Gene
KWMTBOMO08408
Annotation
non-LTR_retrotransposon_R1Bmks_ORF2_protein_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 0.947
Sequence
CDS
ATGAGTGCCAAAGGCCGGAGGACCGGCCTGCATATCCCGGTTGCTTCTGGACTGTCGTCCTCGGCGCCTGTCACCCCGGTTGACCCAGTGGCTGGTGTCCCTAGCTTCCCCATTCCTGTTGCGTCGGGGGCTCCGACTGGACCCCTTGATGTAGCAGCGCAGGGGAGGCTGGAGCTGCTCGAGCGGGCAAACCGAGCGGTGCGCGGGATCATGTCGGTGGCGACGGCGGCATCTAAGCTCAATAAGTCGGAGGTCAATCTAATCTCTGAACTCGGTCGCGATATCCTGGCCGTAGTTGGGGCCCTCGGGATCCAGCTCTCTGATAAGGAGCTGGTGGTCGAAAGGCTCCGCTCGGCAGAGGCCTCTGCACGGCGTGACTCCGTGGCGCCTTCGATGGCTGCTGGTGCGGCGGCCGGGTCTGGGACTGGGCCTGCGACCTTCGCCACTGTCCTCAGGACGGGCCCTGGTGGGGTCCCGAGGTCCATTGGGGCCTCTCAGGGGCCTTCCTTGGCATTCTACCCGTCCGAGGGCAATGCGGAACTGAAGACAGCTGAGGACACAAAGAAAGAGGTAAAAAAGGCCATTGACCCTAAGTCAATGGCTATTGGAATACAGAGCGTAAGGAAGGTTGGGAATGCGGGGGTAGTGGTGCAGACCACGTCCCCCGCGGCCGCAGTCAAGCTTAGAAATGCTGCCCCGCCATCACTGAGAGTCACCGAACCCAGGCGCCGACAGCCCTTAGTAGCTGTCAATGGCGTGGAGGGCGACCCCTGCTTCGAGGAGGTAATCGAGTGCCTGGCTAGCCAGAACCTCGACCCGGAGGAGTGGCCCCTCACTAGGGTACGAGCGGAGCTCACGGGGGCGTTCAAAAAGGGGAGGCGACAATCCAACAACACTACTGTGGTGTTTAACGCCTCCCCTCGCATCAGGGACGCCCTCGTGAAGATTGGCAGAGTGTATGTGGGGTCGAGTATGGATATTAGGCCCCGACTTCGTATTGGCCAAATCAATCTGGGTGGTGCAGAGGATGCGACGAGGGAGCTACCCTCCATTGCACGGGATCTCGGCCTGGATATTGTTCTTGTACAGGAACAATATTCCATGGTCGGGTTCCTAGCCCAATGTGGAGCACACCCCAAGGCGGGTGTGTATATCCGCAATAGGGTGCTCCCCTGCGCGGTTCTGCACCACCTTAGCAGCACACATATAACGGTAGTGCACATTGGGGGGTGGGACTTATATATGGTGTCTGCGTACTTCCAGTATAGTGACCCTATTGACCCATACCTGCACCGGCTCGGGAATATTCTTGATCGGCTGCGGGGGGCTCGGGTCGTTATCTGCGCAGACACTAATGCCCACTCGCCATTGTGGCACTCGCTGCCCAGGCACTACGTCGGTCGGGGTCAGGAAGTGGCTGACCGCCGCGCCAAGATGGAGGATTTCATTGGGGCGAGGCGGTTGGTCGTCCATAACGCGGATGGCCACCTGCCGACCTTCAGTACGGCGAACGGAGAATCTTATGTCGATGTCACGCTGTCTACGCGGGGAGTACGCGTGTCTGAATGGCGTGTAACTAATGAATCATCGAGCGATCACCGGCTCATTGTGTTTGGGGTGGGGGGCGGTACAACAGGGGAGCGGGACGAGGACGAGGAGGCGCGGAGCGATTTGAGGCCGGGCGAGCCGTGCGCACTGCGTCGGTACCGGGACCGTGGGGTGGATTGGGACCTCTTCAGATCGCGTATCCACGAGCGAATGGGGAGTCTGGACCTCGAGGAACCTGTGGCTGCCCTTTGCGAAAAATTTACCGGGGTTATAACTCGCACAGCTGAAGAATGCTTAGGATCACTGAAAGCAGATAGAACTGACAGGGGTTATGAGTGGTGGACCCCAGTACTCGATAAGCTTAGGGTAGCCCAGGGTAGGGCCAGGCGTCGATGGCAAAAGGCCCGCCGAACGGGGGGTGAGGAAGAGGAGCAGTCTGGGAGAGTCTTCCGCGACCGCAGGCGCGAGTATCGAAGAGCGATGCATGACGCTGAGACCGCCTTTTACCGGGAGATCGCTGAAGGGGGAAACCGTGACCCGTGGGGACTAGCGTATCGGACGGCGAGTGGTAGGCGACGCGCACCAACTAATGTGGTTAACGGGGTGGAGTATGCGGGGCGGTGCTCGGATGATGTGAGTGGGGCCATGCGCACCTTGATGTGGGCGCTGTGTCCGGATGACTATATGTCTCGGGACACTCCGTACCATGCGCGGGTGCGTATCATGGCCGCGCTCCCCCCATCCGGGCGGGACGCAGACCCGCTGAGCAAAGACTCCCTTCGTGCCATAATTGGCTCACTGAAGAATACCGCACCGGGCATCGACGGTTTAACGGCGCGCATTATCAAAAAGGCACTTCCGGCTGCTGAGGCCGAGTTCGTGGCCGTATACGCACGGTGCGTTGTGGAGGGGACCTTCCCGCCGGTGTGGAAGGATGGCCGCCTACTTGTTCTGCCAAAGGGGAATGGCAGGCCCTTAACGGACCCTAAGGCGTATCGCCCGGTCACCTTGCTGCCGGTCCTGGGAAAGATCTTGGAGAAGGTATTATTGCAGTGTGCTCCTGGCCTCACCCATAGTATTAGTCCGCGCCAGCACGGGTTCTCTCCTGGACGCTCAACGGTGACGGCGCTGCGAACTCTGCTGGACGTGTCGCGCGCCTCGGAGCAGAGGTACGTAATGGCCATATTCTTGGACATCAGTGGAGCTTTCGATAACGCGTGGTGGCCCATGATAATGGTGAAGGCCAAGCGGAACTGTCCGCCCAACATCTATCGGATGCTGACGGACTATTTCCGCGGACGCCGTATTGCCGTTGTCGCGGGGGAATGTGCGGAATGGAAGGTGTCCACGATGGGCTGTCCGCAGGGCTCAGTGCTCGGGCCGACGCTCTGGAACGTTCTGATGGATGACCTGCTCGCCTTGCCGCAGGGGATAGAGGGAACAGAGATGGTCGCCTATGCCGATGACGTGACGGTACTGGTTAGGGATGACTCACGGGCGCAGCTTGAGAGGAGAGCGCACGCCGTGCTAGGACTCGCAGAGGGGTGGGCGAGCAGGAATAAGCTCGATTTTGCCCCGGCGAAGTCCCGATGCATAATGCTGAGGGGAAAGTTTCAGCGTCCCCCTATAGTCCGGTACGGCAGTCATGTCATTCGGTTCGAGAACCAGGTGACGGTGTTGGGCGTCGTCTTCGACGATTACCTCTCTTTCGCGCCGCATGCGGCGGCCATTGGCGAGAGGGCGAGCAGGTGCTTCGGCAAGATGTCTAGAGTTTCGGCTTCGGCTTGGGGGCTGCGATATAGGGCTTTGCGTGTCTTGTACATGGGCACTTATGTTACAACCCTTACCTATGCGGCGGCCGTATGGTATTTGCGGGCTGCTGTGCACGTCGTGCGCAGCGTGCTGCTTAGGACGCAGCGCCCGTCGTTGACGCTGCTAACGAAGGCCTACCGTTCGTGCAGCACGGCTGCTTTGCCGGTGTTGGCGGGCGTCCTGCCGGCGGACCTGGAGGTGACTCGTGCTGGACGGAGGATGCGGGAGTGCGAAGGATTGGCGCGGGAGTTGGCGGCGGAGAGACGACGACGGATCGACGGCGATGTCTTGGTAGTTTGGCAGAACAGGTGGGTGTCTGAGGGTAAGGGGAGGGAACTGTACAAGTTCTTTCCCGATGTTGCGGACAGGAAGAAGGCAACGTGGATGGAGCCGGACTATCAGACCTCGCAGATCCTCACGGGTCATGGGATCTTTAATAAGCGGTTGGCGGATATGCGACTGAGGGAGGGGCATGCTTGCGACTGCGGGGCGGTTGAGGAGGATAGGGACCATGTCCTGTGGGAGTGTCCTCTCTATGACGAAATCCGGGGCAGGATGCTCGATGGAATCTCGCGGTCTGAGGTGGGCCCAGTTTACCACGCGGACCTGGTCAGGGACGAGAAAAATTTTCGGCTCTTGCGCGAGTTCGCGCATACATGGCACACGGCGCGCACTGCGCGCGAATCACGAGGACTGCCTGGCGACGAAGAATGTGGGTGA
