Gene
KWMTBOMO11982
Pre Gene Modal
BGIBMGA010729
Annotation
hypothetical_protein_AB894_15365?_partial_[Piscirickettsia_salmonis_LF-89_%3D_ATCC_VR-1361]
Location in the cell
Nuclear Reliability : 2.961
Sequence
CDS
ATGTCAAAGTCAAGTACAGGTAGAGGTAAAAATAATAAAACACGTGAACGTTCTCCGAATCCTGGACTGTACCAACAACTTCAAGCGATTGTATCTCGCCTGAATGCGTTGGAAGACAATTCAAGGTCTGGTATAGCGACTGTTGTTGAGAGGCAGCCTGCGGTGGAGTCATCGGGATCGGCGGGCAGTGCTGTGGTGCCGTGCGTGGTTCTGGCTTCTGAGCAAAGCACGACACCGCCATTGGTGCCTACGCCGGTTCCACGAGTTTCCGCTGACGATTGCGTCGCTGCCGAGGTAGCCGGTAAAATTGTAAGCGCAATTAATGAATTGAATCTGGTAAGGCCGAACCATATTTATATATCAAACTTTGATCCCGATTTAAATGACATTAATGTTTGGTGTGATGAAGTTGATCATGCACGTGTCATTTATAGGTGGACCGATAGGGAGTGCTTATCTCATATTGGTAATTGCCTTAAAGGCGATGCTCGTGTGTGGTTAAATGAATGGGTCACCAATGACCGTAGCTGGTCTAATTTTAAACGCGAGTTTAAGCCGTTGTGTCCCCGTCGGGTAGATGTTGCAAATATCCTTTTTGATGTTATGAAAACCGATTCCAACAACTATCCTACATACGCGGAATATGTTAGGCGATCTTTATTGCGTCTTCGTATAGTAAATGGACTTAGTGACGAATTAGTTTCAGCAATAGTGATCCGAGGTATCGTTGATCCACAAATTCGTGCGGCCGCTACAAACGCGAGGTTATTGCCTAACGATTTAGTTGAGTTTTTCTCCATATATGTAAAGCCTACACCTCAAACAAAAACAAATCATAATACTCGCACTGTAGCTGGTCGCTTTCATAATACACAATTCTCATCACGTAAAAGAGAGCATAGTTCTAGTAGAACCGGTTGTTACGTATGTGGATCATTTGGCCATAGACAAGTGAATTGCCCTAAGCGAACGAGAAAACGTTCGCCTACTGTGAATGATAGATTCACATCTGTACCCGCTGCCAGCTCCTCTGTGCAGAAGCCTGAACCTTGTTCTTTTTGTAAAAAGCTGGGCCATAAAGTAGAGCAGTGTTTCTTTAAGCAGCGTTCTGAAGCTCGAGGAAAATCTAACGTGAATTTTTGCCGTGATACTGTAAATGACTATAGAAAAAATGATATAGCTACTGCGATCGTACAGGGTGTACCAGTCGATATCCTGATAGATAGTGGATCCACAGTCTCGCTTATGTCTGAATCAATTGTAAAACATTTTCAATGTAAACGAGTACCCTCATTTTGCGTGTTACGAGGAATTGGTGACTGTGATACTGAATCTCGCTATTTTACTACTTTGACAGTTGAGTTTCCCGAAATCACACTAGAAATAGACTTTCAAATTGTTAGTGACAAGTTCATGAATACTCCAGTCATAATCGGTACTGACGTTTTGAATCGGGAAGGTGTCACGTATATTAGGAAAAAGGGCATACAGCGCTTAACTCGGGTAGAAAAGGTTTTTACTGCTGAGACAACTGAACTTAATTCAATCCCTACCGTGAATACTTCATTAACAGGTGAAGAAAAAAATAAATTATTAGCTTTGGTACGAAAATTTTCAAAATACCTTATAACTGGTACCGCGGCCAGTACTGTTACAACTGGATCCATGCAAATTCGACTCAGCAATGAAACTCCTATTGTTTACAGACCTTACAAATTATCATTTAGCGAAAAACTTCGCGTTAGAGAAATTATTAAAGATCTTCTTGATAAAGGTGTGATTAGGGAGTCTGAATCGGAGTTCTCGAGTCCGATATTGCTAGTTAAGAAAAAGGACGGCAGTGACAGGATGTGCGTGGACTTTCGGGCTCTTAATGCGAATACTGTGAAGGATCGCTATCCATTGCCGTTAATAGACGATCACATTGACCGGTTAGGTAGCGCAAAATATTTTACAAGCCTCGATATGGCCACTGGTTTCCACCAGATTCCTTTAGCAAACGACTCCATTCACAAAACCGGTTTTGTGACACCCGAAGGTCATTTTGAATACCTTAAAATGCCCTACGGGTTAGCCAATGCCCCGGTTGTTTATCAACGTATTATAACTAATACTCTGAAAGCCTTTAGTGAGACAGGGAGGGCTTTAATCTATATCGATGATGTTTTAATACCTAGTCAGACCATTGATGAAGGCCTAAATACTCTGCGTGAAATCTTTGAAACACTAACTAAGGCGGGCTTCTCAATTAATTTAAAAAAATGCAAGTTTCTTGCTAACGAAATTGAATATTTGGGCAGAACTATCAGCAATGGTCAGGTTAGGCCGAGTGCGTATAAAGTAGAAGCATTGACAAGAGCCCCGAAGCCTGGTAATGTTAAACAAGCTAGACAATTTTTAGGTCTAGCGGGTTATTTTCGGCGCTATATTCCTGCATATTCGTTGCAGACAGCTTGTATTTCTAATCTGTTTCGTAAAGGTGTTGAGTTTAAATGGGGTGATGAACAGGAACAAGTACGCCAGTATATAATTACGCGTTTAACCAGTGAACCTGTCCTCAATATATTTAATCCATCATTATTAACAGAAGTACACACTGATGCTTCTTCTCGAGGGTATGGAGCTGTTTTACTTCAGACTCATGGGAATAATAATAAACGCGTGGTGGGATATTTTAGTAAAGTTACCCAAGGCGCCGAACCACGCTATCACTCCTATGAGCTGGAGACACTCGCTGTGGTCAAGGCTCTGCAGCATTTCAGGCACTACCTCATAGGTATACATTTCAAGGTAGTTACAGACTGCAACGCTTTGAAGCTTACCCAACGTAAAAAAGATTTACTACCGAGAGTCGCTCGGTGGTGGATCTACTTACAAGATTATGATTTTTCGTTAGAGTATCGTAAGGGCGCTGTGCTATCTCATGCCGACTATCTAAGTCGTAATCCTATAAATGTTTGTGAAATTGGTAGACCGCATAACTGGGCACAGATAGCACAGAGTGCTGATGAAGAAACTCGGAATTTAATACAAAAGTTACAAAACGGTGAATTAGATGAGACACGCTATGTAACTAAAAATGATGTTCTTTATTATAAATTTGATTCTGTTGGCCAACCTAGTAAATTATTATGTTATATTCCAAGAGGACATCGCCTCAGTTTGTTACGAATCTTTCATGATGAGCATCATCATATTGGAGTAGATAAGACGCTTGATCTAATATTAAACCATTTTTGGTTTCCTAGTCTAAGACAATTTGTTCGTAAATATGTACGCCATTGTATAGTATGTCTTTCACACAAAAAAATACCACGTCAACCCTTGCAGCCGATCGAGTCGTGGAAGAAACCGGACGTACCCTTTGACACGGTACATAGTGATGTCTTGGGTCCTCTTCCCGAATCGAACGGTTACAAATTTGTTGTCTTGATAATTGACGCTTATAGTAAGTTCTGTCTACTAAATCCTATGCGTAAGCAGGATGCAACAGAGTTAAAATTAGTATTTGAAAACGCTGTATCTTTATTTGGTGCACCTAGGCAGATTGTAACCGATAGGGGTAGAATGTACGAAAATAGATCATTTAGACAATGGGTATCAGACGTAGGTAGTAATTTATTCTTTATAACGCCAGAGATGCACCAGAGTAACGGTCAGGCTGAGAGATATTGCAGAACAGTTCTTAATATGATTCGTGTGGAGGTAAATTTCAGAAACGAAAATTGGTCAGAAGTTTTGTGGAAACTGCAGCTCACCCTGAACGTTACGAAACAAAAGTCCACTCAATATTCACCTTTATATTTGTTAATTGGTAGCGATGCTGTGACGCCCGTCATTCGTTCCGTTGTACGCGATGTGGCTCTAGAAGGAACAAGTGCCAACAGAGAAACCTTACGCGAGCTTGCCCGACAAAGAGCTTCTCAACTGCTGGACAAAAACCGAAAACAGCAGGACACTCGAGTAAATGAACGGCGCAAACCCCCGCGTACTTTCCATGAAAACGACGTGGTCTTCGTGCATAAGAATAGCCAGTCTGTTGGAAAGCTGGATTCTGGTATGCGTGGCCCGTACAAAATAGTGCGTGCGCTGCCACATGGACGTTATGAACTGAAGCTTCTTTCTGGCTCACTTGGGAAGACCACGGAAGCTGCTGCCGAATTTATAAGTGCCTGGCACGGAGAGTGGACGCCGGATGTGTGCACCGCATTTTTCGAGTGTGATGAGAATAGCTCTGAGGAAGGTATTGTCGCCGGTCCATCACACCGCCATGACGACATAGTACCTCTAGACGGACCTATTAATGCGGGCGAGGACGCTCCGCCGTCAGGAGAGGCCGTGTTAGAAGATGATGATGACATTGGAGGCGTGGCCTAA
Protein
MSKSSTGRGKNNKTRERSPNPGLYQQLQAIVSRLNALEDNSRSGIATVVERQPAVESSGSAGSAVVPCVVLASEQSTTPPLVPTPVPRVSADDCVAAEVAGKIVSAINELNLVRPNHIYISNFDPDLNDINVWCDEVDHARVIYRWTDRECLSHIGNCLKGDARVWLNEWVTNDRSWSNFKREFKPLCPRRVDVANILFDVMKTDSNNYPTYAEYVRRSLLRLRIVNGLSDELVSAIVIRGIVDPQIRAAATNARLLPNDLVEFFSIYVKPTPQTKTNHNTRTVAGRFHNTQFSSRKREHSSSRTGCYVCGSFGHRQVNCPKRTRKRSPTVNDRFTSVPAASSSVQKPEPCSFCKKLGHKVEQCFFKQRSEARGKSNVNFCRDTVNDYRKNDIATAIVQGVPVDILIDSGSTVSLMSESIVKHFQCKRVPSFCVLRGIGDCDTESRYFTTLTVEFPEITLEIDFQIVSDKFMNTPVIIGTDVLNREGVTYIRKKGIQRLTRVEKVFTAETTELNSIPTVNTSLTGEEKNKLLALVRKFSKYLITGTAASTVTTGSMQIRLSNETPIVYRPYKLSFSEKLRVREIIKDLLDKGVIRESESEFSSPILLVKKKDGSDRMCVDFRALNANTVKDRYPLPLIDDHIDRLGSAKYFTSLDMATGFHQIPLANDSIHKTGFVTPEGHFEYLKMPYGLANAPVVYQRIITNTLKAFSETGRALIYIDDVLIPSQTIDEGLNTLREIFETLTKAGFSINLKKCKFLANEIEYLGRTISNGQVRPSAYKVEALTRAPKPGNVKQARQFLGLAGYFRRYIPAYSLQTACISNLFRKGVEFKWGDEQEQVRQYIITRLTSEPVLNIFNPSLLTEVHTDASSRGYGAVLLQTHGNNNKRVVGYFSKVTQGAEPRYHSYELETLAVVKALQHFRHYLIGIHFKVVTDCNALKLTQRKKDLLPRVARWWIYLQDYDFSLEYRKGAVLSHADYLSRNPINVCEIGRPHNWAQIAQSADEETRNLIQKLQNGELDETRYVTKNDVLYYKFDSVGQPSKLLCYIPRGHRLSLLRIFHDEHHHIGVDKTLDLILNHFWFPSLRQFVRKYVRHCIVCLSHKKIPRQPLQPIESWKKPDVPFDTVHSDVLGPLPESNGYKFVVLIIDAYSKFCLLNPMRKQDATELKLVFENAVSLFGAPRQIVTDRGRMYENRSFRQWVSDVGSNLFFITPEMHQSNGQAERYCRTVLNMIRVEVNFRNENWSEVLWKLQLTLNVTKQKSTQYSPLYLLIGSDAVTPVIRSVVRDVALEGTSANRETLRELARQRASQLLDKNRKQQDTRVNERRKPPRTFHENDVVFVHKNSQSVGKLDSGMRGPYKIVRALPHGRYELKLLSGSLGKTTEAAAEFISAWHGEWTPDVCTAFFECDENSSEEGIVAGPSHRHDDIVPLDGPINAGEDAPPSGEAVLEDDDDIGGVA
Summary
Uniprot
A0A0A9X1Z8
A0A146M2J2
B7S8P8
A0A0J7KEC9
A0A0A9WJJ8
A0A0J7K9X8
+ More
A0A0J7KLK4 J9JJ45 A0A0J7NF11 X1WPP0 A0A0J7K890 X1X5H2 A0A1Y1MFA9 A0A2S2NFQ4 A0A023EY26 A0A2H8TRV6 Q24310 A0A2S2PGQ9 W8C8Q1 J9LBS9 A0A224XHR1 J9JQ65 W8B0V9 A0A1W7R6G2 A0A023EZG2 A0A0A1XB16 A0A2S2NKJ2 A0A023EYH9 T1PMR9 X1XU14 J9JZ77 A0A034VPR8 A0A0A1XFE9 A0A2S2PFS2 A0A1W7R6L8 A0A034VLR3 X1XU22 A0A1W7R6H1 W8APB2 A0A034VKV9 A0A023EYF0 A0A0A1WKC8 A0A023F013 A0A1W7R6R7 A0A034VAM6 A0A2M4AEU2 A0A2M4CKM2
A0A0J7KLK4 J9JJ45 A0A0J7NF11 X1WPP0 A0A0J7K890 X1X5H2 A0A1Y1MFA9 A0A2S2NFQ4 A0A023EY26 A0A2H8TRV6 Q24310 A0A2S2PGQ9 W8C8Q1 J9LBS9 A0A224XHR1 J9JQ65 W8B0V9 A0A1W7R6G2 A0A023EZG2 A0A0A1XB16 A0A2S2NKJ2 A0A023EYH9 T1PMR9 X1XU14 J9JZ77 A0A034VPR8 A0A0A1XFE9 A0A2S2PFS2 A0A1W7R6L8 A0A034VLR3 X1XU22 A0A1W7R6H1 W8APB2 A0A034VKV9 A0A023EYF0 A0A0A1WKC8 A0A023F013 A0A1W7R6R7 A0A034VAM6 A0A2M4AEU2 A0A2M4CKM2
EMBL
GBHO01030786
JAG12818.1
GDHC01004980
JAQ13649.1
EF710649
ACE75273.1
+ More
LBMM01008871 KMQ88569.1 GBHO01036023 GBHO01032007 JAG07581.1 JAG11597.1 LBMM01010976 KMQ87102.1 LBMM01005919 KMQ91096.1 ABLF02008401 ABLF02008404 KMQ91095.1 ABLF02033943 ABLF02042737 LBMM01011782 KMQ86633.1 ABLF02004401 ABLF02013544 ABLF02013550 GEZM01033083 JAV84424.1 GGMR01003388 MBY16007.1 GBBI01004477 JAC14235.1 GFXV01005120 MBW16925.1 X14037 CAA32198.1 GGMR01016004 MBY28623.1 GAMC01007326 JAB99229.1 ABLF02041876 GFTR01008753 JAW07673.1 ABLF02005846 GAMC01015907 JAB90648.1 GEHC01000888 JAV46757.1 GBBI01004551 JAC14161.1 GBXI01005773 JAD08519.1 GGMR01005091 MBY17710.1 GBBI01004550 JAC14162.1 