Gene
KWMTBOMO11436 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA001935
Annotation
PREDICTED:_dystroglycan_[Amyelois_transitella]
Location in the cell
Nuclear Reliability : 3.842
Sequence
CDS
ATGGGGTGCGCAAGGTACATCGCGTGCGCGCTACTCTTGCTGTGTCCTCTTGCTCTCAGTCGGCACGACGACGACTTCGCTTTCGACAATAGCGAAGAATTCCAGGTTGAATTAACGGCAAACCACTCAGAGATAGCTAAGAATGGCCTAAGGAGATTATGGGGTGTACCCGACACGTTGGCCTATGTAGGACACCTGTTCCGCATGGAAATCCCCAAGGAAGCGTTCTCCGGAAAAGTTGTTGCTTATAAAGTTCGCAGCGACCACGGGAGGCGTACACCGAACTGGCTGGCGGTGGATTCGAGGCACGGTCTTATTAGCGGTATCCCACAGTACCAGGACATTGGAACTCACACATTCACCGTCACCGCTCACGGAACTACCAAAGGACTCACTGCAACCGATTCATTCACTATCGAGGTGAAAAAGGGTGAAGACAAACCTCATTCGAAATACGGGACGTGCATCGGAGATGAGAACAGGCTGGTTCTCCTTATTCTGGTTGACGGAGCGTTCCACAAGATCGTGCCTCGACAGAGAATAAGAGCCCTGATGCAACTCGCAAACTTTATGGCTCTTGATGGGGACGAATTTTGGATGGAACCTTACAAGACTGAAACGCATCCGGACACGATATTAAGCGGAATCGGTTCTTCATTGAGGAAACGAGGCGATGCCACAACCGCCATATATTTGAACGTCGGCTGCGGGAACAAGCTGTGGGATCGGCACAAGGTGCTGGTGGCGGGGCTGCGCGAGCAGTCGCGCGACGGAACGCTCGAGCAGCTGCTGCGGCTGCCCGTCATCGGCTGGAGACTCCTGGCCGTCAAGCCCACGTTCAGAGTCAAACGACAGTCCCCGATGGAGGGGTCGGGCGACATGTACGACGCGGAGTACGACGGCGACGACGACGCGGACTACAGCGGCTACGACGACGACAACGACGACCTGAACTTCGAGGACGCGCGCCGGAACGATGTCGGCGTACCGGAGCTGGACGAAGACCACGACGTGAAGATAACGCCTTACTCCGAATCTGCTTCGGAAACAAACAACATAACGTTTGTGCCGGTGTCATCGAGACATCTAGAGGACGTTGCCATTGTGCCAGATTACATTCCAACCACGACGGAACCGGAAATGCAAACCGTTATGATACGCGCGTCAAACGAACTGCCGCCTTTGTCGTCCGAGTCGCCCCCGACCGTGACGTCACAGTCCCCCGAGCCACCCACGCAGCCGATTACCACATCCTCTACGACGACGTCTACGACCACCCAAGCTCCGGCCACGACGCCGGTCACTGTTCCGGTTACGACGCCTGTGACTACGCCGGTGACTACGCCAGTCGCTACGCCGCCGCCCACTACGACGACCAGCACTACGCCGATGACCACTGTACCGACAACGGTACCGACTACAACCGATCCACCAGAAACCACTATACAGGAGGTCACCAAACAGGAGTCCACTGTGACGGAGGGTAAGAGCACAATAATTGGTCAAACCACGGAGACGGTGACCTTCGCGATGCCTGTCAACCAACCACCGGTCCTCAAACATCACATGAAGAAACTCGCTATAACTGCTGGAAAAGCCTTTAGATACATAATCCCCACCGATCTGTTCATGGATCAGGAGGACGGGAGCAACTTGACTTTCACGATGTACGAAGCCGAAAACGTCCCCTTAAGCAAAAACTCATGGATACAATTCATACCGTCCGACCTTGAAGTTTACGGACTACCGCTGGAAGCCCACGTCTCACGTTGGAACTTCATAGTGGAAGCTCAGAACAGCGCCGGCCTCAAGGCCCGGGGCCCGCTAGACATCACCGTGCAGCAACACAAGAGCGGACGCACCATCAACCACCGCTTCATCATGCAGTTCACGCTGCTCAAGCAGTACAATAACGCCATCGACTGGCAGATAAGGGCCTTGGAGGGAATAGTGAATCTGTTCCGGGACACCGACATGGACCATCTGACCGTGTTGAACGCGACCCAAACGGGAGATCTCTGCGAGTTCGTTTGGACGAACGATACCCTGCCGAAAGACGCGGCCTGTCCTATGGATGACATCAATAGACTTATGAAGATAATGGAGTCTGAGTCGGAGCCGGGTCGCGGGTCCCGCTTGTTGTCGCGCGCCATGTCCCCGGAGCTGGGCGTGCGCGGCGTGCGGTGGGAGGGGGCGGGGGTGTGCGCCGCGCCGCCCGCCACCCGCGCGCCCGACACCTACCCGCCCGTCACCCGCAACCAAGTCGACCACATCACTGCCTCCGCCGGACACCTGCTCGTCTACAAAGTGCCCGAGGACACATTCTTCGACCCAGAAGACGGAGGCACCCGTAACCTCATACTGTCGCTACGGTACAGCGACCGCACCGAGATCCCGGCCGGGCACTGGCTACAGTTTGACGCCAATAACCAAGAGTTCTACGGCTTGCCCACTACTACGGACGAGGGCAGCGTTTCTTATCAACTGATTGCTGAAGACTCCAGCAAGAAGACTGCGTACGACAGTTTAATAGTGGAGGTCGTGAAGGCGCCTCCAATCCGACCCACGGTCGAGTTCCAGATGACCTTGGAGTATCCGTTCTTGAAGCTCGCCTTCAACGCTAAAAACAAGCGTAAAGTTGTCGAGAAGCTCGCCAACCTGTTTGGACAAAAGGAGACTGATAATATTAGGATACAAAGCATTACCAATAATCCTACCTCCATTATATGGTACAACACTAGCTTGCCAATGGACAGATGCCCGAAGGCGGAAATCGAGCAACTCCGCAAGATGATCATCGTGGATGATCGCGGCTCACGAGGAGGCGCTCTCCGCGAAAACGTCGATCAAGTCTTCGACAAGGACTTCAAAGTGATGTCGATAACCCTCAACCCGCTCGGCCTGTGCGCGGAGCAGAACACCAAAGTATCGAAGGTCCCACCGGCGCTGTACCCCGGCGCGCCCAACTCGCAGAACAGCAAGACAGGCAGCGCCGCGGAGCAGAGCTACCTCGTGACGTTCATCATCCCGGCCGTGGTCATCGTGTGCATGATACTGCTGGCCGGCGTCATCGCCTGCGTGCTGTACCGGAGGCGGCGGACAGGTAAAATGAGTGTCGGCGACGAGGAGGAGCGACAAGCGTTCCGTTCGAAGGGCATACCCGTTATATTTCAAGACGAATTAGAAGAACGTACAGACACCGAACCTATACACAAAAGTCCTGTTATAATGCGCGAAGAGAAGCCGCCATTGTTGCCGCCCGCACCGGACTACAGATCGGGCGAGGATGCCCCGTACCGTCCGCCGCCGCCATTCGCCGCGTCCCGCACTCCGCCGCGACCCAAAGCCACACCTACCTACAGAAAACCTCCGCCATACTCATCGAAAATGCAATTATTGGAAAGCTTACGAATTTCTCTGAAACGACGACCACAAATGATTGAATTGATCATGAGTATGAGAAAGTGTATTAAAAAGAAGAACGTTGTCATAAAAAAATTAAAACAATGTTTGAAAGAAAAGAACGTCAGAACAACATCCATAAATGCATCTTCTCAAAACAACGTGTTCGAATTGAATATTCCACACAGCAGTGAAAATGAGACGCCAACCTCAGACAATGACAACCAATCTTTAAAAAATACCAAGTCCACGCAAACACCTAAAGTAAAAACAAGCGATACTGCGACACAAATGGAGACAATGAAAACAAAAAAATGTGAGGAAAGCCTAGAAGCGGGATGGAATTTGCATGATGGTTCAGGAGAGATGTCTCTTGCCGAGCAAGTGAAAGAGGTGGCCCAGACTGCCTTGCAGCAGACAGGGATGGTGTATGTTGAGTCAGCAGGCATGTACTACGATTACAAGACTGGTTATTATTATAATTCTGAACTGGGTCTCTACTATCATACCGATACCAATTGCTATTACTACTATTCAGACGAGAAGCAGAGCTTTGTCTTTCATTCTTATCCTGATAGTAGCATCGAGAATCCTGGTTTAGTTGCTCATAATAAAAAGAAAGCTAGAAAGCACAAAGCTGTACAACTAAAAGAAGATGTCATGGAAAACCTGACGAAAAACTTATCTCAGGAAAATGAAGACAGCCACCTTAGGCTGAAGCAGAGGAAGATTTCAAAAGTTAAAGAATCCAAGAATAAAAAACCTTTTAAAGCTAAAATTGATGAAAATGGTGATCAATCTATAGAAAATAATGGTGAAAAATGTGATGTTATGGAGTTAGAAGACAAAGAACAAAATAGTGAAGACACACAGGACACCAGCAAGAAGGACAACAAGGCATCCAGGGATCTCGAAGATGGAGAATGCAGTGATTCAGCTGATGAAGACTCTGGGTCAGACAATGAATGTTCATCTAATGCCAGCACATCCACATTAACTGATGATGAAAATGTTGCAAAACACCATCCACCGTGTATGCGCGTGATCGTCAGGGAAACTAGTCTACCCAAACTGAAAATTGGAAATCTTTTCCTGATAACGAAAGATGGCGGCACGATCGGAAGGGAAGGGGAGCAACACGCTATTGTTTTAAAAGACCACAACGTGTCTAGGAATCATTTGGACATTCAATACGACCTCGCACGACAGACGTACACCGCTGTGGATCTAGGATCTAAGAACGGAACGATACTGAACGGCATCAGAATGTCTGAGAGTCAAGTCGTCAGCAAACGCGTCGATGTCGTTCATGGCAGCACGATACACATAGGCGAGACTAAACTGCTGTGCCATGTGCATCCGGGAAATGACACCTGTGGCCACTTAGAGGAGCGAGAGAAGAAAGTCGCGTACACGCGCACGTGCAGCGTGCAGCGGCAGCACCAGCTCGAGCTGGCGCGGCTGAAGAACAAGTACGCGCCGAAGGTGCTGAGCATCGAGGAGACGGCGTACAACGACCGCGCGCAGGCCCGCCGCGACGCCGTCGGCTCCTCGCACGAAGCCGAGAAAACGCAGACTACAGACCTCGACACGTTTATCGCGCCCGAGAATAAAGGTTTCCGGCTACTAGAGAAGATGGGCTGGTCCAAAGGCGAAGGACTCGGGAAGGACAGCCAGGGAGAAATAGAACCGGTAAGTACATAA
Protein
MGCARYIACALLLLCPLALSRHDDDFAFDNSEEFQVELTANHSEIAKNGLRRLWGVPDTLAYVGHLFRMEIPKEAFSGKVVAYKVRSDHGRRTPNWLAVDSRHGLISGIPQYQDIGTHTFTVTAHGTTKGLTATDSFTIEVKKGEDKPHSKYGTCIGDENRLVLLILVDGAFHKIVPRQRIRALMQLANFMALDGDEFWMEPYKTETHPDTILSGIGSSLRKRGDATTAIYLNVGCGNKLWDRHKVLVAGLREQSRDGTLEQLLRLPVIGWRLLAVKPTFRVKRQSPMEGSGDMYDAEYDGDDDADYSGYDDDNDDLNFEDARRNDVGVPELDEDHDVKITPYSESASETNNITFVPVSSRHLEDVAIVPDYIPTTTEPEMQTVMIRASNELPPLSSESPPTVTSQSPEPPTQPITTSSTTTSTTTQAPATTPVTVPVTTPVTTPVTTPVATPPPTTTTSTTPMTTVPTTVPTTTDPPETTIQEVTKQESTVTEGKSTIIGQTTETVTFAMPVNQPPVLKHHMKKLAITAGKAFRYIIPTDLFMDQEDGSNLTFTMYEAENVPLSKNSWIQFIPSDLEVYGLPLEAHVSRWNFIVEAQNSAGLKARGPLDITVQQHKSGRTINHRFIMQFTLLKQYNNAIDWQIRALEGIVNLFRDTDMDHLTVLNATQTGDLCEFVWTNDTLPKDAACPMDDINRLMKIMESESEPGRGSRLLSRAMSPELGVRGVRWEGAGVCAAPPATRAPDTYPPVTRNQVDHITASAGHLLVYKVPEDTFFDPEDGGTRNLILSLRYSDRTEIPAGHWLQFDANNQEFYGLPTTTDEGSVSYQLIAEDSSKKTAYDSLIVEVVKAPPIRPTVEFQMTLEYPFLKLAFNAKNKRKVVEKLANLFGQKETDNIRIQSITNNPTSIIWYNTSLPMDRCPKAEIEQLRKMIIVDDRGSRGGALRENVDQVFDKDFKVMSITLNPLGLCAEQNTKVSKVPPALYPGAPNSQNSKTGSAAEQSYLVTFIIPAVVIVCMILLAGVIACVLYRRRRTGKMSVGDEEERQAFRSKGIPVIFQDELEERTDTEPIHKSPVIMREEKPPLLPPAPDYRSGEDAPYRPPPPFAASRTPPRPKATPTYRKPPPYSSKMQLLESLRISLKRRPQMIELIMSMRKCIKKKNVVIKKLKQCLKEKNVRTTSINASSQNNVFELNIPHSSENETPTSDNDNQSLKNTKSTQTPKVKTSDTATQMETMKTKKCEESLEAGWNLHDGSGEMSLAEQVKEVAQTALQQTGMVYVESAGMYYDYKTGYYYNSELGLYYHTDTNCYYYYSDEKQSFVFHSYPDSSIENPGLVAHNKKKARKHKAVQLKEDVMENLTKNLSQENEDSHLRLKQRKISKVKESKNKKPFKAKIDENGDQSIENNGEKCDVMELEDKEQNSEDTQDTSKKDNKASRDLEDGECSDSADEDSGSDNECSSNASTSTLTDDENVAKHHPPCMRVIVRETSLPKLKIGNLFLITKDGGTIGREGEQHAIVLKDHNVSRNHLDIQYDLARQTYTAVDLGSKNGTILNGIRMSESQVVSKRVDVVHGSTIHIGETKLLCHVHPGNDTCGHLEEREKKVAYTRTCSVQRQHQLELARLKNKYAPKVLSIEETAYNDRAQARRDAVGSSHEAEKTQTTDLDTFIAPENKGFRLLEKMGWSKGEGLGKDSQGEIEPVST
Summary
Uniprot
ProteinModelPortal
PDB
4WIQ
E-value=3.65729e-10,
Score=162
Ontologies
GO
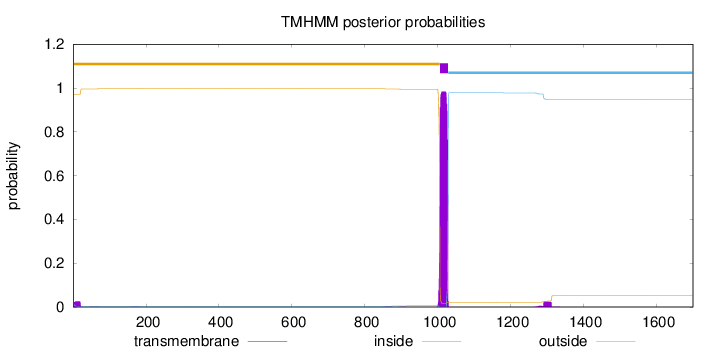
Topology
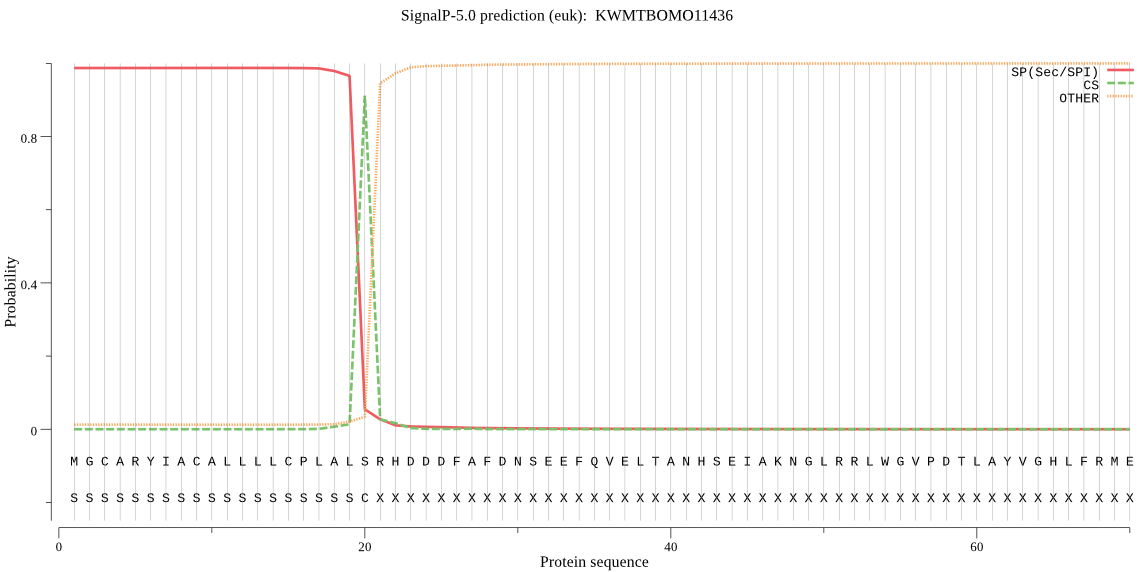
SignalP
Position: 1 - 20,
Likelihood: 0.987259
Length:
1701
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
23.79704
Exp number, first 60 AAs:
0.48298
Total prob of N-in:
0.02949
outside
1 - 1006
TMhelix
1007 - 1029
inside
1030 - 1701
Population Genetic Test Statistics
Pi
243.840195
Theta
19.583057
Tajima's D
0.726411
CLR
0.191243
CSRT
0.587170641467927
Interpretation
Uncertain