Protein
MSAKGRRTGLHIPVASGLSSSAPVTPVDPVAGVPSFPIPVASGAPTGPLDVAAQGRLELLERANRAVRGIMSVATAASKLNKSEVNLISELGRDILAVVGALGIQLSDKELVVERLRSAEASARRDSVAPSMAAGAAAGSGTGPATFATVLRTGPGGVPRSIGASQGPSLAFYPSEGNAELKTAEDTKKEVKKAIDPKSMAIGIQSVRKVGNAGVVVQTTSPAAAVKLRNAAPPSLRVTEPRRRQPLVAVNGVEGDPCFEEVIECLASQNLDPEEWPLTRVRAELTGAFKKGRRQSNNTTVVFNASPRIRDALVKIGRVYVGSSMDIRPRLRIGQINLGGAEDATRELPSIARDLGLDIVLVQEQYSMVGFLAQCGAHPKAGVYIRNRVLPCAVLHHLSSTHITVVHIGGWDLYMVSAYFQYSDPIDPYLHRLGNILDRLRGARVVICADTNAHSPLWHSLPRHYVGRGQEVADRRAKMEDFIGARRLVVHNADGHLPTFSTANGESYVDVTLSTRGVRVSEWRVTNESSSDHRLIVFGVGGGTTGERDEDEEARSDLRPGEPCALRRYRDRGVDWDLFRSRIHERMGSLDLEEPVAALCEKFTGVITRTAEECLGSLKADRTDRGYEWWTPVLDKLRVAQGRARRRWQKARRTGGEEEEQSGRVFRDRRREYRRAMHDAETAFYREIAEGGNRDPWGLAYRTASGRRRAPTNVVNGVEYAGRCSDDVSGAMRTLMWALCPDDYMSRDTPYHARVRIMAALPPSGRDADPLSKDSLRAIIGSLKNTAPGIDGLTARIIKKALPAAEAEFVAVYARCVVEGTFPPVWKDGRLLVLPKGNGRPLTDPKAYRPVTLLPVLGKILEKVLLQCAPGLTHSISPRQHGFSPGRSTVTALRTLLDVSRASEQRYVMAIFLDISGAFDNAWWPMIMVKAKRNCPPNIYRMLTDYFRGRRIAVVAGECAEWKVSTMGCPQGSVLGPTLWNVLMDDLLALPQGIEGTEMVAYADDVTVLVRDDSRAQLERRAHAVLGLAEGWASRNKLDFAPAKSRCIMLRGKFQRPPIVRYGSHVIRFENQVTVLGVVFDDYLSFAPHAAAIGERASRCFGKMSRVSASAWGLRYRALRVLYMGTYVTTLTYAAAVWYLRAAVHVVRSVLLRTQRPSLTLLTKAYRSCSTAALPVLAGVLPADLEVTRAGRRMRECEGLARELAAERRRRIDGDVLVVWQNRWVSEGKGRELYKFFPDVADRKKATWMEPDYQTSQILTGHGIFNKRLADMRLREGHACDCGAVEEDRDHVLWECPLYDEIRGRMLDGISRSEVGPVYHADLVRDEKNFRLLREFAHTWHTARTARESRGLPGDEECG
Summary
Uniprot
Q5NTZ0
Q7M4J4
V9H050
A0A1B6DRM7
A0A1B6E1N0
A0A023EYP7
+ More
A0A224XAL8 A0A0J7KTH2 K7JAI1 J9KMZ9 K7JMI9 J9LPJ1 X1XHQ0 A0A224X653 J9MA04 J9L798 J9LPX1 J9K5I1 J9LMF6 J9M8T8 J9KPX6 J9L0V3 J9M4Z2 J9LNF5 X1WL18 X1WUQ0 J9LPX0 J9KVB7 J9LCW5 J9KRH3 J9JY36 J9KPC7 J9K2L0 J9KPE5 J9KA38 A0A142LX43 Q868T0 X1WVB5 A0A2M4CS98 A0A0K8VPH1 A0A2S2NQQ6 A0A142LX37 A0A2M4BBV9 A0A2M4BC01
A0A224XAL8 A0A0J7KTH2 K7JAI1 J9KMZ9 K7JMI9 J9LPJ1 X1XHQ0 A0A224X653 J9MA04 J9L798 J9LPX1 J9K5I1 J9LMF6 J9M8T8 J9KPX6 J9L0V3 J9M4Z2 J9LNF5 X1WL18 X1WUQ0 J9LPX0 J9KVB7 J9LCW5 J9KRH3 J9JY36 J9KPC7 J9K2L0 J9KPE5 J9KA38 A0A142LX43 Q868T0 X1WVB5 A0A2M4CS98 A0A0K8VPH1 A0A2S2NQQ6 A0A142LX37 A0A2M4BBV9 A0A2M4BC01
