Gene
KWMTBOMO09542 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA013025
Annotation
PREDICTED:_eukaryotic_translation_initiation_factor_3_subunit_A_isoform_X4_[Papilio_polytes]
Full name
Eukaryotic translation initiation factor 3 subunit A
Alternative Name
Eukaryotic translation initiation factor 3 subunit 10
Location in the cell
Cytoplasmic Reliability : 1.744 Nuclear Reliability : 1.938
Sequence
CDS
ATGGCGCGATACGGTCAAAGACCGGAAAATGCCCTTAAACGGGCCAATGAGTTCATGGATTTGGACAAACCAGCAAGGGCCCTAGACACCTTACAGGAAGTTTTCCGTAACAAAAAATGGGCCTACAACTGGTCCGAATCTGTCCTAGAACCAATCATGTTCAAATACTTGGAACTTTGCGTTGATCTACGTAAATCTCATGTTGCAAAGGAAGGTCTGTTCCAGTACAGAAACATGTTCCAATCAGTTAACGTTGGGTCTTTGGAGCAGGTTATAAGAGGCTATCTCCGTATGGCAGAGGAACGCACAGAAACAGCCAGGGCTTTATCGACGCAGGCCGTCATAGACACTGATGATCTGGATAACCTTGCAACCCCGGAGAGCATACTCCTGAGTGCAGTGTCAGGTGAAGATGCCCAGGACCGATCTGACAGAACAATACTCACACCATGGGTGAAATTCCTTTGGGAATCCTACTGCCAATGCCTGGAGCTCCTTCGTACGAATGCTCATGTGGAAACCTTGTATCATGATATTGCTCGCATGGCCTTCCAATTTTGTTTAAAGTACTCGCGAAAAACAGAATTCAGAAAGCTTTGTGATAAACTAAGGAAACATCTTGAAGATATTTGCAAACCTACAGTGCAAACTGGTAACGTTAGCATTTCAAAACCAGAAACTCAACAGCTGAACCTCGAAACAAGATTGTTCCAGCTCGACTGTGCAATTCAAATGGAGTTATGGCAGGAAGCCTATAAAGCCATTGAAGACATCCACAACCTAATGAACATGTCTAAAAAAACTCCAGTCGCCAAAACTATGGCCAACTACTATGGGAAACTGGCACTTGTTTTCTGGAAAGCTGGCCACTGCCTATTCCATGCTGCAGCCTTGCTGAAACTCTTCCAGCTATACAGGGAGATGAAGAAGAACATCACCCAAGAGGAACTGCAGAAGATGGCGTGTCAAGTACTGGTAGCGGTGCTGTCTGTGCCACTGCCATCTCTACACCCTGAGCTCGATCGCTTTGTCGAGACGGATAAGAGCCCTGTTGAGAAGGCCCAACGTTTGGCTGTACTGCTCGGTCTTGCTCAACCACCGACCAGGGCAAGTCTTTTGAAAGATATCGTCCGCCTTAACGTCGTGTCGCTGGCATCGCCTCAACTTCAACAGCTTTATTCTTGGCTTGAAGTGGAATTCGACCCTCTGACCATCTGCCTTAATGTCAAGGGTGTTATCAAATCTTTGCAGGATGAGCCAAATTCATCGCTCGCTCAGTACACCAATGCCTTGACGGACGTGGCCCTGGTGAGGCTGATCCGTCAGGTGGCCCAGTGCTACGCGTGCGTGCAGTTCTCCCGGCTGCTGGAGCTGGCGGCCACCGACGACCTGTTCCATCTGGAGCGCTTGCTCGTCGACTGCGTGCGCCACAACGACATGCAGATACGCATCGATCACGCCAACAAGTGCGTGCACTTTGGCGTAGAAGCGGGCGGCGGCGAGTGGTGCTCGGCCGCGGACGAAGCCTGCGGCGGGGCCATCCTGCAAGCCACCCCGGCGGAACAGGTCCGCGAGCAGCTGGTCCGCGCGGCGGAGGTGCTGTCCCGCGTGGTGGGCGCGCTGTACCCGCAGCGGCGCGGCGCCGAGCGGGAGCGCGCCCGCGCCGCCATGGTGCAGTACTACCACGAGAACAAGCAGGCCGAGCACCACCGCGTGCTGCAGCGCCACAAGATCATCGAAGAACGGAAGGAGTACATCGAGCGACTCAACACCGTGCGCGAGGAGGAGGAACTCAGGCGTCAAGAGGAGCAGCTCCGCGCGGCCGCCATCGCCGAGGCCCGCCGCTTGGAGCAGGAGCGTGAGGAGCGCGAGAAGAAGCGCCACGCGTCGGAGCTGGCCGCCATGAGGGAGCGACACCTCAAGGAACGCATGGCGCACATCTCTCAGACCGCGCACGGACAAAAGATGCTCGGAAAACTCAATGAGGAGGATCTTAAGAAAATGGATGCTGAAGCTATTGCTCAGCGGGAAGCTGAAGAACTGATGAAGGAACGTCGCGAGCTTCAGGCTAGACTGAAGTCACAGGAGAAAAAGGTGGATTACTTTGAGCGTGCCAAGCGATTGGAAGAAATACCACTTCTGCAGAAGAGCCTGGAAGAGAAACAGGTTCAAGACAAGGCATTCTGGGAGCAACAGGAAAAAGAACGCATCGAACAACTCATAGAGGCTCGCGCCTTAGACGTGGCCACGTCGGAGCGCATGTCCCGCATGGCGGTCCACCGCGACGAATTCATGGCGCGACTTCGCTCGGAACGTGGGGCCGCCTACGCTCAAAAGGTAGCCGCTTTCAACGAGAAACTTCAAGCCGAGAAGGAAAAGAGATTAGCTGAGAGACGCGCTCAGCGAATCGAGAAGAGAAGACATGAGTGGATAACAGAGAAGCGTCGCGCTGAGGAACGTGCGGCTGAGGAAGCTCGACGCATCAAGGAAGAGGAAGAAAAGAGAGAAAGGGAAGAACGAGAGAGGAAACAGCAAGAAGAAATGGAAGCGTTGAGAGAGAAAAAAGAGAAAGAACACAAAGAGATGTTGGCACGCGCCGAGGCCAAGGCCCGCGCCAAGGAAGCCGAGATACAACGGAAACTGGAGGGACAACGCGCCGCCGTCCCCCCGCCCGCCACCTCCTCCAGCTGGAGACGAGGACAACCTGCCCCTACCGAACGAGACGACGCCTGGAGGGGCAAGGAAGCACCTGATGCTGGGGAAAAGAAGTCCTCTGATCAATGGAGAACCAGTCGTGTCCGTGAACCCGTACGTGACGAGCGAGCTCGCAGTCCGGAACGACGCCGCGAAGATCGTCCACCCCCCAGGGATGAGCGGCCGTCTCTTAGGGACGAGCGTCCGCCTCCCAGGGACGAAAGACCACCGCCCAGGGACGAAAGACCACCGCCCAGGGACGATCGTCCACCACCCAGGGATGATTGGGCTAGGGAAGACAAACGTGAAGAACGTCCACGGGAAGATCGTTCCAGGGAAGACAGACCTGCACCGAGAGATGATGGTGCCTGGAGATCAGCTAACCGAGAACCGGACAGAGACAGACCTCGCTATGGCGGCCGATCCAGTGGACCCGAGACCAGCTGGCGTCGCGGACCTGCCGAGCCACGACCAGCGCCTACCGAACGCTCTGGAACCTGGCGTTCTAAGGACGCACCACCGCGCGACGATCGGTTCAGAGAGAGAGACAGATATCCACCCCGCAGAGATGAACGTGATGGACCTAGGCGTGACGACAGAGACGGTCCCAGACGCGATGATAGAGACGGTCCGAGACGCGATGACAGGGACGCTCCCAGACGCGATGACAGAGATGGTCCCAGACGTGACGATAGGGATGGTCCCAGGCGTGACGATAGGGATGGTCCCAGGCGCGACGACAGAGACGGACCTCGACGTGACGATCGTGATCGTCGCCCTCCGCCCCCTCGTCGCGATGAAAAACCTCGCGATCCTGAAAGCAGCGGTTGGCAAGAAGTGCGGCGTTGA
Protein
