Gene
KWMTBOMO10368 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA007052
Annotation
PREDICTED:_transcription_initiation_factor_TFIID_subunit_1_isoform_X1_[Amyelois_transitella]
Full name
Transcription initiation factor TFIID subunit
+ More
Transcription initiation factor TFIID subunit 1
Transcription initiation factor TFIID subunit 1
Alternative Name
TAFII250
TBP-associated factor 230 kDa
Transcription initiation factor TFIID 230 kDa subunit
TBP-associated factor 230 kDa
Transcription initiation factor TFIID 230 kDa subunit
Location in the cell
Nuclear Reliability : 4.194
Sequence
CDS
ATGTGTGATAGTGACGAACAAGGTGACCACAGCCGTTCAGGCTTGGATCTGACCGGGTTCTTGTTTGGTAATATTGACGAAAGGGGTCAGTTAGAAGATGATGGATTGCTAGATGGTGAATCGAAGCGAATGTTATCATCGCTTAGCCGCTTAGGTTTAGGGTCTATGCTCTCTGAAGTCCTGGAGGTTGAGGAACCAGTTAAAGAAGAGGAAGAAAAAGACTATAATGAGAAAAGTCCATCGGCTGTGGACTTTTTTGACATTGAAGATGCAGCAGAGGATATAAAAGTAGAAAATAATGTGATAAAATTTGAAAATACTTCAGATGTACAAACTGTGCATAGCAGCAATGTTCCTGTGATTATTGATTCACAGAGTATTAAAGAGGAATTAAAAGAAGATACTTGGAGGGACACTGATATTGCAGGAGAACAAGAGGTACAGAGTACCAATGATGATGGCTATGAAGGTGATATGGAAGGTGATGGTGGACTTATGCCCCCTCCTTCGACAGTTCCACCCCCCAAACAAGAAAAACCCAAAAAACTAGATACTCCATTGGCTGCAATGCTTCCATCTAAATATGCCAATGTTGATGTCACAGAACTGTTTCCGGATTTCAGACCAGATAGAGTACTTCTTTTCTCTCGACTTTTTGGACCTGGAAAACTGTCCAGCTTACCGCAAATATGGCGCGGTGTTAAAAAACGTAGACGTCGAAAGCGCAGTGGAAGTACAGGCAGTGACACACCACCGATGGTTCCAGACAGTCAGGAACCTCAATATGCAAGTGACGATGAAGAGAAACTTCTCAAGCCTATGGAAGAAAATCAACAGATGTCTAATGACGATAAGGGATTAGGCTCAGGAGACAAAGCACAAAGGCCAACACCGGCCCACTGGCGTTTTGGTCCTGCTCAAGTTTGGTATGATATGTTGAATGTACCAGAGACAGGTGATGGGTTTGACTACGGATTCAAATTAAAGACTCAAGGAACAGATCGTGAAGAAAAATCAAAGGAAGTTGAAGAAGAAATTAGAGACACTGTGGAGAGTGCAGATAGCCCTGATAGTGGCTTTCCCGATGATTCTTTCCTTATGCTGTCACAGTTGCAGTGGGAAGATGATGTTATATGGGATGGAAGTGAAATGAAACATAAGGTGCTTGCCCGTTTGAACAGCAAAAGTAATGCAGCCGGATGGGTTCCTACATCAGTAAGCCGCACTGCACAGCAATTCTCACATCCTAGACCACAGCCACCAACCACATTACAGACTAAAACACCCGCTGCTACAGCCACTTCTGCTAATAACCAACCTGGAGGGAATTCAGCTGATGGTGAAGATAACACTTGGTACAGTATATTCCCAGTTGAAAACGAAGAGTTGGTATACGGTACTTGGGAGGATGAAGTTATATGGGATGCAGAGAACATGTCCAAAATACCGAAACCTAAGATACTTACATTGGATCCTAACGATGAGAACATTATATTGGGTATTCCAGATGATGTCGATCCTTCGAAGATTACTAGAGAGCGAGGTCCAGCTCCTAAAGTAAAGATACCTCATCCTCACGTTAAGAAATCCAAGATCCTGCTTGGAAAAGCTGGTGTAATTAATGTACTTCAAGAAGACGCTCCACCGCCTCCCCCTAAGTCGCCTGACAGAGATCCTTTCAATATATCGAATGATGTATATTACCAGCCAAAATCGCAGAACCCACGTTTGAAAGTGGGCGGCGGTCAGCTGATACAGCACAGCACGCCGGTGGTGGAGCTGCGCGCGCCCTTCATCCAGACGCACATGGGGCCGGCCCGACTGCGCGCGTTCCACCGGCCCGCGCTCAGGAAGCTGACGTACGGGCCGCTCTCTGCCCCCGGACCGCACCCCGTCCAACCCTTGCTGAAGCATATTCGAAAGAAAGCTAAGCAACGTGAAGCAGAAAGACTAGCGTCTGGTGGCGGTGACGTGTTCTTCATGCGGACGCCGGAAGATCTGAGCGGTAGAGACGGTGAAATAATACTGGTCGAGTTCTGCGAAGAGCATCCGCCACTGTTGAGTCAAGTTGGCATGTGCACTAAGATCAAAAATTACTACAAGCGGACAGCTACCAAGGACAACGGTCCCAAGCCACTGAAGTACGGTGAAGTAGCGTACGCTCACACGTCGCCGTTCCTCGGGATCCTGGCGCCGGGAGCCACGCAGCCGGTCGTCGAGAACAACATGTACAGAGCTCCTATATACGAACACACGTTGCCGCAGACTGACTTCATCATTATACGTACCAGACAAGCATATTATATACGTGAGATCGACGCTGTGTACGTTGCCGGACAAGAGTGTCCGCTGTATGAAGTCCCCGGACCAAATTCAAAGAGAGCTAACAATTTCGTTAGAGATTTCTTGCAGGTGTTCATATACAGGCTATTTTGGAAATCTCGTGACAAGCCACGTCGTATAAAAATGGATGATATAAAGAGGGCGTTCCCGTCGCATTCTGAAAGTTCGATTAGAAAGAGATTGAAGCTATGCGCTGATTTTAAGCGTACCGGATTGGATTCGAATTGGTGGGTGATAAAGCCGGATTTCCGTCTACCCTCCGAAGAAGAAATCCGAGCCATGGTGTCGCCCGAACAGTGCTGCGCCTACTTCAGTATGGCGGCCGCAGAACAAAGACTGAAAGACGCTGGCTACGGAGAAAAGTTCCTGTTTACCCCGCAAGAGGACGATGACGAGGAAATGCAGCTGAAGATAGATGATGAAGTAAAAGTGGCTCCGTGGAACACGACCCGCGCCTACATCCAGGCCATGCGCGGCAAGTGTCTGCTCCAGCTGACCGGCCCGGCGGACCCCACCGGCTGCGGCGAGGGGTTCTCGTACGTGCGGGTGCCGAACAAGCCCACGCAGCAACCGAACGAGGAGCAACAACCCAAACGAACCGTCACCGGGACCGACGCTGACCTGAGGAGGCTGAGTTTGAACAACGCTAAGGCACTGTTGAGGAAGTTCGGTGTTCCCGAAGAGGAGATCAAAAAGCTGTCGCGCTGGGAAGTAATCGATGTTGTACGAACATTATCGACCGAGAAAGCAAAAGCTGGCGAGGAAGGCATGACGAAGTTCTCCAGAGGAAATAGATTCTCTATTGCAGAGCATCAAGAAAGGTACAAAGAAGAATGTCAGCGTATATTCGAGCTCCAGAACCGCGTCCTGCAGAGTACAGAGGTGCTAAGTACCGACGAGGCCGAGAGTTCGGTCAGCGAGGAATCCGACTTGGAAGAAATGGGCAAGAATCTCGAAAATATGCTAGCAAATAAAAAGACCACAGAACAGCTGTCAATGGAAAGAGAGGAGGCAGAGAGAGCGGAACTTCGGAAGATGATAATGGGACAGTCCGAGAAGAAACCGCAAATTAATCCAAGCGATCAACAACAAACATCGAGTCAAGCAGGTCGAGTGCTCCGCATAGTGCGCACGTTCCGCGACGCTTCCGGCCAGCGGTACACGCGCGTCGAGCTCGTGCGGAAGGCGGCCGTCATAGAGGCCTACACCAAGATACGGTCCACCAAGGACGACATGTTCATACGGCAGTTCGCCTCTATGGATGAAACGCAGAAAGAAGAAATGAAGAGGGAGAAGAGAAGAATACAGGAACAATTGAGACGTATCAAGCGAAATCAGGAGAGAGAAAGACTGGCCGGCAATGTCACCGTACCTGGCCTTGGGAACGACAGTGACCTCGGGCCCTCCTCCAGCAACCTCATACCTCTGGGCCAAATCAAACAAGAGCCGGATCTCCACACGCCATCCCGAAGACGTGCCAAACTAAAGCCTGACTTGAAACTAAAGTGTGGCGCCTGCGGCCAGGTTGGTCACATGAGGACGAACAAAGCGTGTCCGCTATACACCGGCTCGGTTACGGGTGGACCGGCCTCTCCTCCGGACATAGACGTGGAGCCTCCTCCCGTTGAACCAGAAGATGATGATCTTGGATATGTGGATGGAACAAAGCTAACGCTACCAACCAAGATTATTAAGCAAACCGCCGAGGAGCTGAAGCGTCGCGGCGGCGGCAGGCGCGGCAGCGAGTTCGGACGCAGCAAACGCCGCGGCGCCACCGCGGACTCGTGCGAGTACTTGGTCCGGCGGCCGGCCGAGAGGCGCCGCACCGATCCGCTGGTCACCCTGTCGTCGTTGCTGGAAGACGTCCTAAATCACATGCGGCATTTGCCCGATGTACAGCCCTTCCTGTTTCCTGTCAATCATAAGCTTGTTGCAGATTACTATCGCATAGTTTCCCGACCGATGGATCTGCAAACTATACGAGATAATCTCCGACAGAAACATTATCAAAGCCGCGAAGAATTCTTGGCCGATGTCAATCAGATCGTCGAGAACAGCACGCTTTATAATGGTCCAACAAGCAGTCTCACTGTGGCCGCCCAGAGAATGTTACAGCGCTGCGTTGAGAAATTAGCAGAAAAAGAGGAACAGCTAATGAAACTCGAGAAACAAATTAATCCATTACTTGATGATAACGATCAGGTGGCCTTGTCGTTTATATTCGAGAATCTTCTGACAACTAAACTGAAGATAATGCCCGAATCGTGGCCCTTCTTGAAGCCCGTCAACAAGAAACAAGTTAAAGACTATTACAACGTCATCAAGCAACCTATAGACATGGAAACTATGGGAAAGAAGATTCAAGCTCACAAATATCACAGCCGTGAAGAATTCCTCCGGGACGTACAACTTTTGGTGGATAATTGTCGGGCTTACAACGGCCCGAACTCTCAGTTCACGAGACAAGCTGAGGCCGTATTGAAGGTCACGCAGGACGCTTTAGGCCAGTTCGACGAGCATGTAAGTCAGTTGGAAGCGAACATAGTTAGGGTTCAGCAGAAAATGCTCGAAGACGCCCAGCACTCGGAGCCGGAGGGCGACGACCTCCCCCCCACGGACGAGAAGCGCGGCCGGGGGCGCCCGCGGAAACACAAGCCCTCAACATCAGACGGTGCTACTCCTAGAAAACGAGGCAGACCACGTAAAGATCAGAACAGTTTGGAAGAAGATCTTCAATACTCGGACAGTGGTAGTTCGGAATTGGAAGAGGTGGAACAGAAAGACATCGTTGACACCATTCAACTCTGTGTCAAGCCAGAAGATACAACGCTGGACGAGCCGAGCATGATATCGGATCCGTCCGATTTCCCGACGACGATCAAACGAGAAGTGACGGACGACCTGCCTCCGCCTTCGGACGACTTCGTGGACCTCGATCAGCCGACTGACTTTACTTTCCCGTCCATCGTAAAGGAAGAGCCGATCGAACCTGACATGAACATGGTTCCCGCGATGATAGAGAGTCACATGGAGCCGCCTCAGCAGTTCAAGGAGGAGCCGCCAGAGAATTGGCAGCCCGATCCAGCCATTCAAGATGATCTCCAGGTGACTGATAGCGAGGAAGAAGCAGAAGATGGGTTGTGGTTCTAA
Protein
MCDSDEQGDHSRSGLDLTGFLFGNIDERGQLEDDGLLDGESKRMLSSLSRLGLGSMLSEVLEVEEPVKEEEEKDYNEKSPSAVDFFDIEDAAEDIKVENNVIKFENTSDVQTVHSSNVPVIIDSQSIKEELKEDTWRDTDIAGEQEVQSTNDDGYEGDMEGDGGLMPPPSTVPPPKQEKPKKLDTPLAAMLPSKYANVDVTELFPDFRPDRVLLFSRLFGPGKLSSLPQIWRGVKKRRRRKRSGSTGSDTPPMVPDSQEPQYASDDEEKLLKPMEENQQMSNDDKGLGSGDKAQRPTPAHWRFGPAQVWYDMLNVPETGDGFDYGFKLKTQGTDREEKSKEVEEEIRDTVESADSPDSGFPDDSFLMLSQLQWEDDVIWDGSEMKHKVLARLNSKSNAAGWVPTSVSRTAQQFSHPRPQPPTTLQTKTPAATATSANNQPGGNSADGEDNTWYSIFPVENEELVYGTWEDEVIWDAENMSKIPKPKILTLDPNDENIILGIPDDVDPSKITRERGPAPKVKIPHPHVKKSKILLGKAGVINVLQEDAPPPPPKSPDRDPFNISNDVYYQPKSQNPRLKVGGGQLIQHSTPVVELRAPFIQTHMGPARLRAFHRPALRKLTYGPLSAPGPHPVQPLLKHIRKKAKQREAERLASGGGDVFFMRTPEDLSGRDGEIILVEFCEEHPPLLSQVGMCTKIKNYYKRTATKDNGPKPLKYGEVAYAHTSPFLGILAPGATQPVVENNMYRAPIYEHTLPQTDFIIIRTRQAYYIREIDAVYVAGQECPLYEVPGPNSKRANNFVRDFLQVFIYRLFWKSRDKPRRIKMDDIKRAFPSHSESSIRKRLKLCADFKRTGLDSNWWVIKPDFRLPSEEEIRAMVSPEQCCAYFSMAAAEQRLKDAGYGEKFLFTPQEDDDEEMQLKIDDEVKVAPWNTTRAYIQAMRGKCLLQLTGPADPTGCGEGFSYVRVPNKPTQQPNEEQQPKRTVTGTDADLRRLSLNNAKALLRKFGVPEEEIKKLSRWEVIDVVRTLSTEKAKAGEEGMTKFSRGNRFSIAEHQERYKEECQRIFELQNRVLQSTEVLSTDEAESSVSEESDLEEMGKNLENMLANKKTTEQLSMEREEAERAELRKMIMGQSEKKPQINPSDQQQTSSQAGRVLRIVRTFRDASGQRYTRVELVRKAAVIEAYTKIRSTKDDMFIRQFASMDETQKEEMKREKRRIQEQLRRIKRNQERERLAGNVTVPGLGNDSDLGPSSSNLIPLGQIKQEPDLHTPSRRRAKLKPDLKLKCGACGQVGHMRTNKACPLYTGSVTGGPASPPDIDVEPPPVEPEDDDLGYVDGTKLTLPTKIIKQTAEELKRRGGGRRGSEFGRSKRRGATADSCEYLVRRPAERRRTDPLVTLSSLLEDVLNHMRHLPDVQPFLFPVNHKLVADYYRIVSRPMDLQTIRDNLRQKHYQSREEFLADVNQIVENSTLYNGPTSSLTVAAQRMLQRCVEKLAEKEEQLMKLEKQINPLLDDNDQVALSFIFENLLTTKLKIMPESWPFLKPVNKKQVKDYYNVIKQPIDMETMGKKIQAHKYHSREEFLRDVQLLVDNCRAYNGPNSQFTRQAEAVLKVTQDALGQFDEHVSQLEANIVRVQQKMLEDAQHSEPEGDDLPPTDEKRGRGRPRKHKPSTSDGATPRKRGRPRKDQNSLEEDLQYSDSGSSELEEVEQKDIVDTIQLCVKPEDTTLDEPSMISDPSDFPTTIKREVTDDLPPPSDDFVDLDQPTDFTFPSIVKEEPIEPDMNMVPAMIESHMEPPQQFKEEPPENWQPDPAIQDDLQVTDSEEEAEDGLWF
Summary
Description
TFIID is a multimeric protein complex that plays a central role in mediating promoter responses to various activators and repressors. Largest component and core scaffold of the complex. Contains N- and C-terminal Ser/Thr kinase domains which can autophosphorylate or transphosphorylate other transcription factors. Possesses DNA-binding activity. Essential for progression of the G1 phase of the cell cycle. Negative regulator of the TATA box-binding activity of Tbp.
Catalytic Activity
ATP + L-seryl-[protein] = ADP + H(+) + O-phospho-L-seryl-[protein]
ATP + L-threonyl-[protein] = ADP + H(+) + O-phospho-L-threonyl-[protein]
ATP + L-threonyl-[protein] = ADP + H(+) + O-phospho-L-threonyl-[protein]
Cofactor
Mg(2+)
Subunit
Belongs to the TFIID complex which is composed of TATA binding protein (Tbp) and a number of TBP-associated factors (Tafs). Taf1 is the largest component of the TFIID complex. Interacts with Tbp, Taf2, Taf4 and Taf6.
Similarity
Belongs to the TAF1 family.
Keywords
3D-structure
Alternative splicing
ATP-binding
Bromodomain
Cell cycle
Complete proteome
Direct protein sequencing
DNA-binding
Kinase
Nucleotide-binding
Nucleus
Phosphoprotein
Polymorphism
Reference proteome
Repeat
Transcription
Transcription regulation
Transferase
Feature
chain Transcription initiation factor TFIID subunit 1
splice variant In isoform A.
splice variant In isoform A.
