Gene
KWMTBOMO11868 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA004415
Annotation
PREDICTED:_uncharacterized_protein_LOC106119215_[Papilio_xuthus]
Location in the cell
Cytoplasmic Reliability : 1.829 Nuclear Reliability : 1.437
Sequence
CDS
ATGCTGAGGAGGCTCGCGGCCGCCAGGGACGAGCTCGCCAAGTTCATCAACGAATTGAACACATTTAACGTATGGATGGATGGCGCGTACCGCACGTTGGAAGACAAGGAGGCGGCTCTGTCCAAGCTGGACACGCTCTCCTCGCAAACGGACGACATCAGAGAGTTCGTGTCTGACGTCATCGCGCACCAAGCAGACCTGAGGTTCATCACCATGGCCGCGCAGAAGTTCGTCGACGAGAGCAAGGAGTTCCTGTCGATCCTGAACGAGTACCGCACGTCGCTGCCGTCGCGGCTGTCGCACGTCCCGGCGGGCGAGGAGGGCGCGGTGCGGGGCGCGGCGGGCGCGGCGCGGCGGGCGCACGGCGAGCTGGCGGCGCGGGCGCAGCGCCTGCAGGACCGCCTGCGCGCCGCCAGCGACCGCGCCGCGCACCACGCGCACGCGCTCGCCCGGGCCCAGCGCTTCCTCGACGAGGTGGAGCCCCAGGTCCGCGGCGTGCTGTCGGAGCCAGTGGGTGGGGAGCCTCGCGCTGTGGAGGCGCAGCTGTCCCGCGCCAAACATCTGCACAACGAGATCCTGGCGCAGGGACGACTCATCGACAACGCCAAGGATGCTTGTGACCAACTAGTAAAATCTCTAGAGGGTCACCTGACTCCTGCCGAGATTCGACAGTTGGAAGTGCCGGTGGTGGACCTCACTAGCCGGTACCATGACCTCTCCGAGGCTGTTGGTAGCCGATGCTCGGAACTGGAGGCCGCCCTGCTGCAGTGCCAGGGTCTGCAGGACTCCGTCGAGGCCCAGGCGCATTGGTTGGGCGAAGCCGAGGACTTGTTTAAACAGCAGCTGGGTGGCGCGTCGCTGGTGGTGGCGCGGCTGGAGGAGCAGGTCCGGGAGCAGCGGCGCGCGCACGCACAGCTGGGCGGGCGGCGCGCCACGCTGCAGGCGCTCGCGCACTGCGCCGCCGCCGAGCCCGCGCCCTCCCGCCTCGCCAAGAAGCTGGAGCAGCGCGCGCAGGACATATACGCGAGATACGAAAAGCTAGTGGAACGCTCGGCCAAACGCTCCGAATTCTTGGACGAAGTGTCGGCCGAGTTGGCCCAGTTCACCCAACAGGCCAACGTGTTGGATGCGGCGTACGGCCAACTCATCGAGCAGTCCGAGGGCCGGGAGCTGGCCAGGATGCCGGCCGACCAGCTCGGGGCTAGACTGGCCGACCTGGCCAACTATAGGGACAAACAAATGCCGCTTCTAGACGAATGTCTGCGTATGGGGAAGAGGTTGGTCGCGAAGAAAGACGTCACCGACACGCACGTTGTACTCGATAAGATGAAGGCTCTGGAGAACCAGTGGCGCGACTTCAACACGTCCTTGGAAGAGAAGCAGAAACTGTCCAGACAGCGCGCCGACCAACTCACGCAATACGAGTCTTTGAAGATACAGGTACTGGACTGGCTCCAATCGATGGAGAACAGAGTGTCTCACCTCCAGCCCGTGGCAGTCGACCTGGACGTCATCAAGCGTCAGCAGGACGAGCTGCGCCCTCTAGCGAAGGAGTACAGAGACTACTCCATAACCATAGACAAGGTGAACGAGGCCGGCGCCGCGTACGAGGCGCTGCACCGCGGCGACCGCGCCGACAGCCCGCACCGCAAGAGGCAGCTCTACAGCCCGACCAAGCGACACACGCCCAGTCGCACTTTGGATGGAAGGTCGCCTTCTCCAGGCAAGGGCTCAGTCCTCGTCAGTCCCGGATCTACTTCGAGCGGATTCTCGTCACGACGATCCAGCCAAGACGGCTTCCATCTTGAAGAACTGTCCCCGGTCCAGCAGCAACTGTCGGAGATCAACAACCGGTACAGTCTGCTGGGCACGAAGCTGTCGGACCGCCACACGGAGCTGGAGGCCATCAGGGAGGAGATCAAGAAGCACTTGGAGAGCTTCAGGACTTTGAACGCGTTCTTGGACAAGGTGCAGAGACAATTGCCTAAGGACACAGTCCCCAACAACAAGGAGGAGGCTGATAAGATCATAAAACAAGCTCGCGCCGTCCTCGAAGAGATGTACGAGAAACAGAGCATCCTCGACTCCACCAAGACACAGGTACGAGAACTTCTGAAGCGCAAACAGAGCGTGCAGGGGGCTGACCGTCTGCACGACGAGATGGAAGACGTCGCCTCCAGGTGGAAGGCTCTTCACGACGGCTTGAAAGACAAGATAAGACTGATGGAGGAGATGAAAGACTTCTTGGACACACACTCGAACCTGTCCCAGTGGCTCAACGCCAAGGAGCGCATGATGGCGGCCCTGGGACCCATCTCCACCGACTCCAGCATGGTGCACACGCAAGTACAGCAGGTGCAGGTCCTCCGCGAAGAGTTCCGCAGCCAGCAGCCGCAGCTGACTCACCTGGAGGAGGTGGGCAGCGCCGTGCTGTCCCGGCTGCCCCCCCACTCCGCGGACGCGCGTGCCCTCCAGGGACAACTGCATGACGTCACGCATCGCTGGGACGATCTGCTAGCCAAGCTGGCGGCGCGCGCGGAGAGCCTGGGCACGGCGGCGGACACGGCGCGCGAGTTCGACGCGGGGCTGGCGCGGCTGCGGGGCGCGCTCGCCGCCATCAGCGACAAGCTGGACGAGCTCGCGCCCGACCACGAGCCCGACGAGCAGCTGCGCAAGATCGAGCACTTGGAGCGCCAGCTGGAGGGGCAGCGGCCGCTGCTGGCGGGGCTGGAGGTGTCGGGCGCGGCGCTGGCGGGCGTGTGCGAGGCCGCCGCGGCGCAGCACGTGGGCGCGCGCCTGGCCGCCGCCGCCCGACACCTCGACACCCTGCAGCGGAAGCTGGACCACAGGAAGGCCGAGCTCGAAGCCGCGCTCAAGGACGGCCGCAATCTCGAAGAGAACGTCGCCCGAACCCTCGGCTGGCTCCAGTCCGAGCTGGGCTCGCTGCCGAGCCGCCTCCAAGTGTCCGCGGACATCAACAAACTGCAACAACAGATACAGAAACACGAGCCCCTCTACAGAGATCTCACTCAACGGGAACACGAAATTATTATGTTGATTGATAAGGGCCGTGAAATGGAAAAGAAACCTTCTCACCAGAACTTAAGGAAGGATCTCGATCGTATACAAGCTCAGTGGGACAAGCTGAAGCGAGAGATTGTCGACAGAAACACAAGACTACACACCGCCATGGAACATTGCCGTAAGTTCCACAAGTGCCAAGAGTCGTTCTTGCCGTGGCTGGCAGACACAGAGGAACGCATCGCCAAGCTTCCTCCGCCGGCATTCTCCAAGAAGGAAGTTGAGAAACAACTTAGAGAACTGCAACACATCCGAAACGACATATGGAAAAGGGCCGGAGAGTTCGAGAACAACAAAACTCTCGGTGAGACTTTCATTTCGTCGTGTGACGTCGACCAAGACGTGGTCCGAACGCAAATCGACAGCATGAAGGAAAGATGGGACAAGATAAACAACGAGGTTCTCCAGCAAGTGGAGTTCCTGGAGACGACGAGCCGCATGCTGGGCGAGGTGCTGGAGAAGAGCCGCGGCGTGGAGACTCCGCTGCAGCGCTGCGAGGAGCGGCTACGGGACGCGCACGCCGCGCCGCCCGCGCTCGCCGCGCCCGCACTCGCCGCGCTCGCCGACCATCTGCAGGCCCTGTGCGCGCCGCTGCAGAGCGTGGAGGTGGCAGTAGATGACATAGTGACGATGGCGGAGGAGCGGCTGGGCCCCGAGGGCGGAGCCCGGGCCCGCGCGGCGCTGGAGGAGGGCCCGCGCGCCCTGGCCGAGCGGCTGCACCGGCTGCAGGACCAGGCCGACCTCGCACGCACCAGGCTCGCGGGCGCCACCGCCGCGCTCACTCACTTCCAGGACAAAGTGAAGAGTCTATCGCACGACCTATCGGACCTGGACAAGGAGTTGGACTCGATGAAGCCGCCGGGGCGCGACCTCAAGACCGTGAAGCAGCAGCTGGAGGACGTGGCGCGCTTCTACAAGCGGCTGGAGGGCGCCGACGACCTCATCGCGCAGGCGGAGCGCGCCGCCGAGGGGCTCGCCGACAGCGGCTACACCGCAGACTCCGCCAAGACCAGGGACCAGGTGGAAGGGCTCCGTAAGCAACTGGCCAAGCTGGACGAGAGGGCTCGCTCTAAGGAGCAGGACCTCGATGACACCCTCAGCAAACTGGAAGCCTTCTATAAGGCTTACGACTCGGTCATGGATGACGTACAAGAGGCTTCGGAACAAATGAGAAGTCTGAAGCCGGTGTCGTCGGAAGTCGACCAGATCCGCGCCCAGCAGAAGGACTTCGCCGAACTAAAGCGTCACACGTTCGAGCCCCTGGGACAGAACGTGACTCACTGCAACAAGATCGGGCAGGGGCTGGTCAGGTCCGCTCTGCAGGGAGCCAACACTCAGCTGCTAGAGAAGGACCTCGAGAAGATGAACGACAAATGGAACGCTCTGAAGGAAAAGATGAACGAACGCGAGCGGCGCCTGGACGTGGGGCTGCTGCAGTCCGGCAAGTTCGCTGAGGCGCTGGCCGGCCTGGACAAGTGGCTCGCCGACACCGAGGACATGGTGCGCAACCAGAAGCCGCCCTCGGCCGACTACAAGGTCGTCAAGGCGCAGCTACAGGAGCAGAAGTTCCTGAAGAAGATGTTGATGGACCGTCAAAACTCTATGTCGTCTCTGTTCGCGATGGGCAACGAGGTGGCTGCCGGCTGCGAGCCTCAGGAGAGAAAGGCCATCGAGAAACAACTCAAGGGCCTGGTGCAGAGGTTCGACGACCTCACCACCTCCGCACAACAGAGGATGCTGGATCTGGAACAGGCTATGAAGGTAGCAAAGCAATTCCAAGAGGAGCTGCAGCCCCTGGTCGAGTGGCTGGGAGTGTCAGAACGTAAAGTCAAGTCCTTGGAACTGGTGCCCACTGATGAGGAAAAAATACAGCAGAAGATCAGAGAGCATAAGGCCCTCCACGACGACATCCTGTCGAAGCAGCCGGCGTTCAAGCAGCTGACGGAGACAGCCTCGACCCTGATGGGGCTGGTCGGGGACGACGAGGCCACCGCGCTGGCCGACAGGCTGCAGGCCGCCACCGACAGATACCAAACTCTGGTGGATCATAATTTGAACGTAGGCGATCTGTTGGAGAGCTCTCGCAAGGGGCTGCGGCACCTGGTGCTCACGTACCAGGACCTGTCCGCCTGGATGGACGGCATGGAGCAGTACCTCGCCAAGAGGAAGCTGCTCCCGGTCCATATGGAGAAACTGCTCCGGCAAATGGACGAATTGGCTGAGAAAACGGAAGAAATAGCCGTGAAGCAAGAAGCAGTCGACAGCACCGTGGACTCGGGCCTCGAGCTCATGAAGCACATCTCCGGAGACGAAGCCCTGCAGCTCAAGGACAAGCTGGACGCCCTGCAGCGCCGGTACAACGACCTCACCAGCCGCGGGGCCGACCTGCTCAGGGTGGCCTCCGAGACCCTGCCCCTCGTGCAGCAGTTCTACAACAGTCATGCCAAACTAACGGAATGGATGACGAGCGCGGAGACGTGCCTGCAGTCGGTGGAGCCCCGCGAGGAAGACATCCTGCGGCTGGAGGTGGAGCTGCAGGAGTTCAGGCCGGTGCTGGACACCATCAACTCCGTCGGACCGCAGCTCTGTCAGATATCGCCCGGAGAGGGCGCCACTCACATCGAAGGAATCGTGACCCGCGACAACAGGAGGTTCGACGCCATCGCCGAGCAGGTGCAGAGGAAGGCCGAGAGGCTGCTGCTCAGCAAGAAGCGTTCCCTGGAGGTGGTGGGCGACATGGAGGAGCTGGTGGAGTGGCTGCGCGGCGTGGAGGCGCGCCTGCGGTCCGCCGCGCCGCCCTCGTGCGAGCCCGCCGCCGTGCGCGCGCAGCTGCGCGACCAGCGCCCGCTGCACGACGAGCTGGCGGCGCAGCGCGTGCGCTGTCGGGACCTGCTCGCACAGGCCAAGAAGGTACGCGCAAACACTATACCACACGACCAATACAAACCTACATCTGTACTTTATATAAGAGTCTTTATATAA
Protein
MLRRLAAARDELAKFINELNTFNVWMDGAYRTLEDKEAALSKLDTLSSQTDDIREFVSDVIAHQADLRFITMAAQKFVDESKEFLSILNEYRTSLPSRLSHVPAGEEGAVRGAAGAARRAHGELAARAQRLQDRLRAASDRAAHHAHALARAQRFLDEVEPQVRGVLSEPVGGEPRAVEAQLSRAKHLHNEILAQGRLIDNAKDACDQLVKSLEGHLTPAEIRQLEVPVVDLTSRYHDLSEAVGSRCSELEAALLQCQGLQDSVEAQAHWLGEAEDLFKQQLGGASLVVARLEEQVREQRRAHAQLGGRRATLQALAHCAAAEPAPSRLAKKLEQRAQDIYARYEKLVERSAKRSEFLDEVSAELAQFTQQANVLDAAYGQLIEQSEGRELARMPADQLGARLADLANYRDKQMPLLDECLRMGKRLVAKKDVTDTHVVLDKMKALENQWRDFNTSLEEKQKLSRQRADQLTQYESLKIQVLDWLQSMENRVSHLQPVAVDLDVIKRQQDELRPLAKEYRDYSITIDKVNEAGAAYEALHRGDRADSPHRKRQLYSPTKRHTPSRTLDGRSPSPGKGSVLVSPGSTSSGFSSRRSSQDGFHLEELSPVQQQLSEINNRYSLLGTKLSDRHTELEAIREEIKKHLESFRTLNAFLDKVQRQLPKDTVPNNKEEADKIIKQARAVLEEMYEKQSILDSTKTQVRELLKRKQSVQGADRLHDEMEDVASRWKALHDGLKDKIRLMEEMKDFLDTHSNLSQWLNAKERMMAALGPISTDSSMVHTQVQQVQVLREEFRSQQPQLTHLEEVGSAVLSRLPPHSADARALQGQLHDVTHRWDDLLAKLAARAESLGTAADTAREFDAGLARLRGALAAISDKLDELAPDHEPDEQLRKIEHLERQLEGQRPLLAGLEVSGAALAGVCEAAAAQHVGARLAAAARHLDTLQRKLDHRKAELEAALKDGRNLEENVARTLGWLQSELGSLPSRLQVSADINKLQQQIQKHEPLYRDLTQREHEIIMLIDKGREMEKKPSHQNLRKDLDRIQAQWDKLKREIVDRNTRLHTAMEHCRKFHKCQESFLPWLADTEERIAKLPPPAFSKKEVEKQLRELQHIRNDIWKRAGEFENNKTLGETFISSCDVDQDVVRTQIDSMKERWDKINNEVLQQVEFLETTSRMLGEVLEKSRGVETPLQRCEERLRDAHAAPPALAAPALAALADHLQALCAPLQSVEVAVDDIVTMAEERLGPEGGARARAALEEGPRALAERLHRLQDQADLARTRLAGATAALTHFQDKVKSLSHDLSDLDKELDSMKPPGRDLKTVKQQLEDVARFYKRLEGADDLIAQAERAAEGLADSGYTADSAKTRDQVEGLRKQLAKLDERARSKEQDLDDTLSKLEAFYKAYDSVMDDVQEASEQMRSLKPVSSEVDQIRAQQKDFAELKRHTFEPLGQNVTHCNKIGQGLVRSALQGANTQLLEKDLEKMNDKWNALKEKMNERERRLDVGLLQSGKFAEALAGLDKWLADTEDMVRNQKPPSADYKVVKAQLQEQKFLKKMLMDRQNSMSSLFAMGNEVAAGCEPQERKAIEKQLKGLVQRFDDLTTSAQQRMLDLEQAMKVAKQFQEELQPLVEWLGVSERKVKSLELVPTDEEKIQQKIREHKALHDDILSKQPAFKQLTETASTLMGLVGDDEATALADRLQAATDRYQTLVDHNLNVGDLLESSRKGLRHLVLTYQDLSAWMDGMEQYLAKRKLLPVHMEKLLRQMDELAEKTEEIAVKQEAVDSTVDSGLELMKHISGDEALQLKDKLDALQRRYNDLTSRGADLLRVASETLPLVQQFYNSHAKLTEWMTSAETCLQSVEPREEDILRLEVELQEFRPVLDTINSVGPQLCQISPGEGATHIEGIVTRDNRRFDAIAEQVQRKAERLLLSKKRSLEVVGDMEELVEWLRGVEARLRSAAPPSCEPAAVRAQLRDQRPLHDELAAQRVRCRDLLAQAKKVRANTIPHDQYKPTSVLYIRVFI
Summary
Uniprot
EMBL
Proteomes
Pfam
Interpro
IPR002017
Spectrin_repeat
+ More
IPR003108 GAR_dom
IPR002048 EF_hand_dom
IPR011992 EF-hand-dom_pair
IPR001101 Plectin_repeat
IPR029926 Dystonin-like
IPR018159 Spectrin/alpha-actinin
IPR035915 Plakin_repeat_sf
IPR036534 GAR_dom_sf
IPR041615 Desmoplakin_SH3
IPR036872 CH_dom_sf
IPR001715 CH-domain
IPR018247 EF_Hand_1_Ca_BS
IPR003108 GAR_dom
IPR002048 EF_hand_dom
IPR011992 EF-hand-dom_pair
IPR001101 Plectin_repeat
IPR029926 Dystonin-like
IPR018159 Spectrin/alpha-actinin
IPR035915 Plakin_repeat_sf
IPR036534 GAR_dom_sf
IPR041615 Desmoplakin_SH3
IPR036872 CH_dom_sf
IPR001715 CH-domain
IPR018247 EF_Hand_1_Ca_BS
Gene 3D
ProteinModelPortal
Ontologies
GO
PANTHER
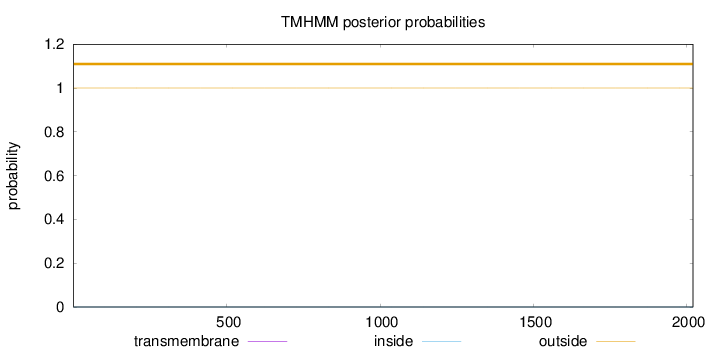
Topology
Length:
2020
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00057
Exp number, first 60 AAs:
0.00057
Total prob of N-in:
0.00003
outside
1 - 2020
Population Genetic Test Statistics
Pi
215.262898
Theta
171.20609
Tajima's D
0.336735
CLR
0.087197
CSRT
0.464976751162442
Interpretation
Uncertain
