Gene
KWMTBOMO09400
Annotation
PREDICTED:_uncharacterized_protein_LOC105391048_[Plutella_xylostella]
Location in the cell
Nuclear Reliability : 2.485
Sequence
CDS
ATGGCGTCTCCGGTCGCAGCGACAGACTTAACAACTTTTTCGTCGCCACCCTCACATTTACGTATCCCACCTTTTTGGCCTGAAAAACCTGCTATATGGTTCGCTCAAATTGAAGGACAGTTTGCAGTAATGCGTATAACCGATGATGCGACCAAATTTTACCACATCTTGAGTACCTTAGACAGGCAGTATGCAGCCGAAGTTGAAGACATTCTTACCGGCCCACCTGACTACAATCGACTCAAAGATGAGCTCATCAAGAGACTATCAGTGTCGCGGGAGAATAAGGTGAAGCAGTTGCTCATGCACGAACAGCTCGGAAGCCGCAAGCCTTCACAATTCCTACGGCACCTGCAACATCTCGCTGGCCCCGGAATACCCGAGGACTTCGTTAAAACAATTTGGACAAGCCGTCTACCCACTGGATTGCAGCCAATCATCGCTTCGCAGCCATCGTTGTCTCTCGACGCACTGGCGGAACTTGCCGACCGGGTCAATGACATCGCGACCCCGGTACCGCAGGTAGCAAGCGCTACCACCTCTACGCATATCGACGAGCTGACACGACAGGTAGCAGAGCTGACAAAACAAGTGAGTGCACTGACCGCGCAAATCAACCATCACCCAAGCAGAGGACAACGGAGACCGACAAAGCAACAGCGCAGCAGATCTTCATCTCGCCGCCGATCACAGTCAAACTACAGACAGCACCCCATATGTTGGTATCACTTCAGATATGGTACCAAAGCCGTCAGATGTATCCAGCCGTGCGATTACAAGGCGTTGGAAAACAGTCAACAGTCCGGGCAGTCGCTGATGGCGACACAAGACTGCCGCAACACCACGGGTCGCCTCTTCATCACGGACAGTAAAACTAAAAATCAATTCCTTATTGATACCGGTAGTGATATTTGTGTCTACCCAGTGTCCGCACTTCGAGAGCGTCGTTATAAAACCTCTTTTCAACTGAGTGCCGCGAATGGTTCAGTGATAGATACGTATGGATATATCGAACTTAATCTTAATTTAGGTTTACGTCGTGACTTTCCATGGCGCTTTGTTGTTGCTGATGTCACGATGGCTATTATTGGTGTTGATTTTCTTTCTCATTACAACCTTATTGTTGACATCAGCAACCAACAACTTATTGATACTTTAACCAATCTTAAGTTTGTAACATCTATATGTAAAAATAATTGTCTTGTCACAAGTGTAAAAATTCCAACTGGTGGTAGTGGTAGGTATCACAATATTTTAGCACAATATCCGGAAATAACTCGCCCCGCTGGTACTCCGGGTATCGTCAGACACCACACGACACACCACATCATCACCACACCAGGTCCACCTGTATCGCTGCCGCCCCGTCGTCTCGCTCCAGATAAATTGAGAATCGCCAAGCAGGAGTTCGATGCCATGCTACGTAACGGCACGGCACGCCCTTCCTGCAGTCCTTGGGCATCACCACTGCATCTGGTGTCGAAAAAAAAAGACGACGGCTGGCGTCCATGTGGCGACTACAGGTCAGCCCAGGAGCACGAAGACCACCTGCACCAACTCTTCACACGCATGAAAGAGTATGGCGTTTTGGTTAATACTACCAAATGTGTCTTCGGCGTCCCAGAAGTCACGTTTTTGGGTTATCAAATTTCCGAAAAAGGTACCAAGCCTTTGGTAAGCAAGGCCGAGGCAATCGCAAAATTTCCGGTCCCGAAAACCGTCAGAGAACTCCGGCGATTTTTGGGCATGATTAATTTTTATCGCCGATTCCTACCCAATGCTGCCCAGATACAAGCGCCTCTCAACGCATTGCTGGTTGGTTCCGTAAAAGGTGCACAACCCGTAGTTATCGAGGGAAAGTCATTGCAAGCCTTCCAAGACTGCAAAACCAGCCTATGCAATGCAGCTCTCCTAGCCCATCCCGATACTCAAGCAAAGTTGAGTCTCGTGACAGACGCTTCGGACTCTGCAATAGGTGGAGTACTCCAGCAGCTTAAAGGTGGAGATTGGCAGCCGTTAGCATTTTTCTCTCGTAAATTGAGCCCCTCGCAGTCAAAATACTCGCCCTACGACCGAGAGCTCCTCGCCATTTATGAGAGCATAAAATACTTCCGGCATATGCTTGAAGCAACAAATTTTACTGTGTATACTGACCACAAACCTTTATGTTATGCATTTCAGCAGCCGAAGCATAACTGTTCGCCGCGTCAGTACAGACATCTGGACTTCATTTCCCAGTTCACCACGGACATAAGGTTTGTTTCGGGCAAAGACAACCTTGTCGCTGACACCTTGTCTCGCATCTGTGAACTGCAGATGCCTGTGGACTTGGAAGAAATGGCCAAGCTACAAACCACAGATCCGGAGCTGGCAGAACATTTATCGGGTGGAACCTCTTTACGCCTGACTAAGATGAGCGTCCCTGGAAGTCAAGCTGTTTTGTACTGCGACGTCAGTACGCAGATGCCCAGGCCGTTCGTCCCACGAGAGATGCGTCAGAAGGTATTTCAGTGCCTTCATTCACTCAGCCACCCCGGTCCCAACGCTTCAGCCAAACTCGTTGAACAACGATTCGTTTGGCCACTAATGCGGAAAAATTGCCGTGAATGGTCTAAGGCATGTTTGAATTGCCAGCGCTCGAAGGTCACAAGACACGTCACCGCCCCTGTGGGCAGGCATGACCTACCTTCAGCACGATTCAAACATGTCCACCTAGACTTGATCGGACCCCTACCGCCAGCAGGTGATTATCGGTACTGCCTTACAGCCGTCGATCGCTTTACGCGATGGGCAGAAGCTGTACCTCTAACCGACATCACCGCCAAAACAGTGGCCACAGCATTCATTTCATGTTGGGTGTCCCGATACGGTTGTCCTGTCGAGGTTGTCACCGACCGCGGCAGACAATTCGAGTCGGATTTATTTCTACGGTTGTCCAAGTCCATCGGCTTTGATCACCGTAGAACAACAGCATATCATCCACAGTGCAACGGTTTGGTTGAACGTTTTCACCGGCAGCTGAAAGCTGCGATAACTTGCCACGCAGACGCAAACTGGACTGAGACCTTGCCACTCGTCCTTCTCGGTATTAGGACTGCTTTCAAGGAAGACCTCCAAACGTCATCGGCAGAGCTGGTGTACGGTGAGCCTCTACGCTTACCCGGTGAATTCTTCGGTCACAATGTCACTCATCACACTACCGACGTCACCGACTTCTTGGCTCGTATGAGGTCCTTTGCAGAGAAGATACGCCCAGTCCCTCCTCAACACCATTCGACACAAAAAACATTCGTTTTTAAAGACCTCGCCACTTGTAGTCATGTATTCCTCCGAGAAGACTTGTTACGTGGCTCACTTCAACCTACATATACAGGGCCGCATGAAGTGCTTAAAAGAGGCGATAAATATTTTTCTATTCTTGTCAAAAACAAAGCTGTGACGGGTTCAAGACTTCAGCATCAGACTATGATGAATAAACACACCGGTTAG
