Gene
KWMTBOMO11308
Pre Gene Modal
BGIBMGA001838
Annotation
PREDICTED:_uncharacterized_protein_LOC105387844_[Plutella_xylostella]
Location in the cell
Nuclear Reliability : 2.864
Sequence
CDS
ATGAAACGACACGATGCCATCACTAAAATGACGGAGCTAGTGCAGGAATACGATCCATCAGCGACCAGAGTGCACATTTTAAGAAAAATTGGGAGTCTACGGGCGTGCGTACGTAGGGAATACAAGCGCGTCCAAGAGAGTAGGAGGAAAGCTACTTGTGAAGAAGAAGTTTACGTTCCTAATCTGTGGTATTACGACTTACTGTCATTCATATTTAAGAACGAAGCGCCGGAGCCAGCAAGATCGCCTATCCCCACTGCTCGGGGCGGTGCGGCGGGGCGCGGGGGTCGAGCCACCGATTCGCCCAACCCAACCGCCAGCACGTTCAGTGACCTGCGCGACGCGCTGCTCGACGCACGCATCGGCATGTCGGAAGAAAACGTAGTGTTCCCACAAAAAATACTGAAGAAATTCATACTTTTATACAAAGATCTGCCGTGTTTGTGGGACAAAGAATGTCCAGCTTACAAAATCAAAATGAAACGACACGACGCCATCACTAAAATGACGGAGTTAGTGCAGGAATACGATCCGTCCGCGACCAGAGTGCACATTTTAAGAAAAATTGAGAGTCTACGGGCATGTGTTCGTAGGGAATACAAGCGCGTTCAAGAGAGCAGGAGGAAGGCTAATTGTGAAGAAGAAGTTTACGTTCCTAATCTGTGGTATTACGACTTACTGTCATTCATATTTAAGAACGAAGCGCCGGAGCCAGCAAGATCGCCTATCCCCACTGCTGAAACAGAGGAAGAAGAAGACGATGACTGTCAAGTGTTCGACAGCCAATCTGTGGACTACTCTAACGACTTTAACGAAACAGGGAACATGGTGGAAGCTGATGATGTGTCAACGATATCCAAAAGATATTTGACGTTTGAACCTGAATCTACAACTTCAAAAGTTAAGAGACAGTTTACTGAAGTGGAAGATGAATACGATGCAATTGAAATGGTGCTCACACGGTCCGAGAAGATGAGGTCGTCACGCCTTGACCGGCCCGGCAACGAAGCTGTCTCGGGCTCAACATCGCAAGACGCACAGCAACGAGCTGTGTCGGCCGCGCCGCGTTCGGGAGTGACGCAGGGACCGCCACCGATGGCGGCAACCTCCTCCCAGTCAACCGCGCCGCGTTCGGGAGTGACGCAGGGACCGCCACCGATGGCGGCACCCTCCTCCCAAGTGGAAAAGTGTCCGGGAGTGCCGCGGGGCTCACAAGCGATGCCCCCCTCCCGCCAAATATTGCCTACGCAATACTCGCCGGCGTCGCCAACGGGACCGAACAGCGGGGTCTGTCGTCGAGTGGTCAGACCTCCCAGCACCGCGACACCGGCAACAACTTCAGGCGACGCAGCAACGGAGAGCGTCGTATCCGCGAGCCAGAACAAGAAGGAGTCAGCGCTCGCGGCCAATCAAATAGTACACGGGTCCCACATCACGGACGCCGCTGCCAAAATCTCGACGACAGAAGAAGGCTCCACACTCCGCGACGGGATGGCGCCACCAGTACGAGGATCTTCAAGAAAGTCGAGTCAACAGTCACAACGGCTGTTGCTTATGGCGCGCCTCAAGGAAGAGCATCTTCGCGCCAAGGAAGAACAAGCCCGACTCCAAGCAGAGCTCGCCGCCGCCCGCATCTCAACATTAGAAGCCGAAGCGCTCGTTGAAGAGGAGGAAGATGCGCGCACAACACTCACGGAGGACGAGAACGAGCAATCGCAGCGCATCGATACATGGCTCAGTCAGCAACGATCGATCGCGCTACAGGGAGTCGAAGAAAGAGTAATGCAGCCAACACACGGATCACCAGCCACCATCGAGCAAAAGCAACTGGAACTTCCCGCACCAATAGAACAGCTGAAGCTACCGGCCCCTGCCGCGGCACCGATTGCCGTACCTGTCGCACCGAAGAGCGACATCGCCGAACTAGCAGCTGCCATCGCGACGGCCGCCCGCCAAGCCAGGCCCGGACCATCGCATCGGTACTACGGGGAGCTTCCAGTGTACAGTGGATCGCACCAAGAATGGCTCTCCTTCAAGGTCTCCTACGCCGAATCAGCGGACAGCTTCAGCGCCGCAGAGAACACTGCGAGACTTCGGCGTACGTTGAGAGGAAGAGCAAGAGAAGCGGTCGAAAACTTGTTGCTGCATTACACCGAGCCCGCCGAGATCATGCGGACTCTAGAATCGCGCTTCGGACGTCCAGAAGCAATCGCCGCAACGGAGCTGGAACGACTGCGCGCGCTGCCACGCTGCACGGACACACCGAGGGACATCTGCGTTTTCGCGAACAAGGTGAACAACGTCGTCGCCGCTCTGAGGGCCCTCGACCGCGTACATTATATGTACAACCCGGAGCTCACCAACATCACATCAGAGAAGCTGCCGTCCACTCTACGCCACCGCTGGTTCGAATTCTCAGCGACTCAACCGGCGGGAGAACCGGACCTCGTCAAGCTGTCGCGCTTCCTGCAACGCGAGGCGGACCTGTGCAGCCCATACGCACAGCCGGAGCCAGAGACGAGAGTGGAGAACACCAGCGGTCGGCGGAAGATGGTGAACACGCCTCAGAGGACGCACACCACGCAAGCGAAGGAAGAGAGGAAATGCGCAGCATGTCAGAAGCCGGGGCACATCCCACAAGATTGTCCCGAATTCAAGAGAGCAGCCGTCAGCGAGCGCTGGGATACGGCGAAGCGCGAGAATTTGTGTTTCCGGTGCCTACGGTTCCGGTCCCGGGGACACGTATGCAAAAAGAAGAAGTGCGGCGTCGACAGCTGCGAACGCACGCACCACGAGCTGTTGCATAAGAAGCCAGCATGGCAGAAGCCGAAAGAAAAAGAAGAGGCGGTCACCTCGACGTGGGCCGCAAGAAGTGCGACAGCCTACCTAAAGATGGCGCCAATTACCGTTATCGGACCGGCGGGAGAAGCAGATACATGGGCCCTGCTGGACGACGGGTCAACGATCTCGCTGATTGACGAAGACTTCGCGAGACGAGTGGGCGCCAAAGGACCGATCGAACCCCTCTTCATCACTGCCATCGGAGACAATAAGATAGACGCAACACGCTCACGACGCGTCCCGCTGAAGCTATGCGGACGCACGGGGGAACCGCAAGAACTGAACCTACGGACAGTCAACGGCTTAAAATTAACACCACAGCGACTGAACATCGAAGTCCTCGCGTCGTGCCATCACCTCACCGACCTCCGCCATCACTTCAAAACGAGCTACGCCTCGCCGAAGATCCTGATCGGCCAAGACAACTGGCACCTGCTGGTGACGGAGGAGATGCGGACGGGACGACGCGATCAACCAGTGGCGTCTCGTACTCCACTCGGGTGGGTCGTGCACGGAGCACACCCGGGAGGCAAGAGACAGCGCGTCAACTTCGTGGGACACGCGACGACGGTCGACACGAACATGGACGAAGCCCTCAAACAGTACTTCGCGATCGAGGGACCCACCGTCGCCGCCAAGACGCCGAAGAATGACCCAGACGAGCGCGCGCTGAAGATCCTGCGAGAGACCACTCAACAGCGACCCGGCGGCCGCTACGAGACCGCACTGCTGTGGCGTGAGGAGGGCCTGAAGATGCCCAACAATCTTGAAGCCGCAATGAATCGCCTGACGTCCGTAGAGAAGAAACTGGAGAAGGATCCAAATTTGAAAGAGCGCTACAAGCAACGAACAAACGCACTGGTAGCAAAAGGATACGCCGAAGTAACTCCGTCGACGGAGGGAAGAAGCCCAAACGACTTCCTGCTCACCGACCCGGACCTGCTGCAGTCGCTGCCCGGAGCGATGATGCGCTTCAGGCAGCACGCCGTTGCCGTCTCCACGGACATCGCGGAGATGTTCATCCAGATAGGCGTCCGAAGCGAGGACCGCGACGCGCTCCGGTACTTGTGGAGGGAGAACCCTTCACGAGAACCTATAGAATACCGGATGAGGTCCATCGTCTTTGGCGCGACAAGCTCGCCTGCAACCACCATCTGCGTGAAGAACCGACTGCAGTACCCGGACGCCGCCGACCTCAAGCTCCACACGTACGTGGACACGAGCAAGTACGCCCACGACGCCGCGTTGTACTGGCGCGTGGAGACGCCCGACGGGGAGATGAGGACCTCCCTCGCCAAAGCCCGAGTCGCACCCATGAAGCTAACATCGATACTGCATCTCGAGCTACAAGCCGCCGTGATGAGCAGCCGCATGGCCGCGGCCGTCACGGAAGAACACAATAGAAAGCCAGACAAGAGTGTTCTGGACAGACAGCGCCACCGTATTGACCTGGCTGCGAACGGGGTCGAGGTCGTATCGACCGTTCGTCGCTCACCGCATTGCAGCGATAGAAGAGAACAGCACTGTGGAGGAATGGCGCTGGGCCCGGAATACCTAAGACGGCATCCGGATGATTGGCCCGTACAACGGACTGCAAGAAGAGCAGAAGAGACGGGCGAAGAGAAGTGCGCAATGCTCGCCGTGAGCAGAGAGAGCCTCGGCGAAGCGATCCCGGACCCAAGACGCTTCTCCAAGTGGGAGAAGTACCTGCGTGCAACGGGGCGAATACTGCAATTCGTCGACCTATGCCGCAGAAGTCGCGAGCGCACTTATTACAAGAGGACCAGACGGAACCCGCGCTCGGACCCGACGTGGGAGAGAAATAGAAAGAAGACGACTTCGAAGACCCCGCTGAACACACCGCGGACGCCAGAGCAAGCAGTCATTCAATGGAAGACTTTAGACGCCGACACGCTTCGACGCGCCGAGACGCTCATTTGGCAACAGAGCCAGCGGGCAGCCTTCGAGGAAGAGATTTTGACGCTCCAGCGAGGGAAACAGATATCCCCAGCGAGCCGACTGCGAAACTTGTCCGTAACTTACGCGGACGGGATACTGAAAATAAACGGACGCATCGGCAACATAGAGGGAGCTGACGTCATCACCTCGCCTCTCGTGCTAGACGGATCCCGACGCGAAACGAGACTGATGATAGACTTCATCCATAGAAAGATGCACCACGCCGGAACCGAAGCTACGATCGCCGAGTGCCGACAGTCGTACTGGGTCTTACGCCTACGCCCAGTGACACGGAGCGTGATCCACAATTGTCTTCCGTGTCGTATCCGCAAGGACACTCCACCGCGTCCAGCCACAGGCGACCACCCACCGAGCAGACTGGCACACCATCGGCGACCATTTACATACGTGGGCCTCGATTACTTCGGGCCCTACCAAGTTACCACCGGCAGAAGCACCCAGAAGCACTACGTGGCCATCTTCACATGTCTCACTACGCGTGCGATACATTTAGAACCGGCAGCGAGCCTCAGCACGGACTCAGCAGTGATGGCACTCCGGCGCATGATCGCGCGCCGGGGAGCTCCGACGGAAGTATGGAGCGACAACGGCACCAACTTACGAGGTGCCGACAAGGAGCTGCGCCAAGCTATGGACAAGGCGACTGAGCATGAAGCGAGCTTAAGGCTTATACAATGGCGCTTCATCCCACCGGGCGCGCCTTTCATGGGCGGCGCCTGGGAGAGAATGGTACGGGCAGTAAAGGCCGCGCTCTCGGCCACGGAACAGACGAGGCACCCGACGCCCGAAATATTTCATACTCTGTTAGCAGAGGCAGAGTTCACAGTGAACAGCCGACCTCTCACCCATGTATCGGTGAGCGCCGACGATCCCGACCCTCTGACACCGAACCACTTCCTGCTGGGAGGCCCGGCGCGAGTCCCCGTGCCGGGCAAATTTGACGACGCCGACCTCATAGGGCGCGCACACTGGCGCGCAGCACAACGTCTGGCAGATGTGTTCTGGAGTCGCTGGCTCCGGGAGTACCTGCCCGACCTGCAGAACCGGCGGGAGCCCCACAGCCGCGGGCCCGCCCTGAAGATAGGCGACGTCGTGATAATAGCAGACGGAACGCTCCCACGGAACACCTGGCCACGTGGGATCATCCAGGAGGTTTACCCGGGGGCCGACGGCATCACTCGAGTGGTCGACGTACGCACCGCCGGCGGTATATTGCGACGCCCGGCAAAGAAGATCATCGTGCTGCCCACGATGTCCGCCGCTCACCAGGGAGGATGCAGCGACGTGAACGACGCTGCACGGCGGGAGGATGTTCGCGACGGACATGAATGA
Protein
MKRHDAITKMTELVQEYDPSATRVHILRKIGSLRACVRREYKRVQESRRKATCEEEVYVPNLWYYDLLSFIFKNEAPEPARSPIPTARGGAAGRGGRATDSPNPTASTFSDLRDALLDARIGMSEENVVFPQKILKKFILLYKDLPCLWDKECPAYKIKMKRHDAITKMTELVQEYDPSATRVHILRKIESLRACVRREYKRVQESRRKANCEEEVYVPNLWYYDLLSFIFKNEAPEPARSPIPTAETEEEEDDDCQVFDSQSVDYSNDFNETGNMVEADDVSTISKRYLTFEPESTTSKVKRQFTEVEDEYDAIEMVLTRSEKMRSSRLDRPGNEAVSGSTSQDAQQRAVSAAPRSGVTQGPPPMAATSSQSTAPRSGVTQGPPPMAAPSSQVEKCPGVPRGSQAMPPSRQILPTQYSPASPTGPNSGVCRRVVRPPSTATPATTSGDAATESVVSASQNKKESALAANQIVHGSHITDAAAKISTTEEGSTLRDGMAPPVRGSSRKSSQQSQRLLLMARLKEEHLRAKEEQARLQAELAAARISTLEAEALVEEEEDARTTLTEDENEQSQRIDTWLSQQRSIALQGVEERVMQPTHGSPATIEQKQLELPAPIEQLKLPAPAAAPIAVPVAPKSDIAELAAAIATAARQARPGPSHRYYGELPVYSGSHQEWLSFKVSYAESADSFSAAENTARLRRTLRGRAREAVENLLLHYTEPAEIMRTLESRFGRPEAIAATELERLRALPRCTDTPRDICVFANKVNNVVAALRALDRVHYMYNPELTNITSEKLPSTLRHRWFEFSATQPAGEPDLVKLSRFLQREADLCSPYAQPEPETRVENTSGRRKMVNTPQRTHTTQAKEERKCAACQKPGHIPQDCPEFKRAAVSERWDTAKRENLCFRCLRFRSRGHVCKKKKCGVDSCERTHHELLHKKPAWQKPKEKEEAVTSTWAARSATAYLKMAPITVIGPAGEADTWALLDDGSTISLIDEDFARRVGAKGPIEPLFITAIGDNKIDATRSRRVPLKLCGRTGEPQELNLRTVNGLKLTPQRLNIEVLASCHHLTDLRHHFKTSYASPKILIGQDNWHLLVTEEMRTGRRDQPVASRTPLGWVVHGAHPGGKRQRVNFVGHATTVDTNMDEALKQYFAIEGPTVAAKTPKNDPDERALKILRETTQQRPGGRYETALLWREEGLKMPNNLEAAMNRLTSVEKKLEKDPNLKERYKQRTNALVAKGYAEVTPSTEGRSPNDFLLTDPDLLQSLPGAMMRFRQHAVAVSTDIAEMFIQIGVRSEDRDALRYLWRENPSREPIEYRMRSIVFGATSSPATTICVKNRLQYPDAADLKLHTYVDTSKYAHDAALYWRVETPDGEMRTSLAKARVAPMKLTSILHLELQAAVMSSRMAAAVTEEHNRKPDKSVLDRQRHRIDLAANGVEVVSTVRRSPHCSDRREQHCGGMALGPEYLRRHPDDWPVQRTARRAEETGEEKCAMLAVSRESLGEAIPDPRRFSKWEKYLRATGRILQFVDLCRRSRERTYYKRTRRNPRSDPTWERNRKKTTSKTPLNTPRTPEQAVIQWKTLDADTLRRAETLIWQQSQRAAFEEEILTLQRGKQISPASRLRNLSVTYADGILKINGRIGNIEGADVITSPLVLDGSRRETRLMIDFIHRKMHHAGTEATIAECRQSYWVLRLRPVTRSVIHNCLPCRIRKDTPPRPATGDHPPSRLAHHRRPFTYVGLDYFGPYQVTTGRSTQKHYVAIFTCLTTRAIHLEPAASLSTDSAVMALRRMIARRGAPTEVWSDNGTNLRGADKELRQAMDKATEHEASLRLIQWRFIPPGAPFMGGAWERMVRAVKAALSATEQTRHPTPEIFHTLLAEAEFTVNSRPLTHVSVSADDPDPLTPNHFLLGGPARVPVPGKFDDADLIGRAHWRAAQRLADVFWSRWLREYLPDLQNRREPHSRGPALKIGDVVIIADGTLPRNTWPRGIIQEVYPGADGITRVVDVRTAGGILRRPAKKIIVLPTMSAAHQGGCSDVNDAARREDVRDGHE
Summary
Uniprot
ProteinModelPortal
Ontologies
GO
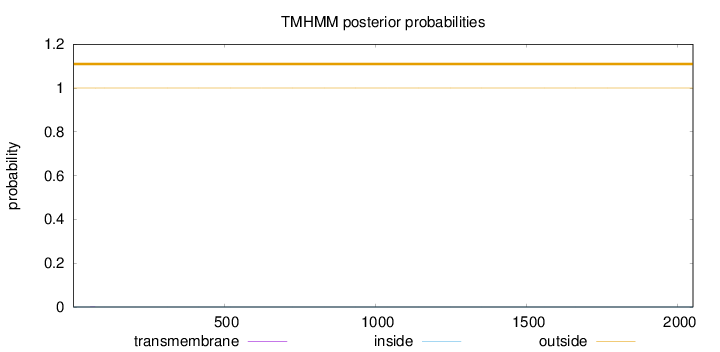
Topology
Length:
2050
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00540999999999998
Exp number, first 60 AAs:
0.00096
Total prob of N-in:
0.00025
outside
1 - 2050
Population Genetic Test Statistics
Pi
209.397007
Theta
153.836557
Tajima's D
1.332333
CLR
0.581364
CSRT
0.747212639368032
Interpretation
Uncertain
