Gene
KWMTBOMO11629
Pre Gene Modal
BGIBMGA004118
Annotation
voltage-dependent_cation_channel_SC1_[Bombyx_mori]
Full name
Sodium channel protein
Location in the cell
PlasmaMembrane Reliability : 4.063
Sequence
CDS
ATGGATATATACATATTCCTGGCGATCTACACGGCGGAGATGATAATCAAATGCATAGCCAAGGGCTTTATCCTGAACAAGTACACTTACCTTAGGAACCCGTGGAACTGGCTGGACTTCGTCGTGATCACATCAGGGTACGCCACAATCGGTATGGAAGTGGGAAATTTGGCCGGCCTTAGGACCTTCAGAGTGTTGAGAGCACTAAAGACTGTCTCTATTATGCCAGGATTGAAAACCATCATCAACGCGCTTCTGCATTCGTTCAAGCAGCTAGCAGAGGTAATGACCCTGACAATATTCTGCCTCATGGTGTTCGCCTTGTTCGCGCTCCAGGTATACATGGGCGAACTTAGAAACAAATGCGTCAAGAACTTGGTTATGCAGCCGGGAGAGAACTTTACTGACGAAATCTGGTCGGCGTGGATCAAAGAACCTACAAACTGGATGGTAGATGAAGAACTAGTTCCAATTATTTGCGGGAACTTGACAGGGGCCAGGCATTGTCCGTTACATTACACCTGCCTTTGCGTGGGCCCAAATCCCAACCATGGGTACACTAATTTCGACAATTTCCTCTGGTCAATGTTGACCACCTTCCAGTTGATCACGCTTGACTACTGGGAGAATGTTTATAACATGGTACTGTCTTCGTGTGGTCCAATGTCCGTATCATTTTTCACGGTGGTGGTTTTTTTTGGCTCGTTTTACCTCATCAACCTGATGCTGGCCGTAGTCGCACTGAGCTATGAAGAGGAATCACAGATCACACAAGAAGAGAGAAAGAAGGATCTGAACGAGCACAGAGATGATTCTACATTCAGCTTTGATCCCTCATCGCTGGCTGTGAGGACCCTCGCTAAGGACTCGAAGAAACGAATCGACGCTAGGAAAGGACTATTATTAGCCTCTTACTCACGCAAAAGAACAAGAAGACGCAAAAGAGGCAGGAGTGCTATACATCATGCTGCTGCGGTTGCCGCCGTGGCTGAACGGTCGAGATCCAGGTCGGTGACCCCGAGCGCGTCACCGCCACCTTTGCCGCCGCCGCCGCCTCCACCGCCGCCCCCTCACACCCTCCACCCCGACAATGCATTAGGTCGTGGCATCCTGAGTGCAGCTGGTCGTCAACTGAGCGATCACAGTAACAACAGGGAATCATCGCTCGACGACTCCGGCGTGGTCGATGACCACGACGACGGAGAACACACGTCTGATGACCAGGCCCCTCACCCTCACCCGAGGCGGGTACTGCTAATGCCGCCACCATTGCCTGCTTTGCAGCAATCAACACCAATGCCACCTTTACAACAAACACAGGAGAGTCACACAGAAGAACCAAAACAGAAAGCCAAACTGAGAATCCGAGAAGAGAAACCAATAGAGAAAGTAAAGAAAGGCGATAAGCAGAAAGAAACCGTGTACGAAAGATATCCATTGAATCCGGACTACCTCAATCAGATCGTCGTTTTAGGGGCGGACTGGCCATACGAGCGTGCGCCCGCCCTCCCGCAAGCGGAAACGACGAAAATTAATGAGATCGGTTTATTGGCAGCAAAGCACAAAACTCATATGGGCAATTACGAGCAAAATTGCACTTACTTCACAGATGAGCTCGTGGATAGAAACTGCGAGTGTTGCGTGTCTTGCTGCATAGACTACGAAGGTTGGCTTCAATTCCAAAACTGTCTTTACGGGATCGTGAAGGATCCTCTATTCGAGTTGTTCATTACGACTTGTATCGTTTTAAACACACTGTTTTTGGCTCTAGAGCATCACGGCATGAGCGAGAACGTTAGAAGGGTCTTAGATATAGGAAATAAGGTTTTCACTTCTATATTTACTTTAGAGTGTATAATGAAAGTGATGGCGATGAGTAAAGACTTTTTTGCTTGCGGATGGAATATATTCGATCTAATCATAGTTTCGGCTAGCTTACTCGATCTCATATTTGAATTAGTGGACGGCTTGTCTGTGCTACGTGGCCTGCGTTTGTTGAGAGTGTTAAAGTTAGCCCAGTCGTGGACTACGATGAAAGTGTTGTTGAGTATTATAATATCGACTATAGGTGCTCTTGGTAATTTGACGTTCGTATTAGTGATAGTTATATACATATTTGCGGTAATCGGTATGCAGCTGTTTTCTAAATCGTACACCCCTGATAAGTTCGATCCAGATCCAGTACCCAGATGGAACTTTAATGATTTCTTCCATTCGTTCATGATGATATTTCGGATACTGTGCGGTGAATGGATCGAGCCCCTGTGGGACTGTATGAGAGCCGAGCAAGCCAGTGGCGCAGAGAGCTGTTTCTTCATATTCTTACCGGCTCTCGTAATGGGAAATTTCATGGTGCTCAATCTCTTCCTTGCCTTGCTGCTCAACAGCTTTAACAGTGAAGAACTTAAAAATAAAAAAGAGGAAGTGGGCGAAGATTCAAAATTAGCTAAAAGCTTCGATAGAATACGTTCTATAGTAAGGAAGAAAGGTTTTCTTATATCTAGAAGTAAAGAGACTGAAAAAAAATCGAAATTAGAGGAGCTAGTTAACGAATTCATGTCACAGCAACGAGCTATTAAAGAGAAGAAAGCGTCAATACCGACCGAGCAGCGTTACTCCGCCTCAATACAGGAGACCATACTCTTTCCGCATGACAATATCTATAGCCATAGCTACCAAGAGGCCGTAAACAGGCCAATTTCTGTTGGTTCAGAATTCGCATACCCGCAACTGTATCAGAGCTGCAGCAACATTAACCACGGCAGTCAAGAGACGTTGAAAGACGTACGAGACTTGGCAACCGAACATAAGATAACAAGCATTAGGGAAGATTCCAAAGAAAATCTAGAAGATACGTCGCCGTTCGAACAAAAATCAGCGCAAAAACTACTAAATCAAATATCTTCTGGATATTACACACAGCCATCGGATTCGAGAGACGAAGAGAACGAACATTATGAAATGGCACAGTTCTCTTGTAAAACAACACCGGAGAAAACTAAGAAGCAAGGTAGAGACCCGCCAAACACGTTATCTAAAGATCCGAATAAAAAGCCCGACGAGGACGACATGAAACATCCGTGGCAAACATTAGTTTCTTATGTGGATGAATTGACCGTAGGGGGGCGGAAGAACTCTAAAGGCCAGTACATCGATGCGATGGGAAATTTTCCGGGATTCGGGAAACAGAAGGAACCAAAAGTGCCCCAGGATTGCTTCCCGAGTCAATGTTACGATATAAGCTCGTGTTGGGACACGTGTATAGACACAAAAATTGGCCAACGTTGGATGTTGGTTCGAACATTTGTTTTACGTTATGTCGACACGCCCGCATTCGAATGGTTCGTTCTGGTCCTGATATTTGCTTCGAGCATCACGCTGTGCTTCGAAGACATTCACCTAGAAAAGAACAAACCATTAAAGAAGATATTGTACTGGACCAATTTGGGATTCTGTATGATATTCATAATAGAAATGTTTCTCAAATGGATAGCTTTAGGATTCTTCAGATACTTCACTAGCTTTTGGACGTTGTTAGATTTTACTATAGTATTCGTTTCTGTATTTAGTTTGTTGATAGAAGAGAATGAAAATTTGAAAGTTTTGAGGTCGTTACGGACTTTACGCGCTTTGAGGCCGCTTCGGGCGATCTCGAGGTGGCAGGGTATGCGTATAGTCGTGAACGCCCTGATGTACGCGATACCCAGCATTTTCAACGTTCTGCTAGTTTGTTTAGTGTTTTGGTTGATATTCTCTATAATGGGAGTACAGTTTTTCGGAGGAAAATTCTTCAAGTGCGTTAATGAAGAAGGAGAATTATTACCTTTAGACATAGTAAACGATAAATGGGAATGTTACTATAATAATTTCTCTTGGGTGAATTCCAAGATATCTTTTGACCATGTCGGTATAGCGTATTTAGCGTTATTTCAAGTAGCCACGTTTGAGGGGTGGATGGAAGTAATGGCCGACGCAGTTGACGCACGAGGAGTCGACTTGCAACCAGCGAGAGAGGCAAATCTATATGCGTACATATATTTTGTTATATTTATCGTCTGCGGCTCTTTCTTCACCCTCAATCTATTTATAGGAGTAATAATAGATAATTTTAATATGCTCAAGAAGAAGTATGAAGGAGGAGTATTAGAAATGTTCCTTACAGAAAGCCAAAAACATTATTACACTGCTATGAAGAAACTTGGCAGGAAAAAGCCCCAGAAAGTAATAAAGAGGCCAAGAAATCAATTTCTAGCAATGTTCTATGATTTATCGAATTCGCGTCGTTTCGAAATAGCTATATTCGTTCTAATTTTTTTAAACATGCTCACCATGGGTATAGAGCATTACGATCAGCCTCATTCCGTATTCTTCATTCTTGAAGTTAGTAATGCGTTTTTTACTACAGTATTCGGCTTAGAAGCAATAGTTAAGATCGTCGGTCTAAGGTATCATTACTTTACGGTGCCTTGGAACGTCTTTGATTTCCTTTTAGTTTTAGCGTCAATTTTAGGCATAGTTATGGAAGATATAATGATAGATCTGCCCATATCGCCCACTCTACTGAGAGTGGTGAGAGTATTTCGTATAGGAAGAATCTTAAGACTGATTAAAGCTGCTAAGGGCATAAGGAAACTTCTATTCGCATTAGTGGTATCGTTACCGGCTCTATTCAATATAGGAGCTCTGTTAGCGTTGATTACATTCATATACGCAATAATCGGTATGTCGGTCTTCGGTCACGTCAAAGAACAAGGTGCCTTAGACGATATAGTCAACTTTCAAACGTTCGGACGGAGTATGCAGTTGCTTTTTCGTCTGATGACGTCGGCGGGTTGGAACGATGTATTAGAGTCACTCATGATCCAACCGCCGGACTGTGAACAAGGCGACCATGGTCACTCGAACGGCAACTGTGGAAGTCCACTTCTAGCGATCACCTACTTCACTTCCTTCATCATAATAAGCTACATGATCGTTATCAACATGTACATAGCTATTATCCTCGAGAATTTCAACCAAGCCCACCAGGAAGAAGAAATTGGTATCGTTGAAGATGACCTTGAAATGTTTTACATTAGATGGTCCAAATACGACCCACATGCGACTCAGTTCATCAGTTTTGCTCAGCTATCCGAGTTCATAGCCTCCTTAGACCCACCTTTGGGCATCTCAAAGCCCAACACCGTGGCTTTAGTCAGTTTTAATCTCCCTATAGCTAGAGGGAATAAGATACATTGTTTAGATATCTTGCATGCACTGGTGAAACACGTTTTGGGTCACGTTGAAGAAACTGAAACCTTCAGGCAATTGCAAGAGCAGATGGATATCAAATTCAAGAAGCAATTTCCGACGAGAAAGGAACTGGAAATTGTCTCTTCGACTAGGATATGGAAGAGAGAAGATAAGGCTGCGAGGACTATACAGCGTGCTTGGAGAGAATACGTCAAGCGTAAAAACCGCAGTCCGTCTGTTGAAGAGGAAAGCACGAAATGGTCTCCGGGAGGAGGCTGGGGCGGTCGCCTCAGTGCTTTGCTGCACGTGAGAAGAGGATCGCATGCGTCAAGTCGGAAATCTTCAAGGGCTTCCGAAGCATCAGACATAAGCGAATTGGGAGGGGCCTGGTTAAATTTACCACTCCTCTTGTTGCCTGGTGCCACGCCGGCTGAACAGATGGCAGCCTGTTCAGAATCAGCACCAACCAGACGTAGGTCGGCATACGGTTTGCCTATTTTCCTTCGTCACCAAGACGCAATGGATGAAGATGTCGGCCCCAAACGCGCAGGTTCCCTTCGTCTGAGCTCAAGAAGAAACTCAGCTCGGCGACCAACGCCTCCCGCCCGCGCCCGCACTCCTTCCCCGCACGCAAATAACAGCGAAGTTAGCATCCTCGTTACTGAAGCATCACCGGACGCAGCCCCGGTTCCGACAGCGCCGCCAACCGTAGTACGAGTCCTCGTGCACAGAGAGAGTGACGAGCAACCCAGCTGA
Protein
MDIYIFLAIYTAEMIIKCIAKGFILNKYTYLRNPWNWLDFVVITSGYATIGMEVGNLAGLRTFRVLRALKTVSIMPGLKTIINALLHSFKQLAEVMTLTIFCLMVFALFALQVYMGELRNKCVKNLVMQPGENFTDEIWSAWIKEPTNWMVDEELVPIICGNLTGARHCPLHYTCLCVGPNPNHGYTNFDNFLWSMLTTFQLITLDYWENVYNMVLSSCGPMSVSFFTVVVFFGSFYLINLMLAVVALSYEEESQITQEERKKDLNEHRDDSTFSFDPSSLAVRTLAKDSKKRIDARKGLLLASYSRKRTRRRKRGRSAIHHAAAVAAVAERSRSRSVTPSASPPPLPPPPPPPPPPHTLHPDNALGRGILSAAGRQLSDHSNNRESSLDDSGVVDDHDDGEHTSDDQAPHPHPRRVLLMPPPLPALQQSTPMPPLQQTQESHTEEPKQKAKLRIREEKPIEKVKKGDKQKETVYERYPLNPDYLNQIVVLGADWPYERAPALPQAETTKINEIGLLAAKHKTHMGNYEQNCTYFTDELVDRNCECCVSCCIDYEGWLQFQNCLYGIVKDPLFELFITTCIVLNTLFLALEHHGMSENVRRVLDIGNKVFTSIFTLECIMKVMAMSKDFFACGWNIFDLIIVSASLLDLIFELVDGLSVLRGLRLLRVLKLAQSWTTMKVLLSIIISTIGALGNLTFVLVIVIYIFAVIGMQLFSKSYTPDKFDPDPVPRWNFNDFFHSFMMIFRILCGEWIEPLWDCMRAEQASGAESCFFIFLPALVMGNFMVLNLFLALLLNSFNSEELKNKKEEVGEDSKLAKSFDRIRSIVRKKGFLISRSKETEKKSKLEELVNEFMSQQRAIKEKKASIPTEQRYSASIQETILFPHDNIYSHSYQEAVNRPISVGSEFAYPQLYQSCSNINHGSQETLKDVRDLATEHKITSIREDSKENLEDTSPFEQKSAQKLLNQISSGYYTQPSDSRDEENEHYEMAQFSCKTTPEKTKKQGRDPPNTLSKDPNKKPDEDDMKHPWQTLVSYVDELTVGGRKNSKGQYIDAMGNFPGFGKQKEPKVPQDCFPSQCYDISSCWDTCIDTKIGQRWMLVRTFVLRYVDTPAFEWFVLVLIFASSITLCFEDIHLEKNKPLKKILYWTNLGFCMIFIIEMFLKWIALGFFRYFTSFWTLLDFTIVFVSVFSLLIEENENLKVLRSLRTLRALRPLRAISRWQGMRIVVNALMYAIPSIFNVLLVCLVFWLIFSIMGVQFFGGKFFKCVNEEGELLPLDIVNDKWECYYNNFSWVNSKISFDHVGIAYLALFQVATFEGWMEVMADAVDARGVDLQPAREANLYAYIYFVIFIVCGSFFTLNLFIGVIIDNFNMLKKKYEGGVLEMFLTESQKHYYTAMKKLGRKKPQKVIKRPRNQFLAMFYDLSNSRRFEIAIFVLIFLNMLTMGIEHYDQPHSVFFILEVSNAFFTTVFGLEAIVKIVGLRYHYFTVPWNVFDFLLVLASILGIVMEDIMIDLPISPTLLRVVRVFRIGRILRLIKAAKGIRKLLFALVVSLPALFNIGALLALITFIYAIIGMSVFGHVKEQGALDDIVNFQTFGRSMQLLFRLMTSAGWNDVLESLMIQPPDCEQGDHGHSNGNCGSPLLAITYFTSFIIISYMIVINMYIAIILENFNQAHQEEEIGIVEDDLEMFYIRWSKYDPHATQFISFAQLSEFIASLDPPLGISKPNTVALVSFNLPIARGNKIHCLDILHALVKHVLGHVEETETFRQLQEQMDIKFKKQFPTRKELEIVSSTRIWKREDKAARTIQRAWREYVKRKNRSPSVEEESTKWSPGGGWGGRLSALLHVRRGSHASSRKSSRASEASDISELGGAWLNLPLLLLPGATPAEQMAACSESAPTRRRSAYGLPIFLRHQDAMDEDVGPKRAGSLRLSSRRNSARRPTPPARARTPSPHANNSEVSILVTEASPDAAPVPTAPPTVVRVLVHRESDEQPS
Summary
Description
Mediates the voltage-dependent sodium ion permeability of excitable membranes. Assuming opened or closed conformations in response to the voltage difference across the membrane, the protein forms a sodium-selective channel through which Na(+) ions may pass in accordance with their electrochemical gradient.
Similarity
Belongs to the sodium channel (TC 1.A.1.10) family.
Feature
chain Sodium channel protein
Uniprot
EMBL
Proteomes
Interpro
Gene 3D
ProteinModelPortal
PDB
6J8E
E-value=0,
Score=1900
Ontologies
KEGG
GO
Topology
Subcellular location
Cell membrane
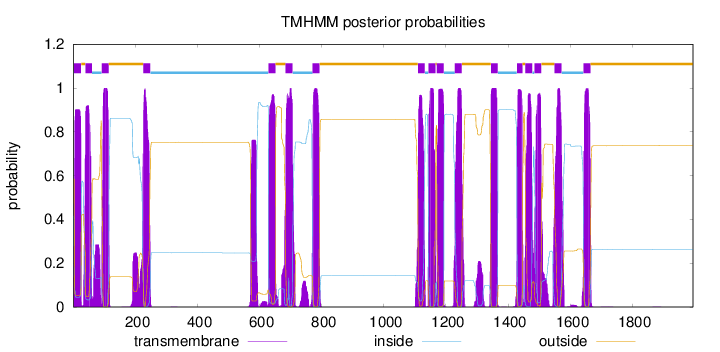
Length:
1995
Number of predicted TMHs:
17
Exp number of AAs in TMHs:
415.10857
Exp number, first 60 AAs:
39.9077
Total prob of N-in:
0.41557
POSSIBLE N-term signal
sequence
inside
1 - 2
TMhelix
3 - 25
outside
26 - 39
TMhelix
40 - 60
inside
61 - 91
TMhelix
92 - 114
outside
115 - 225
TMhelix
226 - 248
inside
249 - 628
TMhelix
629 - 651
outside
652 - 683
TMhelix
684 - 706
inside
707 - 770
TMhelix
771 - 793
outside
794 - 1109
TMhelix
1110 - 1132
inside
1133 - 1143
TMhelix
1144 - 1166
outside
1167 - 1170
TMhelix
1171 - 1193
inside
1194 - 1228
TMhelix
1229 - 1251
outside
1252 - 1344
TMhelix
1345 - 1367
inside
1368 - 1428
TMhelix
1429 - 1446
outside
1447 - 1455
TMhelix
1456 - 1478
inside
1479 - 1484
TMhelix
1485 - 1507
outside
1508 - 1549
TMhelix
1550 - 1572
inside
1573 - 1642
TMhelix
1643 - 1665
outside
1666 - 1995
Population Genetic Test Statistics
Pi
233.286398
Theta
159.034529
Tajima's D
1.533415
CLR
0.198693
CSRT
0.797910104494775
Interpretation
Uncertain