Uniprot
H9JC07
A0A212EJ91
A0A2A4K4T5
A0A2H1V871
A0A3S2LDD4
A0A0L7QNA2
+ More
A0A0C9RHB3 A0A087ZZI2 A0A154PIE5 A0A195AWA9 A0A1B6GDW5 D6WH84 A0A1Y1KSR9 A0A195EGB9 A0A195FEX3 A0A2J7RI17 A0A1Y1KYI1 F4WPV5 A0A2J7RHZ9 A0A158NHZ1 A0A026WWD0 A0A195CLG8 A0A0N0BI81 A0A067R0X8 A0A2J7RI03 E2AC06 E9IBL5 A0A1B6F888 A0A2A3EM21 A0A023F423 E2BXG7 U4U6I9 A0A0A1XJA3 A0A151WRA6 N6UCI4 A0A310SF23 A0A034V2C8 A0A0K8UHF4 A0A146L8G5 E0VZR5 A0A0K8U8E3 A0A1S4MYW8 A0A336LC62 A0A0L0BUW7 A0A1I8P6S7 A0A336MW32 A0A1I8P6M4 A0A182HEW8 A0A1I8P6R1 A0A182HCF5 A0A0P6J4D2 Q177P0 A0A1I8M3M2 A0A1I8M3M0 A0A1Q3F3H4 A0A1Q3F465 B0W9Q3 A0A182VQB5 A0A182XX78 A0A182QS87 A0A2H8TLZ8 X1XTS4 A0A182MJD6 A0A240SWV4 A0A0R1E1Z8 A0A1A9Z717 A0A0Q9WNU3 A0A1A9XSD2 A0A0R1E716 A0A0R1E1K5 A0A182N6X6 A0A0R1E1Y5 A0A0Q9WS64 A0A2S2QID3 A0A182RBU4 A0A1A9UNU3 B4PSK3 A0A0Q9WX17 A0A182PIZ0 A0A0Q9WYV4 A0A0R1E1J8 A0A0P8ZY00 A0A0Q9WPW3 A0A1B0BLX7 A0A0P8YDJ1 P51123-2 A0A0Q9WQR2 E1JJ72 A0A0B4LGU9 B4KBJ7 A0A182K6A5 B3M0S3 A0A0P8XY56 A0A0Q9X3S2 A0A0P6J3D1 A0A0A9YPY2 P51123-3 A0A0B4K602 P51123 Q7QK07
A0A0C9RHB3 A0A087ZZI2 A0A154PIE5 A0A195AWA9 A0A1B6GDW5 D6WH84 A0A1Y1KSR9 A0A195EGB9 A0A195FEX3 A0A2J7RI17 A0A1Y1KYI1 F4WPV5 A0A2J7RHZ9 A0A158NHZ1 A0A026WWD0 A0A195CLG8 A0A0N0BI81 A0A067R0X8 A0A2J7RI03 E2AC06 E9IBL5 A0A1B6F888 A0A2A3EM21 A0A023F423 E2BXG7 U4U6I9 A0A0A1XJA3 A0A151WRA6 N6UCI4 A0A310SF23 A0A034V2C8 A0A0K8UHF4 A0A146L8G5 E0VZR5 A0A0K8U8E3 A0A1S4MYW8 A0A336LC62 A0A0L0BUW7 A0A1I8P6S7 A0A336MW32 A0A1I8P6M4 A0A182HEW8 A0A1I8P6R1 A0A182HCF5 A0A0P6J4D2 Q177P0 A0A1I8M3M2 A0A1I8M3M0 A0A1Q3F3H4 A0A1Q3F465 B0W9Q3 A0A182VQB5 A0A182XX78 A0A182QS87 A0A2H8TLZ8 X1XTS4 A0A182MJD6 A0A240SWV4 A0A0R1E1Z8 A0A1A9Z717 A0A0Q9WNU3 A0A1A9XSD2 A0A0R1E716 A0A0R1E1K5 A0A182N6X6 A0A0R1E1Y5 A0A0Q9WS64 A0A2S2QID3 A0A182RBU4 A0A1A9UNU3 B4PSK3 A0A0Q9WX17 A0A182PIZ0 A0A0Q9WYV4 A0A0R1E1J8 A0A0P8ZY00 A0A0Q9WPW3 A0A1B0BLX7 A0A0P8YDJ1 P51123-2 A0A0Q9WQR2 E1JJ72 A0A0B4LGU9 B4KBJ7 A0A182K6A5 B3M0S3 A0A0P8XY56 A0A0Q9X3S2 A0A0P6J3D1 A0A0A9YPY2 P51123-3 A0A0B4K602 P51123 Q7QK07
EC Number
2.7.11.1
Pubmed
19121390
22118469
18362917
19820115
28004739
21719571
+ More
21347285 24508170 24845553 20798317 21282665 25474469 23537049 25830018 25348373 26823975 20566863 26108605 26483478 26999592 17510324 25315136 25244985 17994087 17550304 8504928 10731132 12537572 12537569 8464492 8625415 8262073 8327460 8178153 15143281 18327897 9741622 12537568 12537573 12537574 16110336 17569856 17569867 26109357 26109356 25401762 12364791 14747013 17210077
21347285 24508170 24845553 20798317 21282665 25474469 23537049 25830018 25348373 26823975 20566863 26108605 26483478 26999592 17510324 25315136 25244985 17994087 17550304 8504928 10731132 12537572 12537569 8464492 8625415 8262073 8327460 8178153 15143281 18327897 9741622 12537568 12537573 12537574 16110336 17569856 17569867 26109357 26109356 25401762 12364791 14747013 17210077
