSSQSTAPRSGVTQGPPPMAAPSSQVEKCPGVPRGSQAMPPSRQILPTQYSPASPTGPNSGVCRRVVRPPSTATPATTSGDAATESVVSASQNKKESALTANPIVHGSHITDAAAKISTTEEGSTLRDGMAPPVRGSSRKSSQQSQRLLLMARLKEEHLRAKEEQARLQAELAAARISTLEAEALVEEEEDARTTLTEDENEQSQRIDTWLSQQRSIALHGVEERVMQPTHGSPATIEQPQLELPAPIEQLKLPAPAAAPIAAPVAPKSDIAELAAAIATAARQARPGPSHRYYGELPVYSGSHQEWLSFKAAYAESADSFSAAENTARLRRTLRGRAREAVENLLLHYTEPAEIMRTLESRFGRPEAIAATELERLRALPRCTDTPRDICVFANKVNNVVAALRALDRVHYMYNPELTNITSEKLPSTLRHRWFEFSATQPAGEPDLVKLSRFLQREADLCSPYAQPEPETRVENTSGRRKMLNTPQRTHTTQAKEERKCAACQKPGHIPQDCPEFKRAAVSERWDTAKRENLCFRCLRFRSRGHVCKKKKCGVDSCERTHHELLHKKPAWQKPKEKEEAVTSTWAARSATAYLKMAPITVIGPAGEADTWALLDDGSTISLIDEDFARRVGAKGPIEPLFITAIGDNKIDATRSRRVPLKLCGRTGEPQELNLRTVNGLKLTPQRLNIEVLASCHHLTDLRHHFKTSYASPKILIGQDNWHLLVTEEMRTGRRDQPVASRTPLGWVVHGARPGGKRQRVNFVGHATTADANMDEALKQYFAIEGLTVAAKTPKNNPEERALKILRETTQQRPDGRYETALLWREESLKMPNNFEAAMNRLTSVEKKLEKDPNLKERYKQRTNALAAKGYAEVTPSTGTKKRTRYLPHFDVTHPKKQEKIRIVHDADAKNRGKKPKRLPAHRPGPAAVAARSDDALQAARRRRGHRGDNHTDRRPKRGPRRAPVLVEGGPFTRAYRIPDEVHRLRRDKRTCNRHLREEPTAVPGRRRPQAPHTRVFWTDSATIEENSTVEEWRWVPTKENVADDATRELPVGFERNHRWFIGPEYLRRHPDDWPVQRTAKRAEETGEEKCATLAVSRESLGEAIPDPRRFSKWEKASSHSMEDFRRRHASTRRDAHLATEPAGSLRGRDLTLQRGKQISPASRLRNLSVTYADGTLKINGRIGNIEGADVITSPLVLDGSRRETRLMIDFIHRKMHHAGTEATIAECRQSYWVLRLRPVTRSVIHNCLPCRIRKDTPPRPATGDHPPSRLAHHRRPFTYVGLDYFGPYQVTTGRSTQKHYVAIFTCLTTRAVHLEPAASLSTDSAVMALRRMIARRGAPTEIWSDNGTNLRGADKELRQAMDKATEHEASLRLIQWRFIPPGAPFMGGAWERMVRAVKAALSATEQPRHPTPEIFHTLLAEAEFTVNSRPLTHVSVSADDPDPLTPNHFLLGGPARVPVPSGVAGSGRADGITRVVDVRTAGGILRRPAKKIIVLPTMSAAHQGGCSDVNDAARREDVRDGHE
Summary
Uniprot
ProteinModelPortal
PDB
6AR3
E-value=0.0139289,
Score=98
Ontologies
GO
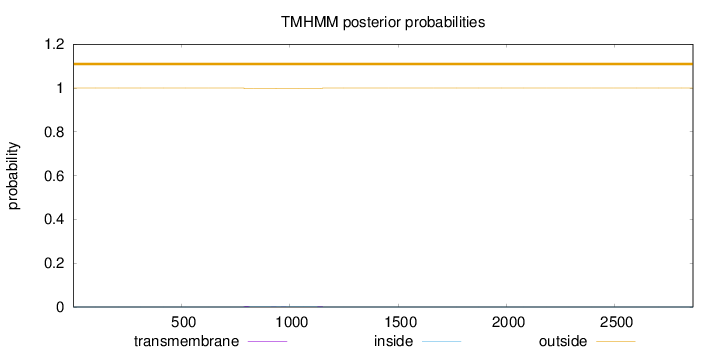
Topology
Length:
2860
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.12188
Exp number, first 60 AAs:
0.0002
Total prob of N-in:
0.00013
outside
1 - 2860
Population Genetic Test Statistics
Pi
195.732521
Theta
129.05615
Tajima's D
2.355968
CLR
0.269444
CSRT
0.931803409829508
Interpretation
Uncertain
