Gene
KWMTBOMO09315
Pre Gene Modal
BGIBMGA003299
Annotation
PREDICTED:_diacylglycerol_kinase_eta-like_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.573
Sequence
CDS
ATGGGGCTCAGACTGTTCAGGCATTTCGCTCCGATCAGGGTGCTCGTGTGTTCTGGTGACGGCTCAGTGGGCTGGGTACTCCAGGAAGTCGACAAGCTGGAGATGCACAAACAAGTTCAAACTGCGGTTCTGCCCCTGGGCACCGGCAACGACCTAGCTCGGGTCCTCGGCTGGGGCGCCTCGTGCGATGACGCCGCCAACCTGCAGCAGCTCATCGAGAGATACGAACGCGCGTCCACTAAAATGCTGGACAGGTGGTCGATAATGACTTTTGAGCGTTCATTATCAGCGCCGCCTCCTCCACCAGTACCACCGGACCTGCTGGAGGAATCCGCGCTCCTAAAAAACTTGCACGACATCATGCAGCCAGGTGAAGTGAGTTGCCTGGCGAGCTCGTCCCTACGGGCGGGGTGCGTGCGGCTGGCGGCGGCCGGGGAGAGGGCGGGGGGAGGCGCGGCGCGGGCGGCGCACCGCCTCAAGCGTGCCGTCTCGCTGCTACTCCACGCGCGGGCGCATCTCGCTCACGACCACGGACGATGCAAATTATGGGAGCCCTTGGAGACGACAAGCGACAGCGAACCTGAGACCCAACCGCTCGCCGAAAAGGGCAGCATTGATAAGACTGAAAAAGAGCAGTTGAACTGGGCCGCGCGTGGGTGTGCACTGGCGGGTCGCGCGGACAGTGTGCGGAAGGCGTTGCGGTCACTGGTGAGGACCCTGTCCCTAATATATCCCCAGGGCGTTGGACCACCTGAGGCGGACTCCTGTGATACGTGCGAGAGTTCGTCGGGCGCGACGGGCGTGGCGGCGGTGGAGGCGGCTGCGGCGGTCCCGACGGACATCCCGGTGGCGTCACTGTCATTGCCAGTGCCACGCGCCTTCGCCGACTCTCGCCGTTCATCTGCCGCTTCGGCTATATCTGCCGTTTCTATGCAACCTGACAACATTCCAGACGTAGATGAAGACATAGTAAAATTAATAAGCTCAAATCCATCAGATTCATTCAATTTGGAAGTTGAGAAACCGGACCGTAATAAAACCAGCTCCGCTTCACCCCAGGACCTGCTGTCGCTGTCTAACCTCTCCTCATGCGACACCAGCTCGTGTCGGAACCTCTTCCGGCCAGACGATCGTACGTTTGATAACAGCAGCCTCACGATACCCAATCTAGTGATTTCCGATGACAGTGATAAACGAGATTCGATCATACAAGGAGACACATATGAATCGGAACAATTGACCATCATAGACATTGATAAGCCGTACACAGACGAGATACATTTTCAAGAGCTGAGCGCCCGAGTGAGTCCCGCCAGCGGCGAGTGCTCTCCCGACAGGCGCCTCTCTAGTGTCGACCTCGAAATAGAAGGGAGCAGCTCCGAAGGATCCAACATCAGTGATGACTTCAGCTTAATGTCCGAGATTATAGACATAAAGCCGGGCGATATAGACGAAGCCGGATGCATAGGACATATCGACTCGCCTGAAGCATCCGAAACCACATATGTCAACTCGGAGACGCTACACGGAGAATCTATCATGGACGACATCAGTTCGATGCTGGGACAAGAAGTGCTAATGGCTATGATGGGAAAGAACGGTGACAATGAAACGTATACAGACGATACAACCCTTTTCACTTCAGACACCGTCTCTGACATAGTTATGGACAGCAGAAACCCCAGCCTCGAGAAGAATGAAGGCAAAAACAAATACATATCTAAAATAAAGAAGAAAGAGGGAGAAGTAGAGAAATTCGGCTTCGAAAATAGAGTATTCTACATTGAAAACGTTGCGAAAGTAGAAGATCAAATCAAGTACTGCAGCTTGGCGCAGTTTGAAGAGGGCAGCGATATAGCCAGGAAGTCATTCAAGAAACAACTCAGGAAGAGCTTAAAAAAGCGCGCGCCTGATGATTCGAGCCTCAAAGGCTTGTTTCCGAAAACGGCCGAAGAGAATCTCAGGGTCGACGACACTCCTAAACTTGAACCGAAAAAGGAGAAGGCCAGTTTGGATATACCATCCTTTCCCCAAGTCAGCGTAGTCGTGGAACCTCCGTCGCCTTCGCACAGTGAAGACAAGAAAAGCATCAAGACATGCGTCAGTCGGATGGCATCGGTTTTGAGCGACATTTTCGACCAAGCTACCGACACTTTAAGCGTAAATTCGCCTGAGCCTAGCATAGGAGTCGCGCGGGAAAGGAGACAGTCCGACAACCCGAAATTACTCAGCTCGGATCCGGAGTATGGAAAATTCTTAAGCTGTTCACCGGCAGCTACCAGACGGATATCCTGCGGGAGTCTCTACAAGCCAGGGGAACCGGACAAGCTTTCGACATCCGTATCCTCAATATGGGGCGAGAGTGGTGCCACAGCGAACACGGGCAGCTCCTCAAAATCGGAAAGCTGCGAAAAGGCCAGGAAATTGCCCATCATCAATCCCCTGGTACAGCTACCGGCTTGGCCACACGTTACCCAGGGCTTCATCAGTCAGTGTCTGCTCGCAAACGCGGATGCCCTTTGCGCGGCGGTGAGTCCCCTCATGGACCCCGACGAGACGTTGCTGGAGGGTTTCTATGAAAGAGCCGTCATGAATAATTACTTTGGAATCGGTATTGATGCAAAAATAACCCTGGACTTCCATAATAAGCGGGAAGAGCATCCGGAGAAGTGCAGGTCAAGAGCCAGGAACTACATGTGGTACGGCGTTTTGGGATCGAAGGAATGGGTCAACAGAACGTACAGTCAGAAGTACGAAATTAACAAAATTGAGACGGAAACTGACATAGATAAAGAACTTTGTGAAAATTTAAAGAAAATTCGTACCAGCCACATGAACGAGGAAGAAAAACGGGAAATTACTAAAATCTGCTATCAGTACCGTGACATATTCTACTCGGAAAACATTCCTTTATCGTTTACCCATACAGTAAAACACGAATTAAGACTAACCGACGACACCCCCATCTTTGTACGAAGTTATAGACAGGCTCCCCAACAACGAACAGAGATACAGAAACAGGTAGATAGTCTGTTAAAACAAGGAATCATTAGGGAAAGTATCTCCCCTTGGTCGTGCCCGGTACACATTGTTCCGAAAAAACCGGATGCATCAGGAAAAGTTAAATGGAGACTTGTTATTGACTATAGAAGACTTAATGACAGAATTATAGAAGACAAGTACCCCTTACCAAACATTAACGACATCCTTGACAGATTAGGGCGCGCACAATATTTCACGACCATAGATTTAGCAAGCGGCTACCATCAATTAGAAATGCACCCTAAAGACGTAGAGAAAACAGCGTTTACTACTGAAAGAGGCCACTATGAGTTCCTAAGAATGCCTTTCGGACTAAAAAATGCCCCGAGCACTTTCCAGCGTCTTATGGACCATATACTCCGAGGTATAGACAACGTATTTACGTACTTAGATGACGTCATAATAGCCGCGACGTCCCTACAAAACCACAATGAAAAACTGAAATTAGTATTTCAGCGATTCAAAATGCATAATCTGAAAGTTCAGTTAGACAAATCAGAATTTCTACAGAAGCACGTTAACTTTCTAGGACATGAATTGACTGACCAAGGACTAAATCCTAACAAGGACAAAATTAAAGCAGTATTAAATTTCCCTATACCACAAACGCAAAAAGACATAAAAGCTTTCTTAGGACTAGTCGGGTACTATAGGAAGTTTATAAAGGACTTTGCAAAGTTGACGAAACCTTTAACAGCATGTCTAAAAAAGAACGCAAAGGTTGAACATACAAACGAATTTTTAGACGCAGTTGATAAATGCAAACAAATTCTAACAAACGCCCCAATCCTGCAATACCCTGACTTCGACAAACCGTTTATTTTAACGACAGACGCATCTGACTTTGCTTTAGGAGCAGTACTTTCCCAAGGCAATGTGGGCTCAGATAAACCAGTAGCCTATGCCTCAAGGACATTATCAGATACTGAGATCCGTTACTCTACCATAGAGAAAGAACTGTTAGGGATAGTATGGGCAATTAAGTATTTTAGACCTTACTTATATGGCCGTAAATTTACAATTTATACGGACCATAGACCCCTTACATGGTTAATGAGTCTAAAGGACCCTAACTCTAAATTAACACGATGGAAACTAAAGTTAGCAGAGTATGATTACAAAGTTGTTTATAAAAAGGGCAAACAAAACACTAACGCAAACACTAATGCACTATCCCGAGCAAAAATTTTTCATAATAGTATAGATTCTCTAGCTGTTAATGTTGATGACAATAGTGACGACAACATAATAAATAGAATATTCGAAAACGCCCGTAGACAGGCAGAGGTAGAAACTAATGACCCGAATAACCAAGACAATGAACGTAACAATACTGACAATAACGACCAACCTTATAACAACAATGACGTAGAAATGACCAGTATCTATCCCTCTCAAACTGACGAAGAGACAGACACAAGGAGTATAACAACAGTCGACCCCGATCAATTAGTTTCTACAAATCATACCCAACCTGATAATGAAAATAACGGTATCCCTATAATATCCGACGCTATTGATAGACAGTTGAAACAATTTTACGTTAGGTCCACACCAGGTTCTACATACAGAGTAGAGGACAGATCAACAAACTCTAGGACAGTTATTAAGGATGTTTTCATCCCAGTAAATAACACTGAATCAGAAATTATCAAATTTTTAAAGGAACACACAATAGCTGACCGTGTTTTTCATTGCTATTTTTACGACGAAAATCTATACTTAGCCTTTTCAAGAGTGTATACTACGATCTTTAATGACAGAGGACCTAAATTAATAAGATGTACTTCGCGGGTCACACTTGTTGAAAATAAAACTGAACAACAAGAACTCATTAAGCGATATCACGAAGGTAAATCATCGCATCGCGGTATCCAAGAGACCTTTAAGCATCTGCATAGGAATTATCACTGGCCTAATATGTTATTGACAGTTCAAAGGTTCATTAATCAATGCGACCTTTGCCTAAAAGCCAAATATGAAAGAAATCCCTTAAAACCTCCATTGATTATAACAGAGACACCTACGAAGCCATTTCAACACTTGTTCATGGATCTCTATAGTACTGGAGGTGCAACGTTTTTAACAATTATCGACAATTTCTCTAAATTTGCCCAGGCGGTACCTCTGAATGCTTCTAGTAGTGTTCACATCGCAGAAGCCCTATTACAAGTATTTTCTGTACTAGGACTACCTCTTAAAATCACCACAGACTCAGATACAAAGTTCGATAATGACGTCATAAAAGAGATATGTGCTTCGCATGATATCCACATTCACTTCACGACGCCTTACAACCCAAACTCTAACTCACCCATTGAACGATTTCATTCAACCATCGCAGAAATAATAAGAATTCAAAGAATGACAAATAAAGACGACCCCATACAATTGATCATGAAATACGCTATCATCGCCTATAACAACGCTATTCATTCCACTACAGGCTATACACCACGTGAGCTTTTATTCGGTCATACGGCATCCCGAAATCCATTAGAGCTATATTATCCTAAAGAATTTTATCAAGATTATGTCCTCAATCACCGCAAGAATGCAGAAGCAGTACAGGAATGTATAGCAGCCCACGTGTCTAAGAACAAAGAGCAGGTAATAGAAAAGAGAAACCAGGCAGCGGAAACAATCACGTTTAAGACCACATCTTGTTCCAGGGCCCTCATCGCAGGAGCCTTCGTGCTCTACACAGCCGCCGACTTGACCCTTAATCCTATAGACAATACTAATGGCATCCTTTTGTTAAAACAAGGACAAATTTTGAAGCAGATAGACACTTTTAGTCTGGCCTGCGTATATAACGTATCGTATTTACATGAAACAACCTTAAAGCTTATGTCTTTATATGCCAGTACTAAAGCTGCTGAAGGTAACGAAGAGTTGCATAGAGCATATAAGGATCAAATAGAAAATAGTTTACATTTAATAGGGAAGAAGTTAGCATTTATTGCACCGCACCATAGATTTAGACGTGGCTTAATTAACGGTTTAGGTTCAGTAGTTAAAACTATTACAGGTAATCTGGATTATGAAGACGCTATTAAGTTTGAAAATGAATTATCTAATCTACGTAATTCAGTCCATAATATTAACACATCTCAAAAACAAACTTTATTCATAGCAAAGCACGCAGTTGAAGAATTTAGTAAACAGATCAAGTTATTAGACGAAAATCAGAAAAAGATAGGTTCAATGTTAAAAAACGCCACTTTAAGTAATAACGTAGTAATAAGCAGATTGCACTTTTTAGATTTATATGTCCAAATATATTTTAGTTTGCAATTACTCTTAGATAAATTAGTTATATTAGAAGACGCCATGACCTTTGCACAACTAGAAGTAATGCATCCTAGCATTATAGCTCCACACAGTCTTATAAGTGAAATAACAGCTATTCAAAAACTTTACCAATTTAGACCCGTTGATAGAATAAGTATTAAAAATATTCATAGTATAGAGAGCTCTATTAGCGTAAAAGCGTATAGCACAAACGACGCACTAACATTCATACTAGATATCCCTTCTATAGATGAAAACCTTTATGACCTTATCCATCTATACTCCATACCAGATAAACAAAACCTCACTATTATTCCTAAATCCAAATACCTAGCACTGGGAACCAACGAGTACTCATACCTGGAGGAAGATTGCAAGAAGATCACACAAGACGTCCAACTCTGCACATCGCTGAACACCCAACCTGTGGAGAACTCTGAAGACTGCATAGTAACTCTTATAAAACACGAGAGCACAAACTGCACCCGTGCCAGGATGAACCTGAAACAAGGCAAGATCCAGAGACTAGAAGACAACAAATGGCTTATCATCTTGAAAGACGAACAAATCCTGAAATCTCGCTGCGGAAGGAAATCTGACTATAAAAAGATGTCAGGAATATACATCGCCAGCATTACAAGCGATTGTCAAGTGGAAATATTCAACCGAACACTGAAGACAAACACGGATACTATTACAGCTGATGAAATCGTACCCATTCCCAGCGAAACCACTATTCTAGAAGGGAATATTCGCTATAACCTACAACTGAAAGATATATCTCTGGATAGCATCCACGAACTGATGGACCGGGTTGAAAACATTCAACAACCTGTCATCGACTGGCAGACTATGATGACTACCCCAAGTTGGTCAACACTGGGACTCTACCTCATTCTGATAGCAATAATCATCTGGAAGCTGTGGCAGTGGAGACAGCGACGACTACAATCAAAGAACGAGAGCCCCGAGAACACTAGCACCGAGGACGCTGCTGGAAGCTGCGGGACGCGCTTCTATCTTAAGGAGGGAGGAGTTAGGCAATCGCCCGATGCCCGTCAAAGGGTCCAGTTGGAGTGCGACGGTCAGAGGATACCCCTCCCGGAGCTGCAGGGAATCGTCGTTCTGAACATACCCTCCTTCATGGGCGGGACGAACTTCTGGGGCGGCACCAGAGCGGATGACATATTCCTCGCGCCATCATTCGACGATAGAATACTTGAAGTGGTGGCAGTTTTCGGTTCAGCCCAAATGGCAGCTTCGCGTCTGATCAACCTTCAGAAACACCGCATCGCCCAGTGCCGGGCCGTTCAGATTAACATTCTCGGTGAAGAGTGCGTACCGGTCCAAGTGGACGGTGAGGCCTGGCTCCAGCCCCCGGGGTGCGTCAGAATCATACACAAGAACCGGGCGCAGATGCTGTGTCGATCCAGAGCCTTGGAGACCAGCCTACGGACATGGGATGAGAAGCAACAGTTGAAGGCCAACGCCTTGGCCGGCTCTGGTACTAATGTCAACGCGAATGCTTCCACCAGCGGCCGCGACGTCCTACTGGCTGCCGAGAGCGCTCAACTCTTGGCTCTACTTGATGACATCAACACCCTCGTCAAACACGTAAAGTTGTCCTGTATCAGCGAGAGCGCGGTGTCGGGCGGCGTGTGCAGCGCGGTGTCCATTGCGCGCCGCGTGTCCGCGCAGGCCGACGCGCTGCAGGACGCCGACGGAAAGCTCCTCCCGGCCCCTCAACTGAGGAGACATCTCGCTACTTTGGTGGAAAGCTGTCACGAGCTGCTGGAGAGCGGCGGCGTGTCGGGCGCCGGCGCCGCCGCCGCCGCCTCGCTGCGGGCACACCTCGCCAGGTGCGAGCTTAGAGACGGACACGCCTACCTGCACGCGGACGAGATCCCAAAGAAAGGCCGCTGGCTCCGAGGTCGGAGAAGCGTCTCAGAAGGTCCGACCACAGTCGCCGCAGTGCGCTCGTGGGGCGTCAAGGAAGTTCAGAACTGGCTAGAGTCACTCCAGCTCGGGGAATATGCTGACGCGTTTACGAAGCACGACGTGACGGGGCGAGAGCTCTTGTCCTTGGCCAGGAGGGACCTCCGGGACCTTGGAGTGACTAAGGTAGGTCACGTGAAGAGAATCCTTCAGGCAGTCAAGGAGCTGCAGTGA
Protein
MGLRLFRHFAPIRVLVCSGDGSVGWVLQEVDKLEMHKQVQTAVLPLGTGNDLARVLGWGASCDDAANLQQLIERYERASTKMLDRWSIMTFERSLSAPPPPPVPPDLLEESALLKNLHDIMQPGEVSCLASSSLRAGCVRLAAAGERAGGGAARAAHRLKRAVSLLLHARAHLAHDHGRCKLWEPLETTSDSEPETQPLAEKGSIDKTEKEQLNWAARGCALAGRADSVRKALRSLVRTLSLIYPQGVGPPEADSCDTCESSSGATGVAAVEAAAAVPTDIPVASLSLPVPRAFADSRRSSAASAISAVSMQPDNIPDVDEDIVKLISSNPSDSFNLEVEKPDRNKTSSASPQDLLSLSNLSSCDTSSCRNLFRPDDRTFDNSSLTIPNLVISDDSDKRDSIIQGDTYESEQLTIIDIDKPYTDEIHFQELSARVSPASGECSPDRRLSSVDLEIEGSSSEGSNISDDFSLMSEIIDIKPGDIDEAGCIGHIDSPEASETTYVNSETLHGESIMDDISSMLGQEVLMAMMGKNGDNETYTDDTTLFTSDTVSDIVMDSRNPSLEKNEGKNKYISKIKKKEGEVEKFGFENRVFYIENVAKVEDQIKYCSLAQFEEGSDIARKSFKKQLRKSLKKRAPDDSSLKGLFPKTAEENLRVDDTPKLEPKKEKASLDIPSFPQVSVVVEPPSPSHSEDKKSIKTCVSRMASVLSDIFDQATDTLSVNSPEPSIGVARERRQSDNPKLLSSDPEYGKFLSCSPAATRRISCGSLYKPGEPDKLSTSVSSIWGESGATANTGSSSKSESCEKARKLPIINPLVQLPAWPHVTQGFISQCLLANADALCAAVSPLMDPDETLLEGFYERAVMNNYFGIGIDAKITLDFHNKREEHPEKCRSRARNYMWYGVLGSKEWVNRTYSQKYEINKIETETDIDKELCENLKKIRTSHMNEEEKREITKICYQYRDIFYSENIPLSFTHTVKHELRLTDDTPIFVRSYRQAPQQRTEIQKQVDSLLKQGIIRESISPWSCPVHIVPKKPDASGKVKWRLVIDYRRLNDRIIEDKYPLPNINDILDRLGRAQYFTTIDLASGYHQLEMHPKDVEKTAFTTERGHYEFLRMPFGLKNAPSTFQRLMDHILRGIDNVFTYLDDVIIAATSLQNHNEKLKLVFQRFKMHNLKVQLDKSEFLQKHVNFLGHELTDQGLNPNKDKIKAVLNFPIPQTQKDIKAFLGLVGYYRKFIKDFAKLTKPLTACLKKNAKVEHTNEFLDAVDKCKQILTNAPILQYPDFDKPFILTTDASDFALGAVLSQGNVGSDKPVAYASRTLSDTEIRYSTIEKELLGIVWAIKYFRPYLYGRKFTIYTDHRPLTWLMSLKDPNSKLTRWKLKLAEYDYKVVYKKGKQNTNANTNALSRAKIFHNSIDSLAVNVDDNSDDNIINRIFENARRQAEVETNDPNNQDNERNNTDNNDQPYNNNDVEMTSIYPSQTDEETDTRSITTVDPDQLVSTNHTQPDNENNGIPIISDAIDRQLKQFYVRSTPGSTYRVEDRSTNSRTVIKDVFIPVNNTESEIIKFLKEHTIADRVFHCYFYDENLYLAFSRVYTTIFNDRGPKLIRCTSRVTLVENKTEQQELIKRYHEGKSSHRGIQETFKHLHRNYHWPNMLLTVQRFINQCDLCLKAKYERNPLKPPLIITETPTKPFQHLFMDLYSTGGATFLTIIDNFSKFAQAVPLNASSSVHIAEALLQVFSVLGLPLKITTDSDTKFDNDVIKEICASHDIHIHFTTPYNPNSNSPIERFHSTIAEIIRIQRMTNKDDPIQLIMKYAIIAYNNAIHSTTGYTPRELLFGHTASRNPLELYYPKEFYQDYVLNHRKNAEAVQECIAAHVSKNKEQVIEKRNQAAETITFKTTSCSRALIAGAFVLYTAADLTLNPIDNTNGILLLKQGQILKQIDTFSLACVYNVSYLHETTLKLMSLYASTKAAEGNEELHRAYKDQIENSLHLIGKKLAFIAPHHRFRRGLINGLGSVVKTITGNLDYEDAIKFENELSNLRNSVHNINTSQKQTLFIAKHAVEEFSKQIKLLDENQKKIGSMLKNATLSNNVVISRLHFLDLYVQIYFSLQLLLDKLVILEDAMTFAQLEVMHPSIIAPHSLISEITAIQKLYQFRPVDRISIKNIHSIESSISVKAYSTNDALTFILDIPSIDENLYDLIHLYSIPDKQNLTIIPKSKYLALGTNEYSYLEEDCKKITQDVQLCTSLNTQPVENSEDCIVTLIKHESTNCTRARMNLKQGKIQRLEDNKWLIILKDEQILKSRCGRKSDYKKMSGIYIASITSDCQVEIFNRTLKTNTDTITADEIVPIPSETTILEGNIRYNLQLKDISLDSIHELMDRVENIQQPVIDWQTMMTTPSWSTLGLYLILIAIIIWKLWQWRQRRLQSKNESPENTSTEDAAGSCGTRFYLKEGGVRQSPDARQRVQLECDGQRIPLPELQGIVVLNIPSFMGGTNFWGGTRADDIFLAPSFDDRILEVVAVFGSAQMAASRLINLQKHRIAQCRAVQINILGEECVPVQVDGEAWLQPPGCVRIIHKNRAQMLCRSRALETSLRTWDEKQQLKANALAGSGTNVNANASTSGRDVLLAAESAQLLALLDDINTLVKHVKLSCISESAVSGGVCSAVSIARRVSAQADALQDADGKLLPAPQLRRHLATLVESCHELLESGGVSGAGAAAAASLRAHLARCELRDGHAYLHADEIPKKGRWLRGRRSVSEGPTTVAAVRSWGVKEVQNWLESLQLGEYADAFTKHDVTGRELLSLARRDLRDLGVTKVGHVKRILQAVKELQ
Summary
Uniprot
ProteinModelPortal
PDB
4OL8
E-value=3.52508e-76,
Score=733
Ontologies
GO
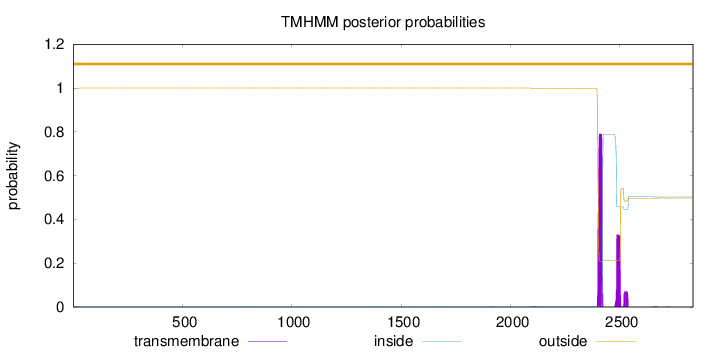
Topology
Length:
2834
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
24.86943
Exp number, first 60 AAs:
0.01358
Total prob of N-in:
0.00066
outside
1 - 2834
Population Genetic Test Statistics
Pi
225.008569
Theta
174.488971
Tajima's D
1.168557
CLR
0.371677
CSRT
0.710114494275286
Interpretation
Uncertain