KA649989 AFP64618.1 ABLF02003120 ABLF02004015 ABLF02057179 ABLF02066208 ABLF02014660 ABLF02042774 GAKP01014483 JAC44469.1 GBXI01004632 JAD09660.1 GGMR01015682 MBY28301.1 GEHC01000930 JAV46715.1 GAKP01016237 JAC42715.1 ABLF02017401 GEHC01000876 JAV46769.1 GAMC01020207 JAB86348.1 GAKP01016235 JAC42717.1 GBBI01004549 JAC14163.1 GBXI01015151 JAC99140.1 GBBI01004613 JAC14099.1 GEHC01000880 JAV46765.1 GAKP01019383 JAC39569.1 GGFK01005990 MBW39311.1 GGFL01001689 MBW65867.1
LBMM01008871 KMQ88569.1 GBHO01036023 GBHO01032007 JAG07581.1 JAG11597.1 LBMM01010976 KMQ87102.1 LBMM01005919 KMQ91096.1 ABLF02008401 ABLF02008404 KMQ91095.1 ABLF02033943 ABLF02042737 LBMM01011782 KMQ86633.1 ABLF02004401 ABLF02013544 ABLF02013550 GEZM01033083 JAV84424.1 GGMR01003388 MBY16007.1 GBBI01004477 JAC14235.1 GFXV01005120 MBW16925.1 X14037 CAA32198.1 GGMR01016004 MBY28623.1 GAMC01007326 JAB99229.1 ABLF02041876 GFTR01008753 JAW07673.1 ABLF02005846 GAMC01015907 JAB90648.1 GEHC01000888 JAV46757.1 GBBI01004551 JAC14161.1 GBXI01005773 JAD08519.1 GGMR01005091 MBY17710.1 GBBI01004550 JAC14162.1 KA649989 AFP64618.1 ABLF02003120 ABLF02004015 ABLF02057179 ABLF02066208 ABLF02014660 ABLF02042774 GAKP01014483 JAC44469.1 GBXI01004632 JAD09660.1 GGMR01015682 MBY28301.1 GEHC01000930 JAV46715.1 GAKP01016237 JAC42715.1 ABLF02017401 GEHC01000876 JAV46769.1 GAMC01020207 JAB86348.1 GAKP01016235 JAC42717.1 GBBI01004549 JAC14163.1 GBXI01015151 JAC99140.1 GBBI01004613 JAC14099.1 GEHC01000880 JAV46765.1 GAKP01019383 JAC39569.1 GGFK01005990 MBW39311.1 GGFL01001689 MBW65867.1
Proteomes
PRIDE
Pfam
Interpro
IPR001878
Znf_CCHC
+ More
IPR012337 RNaseH-like_sf
IPR001969 Aspartic_peptidase_AS
IPR001584 Integrase_cat-core
IPR001995 Peptidase_A2_cat
IPR041577 RT_RNaseH_2
IPR000477 RT_dom
IPR018061 Retropepsins
IPR041588 Integrase_H2C2
IPR036397 RNaseH_sf
IPR021109 Peptidase_aspartic_dom_sf
IPR036875 Znf_CCHC_sf
IPR036361 SAP_dom_sf