EMBL
BABH01014660
BABH01014661
BABH01014662
BABH01014663
AGBW02014522
OWR41530.1
+ More
NWSH01000129 PCG79261.1 ODYU01001168 SOQ37001.1 RSAL01000036 RVE51281.1 KQ414855 KOC60122.1 GBYB01007685 JAG77452.1 KQ434924 KZC11582.1 KQ976725 KYM76533.1 GECZ01009127 JAS60642.1 KQ971330 EEZ99738.1 GEZM01074872 GEZM01074870 GEZM01074867 GEZM01074865 JAV64433.1 KQ978957 KYN27196.1 KQ981636 KYN38772.1 NEVH01003506 PNF40466.1 GEZM01074876 JAV64426.1 GL888255 EGI63784.1 PNF40462.1 ADTU01016114 KK107078 EZA60385.1 KQ977622 KYN01312.1 KQ435732 KOX77334.1 KK853018 KDR12445.1 PNF40464.1 GL438389 EFN69024.1 GL762111 EFZ22135.1 GECZ01023445 JAS46324.1 KZ288212 PBC32805.1 GBBI01002511 JAC16201.1 GL451254 EFN79615.1 KB632005 ERL87928.1 GBXI01003689 JAD10603.1 KQ982813 KYQ50337.1 APGK01034498 KB740914 ENN78346.1 KQ779356 OAD52000.1 GAKP01022293 JAC36659.1 GDHF01026579 JAI25735.1 GDHC01014590 GDHC01000568 JAQ04039.1 JAQ18061.1 DS235854 EEB18871.1 GDHF01032673 GDHF01029694 GDHF01008225 JAI19641.1 JAI22620.1 JAI44089.1 AAZO01006526 UFQS01001591 UFQT01001591 SSX11524.1 SSX31091.1 JRES01001300 KNC23821.1 UFQT01002946 SSX34330.1 JXUM01132778 JXUM01132779 KQ567891 KXJ69235.1 JXUM01127242 KQ567165 KXJ69586.1 GDUN01000966 JAN94953.1 CH477373 EAT42378.1 GFDL01012941 JAV22104.1 GFDL01012704 JAV22341.1 DS231865 EDS40372.1 AXCN02000311 GFXV01003166 MBW14971.1 ABLF02029287 AXCM01005046 CCAG010011328 CM000160 KRK03157.1 CH940650 KRF83073.1 KRK03159.1 KRK03160.1 KRK03161.1 KRF83072.1 GGMS01008306 MBY77509.1 EDW96463.1 CH933806 KRG00555.1 KRG00553.1 KRK03158.1 CH902617 KPU79560.1 KRF83071.1 JXJN01016598 KPU79561.1 S61883 AE001572 AE014297 BT004888 KRF83070.1 BT150382 ACZ94830.1 AGW52192.1 AHN57200.1 EDW13664.1 EDV42088.1 KPU79562.1 KRG00554.1 GDIQ01000177 JAN94560.1 GBHO01010466 JAG33138.1 AFH06271.1 AAAB01008805 EAA03907.5
NWSH01000129 PCG79261.1 ODYU01001168 SOQ37001.1 RSAL01000036 RVE51281.1 KQ414855 KOC60122.1 GBYB01007685 JAG77452.1 KQ434924 KZC11582.1 KQ976725 KYM76533.1 GECZ01009127 JAS60642.1 KQ971330 EEZ99738.1 GEZM01074872 GEZM01074870 GEZM01074867 GEZM01074865 JAV64433.1 KQ978957 KYN27196.1 KQ981636 KYN38772.1 NEVH01003506 PNF40466.1 GEZM01074876 JAV64426.1 GL888255 EGI63784.1 PNF40462.1 ADTU01016114 KK107078 EZA60385.1 KQ977622 KYN01312.1 KQ435732 KOX77334.1 KK853018 KDR12445.1 PNF40464.1 GL438389 EFN69024.1 GL762111 EFZ22135.1 GECZ01023445 JAS46324.1 KZ288212 PBC32805.1 GBBI01002511 JAC16201.1 GL451254 EFN79615.1 KB632005 ERL87928.1 GBXI01003689 JAD10603.1 KQ982813 KYQ50337.1 APGK01034498 KB740914 ENN78346.1 KQ779356 OAD52000.1 GAKP01022293 JAC36659.1 GDHF01026579 JAI25735.1 GDHC01014590 GDHC01000568 JAQ04039.1 JAQ18061.1 DS235854 EEB18871.1 GDHF01032673 GDHF01029694 GDHF01008225 JAI19641.1 JAI22620.1 JAI44089.1 AAZO01006526 UFQS01001591 UFQT01001591 SSX11524.1 SSX31091.1 