Gene
KWMTBOMO10322
Pre Gene Modal
BGIBMGA007221
Annotation
ATP-binding_cassette_sub-family_A_ABCA1_[Bombyx_mori]
Location in the cell
PlasmaMembrane Reliability : 2.898
Sequence
CDS
ATGAGATATTTAGTGCCGCCCAAAGCAATACCGGCTAAAACTTACACATCCTTTGATGTCACCTATTTCAATAAGACAAGGGGAAATCTGTCATCAGCTGACATGGTATTGGCATACTCACCAATAAATCAATTGACTGAAAAAGTTGCAATCAATGCTATGGCTGAACTTGCTCGAGATTCAATTGATCCTGATATATTTTTTTTTATATCACTTGCAATTTCATACACTCCTAAAGGATATAAAAATGCCAAAGATATGGAAGCAGCACTAATACAGCCCAATGCTATGAATAGCATTTTGCTTGGTATACAATTTGATGATGAAATCGCTAATGCTACGTCTTGGCCAGATGATATAAAAATAACTTTTAGGTTTCCTGCTGTTATGAGATCGACAACGTCTGATCATCAAATGCAATTGAGCTGGCAAACAAACTTACTATTTCCATTGTTTCCGAATTCTGGTCCACGAGAACCAGATGATCAATATGGAGGAACTTCGCCAGGTTACTTCTCGGAACTATTCTTGTTCATGCAGCACGCAATTTCCAAAAGCATCGTAAAAGAGAAGACCGGGAAAAACATTGATACCAAAATATATCTACAGCGTTTACCTCAACTTGAATCTAGGGTGGATCAGCTACTGTTCATTTTACAAAGATTTGTATCCATAGCTATAATGCTGGGCTTCGTCTATACATTCGTGAATACAGTCAGGGCTGTCACAACTGAGAAAGAACTGCAGCTAAAGGAAACAATGGCAATTATGGGTCTACCGTCTTGGCTGCACTGGTTAGCGTGGTTCATCAAACAATTTTCATTCTTACTTGTGACTATTGTCATAATGGTTATATTGTTTAAGATTCCGTTATCCGAAACTGAAACAGGAGTGTCGTACTCCGTGTTCACCTACACGCCGTGGTCGGTCCTTTTATTCTTTTTGATTCTATTCGTCATTGCATCATTGACATTCTCTTTTATGATAAGCGTTTTCTTCACTAGAGCAAACACCGCCGCGTCTTTTATGGCTCTCATATGGTTCGCAACGTTCGCAGTCTTTATGTTCACCCAAATGATTAACGAGACCATGTCTGCCCCAGTTAAAATAACACTATGTTTGTTATCAAACACTGCCATTGGATACGCATTCCAGATGATTATCATTGCCGAAGGAACGATGCAAGGTTTACAATGGGCCAATTTCTTTGAGCCGATATCGTACAGTGAAAACTTTCAACCGGCTCATGTAGCCTTCATGCTAATATTGGACTCCGTGATGTACATGGCGATCGCCGTGTATGTGGAGAACATACGACCCGGAATGTACGGAGTGCCGTTGCCTTGGTACTATCCTTTCACTGTTAGTTATTGGTGGCCGAACAGAATATCTGACACAAATCGAGAGAAAACATCTGACGATCTTGAATATAATGATGCATTATTGTCGGTGGTACACGACGAGGAACCCAAAGGCGTTCCCATTGGCGTAAACATTCAAAATCTCACAAAAAGATATAAGGGACGGGGGAAAGCTGTCGATAATTTAAATCTTAGACTTTATGAAAACGAGATTACAGTACTTCTGGGTCACAATGGAGCGGGGAAAACGACAACGATTTCTATGTTAACAGGAATGGTCCCTCCAACATCAGGATCGGTAACGATCAATGGATATGATATCGTGACGGAAACGGAAAAAGCTAGACGTTCTCTTGGAATATGTCCTCAACATAATGTACTGTTCCCTGACCTGACCGTAGCTGAACATTTAATTTTTTATTCAAAGCTAAAGGGGATTCCCGAATCAGAAATCAATGAAGAAATAGATCATTTCGTCAAACTTCTCGAATTGGATGACAAGAGGCACGCGGCGGCATCGAGTCTGTCGGGCGGGCAGAAGCGGCGGCTGTCGGCGGGCTGCGCGCTGTGCGGGCGCTCGCGCGTGGTGCTGCTGGACGAGCCCACGTCGGGCCTGGACCCGGCGGCGCGGCGCGCGCTGTGGGACCTGCTGCAGCGCGAGAAGCGCGGCCGCACCGTGCTGCTGACCACGCACTTCATGGACGAGGCGGACGTGCTGGCCGACCGCGTGGCCGTGCTCGCCGCCGGCCGCCTGGCCTGTCTGGGCTCCCCCTACTTCCTCAAGCGCCACTACGGACTCGGCTACAAGCTCGCGCTCGTCAAGGACGCCGCCTGCCAAGTCGATCTTGTCACGGAATTCTTCAAAACATATGTCCCTAATCTCAAGCAAAATTCAAATATCGGCTCAGAATTAACTTACATTTTACCTAGTGAGAGTGTAAGTAAATTTCCCGAAATGCTCAAAAAACTTGAAGAAAAGAAAGAGTCTTTATGTATATCAAGCTACGGGTTATCAGTGACTAGCCTTGAGGAAGTTTTTATGAAAGCTGGAATCGAAGATAACAATGTTGAAATAAAAGAAACTAAAGGAGATATCGAAATGATTGATATGAATGGGGACATGTTGAAGGACAATGAGCCTTTACATAAAACGCAAGGGTTTCATTTACTGAAGAATCACATAAAAGCTATGTTCTTGAAACTGATGTACAACACATTGAGAAATAAGGCACTCGCTGCGATACAAATAATATGGCCAATAATAAACATTATTTTATCGATGATAGTTTCACTATCTTGGAAATTCTTGAATGTATTGCCCCCGCTTGAACTAAGCCTGGAGAGTGGATTTAAAGGAACCGAGACATTAGTATCGCAAGGTAACGATTTGAGAGACGGCAGTACTGAAGCTAATGTCATGATGGCATACAAAGATTATTTCAAACGATCAACGTACCCCGGCTTGAAGTTATTGGATGTCGGAACTTCTAACTTAAAAAACGTCTATTTGAAACTTATCGCAGAAGATCAATCTCGAGTACGATATGAAGATCTAGTGGGAGCTACATTTCGTAATAACAGCATAACAGCCTGGTTCAGTAACTACGGTCTTCATGATTCTGCTATCTCGCTTTCACTAGTCGAGAACGCAATAATTCGTTCTCTGTCACCCAATACAACTTTGACATTTGTCAACCATCCGCTACCATATTCAGTTGAAGGAATGGTTCAAGTAATGTCTACCGGAACAAACACCGCCTTCATGTTTTCTTTTAGCCTGGGATTTTGTATAGCGGTTATAAGCTCTTTTCTGGTTCTCTTTGTAATTAAAGAGCGCATCAGCGGTGCGAAACTTCTCCAAAGAGTATCAGGAGTGCGACCGGTAGTAATGTGGAGTACTGCCCTCATTTGGGATTGGATTTGGTTGTTTCTGAACCACATTTGCATTATAGTCACTATTGCGTGCTTCCAAGAAATGGGAATGTCGACGCCTGCTGAACTTGGTCGAATTTTATTAGTTCTGATGGTGTTTTCATTGGCAATTATACCGTTGCACTACCTCGCATCGTTCTGTTTCGAAGAAGCCGCCACCGGTTTCAGTAAAATGGTGTTTGTAAATATATTTTGTGGTTCAATGTTGTTCCTTGTCACTGAAGTATTACGGATGCCTTTCATAAATGCTGCTGCTTACGCAGAAATACTTGAGTATCCATTTTCATTGTTACCAATCTACTGTGTCAGCAAGAGTGTCAGGGAAATGGTGACATCTTCAATAAAGATTAAAGCCTGCGACAGCTTATGCAACCAATTAAATTATAAAAATTGCACACGACTAACTATATGCAATGAACTAGACATATCCATGTGTTGTATTGAGGATAATCCATTTTTAGGGTGGAAGGAACCGGGTATTGCAAGATATCTATTTACTATGATAGTTGTAGCGACTGTGTCATTTGCAATATTGCTAGCCAAGGAATACGAACTTTGGAACAAGGTCTTGTACAAGAAACAAGAAGAGACTATGATGTTATCTGGTACAAAACCAAAATCTAATGAGAGTAAAAAGGTTGAAGTAAATGCAGAAGTTGAAGATGATGATGTTGTGGAGGAAAAACAGCGTGTTCTAGCAATGACAAGTAGTGAGGTCACCGCACACAGCCTCGTGTGTCGCGAGCTGAGCAAGCGCTACCGGCGCCTCGTAGCCGTCGACCGACTCACGTTCGCGGTGCGCGGCGGAGAGTGCTTCGGCCTGCTCGGAGTCAACGGCGCCGGCAAGACCAGCACCTTCCGCATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCCGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGGTCCGCATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCGCTCATGCACGGACACTCCGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGGTCCGCATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCGGTGCGAGCACACGTCTCGGTTCGCATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCCGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGGTCCGCATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCGCTCATGCACGGACACTCCGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGGTCCGCATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCGGTGCGAGCACACGTCTCGGTTCGCATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGTACGGACACTCGGTGCGAGCACACGTGCAGGACGTGTACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCAGTCCGTATGCTGACTGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCGGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGGTCCGCATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCGGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGGTCCGTATGCTGACTGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCGGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGATCCGTATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCGGTGCGAGCACACGTCTCGGTTCGCATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGTACGGACACTCGGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGGTCCGTATGCTGACTGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCGGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGGTCCGCATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCGGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGGTCCGTATGCTGACTGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCGGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGGTCCGCATGTTGACCGGCGACGCACGCGTGTCGGACGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGCACGGACACTCGGTGCGAGCACACGTCTCGGTTCGCATGCTGACCGGCGACGCACGCGTGTCGGACGGCGACGCGCTCGTGTACGGACACTCGGTGCGAGCACACGTGCAGGACGTGCACCGCCTCATTGGTGAGTCGACCCTATTACACCTCAGCTCGGTCCACATGCTGATCGCCGACGCATGTGTGTGGGACGGCGACGCGCTCATGCACGGACCCTTGGTAAGAACCCACGTGCAGGACGTGTATTGCCTCATTTGTTACTGCCCCCAATTCGATGCACTGTTTGACAATTTAACCGCAAGGGAGATATTGAAGATTTTCTGTTTGCTGCGTGGCATTCCTACGTCAATAGGCGAAACTCATGCCATTCATCTTGCTAAACAATTGGGATTCATAAAGCACTATGACAAGAAGGTTCGGGAATGTAGTGGTGGAACAAAACGTAAAATCAGTACAGCGGTCGCGTTGCTCGGTGATTACCCAGTTATATTCCTGGATGAGCCTACGACAGGCATGGATCCGGCGTCGAAGCGGCTCGTGTGGCGCGGCATCAGCAGCGCGGTGGGCGGCGGGCGCAGCGTGGTGCTGACGTCACACAGCATGGAGGAGTGCGAGGCTCTCTGCTCCAAGCTCACCGTCATGGTCAACGGCAGGCTCTGCTGTCTCGGCTCGCTGCAACATCTCAAGAGCAAATTCTCACAGGGATACACAATAATCGTGAAATGTAAATCGGGTCCAAATCGAGACGCAGCAGTGCTAGACGTCCACAACTATATGACTACAAATTTTGTTGGTGCTAACCTCATCGAGACGTACCTGGGCATGAGCACGTACCACGTGTCGTCGGCGGGGCTGCCGTGGTGGCGCGTGTTCAGTGCGCTCGAACTAGCGCGGGACTCGCTGCCGCTTGATGACTACTCGGTCGCGCAGACAACACTCGAGCAAGTTTTCCTCGCATTTACAAAGCTCCAACGTCCTATAAATTAA
Protein
MRYLVPPKAIPAKTYTSFDVTYFNKTRGNLSSADMVLAYSPINQLTEKVAINAMAELARDSIDPDIFFFISLAISYTPKGYKNAKDMEAALIQPNAMNSILLGIQFDDEIANATSWPDDIKITFRFPAVMRSTTSDHQMQLSWQTNLLFPLFPNSGPREPDDQYGGTSPGYFSELFLFMQHAISKSIVKEKTGKNIDTKIYLQRLPQLESRVDQLLFILQRFVSIAIMLGFVYTFVNTVRAVTTEKELQLKETMAIMGLPSWLHWLAWFIKQFSFLLVTIVIMVILFKIPLSETETGVSYSVFTYTPWSVLLFFLILFVIASLTFSFMISVFFTRANTAASFMALIWFATFAVFMFTQMINETMSAPVKITLCLLSNTAIGYAFQMIIIAEGTMQGLQWANFFEPISYSENFQPAHVAFMLILDSVMYMAIAVYVENIRPGMYGVPLPWYYPFTVSYWWPNRISDTNREKTSDDLEYNDALLSVVHDEEPKGVPIGVNIQNLTKRYKGRGKAVDNLNLRLYENEITVLLGHNGAGKTTTISMLTGMVPPTSGSVTINGYDIVTETEKARRSLGICPQHNVLFPDLTVAEHLIFYSKLKGIPESEINEEIDHFVKLLELDDKRHAAASSLSGGQKRRLSAGCALCGRSRVVLLDEPTSGLDPAARRALWDLLQREKRGRTVLLTTHFMDEADVLADRVAVLAAGRLACLGSPYFLKRHYGLGYKLALVKDAACQVDLVTEFFKTYVPNLKQNSNIGSELTYILPSESVSKFPEMLKKLEEKKESLCISSYGLSVTSLEEVFMKAGIEDNNVEIKETKGDIEMIDMNGDMLKDNEPLHKTQGFHLLKNHIKAMFLKLMYNTLRNKALAAIQIIWPIINIILSMIVSLSWKFLNVLPPLELSLESGFKGTETLVSQGNDLRDGSTEANVMMAYKDYFKRSTYPGLKLLDVGTSNLKNVYLKLIAEDQSRVRYEDLVGATFRNNSITAWFSNYGLHDSAISLSLVENAIIRSLSPNTTLTFVNHPLPYSVEGMVQVMSTGTNTAFMFSFSLGFCIAVISSFLVLFVIKERISGAKLLQRVSGVRPVVMWSTALIWDWIWLFLNHICIIVTIACFQEMGMSTPAELGRILLVLMVFSLAIIPLHYLASFCFEEAATGFSKMVFVNIFCGSMLFLVTEVLRMPFINAAAYAEILEYPFSLLPIYCVSKSVREMVTSSIKIKACDSLCNQLNYKNCTRLTICNELDISMCCIEDNPFLGWKEPGIARYLFTMIVVATVSFAILLAKEYELWNKVLYKKQEETMMLSGTKPKSNESKKVEVNAEVEDDDVVEEKQRVLAMTSSEVTAHSLVCRELSKRYRRLVAVDRLTFAVRGGECFGLLGVNGAGKTSTFRMLTGDARVSDGDALVHGHSVRAHVQDVHRLIGESTLLHLSSVRMLTGDARVSDGDALMHGHSVRAHVQDVHRLIGESTLLHLSSVRMLTGDARVSDGDALVHGHSVRAHVSVRMLTGDARVSDGDALVHGHSVRAHVQDVHRLIGESTLLHLSSVRMLTGDARVSDGDALMHGHSVRAHVQDVHRLIGESTLLHLSSVRMLTGDARVSDGDALVHGHSVRAHVSVRMLTGDARVSDGDALVYGHSVRAHVQDVYRLIGESTLLHLSSVRMLTGDARVSDGDALVHGHSVRAHVQDVHRLIGESTLLHLSSVRMLTGDARVSDGDALVHGHSVRAHVQDVHRLIGESTLLHLSSVRMLTGDARVSDGDALVHGHSVRAHVQDVHRLIGESTLLHLSSIRMLTGDARVSDGDALVHGHSVRAHVSVRMLTGDARVSDGDALVYGHSVRAHVQDVHRLIGESTLLHLSSVRMLTGDARVSDGDALVHGHSVRAHVQDVHRLIGESTLLHLSSVRMLTGDARVSDGDARVSDGDALVHGHSVRAHVQDVHRLIGESTLLHLSSVRMLTGDARVSDGDALVHGHSVRAHVQDVHRLIGESTLLHLSSVRMLTGDARVSDGDARVSDGDALVHGHSVRAHVSVRMLTGDARVSDGDALVYGHSVRAHVQDVHRLIGESTLLHLSSVHMLIADACVWDGDALMHGPLVRTHVQDVYCLICYCPQFDALFDNLTAREILKIFCLLRGIPTSIGETHAIHLAKQLGFIKHYDKKVRECSGGTKRKISTAVALLGDYPVIFLDEPTTGMDPASKRLVWRGISSAVGGGRSVVLTSHSMEECEALCSKLTVMVNGRLCCLGSLQHLKSKFSQGYTIIVKCKSGPNRDAAVLDVHNYMTTNFVGANLIETYLGMSTYHVSSAGLPWWRVFSALELARDSLPLDDYSVAQTTLEQVFLAFTKLQRPIN
Summary
Uniprot
ProteinModelPortal
PDB
5XJY
E-value=6.30508e-110,
Score=1023
Ontologies
GO
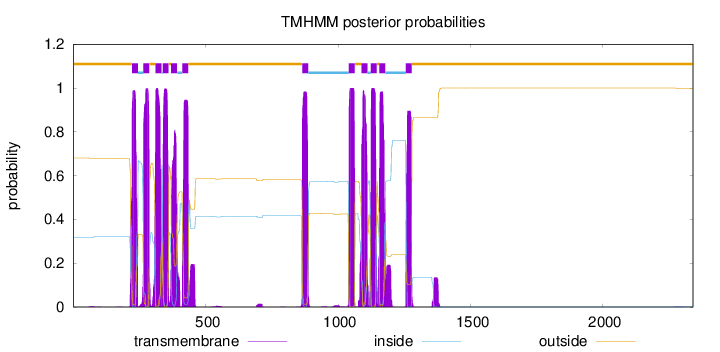
Topology
Length:
2340
Number of predicted TMHs:
12
Exp number of AAs in TMHs:
266.667289999999
Exp number, first 60 AAs:
0.00299
Total prob of N-in:
0.31900
outside
1 - 221
TMhelix
222 - 244
inside
245 - 264
TMhelix
265 - 287
outside
288 - 310
TMhelix
311 - 333
inside
334 - 337
TMhelix
338 - 360
outside
361 - 369
TMhelix
370 - 392
inside
393 - 411
TMhelix
412 - 434
outside
435 - 864
TMhelix
865 - 887
inside
888 - 1040
TMhelix
1041 - 1063
outside
1064 - 1088
TMhelix
1089 - 1111
inside
1112 - 1123
TMhelix
1124 - 1146
outside
1147 - 1155
TMhelix
1156 - 1178
inside
1179 - 1255
TMhelix
1256 - 1278
outside
1279 - 2340
Population Genetic Test Statistics
Pi
191.593755
Theta
166.558713
Tajima's D
0.325655
CLR
0.3874
CSRT
0.458427078646068
Interpretation
Uncertain
