Gene
KWMTBOMO08509 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA009362
Annotation
PREDICTED:_coronin-7_[Bombyx_mori]
Full name
Coronin
Location in the cell
Nuclear Reliability : 3.29
Sequence
CDS
ATGGCGTGGAGATTTAAAGCATCAAAGTATAAAAATGCGGCGCCTATCGTGCCCAAGCCCGAAGCTTGCATTCGTGATGTATGCGTAGGTTCATACCAGACTTATGGGAACAACATTTGTGCATCTGCTGCCTTTATGGCCTTCAACTGGGAACATGTTGGATCAAGCATGGCTGTTTTGCCTCTGGACGACTGTGGCAGGAAAAGCAAGACAATGCCTCTACTCCACGCCCATTCTGATACCATAACCGATATGGAGTTTTCTCCGTTCCACGATGGGTTATTGCTGACCGGATCTCAGGATTCTTTGGTAAAAGTTTGGCACATACCCCCTGAAGGACTTAAAGAGTCTCTGTCGACTCCGGAGTGCTCCCTCTCACAGAAGCAAAGAAGAGTTGAGAATGTCGGCTTTCATCCAGTTGCTGATGGCCTGATTCATGTTGCATCAGGACATGAGTTGTCTCTGTGGGATTTAACTCAGCAGAAGGAGGCGTTTGTAAACAGGGATCATTCTGAAGTTATTCAGTCAACATCTTGGAAGAAAGATGGCAAGCTACTAGCAACATCATGCAAAGACAAGAAAGTGAGGATATTAGACCCGAGGGCCGCCGCGCCCATTCTGGATGTGGCCAACAGCCATCAGAACATCAAGGATAGCAGGATCGTGTGGTTGGGAGATCAGGATCGGATATTGACTACTGGTTTCGACTCAGCTCGCCTCAGACAGATTATAATACGTGACGTCCGTAATTTCTCTCAACCTCAGAAAACATTGGAGCTTGATTGTTCCACCGGAATACTGATGCCACTGTTTGATGCTGACACCAATATGCTGTTTTTGGCTGGGAAGGGTGACACCACCATACTATACATGGAGCTCACCGATAAAGAACCATATCTAATTGAGGGGTTGAGGCATTCAGGAGAACAAACCAAAGGTGCTTGCCTGGTACCAAAGCGAGCTCTCCGGGTCATGGAAGGTGAAGTCAACCGAGTACTGCAATTGACCGGGTCTTCTGTAGTACCGATAATGTATCAAGTACCCAGGAAGAGCTACCGCGAGTACCACGCGGACCTGTACCCTGACACGGCGGGCACGCTCACGTACCTCAGCGCCCCCATGTGGCTGGACAGTCTGGATCACCCAGTACCCAACATTTCTTTGAACCCAGCGGATAATAACTGCACCCAGATACATCGCGGTGATTTAGATAAAGTAGTGAAGGCGATTTTGTCAATGCCGCCATTAAAAAAGACCGAAGCCAAAAAGACTGCCGTGTCTCCTCGCATCGAAGACTTGAAGCCGTTACCGAAGACTCTACCGACACCAGACCCAGAAGAAGACCGCATCGATTTCGTGAACGTTAAAGACCTCATCAAAGGTATGGAGAGGCAGACCAAAGAACCAAAAGAGACGAATGGCTTCAGCAAGAAGATCACGGATAACGGACACGAGAACTCCACAAAGAGTTACGAGTGCGAACAAAACGAGACGACCGATGAGAAGACTGGGAAGACCGAGAAGACCGTCGATAAATCGGACAGCATCGAGTCCCCGGAGGGTTCCATGTCGAGGAGCAACAGCCTGGTCAACGGCGCGCCGACCCAGGCCCCGAAGCCGCTGCCCAGGTCCTCCATATCCGAGCCCGGCTCTGCGGACGAGCCCTCTGAAGTTCCCAAACCCAAACCCAGGACGACCGCCTCTCAGATATCTGGATACAAGCCCCGCCTGGGACCGAAGCCGTTCTCGGCGTCGTCGGGCAGCGAAGAGTTTTCGTTCGACAAGGTGTTCTCCGTGCCGACTGTGCCCGGACTCAAATCTGATGCAGTCACTTCACCGGCATCCACGGAGGCGACCACCCCGGTCTCCGCACCGCTGGTGAAGGACTCGTCCGAAGAGAAAGATAAGTCTCTCTCCCCGACTAGCGATATGGATAATCAGCCCAGCAAAGAGGAGTATATAAATGGAAAATCTGACACGAGTCTTGAAGAAGAGGTGAATTCATCTGATTCCGGCTACAGACCGAAGACGCCCAGCACCGCGGAGAGGAGGAAGATGTTCGAGTCCACTGAGTGCGGCGCGGGGGTGCAGTCGATAGCGGACCGGCGCCGCGCCTACGAGCTGCGCTCCCTCAGCGCGCTGGAGCCGCCCCCCTCGCCCTCGCCCGCGCCCCCCTCCCCCGCGCCACTCAGACGTAGAGACTCGCTGAAGTCCCGCAAGAGTCCTGACCGGGAGGAGAAACGTTCTTCAGTACCTAACGTTACTACCAAGAGAACTTCAACTGTCTTCGGTAAAGTGTCCAAGTTTCGACATTTGAAGGGCACGCCGGGACACAAGTCCACTCAAGTCGAGAACATCAAGAACATCAGCCGGCAGATCTCCGGAGAGTGCAACGGATTTTATGCGAACGGCGTGCGGTGCGCCGTCCCGCTGGCGGGCGGGGGCGGGCGGCTCGGCGTAGTGGAGCTGCCCGCGGGCGCCAGCCCAGTGTCGCGCGGCGCCGCCCCCCCGCCCGGCGGCCTGCACCCCCCCGCGGTGCTGCATCCCGCGGCGCTGCAGGACTGGTGTTGGGACCCCTTCAGGGACGACCGGCTCATGGTCGCGTGCGACGACGGTCTCATCAGGGAGTGGATCATACCAGAGAACGGTCTTCAAGAATCAACAAACGAACCAAATCGCATATTCTCGGCTCATCCAGACAAAATCTACATTATACGTTTCCACCCCACGGCCTCCGACATCCTGACCACGGCCGCCCACGATCTCACCGTCAAGATCTGGGACCTCAGCGTCGACGAACCGAAGGCGGAAATTGTATTGACCGGTCACACCGAACAAATATACGCTCTAGACTGGTCACCCTGCGGAGAACATTTGGCTACACTGTGTAAAGATGGCTTAATTAGGGTGTACGCCCCCCGCTCGTCTGCGTCCCCGCTGCGCAGCGGGGCGGGCCCGGCGGGGTCGCGGGGGGGCCGCCTGGTGTGGGCGCTCGGGGGGACGCATCTAGTCGTCACCGGCTTCGACAAAGTGTCGGAGCGGCAGATCCTGCTGTACAGCGCGACACAGCTGGAGGCGCCGCTGTGCACGCTGGGGCTGGACGTGTCTCCAGCTGTTCTGCAGCCTCACCTGGACCACGACTCCGCCACGCTGTTCCTCACGGGCCGGGGTGACTCCACCATCTACTGCTACGAGGTGACGGGCGAGGCGCCGCACCTGTGCGCGCTGTCCCACCACCGCTGCGCCACGCTGCACCAGGGGATCTGCTTCCTGCAGAAAAATCTTGTCGCTGTCGAGAAGGTCGAATTCGCTCGCGCTTTGAGACTTACGAATGGCAACATCGAGCCCCTGTCGTTCACGGTGCCCAGGATAAAGAGCGAGCTGTTCCAGGACGACCTGTTCCCGGCGACGCTGGTGACGTGGCAGCCCTGGCAGGGCGCGCAGGGCTGGCTGCAGGGCCGCCCCGCGCCCCCCCGCCACCGCAGCCTGCAGCCGCCCGGCATGCCTGCACGTGCGTAG
Protein
MAWRFKASKYKNAAPIVPKPEACIRDVCVGSYQTYGNNICASAAFMAFNWEHVGSSMAVLPLDDCGRKSKTMPLLHAHSDTITDMEFSPFHDGLLLTGSQDSLVKVWHIPPEGLKESLSTPECSLSQKQRRVENVGFHPVADGLIHVASGHELSLWDLTQQKEAFVNRDHSEVIQSTSWKKDGKLLATSCKDKKVRILDPRAAAPILDVANSHQNIKDSRIVWLGDQDRILTTGFDSARLRQIIIRDVRNFSQPQKTLELDCSTGILMPLFDADTNMLFLAGKGDTTILYMELTDKEPYLIEGLRHSGEQTKGACLVPKRALRVMEGEVNRVLQLTGSSVVPIMYQVPRKSYREYHADLYPDTAGTLTYLSAPMWLDSLDHPVPNISLNPADNNCTQIHRGDLDKVVKAILSMPPLKKTEAKKTAVSPRIEDLKPLPKTLPTPDPEEDRIDFVNVKDLIKGMERQTKEPKETNGFSKKITDNGHENSTKSYECEQNETTDEKTGKTEKTVDKSDSIESPEGSMSRSNSLVNGAPTQAPKPLPRSSISEPGSADEPSEVPKPKPRTTASQISGYKPRLGPKPFSASSGSEEFSFDKVFSVPTVPGLKSDAVTSPASTEATTPVSAPLVKDSSEEKDKSLSPTSDMDNQPSKEEYINGKSDTSLEEEVNSSDSGYRPKTPSTAERRKMFESTECGAGVQSIADRRRAYELRSLSALEPPPSPSPAPPSPAPLRRRDSLKSRKSPDREEKRSSVPNVTTKRTSTVFGKVSKFRHLKGTPGHKSTQVENIKNISRQISGECNGFYANGVRCAVPLAGGGGRLGVVELPAGASPVSRGAAPPPGGLHPPAVLHPAALQDWCWDPFRDDRLMVACDDGLIREWIIPENGLQESTNEPNRIFSAHPDKIYIIRFHPTASDILTTAAHDLTVKIWDLSVDEPKAEIVLTGHTEQIYALDWSPCGEHLATLCKDGLIRVYAPRSSASPLRSGAGPAGSRGGRLVWALGGTHLVVTGFDKVSERQILLYSATQLEAPLCTLGLDVSPAVLQPHLDHDSATLFLTGRGDSTIYCYEVTGEAPHLCALSHHRCATLHQGICFLQKNLVAVEKVEFARALRLTNGNIEPLSFTVPRIKSELFQDDLFPATLVTWQPWQGAQGWLQGRPAPPRHRSLQPPGMPARA
Summary
Similarity
Belongs to the WD repeat coronin family.
Uniprot
A0A437B8C4
A0A2A4JVU7
A0A2H1UZY6
A0A194Q776
A0A195E5Y7
A0A151ILV8
+ More
A0A026WIY7 A0A195EUQ7 E2BLK3 A0A151HYK4 A0A151WWT7 E2AJP3 A0A1I8MS29 A0A0K8UVX9 A0A0L7R304 A0A1I8MS41 A0A3L8DYQ3 A0A1I8PG46 A0A1S4FM51 A0A1I8PFV7 D1ZZH3 A0A1B0B3W2 A0A1A9XVI4 A0A0J7NL61 A0A194RFD0 A0A1B0CN23 A0A146LYG7 T1I6B9 A0A310SE16 F4W4C8
A0A026WIY7 A0A195EUQ7 E2BLK3 A0A151HYK4 A0A151WWT7 E2AJP3 A0A1I8MS29 A0A0K8UVX9 A0A0L7R304 A0A1I8MS41 A0A3L8DYQ3 A0A1I8PG46 A0A1S4FM51 A0A1I8PFV7 D1ZZH3 A0A1B0B3W2 A0A1A9XVI4 A0A0J7NL61 A0A194RFD0 A0A1B0CN23 A0A146LYG7 T1I6B9 A0A310SE16 F4W4C8
EMBL
RSAL01000133
RVE46333.1
NWSH01000476
PCG76131.1
ODYU01000049
SOQ34160.1
+ More
KQ459337 KPJ01397.1 KQ979608 KYN20501.1 KQ977085 KYN05872.1 KK107182 EZA56007.1 KQ981965 KYN31886.1 GL449033 EFN83440.1 KQ976717 KYM76777.1 KQ982685 KYQ52340.1 GL440062 EFN66327.1 GDHF01021593 GDHF01002876 JAI30721.1 JAI49438.1 KQ414663 KOC65257.1 QOIP01000003 RLU25079.1 KQ971338 EFA02370.1 JXJN01008092 LBMM01003731 KMQ93195.1 KQ460297 KPJ16164.1 AJWK01019673 AJWK01019674 AJWK01019675 AJWK01019676 AJWK01019677 AJWK01019678 AJWK01019679 GDHC01006953 JAQ11676.1 ACPB03001807 KQ760801 OAD58963.1 GL887513 EGI70941.1