JRES01001300 KNC23821.1 UFQT01002946 SSX34330.1 JXUM01132778 JXUM01132779 KQ567891 KXJ69235.1 JXUM01127242 KQ567165 KXJ69586.1 GDUN01000966 JAN94953.1 CH477373 EAT42378.1 GFDL01012941 JAV22104.1 GFDL01012704 JAV22341.1 DS231865 EDS40372.1 AXCN02000311 GFXV01003166 MBW14971.1 ABLF02029287 AXCM01005046 CCAG010011328 CM000160 KRK03157.1 CH940650 KRF83073.1 KRK03159.1 KRK03160.1 KRK03161.1 KRF83072.1 GGMS01008306 MBY77509.1 EDW96463.1 CH933806 KRG00555.1 KRG00553.1 KRK03158.1 CH902617 KPU79560.1 KRF83071.1 JXJN01016598 KPU79561.1 S61883 AE001572 AE014297 BT004888 KRF83070.1 BT150382 ACZ94830.1 AGW52192.1 AHN57200.1 EDW13664.1 EDV42088.1 KPU79562.1 KRG00554.1 GDIQ01000177 JAN94560.1 GBHO01010466 JAG33138.1 AFH06271.1 AAAB01008805 EAA03907.5
Proteomes
UP000005204
UP000007151
UP000218220
UP000283053
UP000053825
UP000005203
+ More
UP000076502 UP000078540 UP000007266 UP000078492 UP000078541 UP000235965 UP000007755 UP000005205 UP000053097 UP000078542 UP000053105 UP000027135 UP000000311 UP000242457 UP000008237 UP000030742 UP000075809 UP000019118 UP000009046 UP000037069 UP000095300 UP000069940 UP000249989 UP000008820 UP000095301 UP000002320 UP000075920 UP000076408 UP000075886 UP000007819 UP000075883 UP000092444 UP000002282 UP000092445 UP000008792 UP000092443 UP000075884 UP000075900 UP000078200 UP000009192 UP000075885 UP000007801 UP000092460 UP000000803 UP000075881 UP000007062
UP000076502 UP000078540 UP000007266 UP000078492 UP000078541 UP000235965 UP000007755 UP000005205 UP000053097 UP000078542 UP000053105 UP000027135 UP000000311 UP000242457 UP000008237 UP000030742 UP000075809 UP000019118 UP000009046 UP000037069 UP000095300 UP000069940 UP000249989 UP000008820 UP000095301 UP000002320 UP000075920 UP000076408 UP000075886 UP000007819 UP000075883 UP000092444 UP000002282 UP000092445 UP000008792 UP000092443 UP000075884 UP000075900 UP000078200 UP000009192 UP000075885 UP000007801 UP000092460 UP000000803 UP000075881 UP000007062
Pfam
Interpro
IPR036741
TAFII-230_TBP-bd_sf
+ More
IPR036427 Bromodomain-like_sf
IPR040240 TAF1
IPR009067 TAF_II_230-bd
IPR041670 Znf-CCHC_6
IPR000637 HMGI/Y_DNA-bd_CS
IPR018359 Bromodomain_CS
IPR022591 TFIID_sub1_DUF3591
IPR001487 Bromodomain
IPR017956 AT_hook_DNA-bd_motif
IPR011177 TAF1_animal
IPR000210 BTB/POZ_dom
IPR036236 Znf_C2H2_sf
IPR011333 SKP1/BTB/POZ_sf
IPR013087 Znf_C2H2_type
IPR036508 Chitin-bd_dom_sf
IPR002557 Chitin-bd_dom
IPR036427 Bromodomain-like_sf
IPR040240 TAF1
IPR009067 TAF_II_230-bd
IPR041670 Znf-CCHC_6
IPR000637 HMGI/Y_DNA-bd_CS
IPR018359 Bromodomain_CS
IPR022591 TFIID_sub1_DUF3591
IPR001487 Bromodomain
IPR017956 AT_hook_DNA-bd_motif
IPR011177 TAF1_animal
IPR000210 BTB/POZ_dom
IPR036236 Znf_C2H2_sf
IPR011333 SKP1/BTB/POZ_sf
IPR013087 Znf_C2H2_type
IPR036508 Chitin-bd_dom_sf
IPR002557 Chitin-bd_dom
SUPFAM
Gene 3D
ProteinModelPortal
H9JC07
A0A212EJ91
