Pre Gene Modal
BGIBMGA009372
Annotation
PREDICTED:_pre-mRNA_cleavage_complex_2_protein_Pcf11-like_isoform_X2_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.283
Sequence
CDS
ATGCTCACAATTCTTGCGGAAGAGAATATCGAACACGCTGGGGTTATCGTTGAAACCGTGGAAAAGCATTTGGAGAAGGTGCATCCCGATATCAAGTTGCCAGTTCTGTATTTAGTTGATTCAATTATCAAGAATGTTGGCGGAGCCTACACACAAAAATTCTCACAGAGTATCGTCAACATGTTTACAAGGACTTTTAAGCAGGTTGATGAGAAAATACGGTCACAAATGTTCAAACTTCGTGAGACTTGGCACGATGTGTTCCCAGCGACGAAGCTGTACCAGCTAGATGTCAAAGTCAACCTCATTGATCCAGCATGGCCGATACAGGCCCAACCCCAGCAATCAAACATCCATCCACCGGCTTCCACACCGGTGTTGACTGACGAAGAACGAACCATCATCGCTAAGAAAGAGCAGGAGCTGCTCATGCTACAAAAGAAAAAGATTGAGTTGGAATTGGAGCAGACACGGAAGCAGCTTGAGGTAGCTGAGAAGAATGCTAAAAAGGTGGTGACAGCAGTCCCTCCCGTGGTGGCCGCAGCGACTGCGCCCGTCGCCCCCGCCGCGACTCCGCTGGTCTCCGTCGCTGCGCCAGAGGTCACCCCTGTACCTGTCAGACAGAGGCTCGGACCGCCAATAAACAAAACGGGCAGTCGGATAGCGCCCGTGAGCGCGGGGCTGGCCGCCATGCGCCGCGACCCCCGCTTGGCGCGCGCGCCCGCCCCCGCGCGCCCCGCCCCGCCCGCCGCGCCGCCCGCCATCGCCCCGCACGTGTTCGACATCAAGCCGCTCGACCGCGTCACCAAGCGGAAGAACGTCATCACCATCGACGTGCGCTGCCCGGCGCCCGCGCCCCGGCCCTCGCCCCGCCGGGACCCTCGCCTGCACAAGCGCGGGGGCAAGGCGCCGGCGCCCAACGCGGACGGCTACGTCGACGCCTTGCCCGACCCTAAAAAGATCAGCAAGCTCCCGCCCATACCAAAGATAGTCCGGGAGGCGCCCTCCTCGAATAAAAAGCGGAAAGATTCCCGCGAGAAAAAGAAAAAGAGGGACGACGGCAAGGAGAGCTCGAGCGGCTCGTCGCCGGACAAGCGGCTGCGCGCCAAGAACGGGAACAAGGCCCAGAAGAAGAAGGAGCCGGACGCGCCCGTGGCCTTCAAGGAGCTCAAGAACTATGTGAAGGGGCGGTACATGCGCCGCAACAAGGAGCCCTCCGAGAGCCCGGAGAGGCCCGAGGCCGCCGCATCAAGTGTGCCCGACGTGGTCGTAGAGAATAAAGACATCGATCTCAGGGTGCTCCCGCCCGCCAGCGAGCCGCCGCCCGCGCCCGTCGCCCTCAAGAGGTCCTCCACTGAAACGCTCGAACCAAAACCTAAAAGGAACAAACTTGACAAATTTGATATTCTCTTCGGCAATGAAGATGTTGATCTCCGGAAGCTGCCACAAGTTGAAGAAATTCTCCCAGTGGCTCCGCTATCACCGAAACACAATGACGAGTCTCAAGAGAGTGGACCCGACAAGGTCGTTTCCCCTCACGACTCTCCCAAACAAAAAGACTGGAATGAAGTCAAGGAGAAAACTGAAAAGAAGGCTCCATCCAAGTTAGATTTGGTGCGAGCCAAGCTTGCAGAGGCCACTAAAGGCAAGGACAGACTGGGCAGACCTTTACTCTTCAGTAAGTCGCCAAGTATTGAAAGAGAACGGAAGCGTACCTTAAGTTCTGAGGACACTGACCTTAGAAACGAAAATTCCGACGAGTACGACACCGAAGACCACAAGAAGACAATTTCCATCATAATGTCGCAGGCCAAGGAGCAGTACAGCGACGGGCAGATCGACAAGAACCAGTACAACACGCTCGTCTGTCAGGTTCTGCAGCTGAACGAGAAACTGAAGTTGAAAGAGGCGAAACAGAGAGAGTCTCTCGAAGTTTCTAAAAGGAGACTCAACGCGCACATACTCGAAGATAGCTTCAAGGTCGCGTCCCCGAAGTCGTCGCCCGGCGAGAACAACTACGGCGACATCGACGAGCGGGTCCCGCCCACCGCCTACCTCGACGCCCTGCACAACGGCAACGAGCTCAGGCAGGACTCCGACATGCGCGCCGGACCCGCCGACCAGACCGACGGACACAAGGCCAAGGGGCTGTTACCCAGGCCGCCGATGATGCCCATGTTCGGACCCTTCCCTCCCATGTGGAGGGGACAGCCTCACCCCCGGATGGACGAGTACGGCCCCAGGAGGTTCCGAGGGCCGATGCCATTCTTTAGGGGGAAATTCGATAACAGACTCATGAGACCGCCCTTCGACCCACGGATGACCGTGCCTTTGCCGACCCCGAAGCTTGGTATCTGTCAAGGGGAGAGCCCGCTCGAGCCCTACGTGAGGAGCGAGTCTCCCCCTCCCCTGGGAGCTCCTGGGTTCGTTATCCCGCCGACTGACTACCGAATCTTGGAGTACATCGAGCAAGATCCCGTGAAGACCATACAGATAGACGGCGTGCCGCGCGAGATACGGTTCTACGGCGACACGGCGGTCATCATGCTGGACTGGGACGACCCCAGGGAGATCAAGTTCTTGCCTGGCTCGAGACGCGTCACGTTCGACAACAAAGACTCGGTGGTCCTCTCGTTCAACGAAGAGAGCAGACAAATAGAAATAGACGACCAAGTGTTCGATATAAAGTTCGGGGCTCCCACCCGGGAGCTGTGCATCAACGGGCGGTGGTACGAGTGCTTCTTCGGAGGCCAGCCCGTGGGCGTGCTCATCGACGGGCGGCCCCGGCTGGTGCAGCTGGAGGGCCCGCTGCCGCAGGTGGACATCGGCAAGGCGAAGCGGACGGAGCTGGTGGCCGGCAAGATCAACCTCATAGTGAACGCGACGCAGATGTGCCCCGTGTACCTGGACGCTAAAGTGCAGAAGTTTACAATAAACGGACAGTTCTTTACTATCAGATTTGTTGATTCTTTGAAAACTGTTTTAATAAACGAGCAGCCATTTAAAGTTGAGTTTGGTGATTTACCCAAGCCCATAAGTATAGGGAACGAAAAGTTCTTCATAAGATTCTCGGCTTTACCCAGAAACGTAAAGCCGGGCTATATACAGATAGCTAACATGGAAGGAGTCACGCTGCCCAGCATGACGGCGGCGCCCGCGGGCCGCAGCGTGCCGCAGCCCATGGACACCGACCAGGAGCCCGACAGAGCCGTCAAGACTCCTAGCCCGGATATCAATAATGAAAATCAAGGTCTAGAAATGTTGGCCAGCGTGATGCCTTCGAGCATAGTGCCGGCGTCCGCGTCCGAATACAGCGTGGCCGAACCCTTATTCGGGAAGACCGACATGATCCCGGGCCTCGACACTCCGGCCGACGAGAAGCCGAAGCCGACTCTACCGATCCTCGACAACATCAACGTTAACGATTTGTTCGCGAAGCTGGTGGCGACCGGCATCGTCCAAGTGCAGAACGACAGCGCTAAAGACCTGAAGATTGAAACTAAAGTCGAGGAGAAGATAAAACCGAAGGAAGACAAAGACGTCACGCACAAAGTTGATCTCTTGAAACCGGAGACGTTAAGGAGCAAGCAGGGCGGCGTGGTGCGGCGGCTGTACGGCGGCATGCAGTGCTCGGGGTGCGGCGCGCGCTTCCCGCCGGAGCACACGGTGCGCTACTCGCAGCACCTCGACTGGCACTTCCGCCAGAACCGACGCGACCGGGACTCCGCCAGGCGCGCGCACAGCCGCCACTGGCACTACGACCTCTCCGACTGGCTGCAGTACGAGGAGATCGATGAGCTCGACGACAGAGAAAAGAATTGGTTCGAGAGCGCGGGTAGCGAGGGCGGCGAGGCGGGCGGCGCGGGGGCGGCGGGCGCGGGCGCGGGGGGCGCGGAGGAGAGCAGCGCGGCGGGCGCGCGGCCGCGGTGCGCGCTGTGCGGGGACGCCTTCCACATGTTCTACAACCACGACAAGGACGAGTGGCAGCTGCGGAACTCCGTGCGCCACCACGACGACAACTACCACCCCTCCTGCTTTGAGGACTACAAGGCCTCTCTGGCTAAAGAAGAAGAGAAAGAGAAAGTTGAAGAAACCGCCCCAGAAAAAGTAGAAGAAGACAACGAACCGATAGAGATCAAGGACTTCGACGACACGCTCGACCAGTCCGACAACGAGTCGGTAGTAGAAGTCATTGAACCCCCCGTCGAGATACCAGAGCCTCTATTGATTGACGAAGGAGATGAAGACGATGTGGTGCTGAAGGCCGAGCCGATAGTGCAAGTGGAGGTGCAGGACGACGACGACACGGACGACGAGACGGTCGCGCACCGCGCCGAGCGGGACAGGCTCGCCCGCATCGACTTCTCCAACGTCAAGGTCAAGCAGGAGCCCCTCGACCCAGATGATGAACCAATAATAACGGCTGAAGAAGAATCAATTCCAGCACCTTCTGTTGACATGATCCAACCCACCGTCCACACGTCAATTGATGGAAACGTTCAACTGGAAGCACCCGCAGTGGCTCACGCTATCCCCCTGAACACAATTCGCATCAACATCTCTAAATCTTTGCCATTAACTCAGCTCCCAGTTTCAAACAATGGTCTCGAAGACATCAGTGCTGATGATGAGCCTCTACCTCCTGGTGAGGAGGTGGAGTTGGAATATACTTTGAAACCAACCTTGGAAGGCATTAAGTTCAGCAGACAACCCCCAGTCCAGAAAGGCAATGAGCTATCAGGACTCTGCTCCATAATGTGA
Protein
MLTILAEENIEHAGVIVETVEKHLEKVHPDIKLPVLYLVDSIIKNVGGAYTQKFSQSIVNMFTRTFKQVDEKIRSQMFKLRETWHDVFPATKLYQLDVKVNLIDPAWPIQAQPQQSNIHPPASTPVLTDEERTIIAKKEQELLMLQKKKIELELEQTRKQLEVAEKNAKKVVTAVPPVVAAATAPVAPAATPLVSVAAPEVTPVPVRQRLGPPINKTGSRIAPVSAGLAAMRRDPRLARAPAPARPAPPAAPPAIAPHVFDIKPLDRVTKRKNVITIDVRCPAPAPRPSPRRDPRLHKRGGKAPAPNADGYVDALPDPKKISKLPPIPKIVREAPSSNKKRKDSREKKKKRDDGKESSSGSSPDKRLRAKNGNKAQKKKEPDAPVAFKELKNYVKGRYMRRNKEPSESPERPEAAASSVPDVVVENKDIDLRVLPPASEPPPAPVALKRSSTETLEPKPKRNKLDKFDILFGNEDVDLRKLPQVEEILPVAPLSPKHNDESQESGPDKVVSPHDSPKQKDWNEVKEKTEKKAPSKLDLVRAKLAEATKGKDRLGRPLLFSKSPSIERERKRTLSSEDTDLRNENSDEYDTEDHKKTISIIMSQAKEQYSDGQIDKNQYNTLVCQVLQLNEKLKLKEAKQRESLEVSKRRLNAHILEDSFKVASPKSSPGENNYGDIDERVPPTAYLDALHNGNELRQDSDMRAGPADQTDGHKAKGLLPRPPMMPMFGPFPPMWRGQPHPRMDEYGPRRFRGPMPFFRGKFDNRLMRPPFDPRMTVPLPTPKLGICQGESPLEPYVRSESPPPLGAPGFVIPPTDYRILEYIEQDPVKTIQIDGVPREIRFYGDTAVIMLDWDDPREIKFLPGSRRVTFDNKDSVVLSFNEESRQIEIDDQVFDIKFGAPTRELCINGRWYECFFGGQPVGVLIDGRPRLVQLEGPLPQVDIGKAKRTELVAGKINLIVNATQMCPVYLDAKVQKFTINGQFFTIRFVDSLKTVLINEQPFKVEFGDLPKPISIGNEKFFIRFSALPRNVKPGYIQIANMEGVTLPSMTAAPAGRSVPQPMDTDQEPDRAVKTPSPDINNENQGLEMLASVMPSSIVPASASEYSVAEPLFGKTDMIPGLDTPADEKPKPTLPILDNINVNDLFAKLVATGIVQVQNDSAKDLKIETKVEEKIKPKEDKDVTHKVDLLKPETLRSKQGGVVRRLYGGMQCSGCGARFPPEHTVRYSQHLDWHFRQNRRDRDSARRAHSRHWHYDLSDWLQYEEIDELDDREKNWFESAGSEGGEAGGAGAAGAGAGGAEESSAAGARPRCALCGDAFHMFYNHDKDEWQLRNSVRHHDDNYHPSCFEDYKASLAKEEEKEKVEETAPEKVEEDNEPIEIKDFDDTLDQSDNESVVEVIEPPVEIPEPLLIDEGDEDDVVLKAEPIVQVEVQDDDDTDDETVAHRAERDRLARIDFSNVKVKQEPLDPDDEPIITAEEESIPAPSVDMIQPTVHTSIDGNVQLEAPAVAHAIPLNTIRINISKSLPLTQLPVSNNGLEDISADDEPLPPGEEVELEYTLKPTLEGIKFSRQPPVQKGNELSGLCSIM
Summary
Uniprot
EMBL
Proteomes
PRIDE
Pfam
PF04818 CTD_bind
SUPFAM
SSF48464
SSF48464
Gene 3D
CDD
ProteinModelPortal
PDB
1SZA
E-value=1.49657e-11,
Score=173
Ontologies
GO
Topology
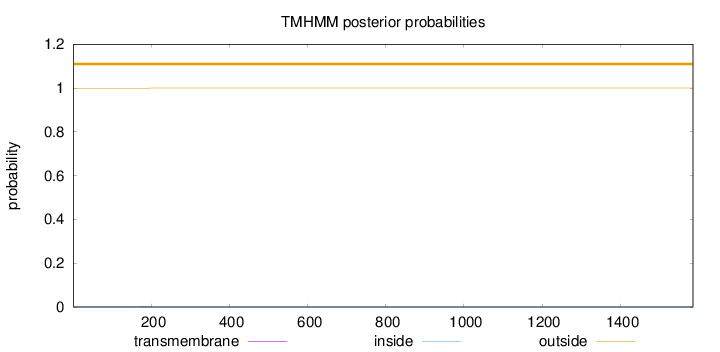
Length:
1586
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.01855
Exp number, first 60 AAs:
0.00176
Total prob of N-in:
0.00085
outside
1 - 1586
Population Genetic Test Statistics
Pi
223.578181
Theta
171.475118
Tajima's D
0.082516
CLR
1.222185
CSRT
0.396030198490075
Interpretation
Uncertain