IPR003034 SAP_dom
IPR041373 RT_RNaseH
IPR028002 Myb_DNA-bind_5
IPR005162 Retrotrans_gag_dom
IPR032071 DUF4806
IPR019103 Peptidase_aspartic_DDI1-type
IPR024650 Peptidase_A2B
IPR012337 RNaseH-like_sf
IPR001969 Aspartic_peptidase_AS
IPR001584 Integrase_cat-core
IPR001995 Peptidase_A2_cat
IPR041577 RT_RNaseH_2
IPR000477 RT_dom
IPR018061 Retropepsins
IPR041588 Integrase_H2C2
IPR036397 RNaseH_sf
IPR021109 Peptidase_aspartic_dom_sf
IPR036875 Znf_CCHC_sf
IPR036361 SAP_dom_sf
IPR003034 SAP_dom
IPR041373 RT_RNaseH
IPR028002 Myb_DNA-bind_5
IPR005162 Retrotrans_gag_dom
IPR032071 DUF4806
IPR019103 Peptidase_aspartic_DDI1-type
IPR024650 Peptidase_A2B
Gene 3D
ProteinModelPortal
A0A0A9X1Z8
A0A146M2J2
B7S8P8
A0A0J7KEC9
A0A0A9WJJ8
A0A0J7K9X8
+ More
A0A0J7KLK4 J9JJ45 A0A0J7NF11 X1WPP0 A0A0J7K890 X1X5H2 A0A1Y1MFA9 A0A2S2NFQ4 A0A023EY26 A0A2H8TRV6 Q24310 A0A2S2PGQ9 W8C8Q1 J9LBS9 A0A224XHR1 J9JQ65 W8B0V9 A0A1W7R6G2 A0A023EZG2 A0A0A1XB16 A0A2S2NKJ2 A0A023EYH9 T1PMR9 X1XU14 J9JZ77 A0A034VPR8 A0A0A1XFE9 A0A2S2PFS2 A0A1W7R6L8 A0A034VLR3 X1XU22 A0A1W7R6H1 W8APB2 A0A034VKV9 A0A023EYF0 A0A0A1WKC8 A0A023F013 A0A1W7R6R7 A0A034VAM6 A0A2M4AEU2 A0A2M4CKM2
A0A0J7KLK4 J9JJ45 A0A0J7NF11 X1WPP0 A0A0J7K890 X1X5H2 A0A1Y1MFA9 A0A2S2NFQ4 A0A023EY26 A0A2H8TRV6 Q24310 A0A2S2PGQ9 W8C8Q1 J9LBS9 A0A224XHR1 J9JQ65 W8B0V9 A0A1W7R6G2 A0A023EZG2 A0A0A1XB16 A0A2S2NKJ2 A0A023EYH9 T1PMR9 X1XU14 J9JZ77 A0A034VPR8 A0A0A1XFE9 A0A2S2PFS2 A0A1W7R6L8 A0A034VLR3 X1XU22 A0A1W7R6H1 W8APB2 A0A034VKV9 A0A023EYF0 A0A0A1WKC8 A0A023F013 A0A1W7R6R7 A0A034VAM6 A0A2M4AEU2 A0A2M4CKM2
PDB
4OL8
E-value=3.64685e-77,
Score=739
Ontologies
GO
Topology
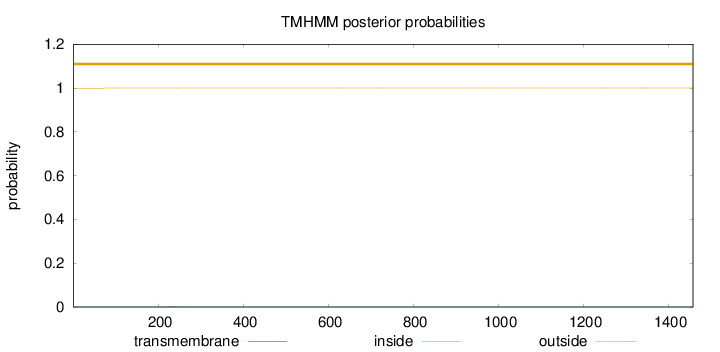
Length:
1458
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00949999999999997
Exp number, first 60 AAs:
0.00032
Total prob of N-in:
0.00039
outside
1 - 1458
Population Genetic Test Statistics
Pi
0
Theta
0
Tajima's D
0
CLR
131.419742
CSRT
0
Interpretation
Uncertain