EMBL
AB182560
BAD82946.1
M19755
AAC13649.1
GEDC01008950
JAS28348.1
+ More
GEDC01005462 JAS31836.1 GBBI01004973 JAC13739.1 GFTR01008452 JAW07974.1 LBMM01003366 KMQ93606.1 AAZX01006426 ABLF02039177 AAZX01008070 ABLF02012872 ABLF02012873 ABLF02012874 ABLF02012875 ABLF02042485 ABLF02010931 GFTR01008469 JAW07957.1 ABLF02008888 ABLF02016960 ABLF02032572 ABLF02007045 ABLF02012124 ABLF02027069 ABLF02027071 ABLF02016436 ABLF02007471 ABLF02007472 ABLF02019936 ABLF02057951 ABLF02012458 ABLF02012459 ABLF02010919 ABLF02010923 ABLF02006133 ABLF02010037 ABLF02010039 ABLF02066755 ABLF02012457 ABLF02020044 ABLF02022279 ABLF02010929 ABLF02020082 ABLF02020086 ABLF02020092 ABLF02019664 ABLF02034348 ABLF02004512 ABLF02004513 ABLF02046624 ABLF02049075 ABLF02059998 ABLF02065990 ABLF02008515 ABLF02013103 ABLF02013105 ABLF02013107 ABLF02061460 ABLF02004773 KU543682 AMS38369.1 AB090812 BAC57900.1 ABLF02007851 ABLF02016357 ABLF02064424 GGFL01004044 MBW68222.1 GDHF01029467 GDHF01011533 JAI22847.1 JAI40781.1 GGMR01006838 MBY19457.1 KU543679 AMS38363.1 GGFJ01001369 MBW50510.1 GGFJ01001370 MBW50511.1
GEDC01005462 JAS31836.1 GBBI01004973 JAC13739.1 GFTR01008452 JAW07974.1 LBMM01003366 KMQ93606.1 AAZX01006426 ABLF02039177 AAZX01008070 ABLF02012872 ABLF02012873 ABLF02012874 ABLF02012875 ABLF02042485 ABLF02010931 GFTR01008469 JAW07957.1 ABLF02008888 ABLF02016960 ABLF02032572 ABLF02007045 ABLF02012124 ABLF02027069 ABLF02027071 ABLF02016436 ABLF02007471 ABLF02007472 ABLF02019936 ABLF02057951 ABLF02012458 ABLF02012459 ABLF02010919 ABLF02010923 ABLF02006133 ABLF02010037 ABLF02010039 ABLF02066755 ABLF02012457 ABLF02020044 ABLF02022279 ABLF02010929 ABLF02020082 ABLF02020086 ABLF02020092 ABLF02019664 ABLF02034348 ABLF02004512 ABLF02004513 ABLF02046624 ABLF02049075 ABLF02059998 ABLF02065990 ABLF02008515 ABLF02013103 ABLF02013105 ABLF02013107 ABLF02061460 ABLF02004773 KU543682 AMS38369.1 AB090812 BAC57900.1 ABLF02007851 ABLF02016357 ABLF02064424 GGFL01004044 MBW68222.1 GDHF01029467 GDHF01011533 JAI22847.1 JAI40781.1 GGMR01006838 MBY19457.1 KU543679 AMS38363.1 GGFJ01001369 MBW50510.1 GGFJ01001370 MBW50511.1
