Gene
KWMTBOMO11162
Pre Gene Modal
BGIBMGA008588
Annotation
PREDICTED:_centrosomal_protein_of_164_kDa_isoform_X2_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.802
Sequence
CDS
ATGAGTTCACCTTCTGCTGTTGTATGCCGTGAAGTTTTTGATGAAAACAGTCAGCCATCAGTCGAGGAAATCTGCGAGTATGCCCAGCAGTTGGGAATTGATCCTGAGAGCGAAAGCCACCTTTTACCACTTGCGCGCGATGGACTTATGCAGGCACTGCCCCATCAGTGGAAAGCATATTATGATGAAAAACTCCAAACTCATTACTACTATAACGAAGAGACAAAGAACACTCAATGGGAGCATCCTCTGGACAACTTGTACCGGGAACTTGTGAAGAAAGCACGAGATGCTTCTATGCAGGATGATACATGTGCTTCAGTTCAGGAACTTCCTACATCAGAGGAGAACACCAACCAAAGAAACCTCGAGCGACATGAAACCAAAGTAGAAAGTGATGAAGAACTAAGTACAGACAGCGAAAACCAGCCAGAAGTCAAGGAAAATACAATACATAATAAACGACTCACACCTTTAGGTCGGCCACCACTGTCACCACTTACCAAACTAGATAAGAAACTTGGAGATATACATATATCTCCACTGCGGAGAAGCATAGAAGGAGTACCAAAGTCAAAATTAGTCCATCATACTTCTGACAAAGATGTGTTTGATAGAATGCCATTTGAGAAACATAAAATAATGTTCAAACAACATTCTGAGAATATAGATCTTAAGATGAACGTACAAAGTCCCGAGGAGGAGAATGTCAAGCTGTTGTTTGGAAGTAAGACTGATAAGGGATTGCCATTGACTGGTAAAGGCAATATGTTTTTAAAGCTATCGAAATCTGATCTACCAAGTCCAGAGACTGAGAAGTCTCTACCATTAGACTCAGTCACAAAGAGCGATCCACCCAAAGGTATCCTCAGGGAATCCATCTCCGATATTATTAATCGGAGACCTGATAATGTGGGTAGACAAACTGCTAGTTTTGACGAAGACAAGAAGTGTGTCCGGTTCCAGCTGGAGGACGCGGCGGAGTCGGCGGCCAGCCCGGGCTCCAACAGCTCCTCGGAACAGAACGAGCCGCAGAGCTCCGTGGTGTCCGCCCGCCCTCCCCTGCCGCCCAGACCAGCCAAGCCTTCGTCGGACAAGGACTCTACTGCAGGTTCAGCGACAGCGTCGGCGGAGTCGGAGGTCGCATCCGGGCCGGGCCGCCGAGTAGTCCGGCCGCCGCCCACCGACTACATCCGGCCCCAGCTCTTCCAGAAGCACTTCCGCAAGATAGCGGACATACTGGCCGACCCCGCGCCCGACCCCGCCCCCGACCTCGCCCCCGACGGACCCAGGCCCAGGTCGCCGATGGTGCCGCTCACTAACAAGATATCGATAAATCTAATGGAAAGTATCGAATCTGAAACCTCGATAGACTCACCAGACAGAGAGTTCGCCAACTTGGACCTCAACGACCTCAACGACGCGAACGAGCTGAACGACCTCGACGACTCAAACGAACAGAAAGACCGAAGCGTCTCGAAGGACGATAGCGACCGCGACTCGGGAATGTTGAGGTCTCCTCCCGCGGAGCGCGCCGGGCGCGGACAGCCCGCGCACTCAGACGAGCTCCGGGACACTTCTGAGCCCGACCGCTGCCAACCATCAAATGAAGGTTTAGCTAAAAATAAATCAAGCTCAGAAACATCCCACACGGCCGCCGCTCCCAGCCCCGCCCCGAACTCCGCCCGAGACATCAAACCCCTCAAGTATGATTTTGCAAAACCTTGGACCCCCTTATCAAGTTTCCAACCGCAGAAAGCTGTGATAGCTCCCCAAGTTAAGACCTCGGAGTCCTCGTCTAGCCTAAAAGTTGCCAGTCCGAGGCTGGATGGAGTCATCTTGTCTAATGGGAATACCAGATCCGACAACGTAATGGTCGTGTACCAGTTCGAAACGCAACAGAACTCTTTGTCGAAACCGCTCAGGTCGCCACTGATACCCGACATGGGGACTAGAGACTTCATAGAACGGCACAAGAGCGACGAGAGAAGGAGATTAGAGTTGGCCTTACAGAAAGAGTTGGAGAGTATAAGAGTGGAGTGGTCATTGAGGGAGAAAAAGCTGAGAGCCGAGCTAAATGAGGAATTGAGAGAGTCTGAAGAGAGGTTTGTTGCGGAGAAGAGGGTCAGGCTGAACGAACAGGCGGAGAGACATCGGAGGGAGCTGGAAGAGACGCTCGCGTCCAACGAGCGCCTGCACCGCGCCGCGCTGGAGGCGGCCCGCGCGCAGCTGGAGGCGCGGCGCACAGCGGACGTCCACGCGGCGGAGAACGAGCACGCCAGGGACATGGAGAGGCTCAAGGAGACCTACCGGGACAAGCGCGACCAGCTCCGCCGGATGTTGGAAGCAGAGCACGAACAGTGCTTGGAGGAGGTCCGGGATCAGTTCGCGTCGCAAGTAGAGCGGGAGCGGGCGCGGCTCCGGGACGAGCAGCGCAGCGCCGTGCTGTGTGCGCGGGAGCAGCACCGCGCCGCGCTGGACGCGCTGCGACAGGACTACCGGGCGCAGGTGGAGCGCGTGCGCGGGGAGCACCGCTGCCTGGCGGAGGAGGCTCGGCGGCGGCTGGCGGCGCAGCGGCAGCCCGCGCCCGACAAGTACCGCGCGCTCAAGGACAAGTACACCAGGCTCAAGCACGACGTCAAGATGTCGATAGAGCGGCGCAACAAGCGGCGCGAGGCCAGCGCCACCACGGGCTCCGAGACCGACCCGTCCGCCTCGCACCGCACCGCGCGCTCCGCCGACAGAAGCAGAGGCGGGCGCCCCCGGACGGACGACGAGCCGGGGAACCGCAACAGCACCTCGGCGTCCGACGGCCCCGCGCCCCGCAGCGCCGCCGTCCCGGGCCCCGTGAGTGCGCCCCCCACCGTCTCGGGGCTTCCTTACTTACTTATCCAAATTATACATTTGTTAGCTGGTCCGAAAATACAGAAAGGAGTTTTTTTTTATTTGTGGTACATTACTGTAGGGCGCGGCCGCAGGAGGAGCTTCGCGAGGCTCAAGTCGGCTTCCACCTCGCGCCTGCACTGCTCGCCGCGGTGGGCGGGCCCGCTGGAGAGCGTGCGGCAGCAGCTGCGCGCCCTGGACGCGCTGGACGCGCTGGGCTCCCCGGACCAGCCGGCGTACGCGCTGCCCTACCCGTTCCGCGCGGGGGAGGCGGCGCGGCCGGAGCTGGAGTTCGTGCGGCACCGCGCGCTGGTGGAGCGCGAGGGCGTGCGGCGCGCGCGCGGCGTGCTGCGGGCTCGCCGGGCCGCGCTGCTGCAGGAGGGGCGCGAGGGTCGGGAGGAGGAGGAGCGCACGGAGCTGGAGGTGTCGCTGCACCGCGCGCGCGCCGTGCTGGGCGAGAAGGAGATCCGGCTGCGGCACATCGAGCGCACGCTCGCCGCCCTCGCCGCGCCCCCGCCGCGCCCCCCGCCGCGCCCCCCGCCGCGCCCCCCGCCGCGCCCCCCGCCGGCACCCCCCTGCAGAACGGAACGACATACGGCTGCAGCGCGCGGGACGACAGTGCAAGCGACGCGTCCTCGCCCTTCGATGACGTCACGCCGCCCGGTGACGTCACGCCGCCCGCCGGCCCCCCGGGGAGCAGCTCGTGCCGCGCCGCGCCGGCCCCCCGCGCGCGCTCGCCCGTGA
