Pre Gene Modal
BGIBMGA009279
Annotation
PREDICTED:_UHRF1-binding_protein_1-like_isoform_X1_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 2.978
Sequence
CDS
ATGGTGACTATAATAAAAAACCAGTTATTAAAACATCTATCCAGGTTCACAAAAAACTTATCACCGGAGCAAATCTCACTATCGGCACTTCGAGGTTCCGGTGAACTCCAAGACTTGACCCTCGATGAAGATTTACTTACTGATCTCCTAGAACTACCAGGATGGCTGCGGCTCACATCTGCTAAATGCAATCGAGCATCTTTCAGAATACAATGGACCAAACTGAAGACTGTGCCCATTGTACTGAATCTAGACGAAGTCCATATAGCTTTGGAGGTATGTTCAGAACCTCGGGTTATGAATCCGAGTGCGGCCGGTGCTTTACCTGTTCCAGGAAAATATAGTTATATACACAAGGTGATAGACGGAATCTCAGTGGCTGTGAATCATGTACAAATAGACTTCAACTGTGATGCGTTCACCAGTAGTGTTCAAATTTCAAGGGTGACCGTTGAGTCACGCACTCCAGACGGTCGGAAAGGGGATCTAAGACTGACTAGAATCAAATGTACTGATACGGGACAACTACTTATTTTTAAGGAGCTGGAATGGCAGAGCGCTCGCATAGAAGCCAAAGCCCACGGCGCGGCTTCGGCTAATTTACCTCCCTTGCGACTCTTGTTAGGGAATACACACTGTCGTATTGTTATAAAGAAGAGGCTATCAGATTGTGCGGTGATAGCATCCCGACTGGCCATCTGCCCGGAGCCCGTGGCGTGGGCGCTCACAGACGGGCAGCTCCGCGCCGCGCTGGCCTGCGCCGCCGCCCTCGCGCAGCCCGTGCGCCGGGCCACCGCCGCCGCCACCAGGGCTAAGGCGCTTAGGAAGATAGAAGAGCCCCGGGAGCAGATACAGAGCCGACCGAGCGGCGCGGCGGGCGAGCGCGACATCCTGGCGCGCGTGTTCGCTAAGCACGACGTGCGGGAGACCTCGTACCATCTGCTCGCGCCCAGGATCGACTTGCATCTATGCGACGACCCGGGATTGGGTCGTTCAGAAAAGCCGTCTCTATCGAAAGGTGGTGCTCTTCAAGTTACGCTGATCAGCATGCAAGCTGACTTATTCCCATACCACAAGGCGTCTAACGACAGGAGGCACTGGAAAGGCTACAGAGAATCAGCAACGCCACACAGTCAGTGGCTGTCTCAGGCGCTATCATCGTTCTGCACGAATTTGCTGGAAACACTCGATCCGAGGCCACTCTCTACTAACAATAAGAACCAGGTCGCGAGAGGTGAAGAGACCGCGTCGAACGGTACAAGTCAGAAGCCGGCGGCGGAGGCCCCGCAGCGCAGCGCCTCCAGCGTCCCGCCCGCTACGACTACGTCACAACCGTCACCAACAAGAACTCGTATCCTTCAACGACTAGGAAAACTGATGACGACATGTCTGGTGCTGAGGATAGACAATTTCACGGTATATAAGGTATCAACTGGTTCGAAAACTTACGAAGCCTTGAGGCCTCTGGTCAACGCAGAGAAGGCGACTCTACCCGGAGACGCCGGCCTCCTGCACGCTGAACTCACGTTCTTCTACTACCCCGGAGACGACTGCTTCCCAGTCCCGGCTCCGAAGCTGTACGTCCAGCTGAGTCCGGTGCGCGTGTCGCTGGACGTGAACAGCGCGGTGTGGCTGGGCGCGTTCCTGCCGCACGTGGCGGGCGCGCTCGCCCCGCCGCGCCGGGGGGCCGCGGACCCCGACACGCCCCCGCCGGCCCCCTACATGGACGTCAGGATGGAAGCCATTATGCCAAAGATAGTGCTGGAGGCGGGCTCCGAGCACGTGTCCCAGCAGCGGGACCGGCCCAAGGAGCTGCACGTGTGCACCGCGCGCGCCATGCTCACGAACGTGCGAGAATCGCCCAGAGCCAACACGGCCGGTACGAGAGCTGATTTAGCTGCCATACTGTCAGCCCTAAGGAGGGCGACTCCGCCCAGAGGAGAATTCCCAGCGTCGACTGAAGATCTGGATCCTATACACGAACAATTTGTTTTACATGCGGACAACCTGGACGACGTGGATCGTGGCACAGCCATAAGTCCGGAGCTGCTGTGGCGCGAGAACCGCTCGGTGTGGTGCGCGCGCGTGGAGCCCCTGTGGGCGGACTTCTGTGGCGCCAGGGCCACTAACTACAAGCCCGCGCCCCTGCTCGACGCCACGCCACTCACCGCCTGGTTATGCTTCAATGATGACCTTTCTCGCATATGGGTGGTGGGTCGGACGTGCGGTCTGGCCGGACTACAAGTGAACCACTACCAGCTGCTGTTCCTGCTGCGGCAGCTGGAACGCGTCTCCGAGATGATGGCGTGGCTGGCGCACGACGCGAGCAGACAGCCTGACGCAGAAGAGGGGTCAATCGTTGTAGGACTTGTGGTTCCAGCAGTGGAACTAACATTCGTGCTTCCATCGAACTGTCCCGGTCAGGAGTCTTCTCGAGATTTGGACAGTGTTCCTTTGGATTCGTCCAGCTTGCAAGATTTGAAAATGGGATCCGAAGCGACCATGGCGCCCTCTATTCAAGACAGAGACAGCGGCGTGCCCCCGGCGAGCAGTGTGGACGTGCTGTTAGCGCAGTCCCTGCCCGCAGAGGAGGTCCCTCCTCCCGCGAGTCCGGGACTTAACTTCGGAGGTTTCTCAACGATGCGACGCGGTTTCAATTCGCTAGTGACTTCAATAGACAGCGCCCTCACACGAGACGACACGCGCAGCGACGCCGCCTCCACCGCCAGCTCGGACAGCGACCGCTACGTGGTCGTGGGGCTGGCCGCGGAGTCGCCCGACGACGCAGACCTCGCCTTCAGAGAATTCGAACACGGTCGTGCGTCCAGCGCCGTGGAGGTGGCCGCCGAGGTGGTAGAACGGTCCTCGTCGCCGAGCGACCACTCCGTCACCAGCTCGTGTCGGAGACGTGACGTTATATCGACGTCGACGTGGCGCCTGAACAACATACACGTCGTTCACCAGAGCGCCAACGGCAGCTCTAGACTGCGGCTCGCCGCCGACGACCTGGTCTCCGACGAGTGCACCGCCATACCCTGGGACGAGTTCCAGAACAAATTTTCAATGCGCGCCCGTGCTTGGACCGAACCTGCTATAGACGAGGACAGCGAACTCAAACCCCGAGAAACACCGAACGTAGCAGCTAGATTGACCAGGACAGAACTATCGAGAACTTTAAACGAAAACGGCGAAGCAACCGGCCTGGCTCCATACGAAGAGCTACTGGAGGCTCGCGTGCGGGACCTCAGCCTCGCGCTGAACATGAGCACGGCGCTCGCTCTCTCGGAGTTCATAGAAGACGAGGTCATCGCACCGCCCATGCCTCTAGAAGTTTTAATAGAAAACGTGAAGGTACATCTCGTGGAAGACCGCCCGGTCCGTTCGATACTGTCGCCGCCGCCGCAGCCCCTGGACATCGACCTGACCACCCTCCGCGTCACGAGGGCCTCAGACGGCGTGCTGAGGCTCGGGCCGCCGCTCTCCACGCCCTCCACGGTGGCCTCGCCCAGCACTCCACAACCGAACCCCGAACTGGACGAAGCCAGGGCCGCAATAGACAGCTTGAACAAGGAAAACGAGGAGTTGAGGAAAAGACTGCTCACTCTGTCGAGGATCGCTGATGACAATAGGGAATTGCGAGCGAAAGTAGAAGAGGCCGCCGCGCTGCGTCAGTGCGTCCACAAGGCGCAGCAGGAGGCCGTCAGCTTGCTGGCCGACAAGCAGGAGCTGCTGGAGACCGTCCGCGCCCTGCAGGAGCAGGCGGGTTGTCGCGGCAAGAGGTAG