KQ459337 KPJ01397.1 KQ979608 KYN20501.1 KQ977085 KYN05872.1 KK107182 EZA56007.1 KQ981965 KYN31886.1 GL449033 EFN83440.1 KQ976717 KYM76777.1 KQ982685 KYQ52340.1 GL440062 EFN66327.1 GDHF01021593 GDHF01002876 JAI30721.1 JAI49438.1 KQ414663 KOC65257.1 QOIP01000003 RLU25079.1 KQ971338 EFA02370.1 JXJN01008092 LBMM01003731 KMQ93195.1 KQ460297 KPJ16164.1 AJWK01019673 AJWK01019674 AJWK01019675 AJWK01019676 AJWK01019677 AJWK01019678 AJWK01019679 GDHC01006953 JAQ11676.1 ACPB03001807 KQ760801 OAD58963.1 GL887513 EGI70941.1
Proteomes
Interpro
IPR027331
CORO7
+ More
IPR036322 WD40_repeat_dom_sf
IPR019775 WD40_repeat_CS
IPR015505 Coronin
IPR001680 WD40_repeat
IPR017986 WD40_repeat_dom
IPR015048 DUF1899
IPR015943 WD40/YVTN_repeat-like_dom_sf
IPR024977 Apc4_WD40_dom
IPR005225 Small_GTP-bd_dom
IPR027417 P-loop_NTPase
IPR001806 Small_GTPase
IPR041820 Rab30
IPR011044 Quino_amine_DH_bsu
IPR011990 TPR-like_helical_dom_sf
IPR036322 WD40_repeat_dom_sf
IPR019775 WD40_repeat_CS
IPR015505 Coronin
IPR001680 WD40_repeat
IPR017986 WD40_repeat_dom
IPR015048 DUF1899
IPR015943 WD40/YVTN_repeat-like_dom_sf
IPR024977 Apc4_WD40_dom
IPR005225 Small_GTP-bd_dom
IPR027417 P-loop_NTPase
IPR001806 Small_GTPase
IPR041820 Rab30
IPR011044 Quino_amine_DH_bsu
IPR011990 TPR-like_helical_dom_sf
Gene 3D
CDD
ProteinModelPortal
A0A437B8C4
A0A2A4JVU7
A0A2H1UZY6
A0A194Q776
A0A195E5Y7
A0A151ILV8
+ More
A0A026WIY7 A0A195EUQ7 E2BLK3 A0A151HYK4 A0A151WWT7 E2AJP3 A0A1I8MS29 A0A0K8UVX9 A0A0L7R304 A0A1I8MS41 A0A3L8DYQ3 A0A1I8PG46 A0A1S4FM51 A0A1I8PFV7 D1ZZH3 A0A1B0B3W2 A0A1A9XVI4 A0A0J7NL61 A0A194RFD0 A0A1B0CN23 A0A146LYG7 T1I6B9 A0A310SE16 F4W4C8
A0A026WIY7 A0A195EUQ7 E2BLK3 A0A151HYK4 A0A151WWT7 E2AJP3 A0A1I8MS29 A0A0K8UVX9 A0A0L7R304 A0A1I8MS41 A0A3L8DYQ3 A0A1I8PG46 A0A1S4FM51 A0A1I8PFV7 D1ZZH3 A0A1B0B3W2 A0A1A9XVI4 A0A0J7NL61 A0A194RFD0 A0A1B0CN23 A0A146LYG7 T1I6B9 A0A310SE16 F4W4C8
PDB
2B4E
E-value=4.23687e-55,
Score=548
Ontologies
GO
PANTHER
Topology
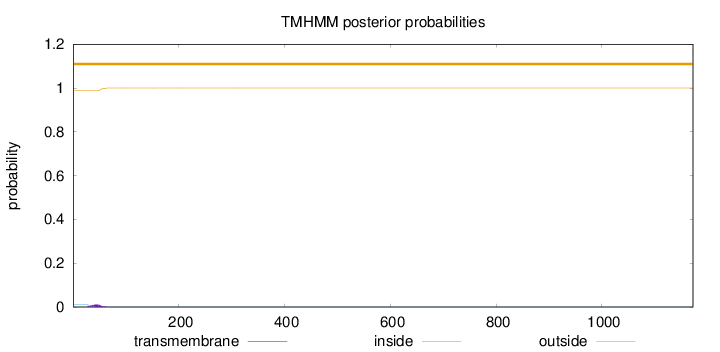
Length:
1172
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.23093
Exp number, first 60 AAs:
0.22377
Total prob of N-in:
0.01108
outside
1 - 1172
Population Genetic Test Statistics
Pi
273.570815
Theta
180.836825
Tajima's D
1.826553
CLR
0.220149
CSRT
0.854407279636018
Interpretation
Uncertain