Protein
MSSPSAVVCREVFDENSQPSVEEICEYAQQLGIDPESESHLLPLARDGLMQALPHQWKAYYDEKLQTHYYYNEETKNTQWEHPLDNLYRELVKKARDASMQDDTCASVQELPTSEENTNQRNLERHETKVESDEELSTDSENQPEVKENTIHNKRLTPLGRPPLSPLTKLDKKLGDIHISPLRRSIEGVPKSKLVHHTSDKDVFDRMPFEKHKIMFKQHSENIDLKMNVQSPEEENVKLLFGSKTDKGLPLTGKGNMFLKLSKSDLPSPETEKSLPLDSVTKSDPPKGILRESISDIINRRPDNVGRQTASFDEDKKCVRFQLEDAAESAASPGSNSSSEQNEPQSSVVSARPPLPPRPAKPSSDKDSTAGSATASAESEVASGPGRRVVRPPPTDYIRPQLFQKHFRKIADILADPAPDPAPDLAPDGPRPRSPMVPLTNKISINLMESIESETSIDSPDREFANLDLNDLNDANELNDLDDSNEQKDRSVSKDDSDRDSGMLRSPPAERAGRGQPAHSDELRDTSEPDRCQPSNEGLAKNKSSSETSHTAAAPSPAPNSARDIKPLKYDFAKPWTPLSSFQPQKAVIAPQVKTSESSSSLKVASPRLDGVILSNGNTRSDNVMVVYQFETQQNSLSKPLRSPLIPDMGTRDFIERHKSDERRRLELALQKELESIRVEWSLREKKLRAELNEELRESEERFVAEKRVRLNEQAERHRRELEETLASNERLHRAALEAARAQLEARRTADVHAAENEHARDMERLKETYRDKRDQLRRMLEAEHEQCLEEVRDQFASQVERERARLRDEQRSAVLCAREQHRAALDALRQDYRAQVERVRGEHRCLAEEARRRLAAQRQPAPDKYRALKDKYTRLKHDVKMSIERRNKRREASATTGSETDPSASHRTARSADRSRGGRPRTDDEPGNRNSTSASDGPAPRSAAVPGPVSAPPTVSGLPYLLIQIIHLLAGPKIQKGVFFYLWYITVGRGRRRSFARLKSASTSRLHCSPRWAGPLESVRQQLRALDALDALGSPDQPAYALPYPFRAGEAARPELEFVRHRALVEREGVRRARGVLRARRAALLQEGREGREEEERTELEVSLHRARAVLGEKEIRLRHIERTLAALAAPPPRPPPRPPPRPPPRPPPAPPCRTERHTAAARGTTVQATRPRPSMTSRRPVTSRRPPAPRGAARAAPRRPPARARP
Summary
Uniprot
ProteinModelPortal
Ontologies
GO
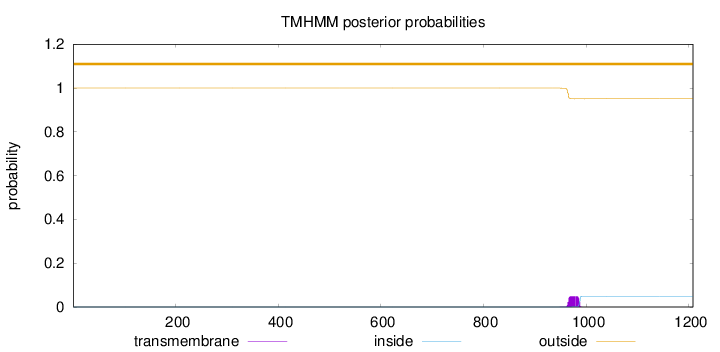
Topology
Length:
1208
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
1.11609
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00000
outside
1 - 1208
Population Genetic Test Statistics
Pi
15.309595
Theta
18.934111
Tajima's D
-0.826671
CLR
2.731392
CSRT
0.167891605419729
Interpretation
Uncertain
