Pre Gene Modal
BGIBMGA013258
Annotation
PREDICTED:_uncharacterized_protein_LOC101740626_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.943
Sequence
CDS
ATGTTCTTTCAGGGTGATTGGGTGTATCCTTATCGTCCGGGAGATTATGCAACTCTAACGAGAAAGTACCTCGGCTCTTTGTACTGGTCCACGCTAACCCTGACCACCATAGGGGACCTGCCGACTCCGGAGACCAATGCCGACACGCAAGGAGGCCCCAAATTTCTGCCGCGCCGCGGACTGAAGTCCCGTTTACTGCAGTTCAGGTCCAACAGAGGGTACGTGTTCACAATAGTAAGCTATCTAATTGGGGTGTTTATATTCGCAACTATTGTCGGACAAGTCGGGAATGTCATCACTAATAGGAACGCGAACCGTCTCGAGTTCGAGAGGCTTCTGGACGGAGCCAAAACTTACATGAGGCACCATAAGGTGCCGGGTGGTATGAAACGTCGTGTATTACGATGGTACGATTACTCGTGGTCCCGCGGCAGGATCCAAGGAGGCGGTGACATCAACACTGCTCTAGGGCTGCTACCCGATAAACTGAAGACCGAACTTGCTCTGCATGTCAATTTGAGCGTACTTAAAAAGGTCACCATCTTCCAAGAGTGCCAGCCGGAGTTCCTTCATGACCTCGTCTTGAAAATGAAGGCTTACATCTTCACACCTGGCGATTCCATTTGTCGTAAAGGGGAAGTTGCTAGAGAAATGTTTATAATAGCCGATGGAATCTTGGAGGTGATATCGGAAACCGGACGAGTACTAACCACCATGAAGGCTGGAGACTTCTTCGGCGAAATCGGGATATTGAACTTAGACGGATTGAACAAACGGACAGCAGATGTCCGTTCCGTTGGTTATTCGGAGCTGTTCTCACTTTCGCGTGAAGACGTGCTCGCTGCGATGAAGGACTATCCTGAGGCGCAGGAGATCCTCCAGACCCTGGGCCGGAAAAGACTGCAGGAAGCCAAGAACATGTCAAGACAGAAAGTCAAGGGAGAAACCAGTCCGGATAAAAATGCTGGTGACGACAGCGGTCCCAAAAGAATAGTCCACAAACTGAGGAGTGATGTCAAGGGCATCCGTAACGCCATACGCAGCAGATCGCGCGGGGGGCGCCGCTCGGCGGACGAGGAGCGCGCGGGGCGGGGGGGCGGTGCAGCCAACGGGGGAGGGGGCGGCGAAGGGAAGGTGCTGCGACGAATGAACCGAGTTGAGAGTGATGACTCACAGGCCCACGGACCTCACGAGGATAACAATGGGGAAACAACATCAGGCAGCAAAGATGGTGAGAAATGCGTTTCTCCCATAGGTGCAGGACTACCATTATTATCGAGATTAAAACTTCTAAAGGAAAAACAGGATAGAGAAGAAAAAGTTGCAAAACAAAGGCATTCAACTTCATCAGTTGTATCGTTAAATATACAAACCCAGCCGATCCCATCCACAAGTGCGGCTCCTGATGAACCTGAAGTAATCGGAGCTGGTTTACCGCTTATTCAAAGGCTGATGCTCCTCAAAGCGAAAGAAGAACGCGAAAAAAATCAGCTAACCCCAACGACCAGCAACCAACCTTCCAGCTCCGACACAATAAGTCCCACCTCTATCAAAAGTCCGTTGAGTCCAACAGTTAAAACTTTAAGTCCCATTAGAAAAGGCTCTGAGTCCAGTTCCCCGGGAAAGCTTCAAAGTCCAACCACCAGGACTTCTAGAAAAAATTCCTCCGGCTCCAGTGACGGGACTTCTAGACCGAAAGTTAGCTTCAGAGACAAAATTCTGCAAGTCCAGAGTGACGGTACAGCTGTTTGCCAGCCTCTAAATAAAGATGGTAGCGAAAAACCGTCAGCAGTCGTTGAGCCCACACCTAAAACAGAAAGCAATTTGATTTCGATTCCACATTCTGTAGTGAGTAAGATAAAATCGCCAGCGAAAGTTGTTGGAACTACTTTCAGGGATAAACTAAAGCTTCTGCAAAGTGGTGGTAAAGATTCAGATACGACTGCAGAAAAGAAAGCTTCATCTTTTGAGAAAAATCCAATAGAAATACCTCCCATACAAATTACGGACAATAAAGAAGAGATTAAAAATAAAAAGCCGTGGTCGAAACTAAAAAAGGCCGCGATTTTAGGTGAATCAAAAAGCCAAAGTAAATCTAGCTTGGAAGAAAAGAAAGATGATGTAACTAATGAAACGCCCGAAGTAATCGTAGAGTCCTGTGTAAAAATATGTGTTCCCGTTGTAACAACTGCGGAACTGGTGAAGATAGACAATAATAATGTTCAAGTTATAAGTGATAGTGATAAGTCGGAAAACCCTAAGGTATGCTTAACGGGCCCTATAGAAACCGTCCAGGAGAAAAGCCTAGATTTGATGACATTATCGCCGAAAAGAAACGTAGCGAAAACTACTGAAACTAAAAATCTCGGCACCCTTTTACCCAAAGTTAAAAAGTATAGATCTATCGATGATCTCTCGCCAGAATACGGAGGATTGCCATTCGTTAAGAAACTCAAGATTTTGAACGAAAGACAGAAATTAGCTGAATTGGAAAAGGTGGTTAAATTTCGAAGTTCAAGCTTAGATTGCACCAGTTCTTCGGAGGATCTACTTTGCGACACATTAACTAGAAGTCATTCAGAAGGCAGCACAATGGACAAAAGGAAATATAAGCGAAAATCTACTGACTCAATCGGAAGTCATGAATCCAATGAAACCCTAGAAAGACGAACATTGAAATCTATATTAAAGAAGTTATCAGAAGACGTGACCCCAGCCGAGAGTCCTGAACGTAGTAATGAATTAAGGAAATTAATTCGAGCACCAACTCTCGAAGGATACGCAGCGAGACACTCAAAATTTGCCAAAAGTGTGACCTTTCATAGGCACACATTACCTTCACCTCCGGCTAGTGCTCCCGCTGACACTAAATGTGCCGTTTTTCAAATCCCAGACGTTCCCATTCAAGTTCCACAAATATCGCCTCCGTTGACGGAAGCTGAAGTGGTCGAACCTGATCCGTGTAATCAAATCACAAGACCGATAGAAGATACGATAGTCACCAAAGAGACGGGCCTGAATTTCAGAACGGAATATCATCTGCAACAGAATATGGATCCGATGTACGATTTCAAAAACTTGAGGCCCGAAGATATTAAAGTGCCCAAAGAAAAACCTAAACTTACTATAATATCGGCTGTTGCAAATCAAAGGAAACTACTCAGAGGCTCCATCGAAGAACAGGAGTATTTTGGGGAAGTTCTCTTGGGAATCAAACAAGTTATACAAGGACATCTACAAGACGTCCAGTTAAAATTTCAAGAAAGATTTACAAGTTTAGAAAATGAGGTTCGCAAGCGTGACGAGATCATCAGCCAACTGCAGAAGAGGATTCAGGAACTCGAGCGGCTCGGGCTCGCGTCCAGCGCGGGGGCGGTGCCTCTGGAACTACCTGTCGCCGTCACCATGAAAAACAGCTCCGGGAGTGAAGAAGAAGAAGACCTTGAAGAAGGATTTATGCGAGGTGATTCTTTAGACACGGTATTCGCCTCGTCTCCACCAACAGCCAGCGCTGAAGACGACAGTGCAGCGAGACTGGAACAGTCCCACGAAGAGATCCCAGAGAGCATCAGCGACGAGAAATTATCAGAGATGACTGAAGGCATCGAATTAGAAAAGCTTTCGTACTCAGAGCTGCAGAGTTTGGCTGAGTCTTTGACGAAAGGCGATAAAAGCTCTTCGAGTAAGGAGGAGTGGTCTATTAGCAAGTCGAAGAGGATGGACCTAAACCTGGACGGGAAGGCGGGAACTTATTCGAGGAAGCGGGCTGCTAAATTGAGGCAGAGAAAGTCTTGGGAAGATCAGAGCGATCAAGAGAGTGTTGAAATGCATGATCTCACGAGGCCATTATCCCCGCACACAATGTCTGAAGACCGCTCCTTGCTGAGTCCAGAACAGTCCAGCCTCCGCAGCAGCAGGAGGACCACTCCCTTCCACTTCTTCGGCTCGCATCTCGACAACACCAAATCAAAAATCAAAAAGACCTTGTCTGTTGACACCGGAATGCATCACACGGGCAGGAATGATAGAAAACAATCTGGTAAACGCGAACATCGGAAGTTCAGTCTCGGTTCGTTCTTTGGACAACAGCGTCGACCCGTCGCCAGGACTCACGACGACGTGGTGCTGGACATGGGCAGTGACCTCAGCTGGACAGATTCATTATCAACATCTTCCAGTAGCGACTCCGAGTCTCCGCCGCGGACGCCCGCCTTCGAAGAGTTCGCGAGTCGGTCCCGACACGCCCCAGTCAGCAGGTTGTCAGGGAGTGGCGGAGACTGGGAGGTGATGATGCTGGCCGACGAACTAGAGAAGAGAGAACGAGAAGAAGCCAGAAGACACCAGTACGAGACCACACTGCGGGAGCTTGAAGAGGAATCAGACACACCACTGCGTGATGAAAGCCCAGAGCGGTCACCGGCCTCTGTACCACTGCTCCCCCAATCATCTTACTTGCAAAGAACTCCTACGAGACAGTACAGAGTCGCTTCATTGGTTGAACCGCTAGGACCAGAGTCTTCGCTCCGACAATCAAGAGGGCTGATCCTCCGAGCGGCGAGTCTTGATCGAGAAACCACTCCATCCTCGGAAACTCGTCGATTCGGCTCCCTGAAGAACACCAGTACAGAATCGCATAAGCGACTCTGA
Protein
MFFQGDWVYPYRPGDYATLTRKYLGSLYWSTLTLTTIGDLPTPETNADTQGGPKFLPRRGLKSRLLQFRSNRGYVFTIVSYLIGVFIFATIVGQVGNVITNRNANRLEFERLLDGAKTYMRHHKVPGGMKRRVLRWYDYSWSRGRIQGGGDINTALGLLPDKLKTELALHVNLSVLKKVTIFQECQPEFLHDLVLKMKAYIFTPGDSICRKGEVAREMFIIADGILEVISETGRVLTTMKAGDFFGEIGILNLDGLNKRTADVRSVGYSELFSLSREDVLAAMKDYPEAQEILQTLGRKRLQEAKNMSRQKVKGETSPDKNAGDDSGPKRIVHKLRSDVKGIRNAIRSRSRGGRRSADEERAGRGGGAANGGGGGEGKVLRRMNRVESDDSQAHGPHEDNNGETTSGSKDGEKCVSPIGAGLPLLSRLKLLKEKQDREEKVAKQRHSTSSVVSLNIQTQPIPSTSAAPDEPEVIGAGLPLIQRLMLLKAKEEREKNQLTPTTSNQPSSSDTISPTSIKSPLSPTVKTLSPIRKGSESSSPGKLQSPTTRTSRKNSSGSSDGTSRPKVSFRDKILQVQSDGTAVCQPLNKDGSEKPSAVVEPTPKTESNLISIPHSVVSKIKSPAKVVGTTFRDKLKLLQSGGKDSDTTAEKKASSFEKNPIEIPPIQITDNKEEIKNKKPWSKLKKAAILGESKSQSKSSLEEKKDDVTNETPEVIVESCVKICVPVVTTAELVKIDNNNVQVISDSDKSENPKVCLTGPIETVQEKSLDLMTLSPKRNVAKTTETKNLGTLLPKVKKYRSIDDLSPEYGGLPFVKKLKILNERQKLAELEKVVKFRSSSLDCTSSSEDLLCDTLTRSHSEGSTMDKRKYKRKSTDSIGSHESNETLERRTLKSILKKLSEDVTPAESPERSNELRKLIRAPTLEGYAARHSKFAKSVTFHRHTLPSPPASAPADTKCAVFQIPDVPIQVPQISPPLTEAEVVEPDPCNQITRPIEDTIVTKETGLNFRTEYHLQQNMDPMYDFKNLRPEDIKVPKEKPKLTIISAVANQRKLLRGSIEEQEYFGEVLLGIKQVIQGHLQDVQLKFQERFTSLENEVRKRDEIISQLQKRIQELERLGLASSAGAVPLELPVAVTMKNSSGSEEEEDLEEGFMRGDSLDTVFASSPPTASAEDDSAARLEQSHEEIPESISDEKLSEMTEGIELEKLSYSELQSLAESLTKGDKSSSSKEEWSISKSKRMDLNLDGKAGTYSRKRAAKLRQRKSWEDQSDQESVEMHDLTRPLSPHTMSEDRSLLSPEQSSLRSSRRTTPFHFFGSHLDNTKSKIKKTLSVDTGMHHTGRNDRKQSGKREHRKFSLGSFFGQQRRPVARTHDDVVLDMGSDLSWTDSLSTSSSSDSESPPRTPAFEEFASRSRHAPVSRLSGSGGDWEVMMLADELEKREREEARRHQYETTLRELEEESDTPLRDESPERSPASVPLLPQSSYLQRTPTRQYRVASLVEPLGPESSLRQSRGLILRAASLDRETTPSSETRRFGSLKNTSTESHKRL
Summary
Uniprot
EMBL
Proteomes
PRIDE
Interpro
SUPFAM
SSF51206
SSF51206
Gene 3D
CDD
ProteinModelPortal
PDB
5H3O
E-value=1.9246e-60,
Score=595
Ontologies
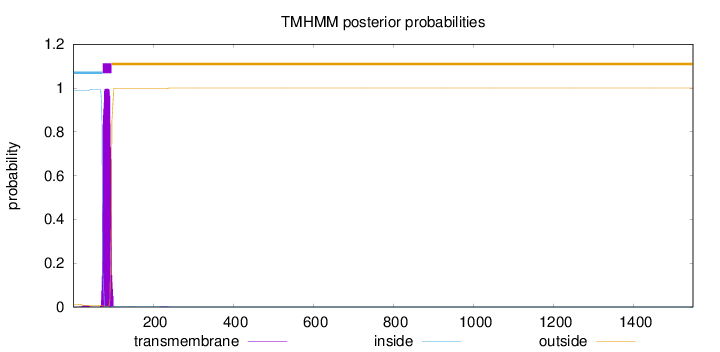
Topology
Length:
1548
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
22.40708
Exp number, first 60 AAs:
0.12855
Total prob of N-in:
0.98748
inside
1 - 73
TMhelix
74 - 96
outside
97 - 1548
Population Genetic Test Statistics
Pi
289.466153
Theta
178.083608
Tajima's D
2.411153
CLR
0.311082
CSRT
0.933503324833758
Interpretation
Uncertain