Proteomes
Pfam
Interpro
IPR000477
RT_dom
+ More
IPR005135 Endo/exonuclease/phosphatase
IPR036691 Endo/exonu/phosph_ase_sf
IPR003959 ATPase_AAA_core
IPR027417 P-loop_NTPase
IPR003960 ATPase_AAA_CS
IPR031996 NVL2_nucleolin-bd
IPR041569 AAA_lid_3
IPR003593 AAA+_ATPase
IPR038100 NLV2_N_sf
IPR001878 Znf_CCHC
IPR036875 Znf_CCHC_sf
IPR005312 DUF1759
IPR008737 Peptidase_asp_put
IPR007889 HTH_Psq
IPR036397 RNaseH_sf
IPR012337 RNaseH-like_sf
IPR005135 Endo/exonuclease/phosphatase
IPR036691 Endo/exonu/phosph_ase_sf
IPR003959 ATPase_AAA_core
IPR027417 P-loop_NTPase
IPR003960 ATPase_AAA_CS
IPR031996 NVL2_nucleolin-bd
IPR041569 AAA_lid_3
IPR003593 AAA+_ATPase
IPR038100 NLV2_N_sf
IPR001878 Znf_CCHC
IPR036875 Znf_CCHC_sf
IPR005312 DUF1759
IPR008737 Peptidase_asp_put
IPR007889 HTH_Psq
IPR036397 RNaseH_sf
IPR012337 RNaseH-like_sf
Gene 3D
ProteinModelPortal
Q5NTZ0
Q7M4J4
V9H050
A0A1B6DRM7
A0A1B6E1N0
A0A023EYP7
+ More
A0A224XAL8 A0A0J7KTH2 K7JAI1 J9KMZ9 K7JMI9 J9LPJ1 X1XHQ0 A0A224X653 J9MA04 J9L798 J9LPX1 J9K5I1 J9LMF6 J9M8T8 J9KPX6 J9L0V3 J9M4Z2 J9LNF5 X1WL18 X1WUQ0 J9LPX0 J9KVB7 J9LCW5 J9KRH3 J9JY36 J9KPC7 J9K2L0 J9KPE5 J9KA38 A0A142LX43 Q868T0 X1WVB5 A0A2M4CS98 A0A0K8VPH1 A0A2S2NQQ6 A0A142LX37 A0A2M4BBV9 A0A2M4BC01
A0A224XAL8 A0A0J7KTH2 K7JAI1 J9KMZ9 K7JMI9 J9LPJ1 X1XHQ0 A0A224X653 J9MA04 J9L798 J9LPX1 J9K5I1 J9LMF6 J9M8T8 J9KPX6 J9L0V3 J9M4Z2 J9LNF5 X1WL18 X1WUQ0 J9LPX0 J9KVB7 J9LCW5 J9KRH3 J9JY36 J9KPC7 J9K2L0 J9KPE5 J9KA38 A0A142LX43 Q868T0 X1WVB5 A0A2M4CS98 A0A0K8VPH1 A0A2S2NQQ6 A0A142LX37 A0A2M4BBV9 A0A2M4BC01
PDB
2EI9
E-value=7.66701e-127,
Score=1167
Ontologies
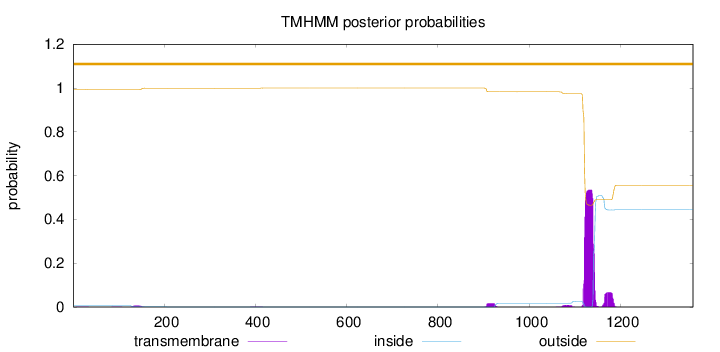
Topology
Length:
1359
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
13.70926
Exp number, first 60 AAs:
0.01322
Total prob of N-in:
0.00731
outside
1 - 1359
Population Genetic Test Statistics
Pi
0
Theta
0
Tajima's D
0
CLR
459.014761
CSRT
0
Interpretation
Uncertain