A0A2A4K4T5
A0A2H1V871
A0A3S2LDD4
A0A0L7QNA2
+ More
A0A0C9RHB3 A0A087ZZI2 A0A154PIE5 A0A195AWA9 A0A1B6GDW5 D6WH84 A0A1Y1KSR9 A0A195EGB9 A0A195FEX3 A0A2J7RI17 A0A1Y1KYI1 F4WPV5 A0A2J7RHZ9 A0A158NHZ1 A0A026WWD0 A0A195CLG8 A0A0N0BI81 A0A067R0X8 A0A2J7RI03 E2AC06 E9IBL5 A0A1B6F888 A0A2A3EM21 A0A023F423 E2BXG7 U4U6I9 A0A0A1XJA3 A0A151WRA6 N6UCI4 A0A310SF23 A0A034V2C8 A0A0K8UHF4 A0A146L8G5 E0VZR5 A0A0K8U8E3 A0A1S4MYW8 A0A336LC62 A0A0L0BUW7 A0A1I8P6S7 A0A336MW32 A0A1I8P6M4 A0A182HEW8 A0A1I8P6R1 A0A182HCF5 A0A0P6J4D2 Q177P0 A0A1I8M3M2 A0A1I8M3M0 A0A1Q3F3H4 A0A1Q3F465 B0W9Q3 A0A182VQB5 A0A182XX78 A0A182QS87 A0A2H8TLZ8 X1XTS4 A0A182MJD6 A0A240SWV4 A0A0R1E1Z8 A0A1A9Z717 A0A0Q9WNU3 A0A1A9XSD2 A0A0R1E716 A0A0R1E1K5 A0A182N6X6 A0A0R1E1Y5 A0A0Q9WS64 A0A2S2QID3 A0A182RBU4 A0A1A9UNU3 B4PSK3 A0A0Q9WX17 A0A182PIZ0 A0A0Q9WYV4 A0A0R1E1J8 A0A0P8ZY00 A0A0Q9WPW3 A0A1B0BLX7 A0A0P8YDJ1 P51123-2 A0A0Q9WQR2 E1JJ72 A0A0B4LGU9 B4KBJ7 A0A182K6A5 B3M0S3 A0A0P8XY56 A0A0Q9X3S2 A0A0P6J3D1 A0A0A9YPY2 P51123-3 A0A0B4K602 P51123 Q7QK07
A0A0C9RHB3 A0A087ZZI2 A0A154PIE5 A0A195AWA9 A0A1B6GDW5 D6WH84 A0A1Y1KSR9 A0A195EGB9 A0A195FEX3 A0A2J7RI17 A0A1Y1KYI1 F4WPV5 A0A2J7RHZ9 A0A158NHZ1 A0A026WWD0 A0A195CLG8 A0A0N0BI81 A0A067R0X8 A0A2J7RI03 E2AC06 E9IBL5 A0A1B6F888 A0A2A3EM21 A0A023F423 E2BXG7 U4U6I9 A0A0A1XJA3 A0A151WRA6 N6UCI4 A0A310SF23 A0A034V2C8 A0A0K8UHF4 A0A146L8G5 E0VZR5 A0A0K8U8E3 A0A1S4MYW8 A0A336LC62 A0A0L0BUW7 A0A1I8P6S7 A0A336MW32 A0A1I8P6M4 A0A182HEW8 A0A1I8P6R1 A0A182HCF5 A0A0P6J4D2 Q177P0 A0A1I8M3M2 A0A1I8M3M0 A0A1Q3F3H4 A0A1Q3F465 B0W9Q3 A0A182VQB5 A0A182XX78 A0A182QS87 A0A2H8TLZ8 X1XTS4 A0A182MJD6 A0A240SWV4 A0A0R1E1Z8 A0A1A9Z717 A0A0Q9WNU3 A0A1A9XSD2 A0A0R1E716 A0A0R1E1K5 A0A182N6X6 A0A0R1E1Y5 A0A0Q9WS64 A0A2S2QID3 A0A182RBU4 A0A1A9UNU3 B4PSK3 A0A0Q9WX17 A0A182PIZ0 A0A0Q9WYV4 A0A0R1E1J8 A0A0P8ZY00 A0A0Q9WPW3 A0A1B0BLX7 A0A0P8YDJ1 P51123-2 A0A0Q9WQR2 E1JJ72 A0A0B4LGU9 B4KBJ7 A0A182K6A5 B3M0S3 A0A0P8XY56 A0A0Q9X3S2 A0A0P6J3D1 A0A0A9YPY2 P51123-3 A0A0B4K602 P51123 Q7QK07
PDB
5FUR
E-value=0,
Score=3448
Ontologies
GO
GO:0006355
GO:0003743
GO:0003677
GO:0005669
GO:0006352
GO:0004674
GO:0043565
GO:0004402
GO:0045944
GO:0017025
GO:0003676
GO:0016021
GO:0016740
GO:0006030
GO:0008061
GO:0005576
GO:0005654
GO:0006468
GO:0005634
GO:0044154
GO:0005730
GO:0043967
GO:0006367
GO:0060261
GO:0007049
GO:0005524
GO:0008134
GO:0035102
GO:0036408
GO:0051123
GO:0010485
GO:0016746
GO:0005515
GO:0006415
GO:0006418
GO:0003723
GO:0046872
GO:0003824
PANTHER
Topology
Subcellular location
Nucleus
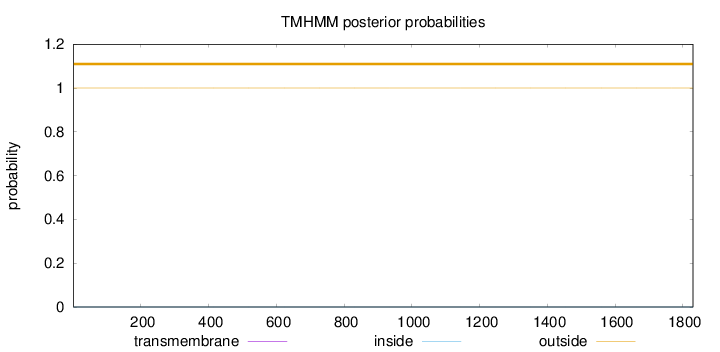
Length:
1830
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00117
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00006
outside
1 - 1830
Population Genetic Test Statistics
Pi
225.937036
Theta
19.007611
Tajima's D
0.060809
CLR
0.362669
CSRT
0.393530323483826
Interpretation
Uncertain
