Gene
KWMTBOMO09965
Pre Gene Modal
BGIBMGA013226
Annotation
PREDICTED:_LOW_QUALITY_PROTEIN:_uncharacterized_protein_LOC101741849_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.256
Sequence
CDS
ATGGAATATGAGCTCGCTAGGAATCTCACTCTGTTATTCTTCGTGGAACGCCTGCTCGATAAAGGCGAGCCGCGCACGTTACACGATCTTTCCTGCCAGTTTGGTGCCAAAGGATTCACTAAGGAGATGCGGCAGATAGCTGGCGGGTCACAGTCGGGGCTCAAGAAGTTCCTGGCCCAGTACCCAGCGTTGTTCAGCATAGACGGGGACTATGTTGATATCAACACGTTCCAGAAGCATCTGAGCGGGGCTGGGGTGTCCTCCAATAATGATTATATCGAGGAAGCCAAGCAGTACTTCGCTGGCAAGATGATCCAATACGGTGAAGGCACTGAAGTGCCCATCAAGAGTCTCCTCGGTCACAGGAGCCAGGCCTCCCCGCAGGTGCGTCACATCTCCGGGCAACGCATCAAGGAGTTCAAAGAGTTCCTCATGAAGCACCCTGATACGTTCCAGATCATAGATGACAATGTTGTTCTAGTCAGTGAGAATCATAGGAGAGATAACGCACACACCAACTCTGAACACTTCCATAATCTACCAGTTGCCAACATCAATACTGACACTGCCCAACAGCTTCTAGACTACATTGCGCAGTGCATTGAGGCCAAGGGCCCTGTGATGGTTGACCAGCTCTTCCATCTAATTGTGTCACGCTTCCCACAAGAATACTGGTATCAGATGTTTAAGTCTCCGGCTGATTTAAGTGCCTTTTTGAAGTTGTTCTCTGATAGTTTTCATGTACAAGCAAACCTTGTCACCCTAATTAGCAAACCAAAAATACCTGTTATGTATCTTAATGTGAAACCAAAAGTAAAGACTGACACACCAAAGCCTATGGCAGAAGAGAAAGCCCCTTCTCCTGCTCCCCCAGTGGCGGTTAGTCCTACTCCCTCAGATGGCAAACAGAGCCCTGCAAACAGAATACTCAGTCCCATAGAATCTCCCCGCGGTCAACAATCCAATATTGCTAATCAAACACTTAAACAAAGAATCAATTCTATTGTAATTAAGAATTTGGCTGAAAATATGGTCAGAGATAGGGTAAATAATCATTTGAATGCAAGAAACTCTGAAGAAACCAACGGTACTCCAAGTTTGAGGAATACTGTAGTAGGTGATGTATGGAGACAAAAAGTTCTGCAATGCACCACAGTCATAACCAGTGTTAGAGAATGTGCAACTTTAATTGATAGCATTATGGCTCCAAAACGCAACGCCAAAAATATAGTCTCCTTTGATTGTGAAGGAATAAACCTGGGTCTCAAGGGAGTGTTGACATTGTGTCAAATAGCCACTCTGAATGGTGAGGTGTACACATTAGATATAATGACATGCCCAGGTATGATAAATGAAGGAAAAATTAAAGAACTATTAGAAAGCGAGCATGTCATTAAAATTATTCATGACTGCAGAAATGACTCGGTTAATTTGTACAATCAATTTGAGATCACAATGAAGAATGTGTTTGATACACAGGCTGCCCATGCTGTGTTGCAATTACAACAACAGGGTGTGCCTGTTTACAAAGTTAAGAATCTTAGCTTGAATGCTCTATGTGAATTATACAATGCTCCAATGAATCCAATGAAAGAACAATTGAAGAACTTGTACCGTAGGGATCAAAGATACTGGGCCCGCAGACCTCTTACAAAAGATATGATAATTTATGCTGCTTCAGATGTGCTTTCTTTAGTAAACCCTGCAATATATGCTTATATGTCATCTAATATTATGCCAGAAAACCAACAACTTTTTGAAGAATTAAGCAATGAGCAAGTGTTTATGCATATTCAACCCACAGAAGTTAAACTTCGCAAGAGACAAAGGAAAATTAACACAGAAGTGGGTGAGCTAAAACAGAAATTGGCAGAGAGCACTAAAAATATTGTGTTGAGCAATAGGGAGATACGATTACTCCGATATTTAGAACTTACAGAAGAAGAAAAAGAAAAATTAAAAGGTTGTCACAAAATATCTAAGAAACTAGAGAAATTGGAAGCAATCGGGCAAGATAGAGACTCTGATTCAGATGATGATGACAGGGAGAATGAGATGGCTAGCTTGGATTCTAACCCCTCAGACCCAATTTCATCACCCCATTCCACACAACCACCCAGCCTCACAGAGTCAATGCAAATGATGGATGAGATCTTGTCGGACACCAACATGGATAAGGTTGAAAAGATAAATCGCTTAGAAGCTATATTATCAGCAGTGGCTCCCCTCAGTGGGGAACTGGAAGAGAAATTCTCACAGACAATGGAACAAACATTACCACTGCTAAAAAACAAAGATTGGTCGAATCTGAGCCAAATTCTGAATATGGGAGACACAGAAAACAAGAATTGTTGCTGCAAATGCCATAACGGTGGTTTTGAAGAGGTGAAATGCAATGATCTCAATGAATTGAAAAAATCAGAGGTCGGATCACAAACTCTTAGCACTGGAGATATAGTCATCACAAGAATACATTTTAGGGAGGAGGACAAGGTTAATGAGAGGGTTGTGGATGCGTCCCCAATGAGTAAAAGGTCAAATGAAAAGTTAATAACTTACCAAACGTTGAGAAACATGGAAGATTTCGATGTATTCACAAATAAAATACATATCACGAAGCCGATTTACAAGAATATATTGAACAAATTCGCTAAGGATATACCTGCGACTCCATTTGGCCCTAATTATCAGAGTGCGAGAAAATTGTTGGCTGAACAATGTCTGATGGATGGTGACGAAGCTGGATGTGCGTTTCACTTCAGCGAATCAGTGTTCGCTACTTTAAGGACCATGGCAATTTATAGGGACGAGCAGATAAAATTAGCCAATGACAACCTAAGAAAGATAACAAGTTACATAAAACCTGTACAAGAAATAATTGAAGCTAATCCAAAGACTGATGACCAATTAATTGATAACTTAATTAAAATAAATGACATAGATGTAACGGGAGTTTTAGACTCGATCAAAACAGACGATGAACTACCATTTCACCAGAGATACTTGAAATTCAGCTCTGAAAATAATATTGACAACTTCAGGAGGATACTGAAGGAATTGCCGAAAGAATGGACAGTAATACAATTGACCGCACCGTACAATCCGAATGAAAATTTGAAGCAAATGGATGAGTTCAGAACAGAGGTGGATTCGATATATTTAAGCGTTTTCACTAATGATTACTTAGATGACAGTAATTTGGGTCCATTTACTATAAACATTCCAGCTAATCGACACAAAGAAGGCGAAAGACCACTATTCACGGAGCTGTACTCGTTGTTGGACGAAAACTACAAGACCATCGAGAACGCGCAGTTCCTCAACAACAAGAGGCTCGTGCAGGACTACTGGGCCAAGCGCGAGGACATTGACCTCAGAATGAAGAGTGTAATTAACGTGATGGACAAGGAATGGCTCGGCGGATGGGGCAGCTTGCTGACTGGTAAACTTATTGATACGAAATGGAAAGAAAAAATCAAGAGCACAGTACAGAATACCGTCTCTGACTGGGGGTTAATGGGACTAAATGAGAAGCAAATGATACTCTTGTACAATCTCATGGAGAGTTGCCCAGTGTTGTCATCGCAGCAGCTAAAATCGTGCATAAGGAAAATCCTGACGGAACATGGCAATACCGAGCGTTTCAGACAGGCGCTGACGTGCTGCGAAAGTTGCAGCAAAGATTTTAATTTACTGAACGAATTGTGTCTGAAATGTTTGTCGAAATGCTTCGAGGCCGTCCACCATTTTACGTTGGTAGACGCGATACGAGCGTTTTCTCAGCTGGCAATTCAGATAAAGGACTGCAACGAGTGGGCAACACTGAAGAAAGCTAAACGACACCCCGTCATATTGATTGTTGATGAGGCGCTGGACACGTTCCCGTGGGAGAGCACGGCGGCGCTGCGCGAGCACCCCGCGTCCCGGATGGAGAACGTCCACTTCCTGTACCACCTGTACAAGCTGCACGAGGGGCGCGTGGCGGCCGGGCACTACGTGGCGTCGGGCGGCGCCGGCAGATACGTCATCAACCCAGAGAAGAATTTAGACCGAATGGAGAAGAGAATGAAGTCGTTCGTGGAGTACTGGTGCGAGTCGTGGCGCGGCTGCACGGGCTGCGCCCCCACGCCAGAGCAGTTCATAGAGTACTTGAACGAGGCAGACATATTCCTGTACTGCGGCCACGGCGACGGGTGCCGCTGTGCGGGGGGCGGCTCCGTGGTGGAGGGGGGCGGCGCTCGCTCCGTCTGCGTACTCGCGGGCTGCGGCTCGGTGCGCCTGTGTCGCACGCAGCCTCGCCGCCCGCCGCGCGCCGCGCACCTGCATCTGCACGTCGCCGGCAGTCCAATGGTGGTCGGCATGCTATGGGAGGTGACCGACCTAGAAGTGGACAAGGTGGTGACGACGATGATGTCCCTGTACGTGCCGTCCCGACAGGCGCTGCCCTGGTCGGCCGTGGGGAAAACTAAATGGAGCCAGGGGATTATCGATGTGAGCCCGCCCGGCTGCCCGGCCCGGCCGCCGCACGAGCCGCAGCTGCTGCGCGCGCTGGGCGCCGCCCGCGCCTCCACCAACTTCATCATGATCGCCAGCAGCGTGGTGGCCAGGGGGCTGCCCGTCAAGAACTACCAGTGA