MARYGQRPENALKRANEFMDLDKPARALDTLQEVFRNKKWAYNWSESVLEPIMFKYLELCVDLRKSHVAKEGLFQYRNMFQSVNVGSLEQVIRGYLRMAEERTETARALSTQAVIDTDDLDNLATPESILLSAVSGEDAQDRSDRTILTPWVKFLWESYCQCLELLRTNAHVETLYHDIARMAFQFCLKYSRKTEFRKLCDKLRKHLEDICKPTVQTGNVSISKPETQQLNLETRLFQLDCAIQMELWQEAYKAIEDIHNLMNMSKKTPVAKTMANYYGKLALVFWKAGHCLFHAAALLKLFQLYREMKKNITQEELQKMACQVLVAVLSVPLPSLHPELDRFVETDKSPVEKAQRLAVLLGLAQPPTRASLLKDIVRLNVVSLASPQLQQLYSWLEVEFDPLTICLNVKGVIKSLQDEPNSSLAQYTNALTDVALVRLIRQVAQCYACVQFSRLLELAATDDLFHLERLLVDCVRHNDMQIRIDHANKCVHFGVEAGGGEWCSAADEACGGAILQATPAEQVREQLVRAAEVLSRVVGALYPQRRGAERERARAAMVQYYHENKQAEHHRVLQRHKIIEERKEYIERLNTVREEEELRRQEEQLRAAAIAEARRLEQEREEREKKRHASELAAMRERHLKERMAHISQTAHGQKMLGKLNEEDLKKMDAEAIAQREAEELMKERRELQARLKSQEKKVDYFERAKRLEEIPLLQKSLEEKQVQDKAFWEQQEKERIEQLIEARALDVATSERMSRMAVHRDEFMARLRSERGAAYAQKVAAFNEKLQAEKEKRLAERRAQRIEKRRHEWITEKRRAEERAAEEARRIKEEEEKREREERERKQQEEMEALREKKEKEHKEMLARAEAKARAKEAEIQRKLEGQRAAVPPPATSSSWRRGQPAPTERDDAWRGKEAPDAGEKKSSDQWRTSRVREPVRDERARSPERRREDRPPPRDERPSLRDERPPPRDERPPPRDERPPPRDDRPPPRDDWAREDKREERPREDRSREDRPAPRDDGAWRSANREPDRDRPRYGGRSSGPETSWRRGPAEPRPAPTERSGTWRSKDAPPRDDRFRERDRYPPRRDERDGPRRDDRDGPRRDDRDGPRRDDRDAPRRDDRDGPRRDDRDGPRRDDRDGPRRDDRDGPRRDDRDRRPPPPRRDEKPRDPESSGWQEVRR
Summary
Description
RNA-binding component of the eukaryotic translation initiation factor 3 (eIF-3) complex, which is involved in protein synthesis of a specialized repertoire of mRNAs and, together with other initiation factors, stimulates binding of mRNA and methionyl-tRNAi to the 40S ribosome. The eIF-3 complex specifically targets and initiates translation of a subset of mRNAs involved in cell proliferation.
Subunit
Component of the eukaryotic translation initiation factor 3 (eIF-3) complex.
Similarity
Belongs to the eIF-3 subunit A family.
Uniprot
EMBL
Proteomes
PRIDE
Pfam
PF01399 PCI
ProteinModelPortal
PDB
6FEC
E-value=8.95824e-175,
Score=1580
Ontologies
GO
PANTHER
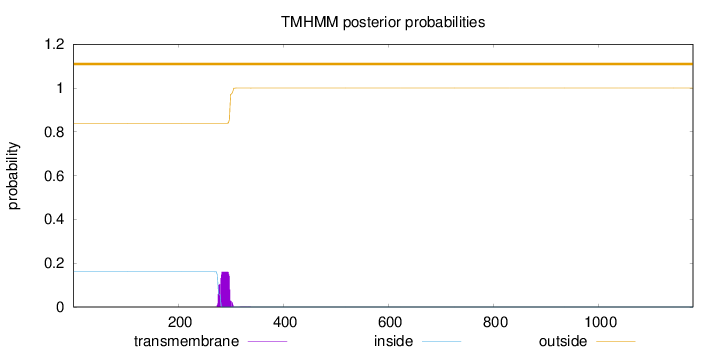
Topology
Subcellular location
Cytoplasm
Length:
1180
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
3.53665
Exp number, first 60 AAs:
0.0007
Total prob of N-in:
0.16076
outside
1 - 1180
Population Genetic Test Statistics
Pi
23.666168
Theta
195.682935
Tajima's D
-1.46205
CLR
14.50591
CSRT
0.0669966501674916
Interpretation
Uncertain
