Gene
KWMTBOMO10400
Annotation
endonuclease_and_reverse_transcriptase-like_protein_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 2.506
Sequence
CDS
ATGAATTCCTTTACAAAAACAGAAAATATAAACAGACTCAGAAGGAACCTGAAAGGAAGGGCAAAGGAAGCCGTTGACGGATTACTTATAACGAACGCTGATCCGTCCGACGTCATAAGAAGTCTAGAAGCGCGATTCGGAAGACCGGAAACAATAGCCATAACGGAGTTAGACACGCTACGAGCTCTGCCACGATTAACAGAAACACCAAGAGACATTTGTATATTCTCCAGTAAGGTGACCAACGCCGTAGCTACGCTTCGTGCATTAAATTGCACACATTACTTATATAATCCGGAAACTACCAAAACAATGTTAGAAAAACTCACACCAACACTACGTTACCGATACTACGACTTCACCGCGGTACAACCGAAGGAGGATCCGGATCTGATTAAATTTGAAAAATTCATGAAAAGAGAAGCCGAACTGTGCAGCCCTTATGCACAGCCTGAACAGGCGGGGCACTACTCGCAGCCCGCACAACACAACAGACGCACACAGAACGTGCACATAGTCAGTGAGAAGCCATCACTAGCTAAATGTCCGGTATGTATCAACACTGAACACACCACAACAGACTGCTACATATTCAAGAAGGCAGACTCAAACACAAGATGGGACATCGCTAAGAATAAACACCTGTGTTTCCGATGTCTCAAGTATAGAAATAAAACCCACCACTGTAAACCGAAGACGTGTGGCATTAATGATTGCAAATATACTCACAACAAGATGCTACACTTCGACAGAAAAATTGAAAAAACAGACAACAGTGACAAGGAAACAACAGAGAACATTAATTCTGCTTGGACCGGAAAACAGAAACAGTCCTATTTGAAAATAATCCCAGTCCAAGTACAAGGACCGATAGGCACGGTTGATACATACGCGCTGCTCGACGATGGATCAACGGTAACACTGATAGACGAAATCATCTGCAAGAAGACTGGAATAACAGGACTAATCGATCCGTTACACATACAGGCGATTAACAACATAAAATCAACGGAAACAAGGTCAAGAAGAGTCAACCTCACGCTCAGAGGCCTCAACAGTCGAAAAGAAATAATACAAGCGAGAACAGTTAACGATCTACAAGTAACAGCACAAAAAATACCAAAGGAACAGATAGATGAGTATTCGCACCTACGAGACATCAGTGACATCATCACGTACGAGAACGCGAAACCTGGAATCCTGATTGGCCAAGACAACTGGCACATGTTACTAACTTCGAAAGTTAGACGAGGCAACAGGAATCAGCCAATAGCGTCACTGACACCTCTAGGCTGGGTATTGCATGGAGGTCGCACTCGTACCCTAGGCCACCACATAAACTACATAAATCATGCTAGCGAAACCCAGGAAGATGATAAAATAGAAAATCTGGTAAAACAGTATTTCGCTATGGATGCGCTATGCATCACACCAAGAAGACCAAAAACAGACCCAAAGGAACAGGCGCTTCGCATCCTCAACAGAAATACAGTCCACACAACAGATGGAAGATACGAAACCGCTCTGCTCTGGAAAACAGATAATGTCAGTCTACCAGACAACTACAATAACTCGTTAAAGCGACTGATAAATATAGAAAACAAACTTGATCGTAATCCGGAACTGAAACAGAAATACACAGAACAGATGGAAGCACTCGTCGCGAAAGGCTACGCCGAGCCCGCTCCAAACACAAAAACAGAGAACAGAACGTGGTACCTACCTCACTTCGCCGTCGCGAATCCCCTGAAGCCGGAAAAACTCCGAGTTGTCCACGGCGCCGCCGCCAGAACAGGAGGGGTAGCTTTGAATGATATGCTGCTTAAGGGACCGGACCTACTCCAATCACTACCAGGAGTGATAATGCGATTTAGACAGCATAATATAGCAGTAACAGCAGACATTTGGGGGTTGATTGCTTCCCGCTTCCGTAGCAATGTAAGGGGTCTACATAGCAACCTCGACGCCGTACACCACCATCTTGAGACGGCGCAGCCTGCCCTTCTTTTTCTGACGGAGACGCAGATATCTGCTCCGGATGATACTTCGTACCTTGAATACCCCGGCTACGTATTGGAGCACAACTTCCTGCGTAAAGCCGGGGTGTGTGTATTCGTCCGGGCTGATGTCTGTTGTCGCCGTCTACGAAGCCTCGAACAACGGGACCTGTCCCTCTTGTGGCTGCGCGTAGATCACGGGGGCTGTACCCGAGTCTACGCGTGCCTGTACAGGTCCCACAGCAGTGATGCAGGTTCAGCTCTGATAGAGCATGTGCAAGAGGGGACTAACCGCGTGCTTGAGCAGTACCCATCTGCGGAGGTGGTGGTTCTTGGAGACTTTAACGCTCATCACCAAGAGTGGTTGGGGTCCAGAACCACTGACCTCCCGGGTCGGACTGCCTACGATTTCGCCTTGGCCTACGGCCTCTCCCAGCTGGTGACACAGCCCACCCGTGTCCCAGATATTGAGGGGCACGAGCCTTCTCTGTTGGACCTTCTGCTGACCACCGATCCAGCCGGATACAGTGTGGTGGTCGACGCTCCACTTGGATCGTCTGATCACTGCCTTATCCGTGCTGCCACACCACTCTCTCGTCCTAGTCGTCGAACGACGACCAGGTATCGAAGAGTTTGGCAGTATTTGTCAGCAGATTGGGATGGATTGCGTGAGTTTTACGCATCCTACCCATGGGGGCGGTTCTGCTTTTCCTCTGCTGATCCTGACGTCTGTGCGGACCGTCTTAAAGACGTGGTGCTCCAGGGGATGGAATTGTTTATTCCCTCCTCTGAAGTGCCCGTTGGGGGTCGCAGCAGACCCTGGTATAACAATGCCAGCAGGGATGCTGCACACCTCAAGCGGTCCGCATACGTTGCATGGGATGATGCTAGGAGACGTCGGGATCCTAACATCTCAGAGGAAAGGCGGAAATATAACGCCGCTTCCAGGTCCTACAAGAAGGTTATTGCCAGGGCGAAATCGGAGCACGTTGCTAGAATTGGCGAGCGACTGAAGAGCTATCCCTCTGGGAGCCGTGCTTTTTGGTCGCTCGCCAAAGCTGCAGAAGGTAACTTTTGCAGGTCTAGTCTCCCACCACTACGCAAGTCCGATGACAGTCTGGCCCATAGTGCGAAAGAGAAGGCTGACCTTCTGGTCAAACTCTTCGCCTCGAACTCGACTGTGGACGACGGGGGTGCCACACCACCGAACATCCTCCGGTGTGATAGTTCCCTGCCGGAGATCTGCTTTACACAGTGTGCAGTCAGGCGGGAACTCCGACTCCTGGACGTCCATAAGTCGAGCGGGCCAGACGGCATCCCTGCAGTGGTTCTGAAAACGTGCGCCCCTGAGCTGACGCCTGCGCTAACGCGTTTGTATCGCCTCTCTTATTGCGCTAACAGGGTTCCGTCTTCATGGAAGACTGCCCACGTCCACCCTATCCCCAAGAAGGGTGACCGGTCGGACCCATCGAGCTACAGGCCTATCGCGATAACTTCCTTGCTTTCCAAGGTGATGGAGCGAATAATTAATATACAACTCCTGAAGTATCTGGAGGATCGCCAGCTGATCAGTGACCGACAGTACGGTTTCCGTCACGGTCGCTCAGCTGGCGATCTTCTTGTATACCTTACTCACAGGTGGGCTGAAGCCTTGGAGAGCAAGGGCGAGGCTCTTGCTGTGAGCCTTGATATTGCGAAGGCCTTCGACAGGGTCTGGCATAGGGCACTTCTGTCGAAGCTACCATCTTACGGAATCCCCGAGGGTCTCTGCAAGTGGATCGCTAGCTTTTTGGATGGGCGGAGCATCACGGTCGTTGTAGACGGTGACTGTTCTGATACCATGACCATTAACGCTGGCGTTCCACAAGGTTCGGTGCTCTCCCCCACGCTTTTCATCCTGTATATCAATGACATGCTGTCTATTGATGGCATGCATTGCTATGCGGATGACAGCACGGGGGATGCGCGATATATCGGCCATCAGAGTCTCTCTCGGAGCGTGGTGCAAGAGAGACGATCAAAACTTGTGTCTGAAGTGGAGAACTCTCTGGGGCGAGTCTCCAAATGGGGTGAATTGAACTTGGTTCAATTCAACCCGTTAAAGACACAAGTTTGCGCGTTCACTGCGAAGAAGGACCCCTTTGTCATGGCACCGCAATTCCAAGGAGTATCCCTGCAACCTTCCGAGAGTATTGGGATACTTGGGGTCGACATTTCGAGCGATGTCCAGTTTCGGAGTCATTTGGAAGGCAAAGCCAAGTTGGCGTCCAAAATGCTGGGAGTCCTCAACAGAGCGAAGCGGTACTTCACGCCTGGACAAAGGCTTTTGCTTTATAAAGCACAAGTCCGGCCTCGCGTGGAGTACTGCTCCCATCTCTGGGCCGGGGCTCCCAAATACCAGCTTCTTCCATTTGACTCCATACAGAGGAGGGCCGTTCGGATTGTCGATAATCCCGGTCTCACGGATCGTTTGGAACCTCTGGGTCTGCGGAGGGACTTCGGTTCCCTCTGTATTTTGTACCGTATGTTCCATGGGGAGTGCTCTGAGGAATTGTTCGAGATGATACCGGCATCTCGTTTTTACCATCGCACCGCCCGCCACCGGAGTAGAGTTCATCCATACTACCTGGAGCCACTGCGGTCATCCACAGTGCGTTTCCAGAGGTCTTTTTTGCCACGTACCATCCGGCTATGGAATGAGCTCCCCTCCACGGTGTTTCCCGAGCGCTATGACATGTCCTTCTTCAAACGAGGCTTGTGGAGAGTATTAAGCGGTAGGCAGCGGCTTGGCTCTGCCCCTGGCATTGCTGAAGTCCATGGGCGACGGTAA
Protein
MNSFTKTENINRLRRNLKGRAKEAVDGLLITNADPSDVIRSLEARFGRPETIAITELDTLRALPRLTETPRDICIFSSKVTNAVATLRALNCTHYLYNPETTKTMLEKLTPTLRYRYYDFTAVQPKEDPDLIKFEKFMKREAELCSPYAQPEQAGHYSQPAQHNRRTQNVHIVSEKPSLAKCPVCINTEHTTTDCYIFKKADSNTRWDIAKNKHLCFRCLKYRNKTHHCKPKTCGINDCKYTHNKMLHFDRKIEKTDNSDKETTENINSAWTGKQKQSYLKIIPVQVQGPIGTVDTYALLDDGSTVTLIDEIICKKTGITGLIDPLHIQAINNIKSTETRSRRVNLTLRGLNSRKEIIQARTVNDLQVTAQKIPKEQIDEYSHLRDISDIITYENAKPGILIGQDNWHMLLTSKVRRGNRNQPIASLTPLGWVLHGGRTRTLGHHINYINHASETQEDDKIENLVKQYFAMDALCITPRRPKTDPKEQALRILNRNTVHTTDGRYETALLWKTDNVSLPDNYNNSLKRLINIENKLDRNPELKQKYTEQMEALVAKGYAEPAPNTKTENRTWYLPHFAVANPLKPEKLRVVHGAAARTGGVALNDMLLKGPDLLQSLPGVIMRFRQHNIAVTADIWGLIASRFRSNVRGLHSNLDAVHHHLETAQPALLFLTETQISAPDDTSYLEYPGYVLEHNFLRKAGVCVFVRADVCCRRLRSLEQRDLSLLWLRVDHGGCTRVYACLYRSHSSDAGSALIEHVQEGTNRVLEQYPSAEVVVLGDFNAHHQEWLGSRTTDLPGRTAYDFALAYGLSQLVTQPTRVPDIEGHEPSLLDLLLTTDPAGYSVVVDAPLGSSDHCLIRAATPLSRPSRRTTTRYRRVWQYLSADWDGLREFYASYPWGRFCFSSADPDVCADRLKDVVLQGMELFIPSSEVPVGGRSRPWYNNASRDAAHLKRSAYVAWDDARRRRDPNISEERRKYNAASRSYKKVIARAKSEHVARIGERLKSYPSGSRAFWSLAKAAEGNFCRSSLPPLRKSDDSLAHSAKEKADLLVKLFASNSTVDDGGATPPNILRCDSSLPEICFTQCAVRRELRLLDVHKSSGPDGIPAVVLKTCAPELTPALTRLYRLSYCANRVPSSWKTAHVHPIPKKGDRSDPSSYRPIAITSLLSKVMERIINIQLLKYLEDRQLISDRQYGFRHGRSAGDLLVYLTHRWAEALESKGEALAVSLDIAKAFDRVWHRALLSKLPSYGIPEGLCKWIASFLDGRSITVVVDGDCSDTMTINAGVPQGSVLSPTLFILYINDMLSIDGMHCYADDSTGDARYIGHQSLSRSVVQERRSKLVSEVENSLGRVSKWGELNLVQFNPLKTQVCAFTAKKDPFVMAPQFQGVSLQPSESIGILGVDISSDVQFRSHLEGKAKLASKMLGVLNRAKRYFTPGQRLLLYKAQVRPRVEYCSHLWAGAPKYQLLPFDSIQRRAVRIVDNPGLTDRLEPLGLRRDFGSLCILYRMFHGECSEELFEMIPASRFYHRTARHRSRVHPYYLEPLRSSTVRFQRSFLPRTIRLWNELPSTVFPERYDMSFFKRGLWRVLSGRQRLGSAPGIAEVHGRR
Summary
Uniprot
ProteinModelPortal
PDB
6AR3
E-value=3.27857e-05,
Score=119
Ontologies
GO
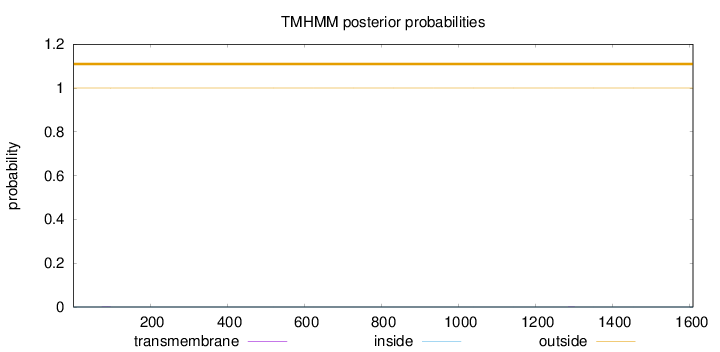
Topology
Length:
1608
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00700999999999999
Exp number, first 60 AAs:
0.00019
Total prob of N-in:
0.00020
outside
1 - 1608
Population Genetic Test Statistics
Pi
0
Theta
0
Tajima's D
0
CLR
245.033524
CSRT
0
Interpretation
Uncertain