Protein
MEYELARNLTLLFFVERLLDKGEPRTLHDLSCQFGAKGFTKEMRQIAGGSQSGLKKFLAQYPALFSIDGDYVDINTFQKHLSGAGVSSNNDYIEEAKQYFAGKMIQYGEGTEVPIKSLLGHRSQASPQVRHISGQRIKEFKEFLMKHPDTFQIIDDNVVLVSENHRRDNAHTNSEHFHNLPVANINTDTAQQLLDYIAQCIEAKGPVMVDQLFHLIVSRFPQEYWYQMFKSPADLSAFLKLFSDSFHVQANLVTLISKPKIPVMYLNVKPKVKTDTPKPMAEEKAPSPAPPVAVSPTPSDGKQSPANRILSPIESPRGQQSNIANQTLKQRINSIVIKNLAENMVRDRVNNHLNARNSEETNGTPSLRNTVVGDVWRQKVLQCTTVITSVRECATLIDSIMAPKRNAKNIVSFDCEGINLGLKGVLTLCQIATLNGEVYTLDIMTCPGMINEGKIKELLESEHVIKIIHDCRNDSVNLYNQFEITMKNVFDTQAAHAVLQLQQQGVPVYKVKNLSLNALCELYNAPMNPMKEQLKNLYRRDQRYWARRPLTKDMIIYAASDVLSLVNPAIYAYMSSNIMPENQQLFEELSNEQVFMHIQPTEVKLRKRQRKINTEVGELKQKLAESTKNIVLSNREIRLLRYLELTEEEKEKLKGCHKISKKLEKLEAIGQDRDSDSDDDDRENEMASLDSNPSDPISSPHSTQPPSLTESMQMMDEILSDTNMDKVEKINRLEAILSAVAPLSGELEEKFSQTMEQTLPLLKNKDWSNLSQILNMGDTENKNCCCKCHNGGFEEVKCNDLNELKKSEVGSQTLSTGDIVITRIHFREEDKVNERVVDASPMSKRSNEKLITYQTLRNMEDFDVFTNKIHITKPIYKNILNKFAKDIPATPFGPNYQSARKLLAEQCLMDGDEAGCAFHFSESVFATLRTMAIYRDEQIKLANDNLRKITSYIKPVQEIIEANPKTDDQLIDNLIKINDIDVTGVLDSIKTDDELPFHQRYLKFSSENNIDNFRRILKELPKEWTVIQLTAPYNPNENLKQMDEFRTEVDSIYLSVFTNDYLDDSNLGPFTINIPANRHKEGERPLFTELYSLLDENYKTIENAQFLNNKRLVQDYWAKREDIDLRMKSVINVMDKEWLGGWGSLLTGKLIDTKWKEKIKSTVQNTVSDWGLMGLNEKQMILLYNLMESCPVLSSQQLKSCIRKILTEHGNTERFRQALTCCESCSKDFNLLNELCLKCLSKCFEAVHHFTLVDAIRAFSQLAIQIKDCNEWATLKKAKRHPVILIVDEALDTFPWESTAALREHPASRMENVHFLYHLYKLHEGRVAAGHYVASGGAGRYVINPEKNLDRMEKRMKSFVEYWCESWRGCTGCAPTPEQFIEYLNEADIFLYCGHGDGCRCAGGGSVVEGGGARSVCVLAGCGSVRLCRTQPRRPPRAAHLHLHVAGSPMVVGMLWEVTDLEVDKVVTTMMSLYVPSRQALPWSAVGKTKWSQGIIDVSPPGCPARPPHEPQLLRALGAARASTNFIMIASSVVARGLPVKNYQ
Summary
Uniprot
ProteinModelPortal
PDB
5FC2
E-value=4.99762e-11,
Score=169
Ontologies
GO
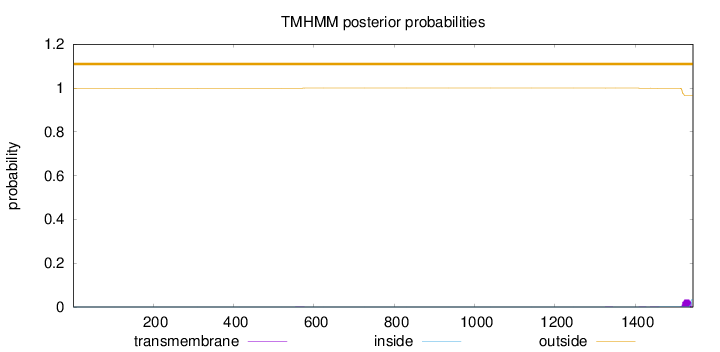
Topology
Length:
1544
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.74068
Exp number, first 60 AAs:
0.00029
Total prob of N-in:
0.00045
outside
1 - 1544
Population Genetic Test Statistics
Pi
268.770316
Theta
212.553155
Tajima's D
-1.329863
CLR
32.300745
CSRT
0.0829958502074896
Interpretation
Uncertain
