Gene
KWMTBOMO08808 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA007875
Annotation
PREDICTED:_uncharacterized_protein_LOC105841250_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.996
Sequence
CDS
ATGTCTGCACTCTCAACGCCGGGCGGCGGAGGCACTACGGCGCAGAGCAAGCCGACGTCCGGCAAGCAAAAATATCAGAAATTGGACATCAATAGCTTGTATTGCGCTAATAGAAATGAAAACTCAGAACCGTCCTCAGTAAAATCTCAACTAAGCCGCAAACATGGAATGCAAAGTCTTGGAAAAGTACCATCCGCTCGAAGACCACCAGCTAATTTGCCATCTTTGAAAACTGAAATTGGTCAAGATACAACTGCCAACTCAACTTCTGCTGTTACTACAACCGTATCTGCACCACCACCATGTACTACCCAAACAACAACAGCACCATCGAACAGCAATGTGGTTGTCGGCCCAGGCGGTTGGGTGTCGTTACCACCACCGTCATCTCCACACTTCCGCACAGAGTTTCCCTCTTTGGAAGCAGCCGCACAACCATCACATCGTACCGGAGAACACACTGGACCTCAGCCACAACTGAGACCACAAACGGAAGGCAGCTGGACGTGCGGTGGATCAGTGAGCGGCAGGCAAGAAAGTGGTTCCGCTCCCGTTGCTGCCGCACCTGCTGCGGCTCCCACCTCGCAACAAACTCCAGCATTCCGCGCCATCTTGCCATCCTTTTTGATGAAAGGTAGCAGTGGTAGTGGAGGGCTCGGGTTAGGCGGTCTCGGAGCGCTGCGTGAGCGCGGCGGTGGGGGAGCCGGTAGTGGCCCCCAGCGAGAGCGCGGTGCCACCCGAGCACCTCCCACGCCCCGCGCCGTCGAAGTACTCACGGCGCGACCCATTCTGCGTGACGAGCAGATTTCTTCCCTCGACGATATTTCACGTGATGCTGGCTGGGCTCAGCACGATGACATCGATTACGACCAAAAATTGGACTTTTCCGATGGAGAATCTTCAGCTCCCACAAAAGGGAGCACTAAGAGCAGTAGCACTCGGGCCAGCATCGAAAGTGAACGAGCTGAAATAAAAATGCATGAGCTTGGTGATGAAGACCAAATGTGGGCTGAAAGACGACAAAAGCAAAATAATGAAGTAGCACAAGCCGTTGCACGTGCTCGGCAACGGAAAGAAGAAGAGCAGCGCCGGCAATTACGGGACGCCCCCTCATCTAACTCTCAATCTAAAGATTTTCGTGGAGATCGGGAACGCAACGAAAATCGTGAAAGGGATTTGGAACCAAGGGATAAAGACAGGGTCGAAAGTAAAAATAGAGATCGTGTCGAGCGCGATAGGGATCGGATTGATAAGGAGAAAGAAAGAAACGATTGGGATACACGAGATAAAGATCGTGTACATGAAAACAGAGATCGTAATCGAATGGATGCTAGGGAACGATTTGACAATAGAGATCGCGACTTGAAATCTGATCGGGAACGTGATGTACGAGCGGATCGTGATAACGACCTTCGAGATCGTGATCGTGCCGAAAATAGAGATAGAGGTCGCGGCGAGAATCGAGAGCGTCATGAAAATGATAAAGAGAGGATGGATAATCGTAATGAGAGAGACAGAGCAGACCGTGATAGGTTCGATAGAGAAAGAGAACGTGATCGCGAACGTGAACGTGAGCGTGACCGAGATAGAGATACAGCAAGAGAAAGAAATGATAGAGACCGCGAGTTTAGAGATCGTGATCGAGAGTATGGTCGCGATCGTGATCAAAATAATCCAGCGTTTTCCAAGACTTTTCAAGCAAATATTCCACCCCGATTTTTGAAACAACAACAAAACAGACAACAAGACGATCCAAAAGCAGGATGGGCCTTTTCGGGTAAACCTGCCCCAAGGAGACAAGATGTACAGCCTTTTTCTGCTCCGAGACATGTACAGCACAACAATGGTCGCAGATCTTATTCCAGGGATTATTCAGATCGAGAAGAAGTTTTTAGAAGGGAGAAAGAAGGACCTGGACCGCAATGGCGGTCTGAAATGCAAGATTTTGAAAGATTCGGAAAGGATCTTGAGAGGTCTAATTCTAAAGAATCTTATAAAGAATATGTCGACTACAAAGATAGAAGAAACGAATGTGACAAAAGAAGTACTGAAAATATAATTGAAACTAATTCTAGATCTGCTGCAGAAAAATTGAGTGAAGTATTTGAAAGAAAAAGCATTGGAATATCAGAGACTGTATCCTCTGATTCATCAGTGCAAACTCCTGGCTCTATAAAACTAAGTTCACCTGTACCTCCTTCTGCAAGAGAATCATCTGAAAAAGAGTTTAGTAAAACATCTTGGGCAGATGCTGTTCAAGATGAACAAACGCATATTGCAACATTAAAGACTTCTCTTGAAAAAGTGTCTGTGCTAATGGATAATGACAAGGTTCCTAAAGACCCACCAAAAGTAGAAAATGATGAACCAAGTCATGCTTCTCAATCAGCAAAAAATGTATCTCAACTTTCTTTGTCTTTATCTAAAGGAAATTTAATTCCATCACTTTCTCAGATCCAATCTCAAAAACCTGAAACTAGTACATCAAATACTCAAGGTATTAGTTACAATCAAGTACTATCTCAATCAGGATCTTTAGCTAATTCCACTCAATCTGTTCTTAATAATAATCACACACAAATGTCTTTCCCTGAACAACAAGTTGCAAAACCATCTTTTTCTGCTGTTTCCAAACAAAATTCTCAAAATGAAAATCTTCATAATTCTTCATTACTTTTACCAACATCAAAGCAAATGCCTGAGCCACAAACTCAAATAGCAAAACCTAAATTGTCAGCTGCTAAAACAGAAAAAGAACTTTCTGAATCTGATTCGGTAGTACCAAAATCCAGTACTGAGCCAACTGTGAAGTACAATGAAACGCAGTCTACAGATTCACTTCAAGATTGCAATGAAGGTCAAAAACGTCACACTGATGACAAGAAAAATGAGAGATTTACTAATGAACAACATATCAAAATTCCCCTTAAAGAACCCATAGAAAGGAAGTCTAGTGGGTCTGGTTCTGAGAAAAAGGTTAGAGGCTATGCAGGAAGCGGAGGATATGCTGTGTACAATAGAGGTTGGGGATCAAGGGAATCTCGTGGAAGACGGTCACATCGCAGTTCCCGTTCAAATAATAGGGCTAGTGAATCTGATGGATCTACTGATGGAGCTCTCAATTCAGAACGCAGGGAACGGCGTAGAGCACCTCGTAGTCCACGAGGACCGAAAAAGTCTGATAAGCCTGATGAGTTAAATCCCGCAGTACAAGATCAAACTCCGACAACTATTGATATATTGGAAAATCGAGAACCGTTTGCACCTCGCGGGCAACCTTCTAGAAGGGGTAGGGGTGGTTTCCAGGGATCCGCACGTCCACCAGCTCCTGCTAAAAGAGTAGTAGGATATGGCCCTCCTAATACGAAGAGTCCATTCAGTCAAGCCAATAGAGCAGTGAAAGATACTGAAGAAGTTAAGGATAACATTGATGATAGAGGAAAACCAAACAAGCCACGTGCTGGTTCGACGTCAGGTAGAGGACGTGATCGTCGTCCTAAAGGTGGAGCTCCGAGTGGGGAAGATGAAAATTGGGAAACGACATCTGAACATTCCGAAGGAGGTGGTACTTCCGGTCGCCGTCGTTCTGCTCAATCTCAAAAGAATAGTAGAAATGCTAATTCCAGTAATCGTCAAAATGGACGTATTTCACAAGGAGGAAAGAAAGACGTAGTTACAGGTGAAAATAAAACTGCTGCTGAAATAACTGAGGCCATTTCTGATCTGAAGTTAAACACTAAAAATGACGAAGTTATCGATGACGGTTTTCAAGAGGTCCGCAATAAAAAGAGTTCCAAAGATACCCGACCACCTGCAAAAGAAGATGGTCAAGGTTCTGGAAAACAGTCAAGATCTCATTCTAATCAAGGAAATGGTCGCAATCGATCGTCGACTAGAAACTCCAATGATAAATCCACAAACAGAAGCTCCGCCCCAGTACCAGGCAAATCCGGATCTCAATATGATAGACCTCGACAGGCGAACTTAGCCCCTCGTTTTGTGAAACAACGACAGCAAAGGCAGCAAGTAGGCGGCTTAGTGAGCGCATGCGGCCCCGATACCGGCGCCGCACCGCCGCCACCCGCAGTTAATGCATGGGATAAACCCATATCCCAAACCTTACGTGGTAATGTAGAAGAAAATGTAGATTTAGTTGAAAATAAATCTGCGCAATCCAGTCAGCGTAGCACACCAGCTGAGACGTCGACTGATATCAAGACTGCTCCCACTCCTTGTACTCTATCTGCTGATAAAACAAGTATGTTAGATGGAGCAACGCCGCCTGTAGAAACCATAATTTTTGAAAATACCAACTATAAGACTGCTACACCAGATGAGGCCTTGCAACAAAAATATCAACTAAATTCTAATATGTCTAAAAATCAAACTGAAGAAGTATCCACTGAAATAGATAGTCGTTCCCTGACATTTAACGGAGAAGTTAGGGGACGTCCTAGATCCATACAAGAACTTATGGCAGAGAGTGGGAGACAATCTGCAGAAGGGGACGCGTCGTTAGGCTTACAAATGTCATTTGACACAACACAAAAAACAGAAGATTCTGACATGAAACTTGATTTTGGCTTTGATTCAGATTTGGGACAACTTTCAGAAGATAAATCAGCTAAGTCGCTGGGTTTACCACGTGGTGTCCACATGAGCACTTCTAATACGATTTCGCCTCTGGCAGCTGATCTTAATTTAAAAATCGCTAGTGTTAAGAAGGTCTGGGAGATGCCTGCTGTTGCGGAAAATACGGAGGAATTACAATTTACTGGATTTGAAGAAACCAATACAGAAAGCGCTCCACCTAATGTGTGCAAAGTGAAGCCAACGCAACAATTGCAGTCCCCACCGCCTCAACATTACAACCACGTGGGCTATCAGGGAGGGTACGGTGGGCTATCAGTTCCGTCGCCGCCTGCCATGTTGTTTAACTCATCACAGCAATTGTTAGGATCTTCTCAACAGCTTCCCCAGCAGGGTGGACTTTACGGAGCTTTCTTGGATCAGAGTAGAGGTCAATTTGGTGGTTTTCCTGGTACTCCATATGGCGCCGGTTCAGCGGCCCCCTATAACTACCAACCGCCACCGGATATGTTTTCTAGTATTCCAAGCCAATATAGGATGGCAGCAGGCGGGGGTGCAGCTTTTGGCCAATCAGGGCAGCTTGGAAACAGTCCTAGTACAGTGCTCATATCTAGTACATCTAATTCTCTAATGTCTGCAACTGTGAAGCCCACTACTCAACAAATTGGTGCCATAGGTGCAGGCAGCAAAGGCGGCGGTGTGGGTGGAGTAGGAGGCGTCAACACCTACGGCCAACAGTACCTAGGATACTCAGGACCTGTGGGCGAAGCCCCGTACTCACTCTTGCCACGACCGGCTCCGCCAGCTTCCTCGTACTATTCACCTTACCAACCACCAACTGCGCCAGCACCTACCTATCCTCTCCAGTTTACGCAACCTGCGCAGTCTGGCGCCTTTGGCTCCCAATTTCTCTCTTCGCAACTACAGGTTGCCGCCGCTGTACAACAGATGCAACAACAATATAGAGCGCCTTTACAACAACAGTATCCTCCGCCGCAACCACAGCCTCGTTTACCCCCTCAACAACAATTGAAGAGTCCTCTTCACGAGCATGCCAATGGATTCGCGCCACTTTGCGATGCAGCGTCACCGACTCCGAAAGGTGGTGGAAAACCGCAAAAGCCGCCACATTCTCCACCGCAACACAAGTATCACGCCCCGCCTCAGCATCCACCGCCGGCACACACACCCCATCAACACCATCAACAACAGATGGTGAGCGGCGGCAACAACGGGCGTTGCGGCGGGGGCGGGGGCGGAGCGGCAGGAGTCATGACTCGCGGCGGAGGTCCTGCCCCGCGCTACCCAGCGCCTATACAGCGCCCCCATGCGCCAGCACTGCCGCTGTATCGCGCACCACAACAGCGACCTCACCATGCTCAGCCGCGCCCCAATCTCTACTATCATCATCCTCAGCGAAACGGAGGCGGCGGAAACGAGCGCGCGCCCGAGAATACGGAACCGACCGCCGGCGGTGAGGAGAGCGGCGACCCGGCACCGCCGGCGGAGGTGCAGACCGTGCCCCCGCCGGAGGTCAAAGCGGAGTGA
Protein
MSALSTPGGGGTTAQSKPTSGKQKYQKLDINSLYCANRNENSEPSSVKSQLSRKHGMQSLGKVPSARRPPANLPSLKTEIGQDTTANSTSAVTTTVSAPPPCTTQTTTAPSNSNVVVGPGGWVSLPPPSSPHFRTEFPSLEAAAQPSHRTGEHTGPQPQLRPQTEGSWTCGGSVSGRQESGSAPVAAAPAAAPTSQQTPAFRAILPSFLMKGSSGSGGLGLGGLGALRERGGGGAGSGPQRERGATRAPPTPRAVEVLTARPILRDEQISSLDDISRDAGWAQHDDIDYDQKLDFSDGESSAPTKGSTKSSSTRASIESERAEIKMHELGDEDQMWAERRQKQNNEVAQAVARARQRKEEEQRRQLRDAPSSNSQSKDFRGDRERNENRERDLEPRDKDRVESKNRDRVERDRDRIDKEKERNDWDTRDKDRVHENRDRNRMDARERFDNRDRDLKSDRERDVRADRDNDLRDRDRAENRDRGRGENRERHENDKERMDNRNERDRADRDRFDRERERDRERERERDRDRDTARERNDRDREFRDRDREYGRDRDQNNPAFSKTFQANIPPRFLKQQQNRQQDDPKAGWAFSGKPAPRRQDVQPFSAPRHVQHNNGRRSYSRDYSDREEVFRREKEGPGPQWRSEMQDFERFGKDLERSNSKESYKEYVDYKDRRNECDKRSTENIIETNSRSAAEKLSEVFERKSIGISETVSSDSSVQTPGSIKLSSPVPPSARESSEKEFSKTSWADAVQDEQTHIATLKTSLEKVSVLMDNDKVPKDPPKVENDEPSHASQSAKNVSQLSLSLSKGNLIPSLSQIQSQKPETSTSNTQGISYNQVLSQSGSLANSTQSVLNNNHTQMSFPEQQVAKPSFSAVSKQNSQNENLHNSSLLLPTSKQMPEPQTQIAKPKLSAAKTEKELSESDSVVPKSSTEPTVKYNETQSTDSLQDCNEGQKRHTDDKKNERFTNEQHIKIPLKEPIERKSSGSGSEKKVRGYAGSGGYAVYNRGWGSRESRGRRSHRSSRSNNRASESDGSTDGALNSERRERRRAPRSPRGPKKSDKPDELNPAVQDQTPTTIDILENREPFAPRGQPSRRGRGGFQGSARPPAPAKRVVGYGPPNTKSPFSQANRAVKDTEEVKDNIDDRGKPNKPRAGSTSGRGRDRRPKGGAPSGEDENWETTSEHSEGGGTSGRRRSAQSQKNSRNANSSNRQNGRISQGGKKDVVTGENKTAAEITEAISDLKLNTKNDEVIDDGFQEVRNKKSSKDTRPPAKEDGQGSGKQSRSHSNQGNGRNRSSTRNSNDKSTNRSSAPVPGKSGSQYDRPRQANLAPRFVKQRQQRQQVGGLVSACGPDTGAAPPPPAVNAWDKPISQTLRGNVEENVDLVENKSAQSSQRSTPAETSTDIKTAPTPCTLSADKTSMLDGATPPVETIIFENTNYKTATPDEALQQKYQLNSNMSKNQTEEVSTEIDSRSLTFNGEVRGRPRSIQELMAESGRQSAEGDASLGLQMSFDTTQKTEDSDMKLDFGFDSDLGQLSEDKSAKSLGLPRGVHMSTSNTISPLAADLNLKIASVKKVWEMPAVAENTEELQFTGFEETNTESAPPNVCKVKPTQQLQSPPPQHYNHVGYQGGYGGLSVPSPPAMLFNSSQQLLGSSQQLPQQGGLYGAFLDQSRGQFGGFPGTPYGAGSAAPYNYQPPPDMFSSIPSQYRMAAGGGAAFGQSGQLGNSPSTVLISSTSNSLMSATVKPTTQQIGAIGAGSKGGGVGGVGGVNTYGQQYLGYSGPVGEAPYSLLPRPAPPASSYYSPYQPPTAPAPTYPLQFTQPAQSGAFGSQFLSSQLQVAAAVQQMQQQYRAPLQQQYPPPQPQPRLPPQQQLKSPLHEHANGFAPLCDAASPTPKGGGKPQKPPHSPPQHKYHAPPQHPPPAHTPHQHHQQQMVSGGNNGRCGGGGGGAAGVMTRGGGPAPRYPAPIQRPHAPALPLYRAPQQRPHHAQPRPNLYYHHPQRNGGGGNERAPENTEPTAGGEESGDPAPPAEVQTVPPPEVKAE
Summary
Uniprot
ProteinModelPortal
Ontologies
GO
Topology
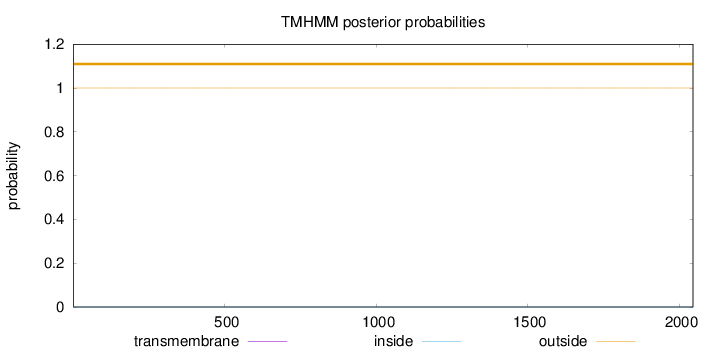
Length:
2045
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00267
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00009
outside
1 - 2045
Population Genetic Test Statistics
Pi
199.576175
Theta
179.998942
Tajima's D
-0.696232
CLR
481.187192
CSRT
0.194040297985101
Interpretation
Uncertain
