Gene
KWMTBOMO11783
Annotation
ORF_B_(bases_1850-5560)_first_start_codon_at_2306_[Autographa_californica_nucleopolyhedrovirus]
Location in the cell
Nuclear Reliability : 3.803
Sequence
CDS
ATGTTAGCCCTAAGCCCACTACCGTCACAGTTGATAGAAAACAGTCAAAAGTACGAAATTAACAAAATTGAGACGGAATCTGACATAGATAAAGAACTTTGTGAAAATTTAAAGAAAATTCGTACCAGCCACATGAACGAGGAAGAAAAACGGGAAATTACCAAAATCTGCTATCAGTACCGTGACATATTCTACTCGGAAAACATTCCTTTATCGTTTACCCATACAGTAAAACACGAATTAAGACTAACCGACGACACCCCCATCTTTGTACGGAGTTATAGACAGGCTCCCCAACAACGAACAGAGATACAAAAACAGGTAGATAGTCTATTAAAACAAGGAATCATTAGGGAAAGTATCTCCCCTTGGTCGTGCCCGGTACACATTGTTCCGAAAAAACCGGATGCATCAGGAAAAGTTAAATGGAGACTTGTTATTGACTATAGAAGACTTAATGACAGAATTATAGAAGACAAGTACCCCTTACCAAACATTAACGACATCCTTGACAGATTAGGGCGCGCACAATATTTCACGACCATAGATTTAGCAAGCGGCTACCATCAATTAGAAATGCACCCTAAAGACGTAGAGAAAACAGCGTTTACTACTGAAAGAGGCCACTATGAGTTCCTAAGAATGCCTTTCGGACTAAAAAATGCCCCGAGCACTTTCCAGCGTCTTATGGACCATATACTCCGAGGTATAGACAACGTATTTATGTACTTAGATTACGTCATAATAGCCGCGACGTCCCTACAAAACCACAATGAAAAACTGAAATTAGTATTTCAGCGATTCAAAATGCATAATCTGAAAGTTCAGTTAGACAAATCAGAATTTCTACAGAAGCACGTTAACTTTCTAGGACATGAATTGACTGACCAAGGACTAAATCCTAACAAGGACAAAATTAAAGCAGTATTAAATTTCCCTATACCACAAACGCAAAAAGACATAAAAGCTTTCTTAGGCCTAGTCGGGTACTATAGGAAGTTTATTAAGGACTTCGCGAAGTTGACGAAACCTTTAACAGCATGTCTAAAAAAGAACGCAAAGGTTGAACATACAAACGAATTTTTAGACGCAGTTGATAAATGCAAACAAATTCTAACAAACGCCCCAATCCTGCAATACCCTGACTTCGACAAACCGTTTATTTTAACGACAGACGCATCTGACTTTGCTTTAGGAGCAGTACTTTCCCAAGGCAATGTGGGCTCAGATAAACCAGTAGCCTATGCCTCAAGGACATTATCAGATACTGAGATCCGTTACTCTACCATAGAGAAAGAACTGTTAGGGATAGTATGGGCAATTAAGTATTTTAGACCTTACTTATATGGCCGTAAATTTACAATTTATACGGACCATAGACCCCTTACATGGTTAATGAGTCTAAAGGACCCTAACTCTAAATTAACACGATGGAAACTAAAGTTAGCAGAGTATGATTACAAAGTTGTTTATAAAAAGGGCAAACAAAACACTAACGCAGATGCACTATCTCGAGCAAAAATTTTTCATAATAGTATAGATTCTCTAGCTGTTAATGTTGATGACAATAGTGACGACAACATAATAAATAGAATATTCGAAAACGCCCGTAGACAGGCAGAGGTAGAAACTGATGACCCGAATAACCAAGACAATGAACGTAACAATACTGACAATGACGACCAACCTTATAACAACAATGACGTAGAAATGACCAGTATCTATCCCTCTCAAATTGACGAAGAGACAGACACAAGGAGTGCAACAACAGTCGACCCCGATCAATTAGTTTCTACAAATCATACCCAACCTGATAATGAAAATAACGGTATCCCTATAATATCCGACGCTATTGATAGACAGTTGAAACAATTTTACGTTAGGTCCACACCAGGCTATACACCACGTGAGCTTTTATTCGGTCATACGGCATCCCGAAATCCATTAGAGCTATATTATCCTAAAGAATTTTATCAAGATTATGTCCTCAATCACCGCAAGAATGCAGAAGCAGTACAGGAATGTATAGCAGCCCACGTGTCTAAGAACAAAGAGCAGGTAATAGAAAAGAGAAACCAGGCAGCGGAAACAATCACGTTTAAGACCACATCTTGTTCCAGGGCCCTCATCGCAGGAGCCTTCGTACTCTACACAGCCGCCGACTTGACCCTTAATCCTATAGACAATACTAATGGCATCCTTTTGTTAAAACAAGGACAAATTTTGAAGCAGATAGACACTTTTAGTCTGGCCTGCGTATATAACGTATCGTATTTACATGAAACAACCTTAAAGCTTATGTCTTTATATGCCAGTACTAAAGCTGCTGAAGGTAACGAAGAGTTGCATAGAGCATATAAGGATCAAATAGAAAATAGTTTACATTTAATAGGGAAGAAGTTAGCATTTATTGCACCGCACCATAGATTTAGACGTGGCTTAATTAACGGTTTAGGTTCAGTAGTTAAAACTATTACAGGTAATCTGGATTATGAAGACGCTATTAAGTTTGAAAATGAATTATCTAATCTACGTAATTCAGTCCATAATATTAACACATCTCAAAAACAAACTTTATTCATAGCAAAGCACGCAGTTGAAGAATTTAGTAAACAGATCAAGTTATTAGACGAAAATCAGAAAAAGATAGGTTCAATGTTAAAAAACGCCACTTTAAGTAATAACGTAGTAATAAGCAGATTGCACTTTTTAGATTTATATATCCAAATATATTTTAGTTTGCAATTACTCTTAGATAAATTAGTTATATTAGAAGACGCCATGACCTTTGCACAACTAGAAGTAATGCATCCTAGCATTATAGCTCCACACAGTCTTATAAGTGAAATAACAGCTATTCAAAGACTTTACCAATTTAGACCCGTTGATAGAATAAGTATTAAAAATATTCATAGTATAGAGAGCTCTATTAGCGTAAAAGCGTATAGCACAAACGACGCACTAACATTCATACTAGATATCCCTTCCATAGATGAAAACCTTTATGACCTTATCCATCTATACTCCATACCAGATAAACAAAACCTCACCATTATTCCTAAATCCAAATACCTAGCACTGGGAACCAACGAGTACTCATACCTGGAGGAAGATTGCAAGAAGATCACACAAGACGTCCAACTCTGCACATCGCTGAACACCCAACCTGTGGAGAACTCTGAAGACTGCATAGTAACTCTTATAAAACACGAGAGCACAAACTGCACCCGTGCCAGGATGAACCTGAAACAAGGCAAGATCCAGAGACTAGAAGACAACAAATGGCTTATCATCTTGAAAGACGAACAAATCCTGAAATCTCGCTGCGGAAGGAAATCTGACTATAAAAAGTTGTCAGGAATATACATCGCCAGCATTACAAGCGATTGTCAAGTGGAAATATTCAACCGAACACTGAAGACAAACACGGACACTATTACAGCAGATGAAATCGTACCCATTCCCAGCGAAACCACTATTCTAGAAGGGAATATTCGCTATAACCTACAACTGAAAGATATATCTCTGGATAGCATCCATGAACTGATGGACCGGGTTGAAAACATTCAACAACCTGTCATCGACTGGCAGACTATGATGACTACCCCAAGTTGGTCAACACTGGGACTCTACCTCATTCTGATAGCAATAATCATCTGGAAGCTGTGGCAGTGGAGACAGCGACGACTACAATCAAAGAACGAGAGCCCCGAGAACACTAGCACCGAGGACGCTGCTGGAAGCTGCGGGACGCGCTTCTATCTTAAGGAGGGAGGAGTTAGGCAATCGCCCGATGCCCGTATTTGCTGA
