Gene
KWMTBOMO10648 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA014430
Annotation
endonuclease_and_reverse_transcriptase-like_protein_[Bombyx_mori]
Location in the cell
Mitochondrial Reliability : 1.099 Nuclear Reliability : 1.346 PlasmaMembrane Reliability : 1.642
Sequence
CDS
ATGTTAAACTTCTATCGGCGTTTCATTCCAAACGCTGCTGCGGCTCAAGCACCTCTCCATGGCATGCTGTCGGGATCAAAGGTCAAAGGATCACACCCACTTACCTGGACGCCGGAACTTCTCGAAGCTTTCAACACCTGTAAAGCAAGTATAGCTAGAAGTACTCTCCTCGCTCACCCAGCCATGAACGCGCCGCTCGCTCTCGTGACAGATGCCTCAAATTCTGCCTTGGGCGCGGTGCTACAGCAGTCAGTGGAAGGACAATGGCAACCACTCGCCTTCTTCTCGAAGAAACTTAAAAAAGCTCAGCAGCTGTACAGCGCCTATGACCGAGAGTTGCTCGCTATATACGAGGGCGTTAAACATTTCCGTTTTATGGTTGAAGGCAGACACTTCGTCATTTATACGGATCATAAACCCATCACATACACCTTTTATCAGAATAGCCAGAAGTGCTCGCCCAGACAGTTTAACCACCTCGATTTCATGTCTCAATTCACCACAGACATAAGGTTTATATCGCGGAAGGATAATATACCTGCGGACACTTTGACGCGCATTGAAGCCGTATCATCGCCACCGGACTTACAACAGCTTGCTCGTTCACAGGAGAATGACAACGAGCTCCAGGAACTCCTCTCAAAGCGCTCATCTTCTTCGTTAAAGATGGAACAGATACCTATACCTGGAACGAACGTTACTTTATACTGTGACGTCACTCTGTCGAGGCCTCGTCCTTTTATAACAAAGGAGTTGAGTCGGCAGGTCTTCAACTCAATTCATACCATGAGTCACCCTGGTACGAAAGCGACAACCAAGATGGTAATGAGTAGGTTTATTTGGCCTTCAGCTCGATGGGATTGTCGCACTTGGACTCGGGCCTGCGAAGCCTGTCAGAAATCGAAGATCCACAGGCATATTTCATCTCCGCTGGGTGATTTCCAGTTACCGCAATCACGTTTCAGCCACGTACACATTGATTTGATTGGACCGCTACCGTCTTCGAATGACTACAAGTACTGTCTTACAGCAGTAGACAGGTTCACAAGATGGCCAGAGCTAATCGAGAAGGGTCGCGAATACAACGTTCCATTCATCATGTGTTTCATCGACTACAGCAAGGCTTTTGATTGTGTCAACTGGAGTTCCTTGTGGAAGGTATTGAATGTTCCTGGTGTACCCAATCATCTGATAGTGCTGGTACAGAGCCTGTATATCTACAGTCAGGGAGTTGTCAGAATCGATGAAGCTGTGTCCCAACCGTTCTGTTTTGGAAAAGGTGTCCGGCAAGGTTGCATACTGTCACCTATACTTTTTGATGCATATGGAGAGTACATCTTGCGGCAGACTTGTGAAGATTGGTCGGGAGATGTGCGCATTGGTGGAGCTCATATTACAAATCTCCGATATGCCGATGACACGACCCTGCTAGCTGCAGACGAATCTGAAATGTCTTCTTCAGCAAAATGGAACCTACAGAAGATCTGGAAGAATAGAGGGATAGGCCTGAAAACTAAAACCAGACTGGTGCGGACTCTTGTTTTCTCTATCTTCTTGTATGGAGCTGAGACATGGACGTTGAAAGCAGCAGACCGAATGCGCATCGATACTTTCGAAATGTGGTGTTGGAGACGCATGCTAAGAATTCCGTGGACAGCCTTCCGGACTAACGTGTCGATATTGAAGCAACTGGGCATCAAAATCAGACTGTCTACTGTATGGAAAGTTGAAGGCAACAGATCTAGAGGCCGCAGCCATACTCGTTGGTCCGATCAGATCCGCACCGCTTTGGACAGTACAGTGTACAGCGCGCTGCATGACGCCGTGGACAGAGGGAAAGTGGAAAAAGATCCTAAGATTGAAGCTCATGGTATAAAAGACACCGAAGTGATGACTGACAACATTCTACTCGAGGGAACCTTTAAACTGGTAGTAGCCATGAAGGTCTTCGCAGCAGTACTGATGGCGTTGGCGGCCGTGGTCGTGGCAGAAGAGCCCATCGAACTCGACTACCACAACAAGATCGGTATCCCCCGGGCCGAGAGTCTTAGACGCGCCGAGGAAGCCGCTGACTTCGACGGTACCAGGATTGTGGGTGGTTCTGCCGCCAACGCTGGTGCTCACCCCCATCTTGTAAACGATCAAAACTTGTGTCTGGGGCGAGTCTCCGAATGGGGTGAATTGAACTTGGTTCAATTCAACCCGATAAAGACACAAGTTTGCGCGTTCACTGCGAAGAAGGACCCCTTTGTCATGGCGCCGCAATTCCAAGGAGTATCCCTGCAACCTTCCGAGAGTATCGGGATACTTGGGGTCGACATTTCGAGCGATGTCCAGTTTCGGAGTCATTTGGAAGGCAAAGCCAAGTTGGCGTCCAAAATGCTGGGAGTCCTCAACAGAGCGAAGCGGTTCTTAACGCCTGGACAAAGACTTTTGCTTTATAAAGCACAAGTCCGGCCTCGCATGGAGTGCTGCTCCCATCTCTGGGCCGGGGCTCCCAAATACCAGCTTCTTCCATTTGACTCCATACAGAGGAGGGCCGTTCGGATTGTCGATAATCCCATTCTCTCGGATCGTTTGGAGCCTCTGGGTCTGCGGAGGGACTTCGGTTCCCTCTGTATTTTGTACCGTATGTTCCATGGGGAGTGCTCTGAGGAATTGTTCGAGATGATACCAGCATCTCGTTTTTACCATCGCACCGCCCGCCACCGGAGTAGAGTTCATCCATACTACCTGGAGCCACTGCGGTCATCCACAGTTGGACTTGTGATCGCACTGACGAATGGCAGAACTTCCGTCTGCGGAGCTTCCTTACTGACCAACACCCGCTCCGTGACCGCGGCTCACTGCTGGAGGACCAGGAACGCCCAGGGTCGTCAGATCACCCTCGCTTTTGGCACAGCTAACATCTTCTCCGGAGGCACCAGGGTCACCACCTCCAATGTCCAGATGCACGGCAGCTACAACATGAACAACCTCAACAACGACGTCGCCGTCATCAACCACAACCACGTTGGCTTCAACAACAACATCCAGCGCATCAACCTAGCCAGTGGAAGCAACAACTTTGCTGGTACTTGGGCCTGGGCTGCCGGCTTCGGGAGGACCTCCGATGCTGCTTCGGGAGCCAACAACCAACAAAAACGCCAAGTCAGCCTCCAGGTCATTACCAACGCCGTCTGCGCCCGCACGTTTGGAAACACTGTGATCATTGGCTCCACTCTCTGTGCTGACGGCTCTAACGGTCGCAGCGTCTGCAGCGGAGACTCCGGCGGCCCTCTCACCATCGGCAGCGGCGGAGGCCGTCAGCTGGCGGCTCCCCATTCCACATTTAATGTGGATTTCAGCAATGTCAGGGGCCTACATAGCAACCTTGACGCCGTACACCACCACCTTGAGACGGCGCAGCCTGCCCTGCTTTTTTTAACGGAGACGCAGATATCTGCTCCGGATGATACCTCATACCTTGAATACCCCGGCTACGTATTGGAGCACAACTTCCTGCGTAAAGCCGGGGTGTGCGTATTCGTCCGGGCTGATGTCTGTTGTCGCCGTCTTCGGGGCCTCGAACAACGGGACCTGTCCCTCTTGTGGCTGCGCGTAGATCACGGGGGCCGTAGCCGAATCTACGCGTGCCTGTACAGGTCCCACAGCAGTGATGCAGGTTCAGCTCTATTTGAGCATGTGCAAGAGGGGACTAACCGCGTGCTTGAGCAGTACCCATCTGCGGAGGTGGTGGTTCTTGGAGACTTTAACGCTCACCACCAAGAGTGGTTGGGGTCCAGAACCACTGACCTCCCGGGTCGGACTGCCTACGATTTCGCCTTGGCCTACGGCTTCTCCCAGCTGGTGACACAGCCCACCCGTGTCCCAGATATCGAGGGGCACGAGCCTTCTTTGTTGGACCTTCTGCTGACCACAGATCCGGCCGGATACAGTGTGGTGGTCGACGCTCCGCTTGGATCGTCTGATCACTGCCTTATTCGTGCTGCCGTTCCACTCTCTCGTCCTGATCGTCGAACGACGACCGGGTATCGAAGAGTTTGGCGGTATATGTCAGCAGATTGGGATGGATTGCGTGAATTTTACGCATCCTACCCATGGGGGCGGTTCTGCTTTTCCTCTGCTGATCCTGACGTCTGTGCGGACCGTCTTAAAGACGTGGTGCTCCAGGGGATGGAATTGTTTATTCCCTCCTCTGAAGTGCCCGTTGGGGGTCGCAGCAGACCCTGGTATAACAATGCCAGCAGGGATGCTGCACACCTCAAGCGGTCCGCATACGTGGCATGGGATAATGCCAGGAGACGTCAGGACCCTAACATCTCAGAGGAAAGGCGGAAATATAACGCCGCTTCCAGGTCCTACAAGAAGGTTATTGCCAAGGCGAAGTCGGAGCACGTTGCTAGAATTGGCGAGCGACTGAAGAGCTATCCCTCTGGGAGCCGTGCTTTTTGGTCGCTCGCTAAAGCTGCAGAAGGAAACTTTTGCAGGTCTAGTCTCCCACCACTACGCAAGTCCGATGACAGTCTGGCCCATAGTGCGAAAGAGAAGGCTGACCTTCTGGTCAAACTCTTCGCCTCGAACTCGACTGTGGACGACGGGGGTGCCACACCACCGAACATCCTCCGGTGTGATAGTTCCCTGCCCGAGATCTGCTTTACACAGTGTGCAGTCAGGCGGGAACTCCGACTCCTGGACGTCCATAAGTCGAGCGGGCCAGACGGCATCCCTGCAGTGGTTCTGAAAACGTGCGCCCCTGAGCTGACGCCTGCGCTAACGCGTTTGTATCGCCTCTCTTATTGCACTAACAGGGTTCCGTCTTCATGGAAGACTGCCCACGTCCACCCTATCCCCAAGAAGGGTGACCGGTCGGACCCATCGAGCTATAGGCCTATCGCGATAACTTCCTTGCTTTCCAAGGTGATGGAGCGAATAATTAATATACAACTCCTGAAGTATCTGGAGGATCGCCAGCTGATCAGTGACCGACAGTACGGTTTCCGTCACGGTCGCTCAGCTGGCGATCTTCTTGTATACCTTACTCACAGGTGGGCTGAAGCCTTGGAAAGCAAGGGCGAGGCTCTTGCTGTGAGCCTTGATATCGCGAAGGCCTTCGACAGGGTCTGGCATAGGGCACTTCTATCGAAGTTACCATCTTACGGAATCCCCGAGGGTCTCTGCAAGTGGATCGCTAGCTTTTTGGATGGGCGGAGCATCACGGTCGTTGTAGACGGTGACTGTTCTGATACCATGACCATTAACGCTGGCGTTCCACAAGGTTCGGTGCTCTCCCCCACGCTTTTCATCCTGTATATCAATGACATGCTGTCTATTGATGGCATGCATTGCTATGCAGATGACAGCACGGGGGATGCGCGATATATCGGCCATCAGAGTCTCTCTCGGAGCGTGGTGCAAGAGAGACGATCAAAACTTGTGTCTGAAGTGGAGAACTCTCTGGGGCGAGTCTCCGAATGGGGTGAATTGAACTTGGTTCAATTCAACCCGATAAAGACACAAGTTTGCGCGTTCACTGCGAAGAAGGACCCCTTTGTCATGGCGCCGCAATTCCAAGGAGTATCCCTGCAACCTTCCGAGAGTATCGGGATACTTGGGGTCGACATTTCGAGCGATGTCCAGTTTCGGAGTCATTTGGAAGGCAAAGCCAAGTTGGCGTCCAAAATGCTGGGAGTCCTCAACAGAGCGAAGCGGTACTTCACGCCTGGACAAAGACTTTTGCTTTATAAAGCACAAGTCCGGCCTCGCATGGAGTACTGCTCCCATCTCTGGGCTGGGGCTCCCAAATACCAGCTTCTTCCATTTGACTCCATACAGAGGAGGGCCGTTCGGATTGTCGATAATCCCATTCTCTCGGATCGTTTGGAGCCTCTGGGTCTGCGGAGGGACTTCGGTTCCCTCTGTATTTTGTACCGTATGTTCCATGGGGAGTGCTCTGAGGAATTGTTCGAGATGATACCAGCATCTCGTTTTTACCATCGCACCGCCCGCCACCGGAGTAGAGTTCATCCATACTACCTGGAGCCACTGCGGTCATCCACAGTGCGTTTCCAGAGATCTTTTTTGCCACGTACCATCCGGCTATGGAATGAGCTCCCCTCCACGGTGTTTCCCGAGCGCTATGACATGTCCTTCTTCAAACGAGGCTTGTGGAGAGTATTAAGCGGTAGGCAGCGGCTTGGCTCTGCCCCTGGCATTGCTGAAGTCCATGGGCGACGGTAA
Protein
MLNFYRRFIPNAAAAQAPLHGMLSGSKVKGSHPLTWTPELLEAFNTCKASIARSTLLAHPAMNAPLALVTDASNSALGAVLQQSVEGQWQPLAFFSKKLKKAQQLYSAYDRELLAIYEGVKHFRFMVEGRHFVIYTDHKPITYTFYQNSQKCSPRQFNHLDFMSQFTTDIRFISRKDNIPADTLTRIEAVSSPPDLQQLARSQENDNELQELLSKRSSSSLKMEQIPIPGTNVTLYCDVTLSRPRPFITKELSRQVFNSIHTMSHPGTKATTKMVMSRFIWPSARWDCRTWTRACEACQKSKIHRHISSPLGDFQLPQSRFSHVHIDLIGPLPSSNDYKYCLTAVDRFTRWPELIEKGREYNVPFIMCFIDYSKAFDCVNWSSLWKVLNVPGVPNHLIVLVQSLYIYSQGVVRIDEAVSQPFCFGKGVRQGCILSPILFDAYGEYILRQTCEDWSGDVRIGGAHITNLRYADDTTLLAADESEMSSSAKWNLQKIWKNRGIGLKTKTRLVRTLVFSIFLYGAETWTLKAADRMRIDTFEMWCWRRMLRIPWTAFRTNVSILKQLGIKIRLSTVWKVEGNRSRGRSHTRWSDQIRTALDSTVYSALHDAVDRGKVEKDPKIEAHGIKDTEVMTDNILLEGTFKLVVAMKVFAAVLMALAAVVVAEEPIELDYHNKIGIPRAESLRRAEEAADFDGTRIVGGSAANAGAHPHLVNDQNLCLGRVSEWGELNLVQFNPIKTQVCAFTAKKDPFVMAPQFQGVSLQPSESIGILGVDISSDVQFRSHLEGKAKLASKMLGVLNRAKRFLTPGQRLLLYKAQVRPRMECCSHLWAGAPKYQLLPFDSIQRRAVRIVDNPILSDRLEPLGLRRDFGSLCILYRMFHGECSEELFEMIPASRFYHRTARHRSRVHPYYLEPLRSSTVGLVIALTNGRTSVCGASLLTNTRSVTAAHCWRTRNAQGRQITLAFGTANIFSGGTRVTTSNVQMHGSYNMNNLNNDVAVINHNHVGFNNNIQRINLASGSNNFAGTWAWAAGFGRTSDAASGANNQQKRQVSLQVITNAVCARTFGNTVIIGSTLCADGSNGRSVCSGDSGGPLTIGSGGGRQLAAPHSTFNVDFSNVRGLHSNLDAVHHHLETAQPALLFLTETQISAPDDTSYLEYPGYVLEHNFLRKAGVCVFVRADVCCRRLRGLEQRDLSLLWLRVDHGGRSRIYACLYRSHSSDAGSALFEHVQEGTNRVLEQYPSAEVVVLGDFNAHHQEWLGSRTTDLPGRTAYDFALAYGFSQLVTQPTRVPDIEGHEPSLLDLLLTTDPAGYSVVVDAPLGSSDHCLIRAAVPLSRPDRRTTTGYRRVWRYMSADWDGLREFYASYPWGRFCFSSADPDVCADRLKDVVLQGMELFIPSSEVPVGGRSRPWYNNASRDAAHLKRSAYVAWDNARRRQDPNISEERRKYNAASRSYKKVIAKAKSEHVARIGERLKSYPSGSRAFWSLAKAAEGNFCRSSLPPLRKSDDSLAHSAKEKADLLVKLFASNSTVDDGGATPPNILRCDSSLPEICFTQCAVRRELRLLDVHKSSGPDGIPAVVLKTCAPELTPALTRLYRLSYCTNRVPSSWKTAHVHPIPKKGDRSDPSSYRPIAITSLLSKVMERIINIQLLKYLEDRQLISDRQYGFRHGRSAGDLLVYLTHRWAEALESKGEALAVSLDIAKAFDRVWHRALLSKLPSYGIPEGLCKWIASFLDGRSITVVVDGDCSDTMTINAGVPQGSVLSPTLFILYINDMLSIDGMHCYADDSTGDARYIGHQSLSRSVVQERRSKLVSEVENSLGRVSEWGELNLVQFNPIKTQVCAFTAKKDPFVMAPQFQGVSLQPSESIGILGVDISSDVQFRSHLEGKAKLASKMLGVLNRAKRYFTPGQRLLLYKAQVRPRMEYCSHLWAGAPKYQLLPFDSIQRRAVRIVDNPILSDRLEPLGLRRDFGSLCILYRMFHGECSEELFEMIPASRFYHRTARHRSRVHPYYLEPLRSSTVRFQRSFLPRTIRLWNELPSTVFPERYDMSFFKRGLWRVLSGRQRLGSAPGIAEVHGRR
Summary
Uniprot
ProteinModelPortal
PDB
4OL8
E-value=2.41888e-18,
Score=233
Ontologies
GO
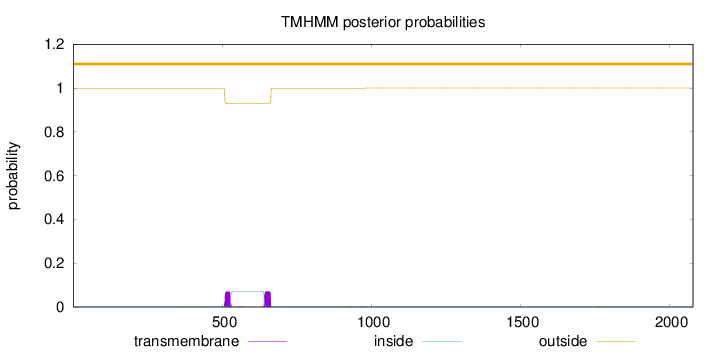
Topology
Length:
2079
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
3.00147000000001
Exp number, first 60 AAs:
0.00184
Total prob of N-in:
0.00156
outside
1 - 2079
Population Genetic Test Statistics
Pi
197.050967
Theta
159.114514
Tajima's D
1.1073
CLR
0.000588
CSRT
0.689515524223789
Interpretation
Uncertain