Protein
MASPVAATDLTTFSSPPSHLRIPPFWPEKPAIWFAQIEGQFAVMRITDDATKFYHILSTLDRQYAAEVEDILTGPPDYNRLKDELIKRLSVSRENKVKQLLMHEQLGSRKPSQFLRHLQHLAGPGIPEDFVKTIWTSRLPTGLQPIIASQPSLSLDALAELADRVNDIATPVPQVASATTSTHIDELTRQVAELTKQVSALTAQINHHPSRGQRRPTKQQRSRSSSRRRSQSNYRQHPICWYHFRYGTKAVRCIQPCDYKALENSQQSGQSLMATQDCRNTTGRLFITDSKTKNQFLIDTGSDICVYPVSALRERRYKTSFQLSAANGSVIDTYGYIELNLNLGLRRDFPWRFVVADVTMAIIGVDFLSHYNLIVDISNQQLIDTLTNLKFVTSICKNNCLVTSVKIPTGGSGRYHNILAQYPEITRPAGTPGIVRHHTTHHIITTPGPPVSLPPRRLAPDKLRIAKQEFDAMLRNGTARPSCSPWASPLHLVSKKKDDGWRPCGDYRSAQEHEDHLHQLFTRMKEYGVLVNTTKCVFGVPEVTFLGYQISEKGTKPLVSKAEAIAKFPVPKTVRELRRFLGMINFYRRFLPNAAQIQAPLNALLVGSVKGAQPVVIEGKSLQAFQDCKTSLCNAALLAHPDTQAKLSLVTDASDSAIGGVLQQLKGGDWQPLAFFSRKLSPSQSKYSPYDRELLAIYESIKYFRHMLEATNFTVYTDHKPLCYAFQQPKHNCSPRQYRHLDFISQFTTDIRFVSGKDNLVADTLSRICELQMPVDLEEMAKLQTTDPELAEHLSGGTSLRLTKMSVPGSQAVLYCDVSTQMPRPFVPREMRQKVFQCLHSLSHPGPNASAKLVEQRFVWPLMRKNCREWSKACLNCQRSKVTRHVTAPVGRHDLPSARFKHVHLDLIGPLPPAGDYRYCLTAVDRFTRWAEAVPLTDITAKTVATAFISCWVSRYGCPVEVVTDRGRQFESDLFLRLSKSIGFDHRRTTAYHPQCNGLVERFHRQLKAAITCHADANWTETLPLVLLGIRTAFKEDLQTSSAELVYGEPLRLPGEFFGHNVTHHTTDVTDFLARMRSFAEKIRPVPPQHHSTQKTFVFKDLATCSHVFLREDLLRGSLQPTYTGPHEVLKRGDKYFSILVKNKAVTGSRLQHQTMMNKHTG
Summary
Uniprot
Pubmed
Proteomes
Interpro
Gene 3D
ProteinModelPortal
PDB
4OL8
E-value=1.40191e-38,
Score=405
Ontologies
GO
Topology
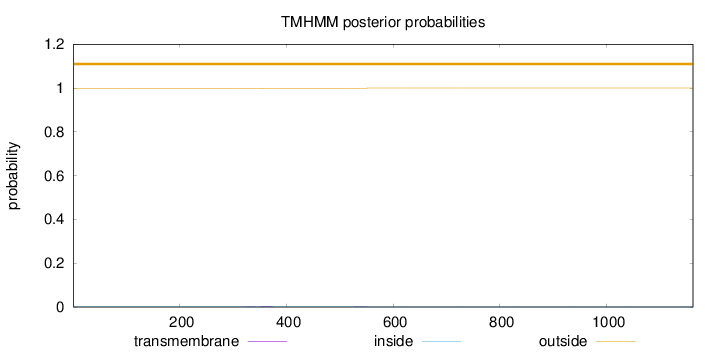
Length:
1162
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.06918
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00063
outside
1 - 1162
Population Genetic Test Statistics
Pi
11.464101
Theta
11.962585
Tajima's D
0
CLR
0.324677
CSRT
0.373631318434078
Interpretation
Uncertain