Protein
MVTIIKNQLLKHLSRFTKNLSPEQISLSALRGSGELQDLTLDEDLLTDLLELPGWLRLTSAKCNRASFRIQWTKLKTVPIVLNLDEVHIALEVCSEPRVMNPSAAGALPVPGKYSYIHKVIDGISVAVNHVQIDFNCDAFTSSVQISRVTVESRTPDGRKGDLRLTRIKCTDTGQLLIFKELEWQSARIEAKAHGAASANLPPLRLLLGNTHCRIVIKKRLSDCAVIASRLAICPEPVAWALTDGQLRAALACAAALAQPVRRATAAATRAKALRKIEEPREQIQSRPSGAAGERDILARVFAKHDVRETSYHLLAPRIDLHLCDDPGLGRSEKPSLSKGGALQVTLISMQADLFPYHKASNDRRHWKGYRESATPHSQWLSQALSSFCTNLLETLDPRPLSTNNKNQVARGEETASNGTSQKPAAEAPQRSASSVPPATTTSQPSPTRTRILQRLGKLMTTCLVLRIDNFTVYKVSTGSKTYEALRPLVNAEKATLPGDAGLLHAELTFFYYPGDDCFPVPAPKLYVQLSPVRVSLDVNSAVWLGAFLPHVAGALAPPRRGAADPDTPPPAPYMDVRMEAIMPKIVLEAGSEHVSQQRDRPKELHVCTARAMLTNVRESPRANTAGTRADLAAILSALRRATPPRGEFPASTEDLDPIHEQFVLHADNLDDVDRGTAISPELLWRENRSVWCARVEPLWADFCGARATNYKPAPLLDATPLTAWLCFNDDLSRIWVVGRTCGLAGLQVNHYQLLFLLRQLERVSEMMAWLAHDASRQPDAEEGSIVVGLVVPAVELTFVLPSNCPGQESSRDLDSVPLDSSSLQDLKMGSEATMAPSIQDRDSGVPPASSVDVLLAQSLPAEEVPPPASPGLNFGGFSTMRRGFNSLVTSIDSALTRDDTRSDAASTASSDSDRYVVVGLAAESPDDADLAFREFEHGRASSAVEVAAEVVERSSSPSDHSVTSSCRRRDVISTSTWRLNNIHVVHQSANGSSRLRLAADDLVSDECTAIPWDEFQNKFSMRARAWTEPAIDEDSELKPRETPNVAARLTRTELSRTLNENGEATGLAPYEELLEARVRDLSLALNMSTALALSEFIEDEVIAPPMPLEVLIENVKVHLVEDRPVRSILSPPPQPLDIDLTTLRVTRASDGVLRLGPPLSTPSTVASPSTPQPNPELDEARAAIDSLNKENEELRKRLLTLSRIADDNRELRAKVEEAAALRQCVHKAQQEAVSLLADKQELLETVRALQEQAGCRGKR
Summary
Uniprot
EMBL
Proteomes
PRIDE
Pfam
PF12624 Chorein_N
ProteinModelPortal
Ontologies
GO
PANTHER
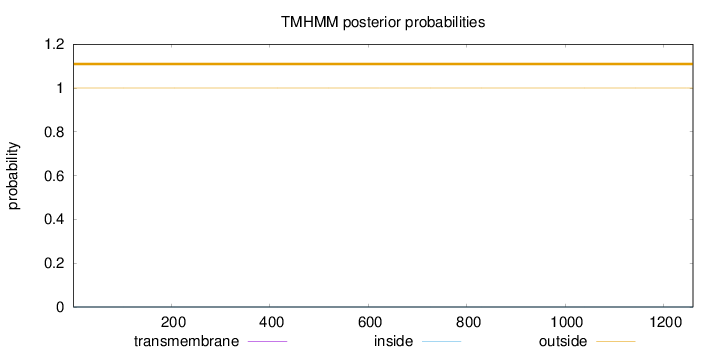
Topology
Length:
1260
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00257
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00008
outside
1 - 1260
Population Genetic Test Statistics
Pi
221.688719
Theta
161.492275
Tajima's D
0.2877
CLR
10.741553
CSRT
0.447377631118444
Interpretation
Uncertain
