Gene
KWMTBOMO08552 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA009316
Annotation
PREDICTED:_LOW_QUALITY_PROTEIN:_neurobeachin-like_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 2.983
Sequence
CDS
ATGTTGATATTGTTTCAGGCTGTAGTACTACCGCCGTTGGCGCGGTGGCCGTACGAGAACGGCTTCACGTTCACCACCTGGTTCAGACTGGACCCCATCAACTCCGTCAACATCGAAAGGGAAAAGCCTTATTTGTACTGCTTCAAGACAAGTAAAGGCGTCGGCTACACAGCGCACTTCGTCGGTAACTGCCTCGTGCTTACATCCATGAAGATCCGAGGCAAGGGATTCCAGCACTGCGTGAAATACGAATTTCAACCGAGGAGATGGTATGCCATAGCAGTCGTCTATATATACAATAGATGGACGAAAAGCGAAATCAAGTGTCTAGTGAACGGTCAGCTGGCATCGAGCACTGAGATGGCCTGGTTCGTCTCCACCAATGATCCATTCGACAAGTGCTACATCGGTGCTACAGCTGAATTGGACGAGGAGAGGGTGTTCTGCGGACAGATGGCAGCCATATACCTGTTCGGAGAAGCTCTAACTACTCACCAGATATGCGCCATGCATAGATTAGGGCCCGGATACAAGAGTCAGTTCCGTTTCGACAACGAATGCAACATCAGTTTACCGGAGAACCACAAAAGGGTGTTATACGACGGTAAGCTGTCGTCTGCGATAGTGTTCATGTATAATCCGGTCGCGACGGATGGCCAGCTGTGTCTCCAATCAGCACCCAAGGGCAACGTTTCTTACTTCGTGCACACGCCCCACGCCCTAATGTTACAGGAAGTGAAAGCAGTCGTGACGCATTCGATACACAGCGCTCTGAACTCGATAGGGGGAGTGCAAGTCTTATTTCCGCTGTTTTCTCAACTCGACCTACAGCACGACGCGCCGCCGAACGATCCCAAACGAGATCCCTTGCTATGTTCGAAGCTGCTTGGGTTCGTTTGTTCCTTGGTGGAATCCTGCAGCACGGTTCAGCAACACATGCTGCAGTGTCGCGGGTTCCTCGTGATCTCTCACATGCTGCAGAGGTGCTCCAGAGACCACCTGACGCCTGATACGCTCGCCTCCTTCCTGCATTTAACGAAACATCTTGTAACTTGCTGCTCTCCTAATTCTGATCTGCTATTAAAACAGCTCCTGGACCACATATTGTTCAACCCCGCGCTGTGGATCCACACTCCTGCTGCAGTACAGGCCAGGCTTTACTGCTACTTGGCGACGGATTTCCTCGCTGACGCCCACATATACGGAAGCGTCAGAAGAGTGAGCACGGTCTTGCAGACTGTTCACACGCTGAAGTTCTACTACTGGGTCGTGAACCCGAGGGCCAAAAGTGGAATCGCACCCAAAGGACTCGATGGTCCTCGACCAGCTCACAAAGATATATTAACAATCCGAGCGTACATTTTGTTGTTTTTGAAACAACTGATCATGATCGGGAATGGCGTCAAGGAGGACGAACTGCAATCTATACTCAACTATCTAACTACCATGCACGAGGATGAAAACTTGCATGATGTTCTGCAGATGTTGATCTCATTAATGTCCGAGCACCCCAGCTCCATGGTACCTGCTTTTGACGCGAAAGGCGGAATAAGGACAATATTCAAGCTGTTGGCGTCAGAAAGTCAATTAATAAGGTTACAGGCGCTAAAACTTCTCGGTTTCTTTCTGAGCAGAAGCACGCACAAACGCAAATACGACGTAATGTCGCCACACAACCTGTACACGTTGCTGGCAACCAGACTGGGGGCGAGCGGCGAGGGACTGGCCCTGCCCGTCTACAACGCCCTGTACGAACTCCTCACGGAGCACGTCGGGCAGCAGATACTGTACACCAGCCACCCGGAGCCGCAGCCACACTTCAGACTCGAAAATCCTATGATCCTGAAGGTGGTGGCCACGCTGATAAGGCAGTCGAAGCAAACGGAACAGCTGCTGGAAGTGAAGAAGCTGTTCTTGTCGGACATGACCCTGCTGTGCAGCAACAACCGCGAGAACCGACGCACCGTGCTGCAGATGTCCGTATGGCAGGAATGGCTCATAGCGATGGCTTATATCCACCCAAAGAACGCCGAGGAACAGAAAATCTCTGACATGGTCTACTCGCTGTTCCGGATGCTTCTTCATCACGCCATCAAACATGAATACGGAGGCTGGAGAGTATGGGTGGACACATTAGCCATTGTGCATTCAAAGGTTTCGTACGAAGAATTCAAGTTGCAATTCGCACAAATGTATGAACATTACGAGCAAAGACGAGCTGACAACATCACAGACCCAGCCGAGAGACAACAACGACCCATCTCCACTATATCCGGCTGGGACAGGCACGCCGACACCCAGCACACCCCACGCGTCATCCCGGACACAGACGACAGCATGGACAGCTCTCCCGCGTCCATCAGGAAGCAGAATGTGCTCAATCACGGCGCGCAGACCGAAATCGGAAAAGGGCTCTCGTTGCGAGAAGTCGAATCGTGCAATTGTACCACAGTTAAAGCAGAAAGTGATAAAAGTGAGGAAGAATCCGATCGGACTACACAAGTCGTTTATAGTGAAGTGTGTAAAGTGCATAGTCCCGTTAAAACTGTTGAAGCCGCAGTGCCCTCCGCCGATGGCTGTGATGCTGTGATCCGCGACTCTGAAGTCGAACACGCAATCGATGAAGCCGAGTCTGAGAATGAACAGACAATCTTCAACCCTGCTATACAGTCCAGTAACGAATTAGTAGAATCTATTATAAGTGAAGATACTATTTTGGGCACTGAATCTGGATTAGGGACGTTAGAGAAACCCGAAAAACTCAACCGACAAGGAAGTTTAGATTATATTCCAGTCAGAGATGTAGGCGACACCGTATCTAAAGATGACAACACAGATAAGAGTGAGGGAATACCGTCAAGTTTATCTGTGAGTGAAACAGCTAGTCCCGAGAGAGTAGCGGACTTAAATATCGTTACTGAGAGAGAATCTGAGCTTTCAGATCCATCCGAACTATACTTAACCCCTAGCGAAGCCACCAGCCCAAAGGAAGTTGAGGAAAAAGTTGAAGTTTTAGATGAACCAACAGACGGTATCGACGATCCGAGGCACGTCGCTGTAAACATTGTCAATGACGTACTCAGTGTGGCGCTGGAGACCGTTAGGCTGAAAGCTGACGACGACACCGACTCTGGTGCGATATCCGGCGGATTGCAATCCGAAGGTAACACGCCAAACGGTCGCGATGACTTCGATCAAGAAATCGAAGAAATCGTTAGCGAGAAACAAGCTGCTGAGTCTATAGCTAATGAAATCGTTATGGATATTGTAGAATCTGCATTGGCTAAGGGCGCTGAGAATACTGAACCATCCGAAGAGAATAGCCCGCAAAGGGTGTTACCCTCGGATCATCCTCACGAAGGGAACGTTTTGCCACTAGACGGTGAATTCTTGGTTAGTCCCAGAGAAGAGGATGCTGAAAAACTTGAGGTTGAAGAAGATTCTGAAAAGATTCCTGAAGAAAATATGAACATTGAAATTGAAAATGCCGATACTGAAGAACCAGAGCAACAGAAAACGACGGAAATTCCACCAATCTCGACTATCAGTGAAAACATATCTTTAGCGAACAAGAAAGAACAAGAAACCGATGAAGATAGAGGTAGAGAGGGTGAGAGAGAAAAAAGACGGGTCAGTTTACCCGAAGACAGCGAGAGTAAGCAGGATAGTGCTAGAGGTGAGGGTGTGGCCTCGCACGGTACCAACACGTCATCATCACCCAAAAGGCCTCGAAGTGCGTCCACTAGTACACAAGTGGACTCTAATCATTTTGAATCGAAACGTCCATCGAAATGCTCCAGACCTATGTTCTCCCCGGGACCCACTCGCCCCCCGTTCCGCATCCCCGAGTTCCGCTGGTCCTACATCCACCAGAGGCTGCTGTCGGATGTGTTATTCTCATTGGAAACTGATATTCAGGTTTGGCGAAGTCATTCCACTAAATCTGTCATAGACTTCGTCAATAGCAGCGAGAACGCCATCTTTGTCGTGAATACCGTACACCTGATCAGTCAGTTGGCCGACAATCTGATCATCGCTTGTGGAGGGCTCCTGCCGCTCCTAGCGTCGGCCACGTCACCCAATAACGAGCTCGATGTCATCGAACCGACCCAGGGTATGCCGGTGGAGGTGGCTGTGACCTTTCTACAGCGACTGGTCAGCATGGCGGACGTTTTGATATTTGCAAGCGCCCTTAACTTTGCCGAGCTGGAGGCTGAGAAGAATATGTCCAGTGGCGGTATCCTGAGGCAGTGTCTCCGACTTGTGTGCACGTGTGCGGTGCGCAATTGCCTCGAGTGCAAGGAGCGCCAGCGGTACGCCGCCGCCAGGGCTGCACGTGCCGGAGACTCGCCCTCGCCGAAGAGCGTCGTGGCGAGTCTTGCGGACGCCTCCAGCCCCGTCAAAGATCCGGAAAGGCTTCTGCAGGACATGGACGTCAATCGACTTCGAGCTGTTATCTACAGGGATGTTGAGGAGACGAAACAAGCGCAGTTCTTGTCGCTTGCCATCGTTTATTTCATCTCGGTACTGATGGTTTCGAAGTACCGCGACATCTTGGAGCCGCCCGCCCACGCGCCTCCGGAATGTTCCAGAAGACCGCACCACTCCCACGAGCATCACGGGTCTAGGCCTCTGTTCCCCCAGTGGTCGCACCACGTGTACCCGCAGTTCCTGCCGGGTGGGCATCCCGCTCACCGACATCCACACTCGCACTGCAAGCTCGACTGCAGCCAACACGTTAACAATAACACGCACGCACACTCACGCATCGCTAGTTACCACCGCACACACGCAGAACACAACGGGGATGATGTGGAATACGCCATGATTGTTGTTGACGAGAACAATTCTACAATAAACGAATTAGATTCACCATCGATGAAGGAGTCGGAAGCCAAGGAAGATGCTGTGGCAAAAATAGAAACAACGGCCATAGAATTGAAGCCGCCGTCTCCGGAACAGCCCGAGCTGAGTAAGCCGGCTGAGACGCCCACCCCAGAAAAGGAAGAACCGCTTTTCAAGTCGAGCCTCCGAGTGAAACCGCAGCCCAAAATAAAGAGCGTGGATTCGATCGAAGACGCCGGCTCGTTTCATCTCAACTCTAATGAGACTACTAACAATGATCCTGAGACCTCCAGCGAGATCGCTCTAGATGATAACAAACACGCGGCCAGTAATGACGAATCTTGGACCGATGTCAACTTGAATGAAGAGGGTGAAAGGGGTCCGGCCACCATTACTGGGAGAACGAGAGACCACGAAGGGAACATTCATGAAGATATCGACAAACAAATTCATATGAGGAATACAGATTCACATCACCACATTCAACAACGACAGAACAGAAACCTTCAGGCTGCACAACGGCATTTACATCCGGACAATGAGACCCTGGCTGGTCTAAATGCAATGAACGCTTCGATGTCCGCCGACGGAGTGTCCCGGGAAGCCTCTCTGACCCACAAGCTTGAGACAGCCCTGGGCCCTGTCTGTCCGCTTTTGAGAGAGATAATGCTAGATTTTGCTCCTTTCCTTTCTAAAACCCTGGTAGGAAGCCACGGACAGGAGCTCCTGATGGAGGGTAAAGGTCTCCAAACATTTAAATCCAGCACTTCGGTAGTGGAACTCGTGATGTTGCTCTGCTCGCAAGAGTGGCAGAACTCCCTCCAGAAGCACGCCGGCCTCGCCTTCATCGAGCTCATCAACGAGGGACGGTTACTGTCCCACGCCATGAGGGACCACATTGTCCGCGTTGCGAACGAAGCTGAGTTCATCCTCAACAGAATGAGAGCTGACGATGTTTTGAAACACGCCGATTTTGAGTGCCTTTGCGCCACGAGTAGCGCGGAGCGAGCTGACGAGGAGCGGACCTGTGAGCGGCTGATCGCGGCGGCGAGGAGGAGAGACACCGCGGCCGCCGCCCGCCTGCTGGACAAGCTCCGCCACGCTGCAGCACACCAGGCCGGGACCGGCACGCAGTTCTGGAAGCTAGACTCGTGGGAGGACGATGCCCGGCGCCGGAGGAGACTGGTGCCCGACCCACGCGGACACCGACACGACGACGCCGTGCTCGTGCGCCAACACGCGCAGCCGCCGCCCCACGACGCCATCCTCCAGGTCAGCACGCTCTGCAACGCCGCGCTACATCTACCGCCAGGGGATAATGGGCTCCTGGTTGAAGAGTGCCACCCAACATTCTAA
Protein
MLILFQAVVLPPLARWPYENGFTFTTWFRLDPINSVNIEREKPYLYCFKTSKGVGYTAHFVGNCLVLTSMKIRGKGFQHCVKYEFQPRRWYAIAVVYIYNRWTKSEIKCLVNGQLASSTEMAWFVSTNDPFDKCYIGATAELDEERVFCGQMAAIYLFGEALTTHQICAMHRLGPGYKSQFRFDNECNISLPENHKRVLYDGKLSSAIVFMYNPVATDGQLCLQSAPKGNVSYFVHTPHALMLQEVKAVVTHSIHSALNSIGGVQVLFPLFSQLDLQHDAPPNDPKRDPLLCSKLLGFVCSLVESCSTVQQHMLQCRGFLVISHMLQRCSRDHLTPDTLASFLHLTKHLVTCCSPNSDLLLKQLLDHILFNPALWIHTPAAVQARLYCYLATDFLADAHIYGSVRRVSTVLQTVHTLKFYYWVVNPRAKSGIAPKGLDGPRPAHKDILTIRAYILLFLKQLIMIGNGVKEDELQSILNYLTTMHEDENLHDVLQMLISLMSEHPSSMVPAFDAKGGIRTIFKLLASESQLIRLQALKLLGFFLSRSTHKRKYDVMSPHNLYTLLATRLGASGEGLALPVYNALYELLTEHVGQQILYTSHPEPQPHFRLENPMILKVVATLIRQSKQTEQLLEVKKLFLSDMTLLCSNNRENRRTVLQMSVWQEWLIAMAYIHPKNAEEQKISDMVYSLFRMLLHHAIKHEYGGWRVWVDTLAIVHSKVSYEEFKLQFAQMYEHYEQRRADNITDPAERQQRPISTISGWDRHADTQHTPRVIPDTDDSMDSSPASIRKQNVLNHGAQTEIGKGLSLREVESCNCTTVKAESDKSEEESDRTTQVVYSEVCKVHSPVKTVEAAVPSADGCDAVIRDSEVEHAIDEAESENEQTIFNPAIQSSNELVESIISEDTILGTESGLGTLEKPEKLNRQGSLDYIPVRDVGDTVSKDDNTDKSEGIPSSLSVSETASPERVADLNIVTERESELSDPSELYLTPSEATSPKEVEEKVEVLDEPTDGIDDPRHVAVNIVNDVLSVALETVRLKADDDTDSGAISGGLQSEGNTPNGRDDFDQEIEEIVSEKQAAESIANEIVMDIVESALAKGAENTEPSEENSPQRVLPSDHPHEGNVLPLDGEFLVSPREEDAEKLEVEEDSEKIPEENMNIEIENADTEEPEQQKTTEIPPISTISENISLANKKEQETDEDRGREGEREKRRVSLPEDSESKQDSARGEGVASHGTNTSSSPKRPRSASTSTQVDSNHFESKRPSKCSRPMFSPGPTRPPFRIPEFRWSYIHQRLLSDVLFSLETDIQVWRSHSTKSVIDFVNSSENAIFVVNTVHLISQLADNLIIACGGLLPLLASATSPNNELDVIEPTQGMPVEVAVTFLQRLVSMADVLIFASALNFAELEAEKNMSSGGILRQCLRLVCTCAVRNCLECKERQRYAAARAARAGDSPSPKSVVASLADASSPVKDPERLLQDMDVNRLRAVIYRDVEETKQAQFLSLAIVYFISVLMVSKYRDILEPPAHAPPECSRRPHHSHEHHGSRPLFPQWSHHVYPQFLPGGHPAHRHPHSHCKLDCSQHVNNNTHAHSRIASYHRTHAEHNGDDVEYAMIVVDENNSTINELDSPSMKESEAKEDAVAKIETTAIELKPPSPEQPELSKPAETPTPEKEEPLFKSSLRVKPQPKIKSVDSIEDAGSFHLNSNETTNNDPETSSEIALDDNKHAASNDESWTDVNLNEEGERGPATITGRTRDHEGNIHEDIDKQIHMRNTDSHHHIQQRQNRNLQAAQRHLHPDNETLAGLNAMNASMSADGVSREASLTHKLETALGPVCPLLREIMLDFAPFLSKTLVGSHGQELLMEGKGLQTFKSSTSVVELVMLLCSQEWQNSLQKHAGLAFIELINEGRLLSHAMRDHIVRVANEAEFILNRMRADDVLKHADFECLCATSSAERADEERTCERLIAAARRRDTAAAARLLDKLRHAAAHQAGTGTQFWKLDSWEDDARRRRRLVPDPRGHRHDDAVLVRQHAQPPPHDAILQVSTLCNAALHLPPGDNGLLVEECHPTF
Summary
Uniprot
EMBL
Proteomes
PRIDE
Interpro
ProteinModelPortal
Ontologies
GO
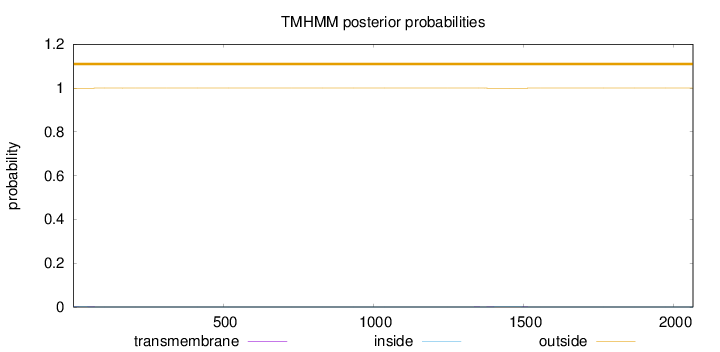
Topology
Length:
2066
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.0568399999999999
Exp number, first 60 AAs:
0.00904
Total prob of N-in:
0.00090
outside
1 - 2066
Population Genetic Test Statistics
Pi
220.807861
Theta
178.720159
Tajima's D
0.828431
CLR
0.359576
CSRT
0.610669466526674
Interpretation
Uncertain