Protein
MLALSPLPSQLIENSQKYEINKIETESDIDKELCENLKKIRTSHMNEEEKREITKICYQYRDIFYSENIPLSFTHTVKHELRLTDDTPIFVRSYRQAPQQRTEIQKQVDSLLKQGIIRESISPWSCPVHIVPKKPDASGKVKWRLVIDYRRLNDRIIEDKYPLPNINDILDRLGRAQYFTTIDLASGYHQLEMHPKDVEKTAFTTERGHYEFLRMPFGLKNAPSTFQRLMDHILRGIDNVFMYLDYVIIAATSLQNHNEKLKLVFQRFKMHNLKVQLDKSEFLQKHVNFLGHELTDQGLNPNKDKIKAVLNFPIPQTQKDIKAFLGLVGYYRKFIKDFAKLTKPLTACLKKNAKVEHTNEFLDAVDKCKQILTNAPILQYPDFDKPFILTTDASDFALGAVLSQGNVGSDKPVAYASRTLSDTEIRYSTIEKELLGIVWAIKYFRPYLYGRKFTIYTDHRPLTWLMSLKDPNSKLTRWKLKLAEYDYKVVYKKGKQNTNADALSRAKIFHNSIDSLAVNVDDNSDDNIINRIFENARRQAEVETDDPNNQDNERNNTDNDDQPYNNNDVEMTSIYPSQIDEETDTRSATTVDPDQLVSTNHTQPDNENNGIPIISDAIDRQLKQFYVRSTPGYTPRELLFGHTASRNPLELYYPKEFYQDYVLNHRKNAEAVQECIAAHVSKNKEQVIEKRNQAAETITFKTTSCSRALIAGAFVLYTAADLTLNPIDNTNGILLLKQGQILKQIDTFSLACVYNVSYLHETTLKLMSLYASTKAAEGNEELHRAYKDQIENSLHLIGKKLAFIAPHHRFRRGLINGLGSVVKTITGNLDYEDAIKFENELSNLRNSVHNINTSQKQTLFIAKHAVEEFSKQIKLLDENQKKIGSMLKNATLSNNVVISRLHFLDLYIQIYFSLQLLLDKLVILEDAMTFAQLEVMHPSIIAPHSLISEITAIQRLYQFRPVDRISIKNIHSIESSISVKAYSTNDALTFILDIPSIDENLYDLIHLYSIPDKQNLTIIPKSKYLALGTNEYSYLEEDCKKITQDVQLCTSLNTQPVENSEDCIVTLIKHESTNCTRARMNLKQGKIQRLEDNKWLIILKDEQILKSRCGRKSDYKKLSGIYIASITSDCQVEIFNRTLKTNTDTITADEIVPIPSETTILEGNIRYNLQLKDISLDSIHELMDRVENIQQPVIDWQTMMTTPSWSTLGLYLILIAIIIWKLWQWRQRRLQSKNESPENTSTEDAAGSCGTRFYLKEGGVRQSPDARIC
Summary
Uniprot
ProteinModelPortal
PDB
4OL8
E-value=9.82302e-77,
Score=735
Ontologies
KEGG
GO
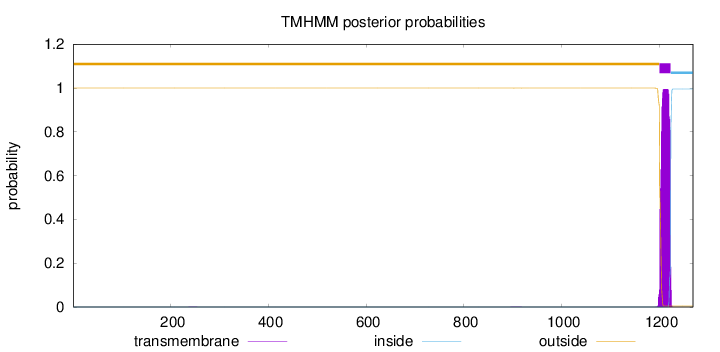
Topology
Length:
1269
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
21.1885
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00015
outside
1 - 1200
TMhelix
1201 - 1223
inside
1224 - 1269
Population Genetic Test Statistics
Pi
11.676493
Theta
17.209397
Tajima's D
-0.972153
CLR
16.811669
CSRT
0.139643017849108
Interpretation
Uncertain
