Gene
KWMTBOMO07990
Pre Gene Modal
BGIBMGA001143
Annotation
PREDICTED:_protein_PF14_0175-like_isoform_X2_[Papilio_xuthus]
Location in the cell
Nuclear Reliability : 3.542
Sequence
CDS
ATGTGGAATTGGCACGTAAAAGTGAGGAAACTCAACGATTTACAAGGAGTGATTTTGTTGGTGTTCGCGACACTACCGCTGATAGCATCGACGAATATCGACTGCCTTGGAAAAGCTTTTCATTGTGTTAATTCGACTCATTTCATGATATGTGTGGATATCGGCGCAGGGTTTTCAAGTACGATTGATGATTTCGTTATACCGTGCCCTCCTACAACAGTTTGCCAACAAAATAATCGATTTGAGTGTGAATTTCCACCTATCACGACACCTGCACCGACGTTACCGACAGTTAGTTATGTTAAAGAAAGCATCCAATGGCTCGATCCCACAAATCCGACCCACGAAAATATTATTCGATCAACACAGCTCGACACAACGATAAACGAAGCTTACAATACCATCAGCACAACAACCATAGCAAATCTTGAAAACGACAACGAAATCACTACACGAGCGTTGGAAAAATATCCATTAGGATCAAGTGCTACGAAAGATTTTTTTTGGAATACTTCTCCAACGCTGGATGAAACAACTAGTCATTATAAAGAAAAACGGGAAAGCGTTTCAACAAATCCTCTAACGGACTCAACTACGGAAGCTATACCGGAAAAATCGACGCTTAGTGTACAAAAAGAAACAACGGATGATAGTTTCATCGCAACTACTAGCCTACAAAATGAAAACATTCCTGCCGTAATTTCCACGCCGCTTTCTAGTGTGAATGACCCAATTGCAACATCAAGTTTCCAAACAACAGAGAAAAATATAAAATTATCGACAAAAGCGGAGTCTGAATATGTAAGCTATAAGCCAACGTATTTATCAAACTTAGTTTCTACAATGGAACCTGCTACCGAATATTATACATCGAATGACAATACTCAAACACCCAGAACTCAATATTTACCGATTACAACTTCAACAGATAGCGTTTACACAACTGCACCTACCATTGTAACAACGATAGCACAATTTATAGAAACATCTGCAATCACAAGTAACGTTTTGAATGATAGCAACAAAATAAATAGTGAAAATTCGGATATAAAGTCAACGACCAAAGCTTTTCAAGTACAATCTACGCTTGATACAAATAAAGAAAATACTCATGATGAAATTACTACTCCTGAAGTTAGTCTAAGTGTAAACCAAAACATTCGACCTGCGGTCTCTGTCACTAATCATGTAATTCCAACTGATTCAAGTTATGTTTCGACTTTAGCTGCTGGTTCTACTAATGACGATAAATTGATTACCGGTATTTCTACCGAATCATTGTCTGTTACTGATAAAATTATATTGGAAGGCAATCATAAACAGTTTAATGACGTCATTCCAATTATTACATATACTACGACAAGTGACGCTTTTGCATCCAAACCTATGACTGAAATTGATTATTCTAGTATGACGGAATCAAGTTTAAAAATTAGAGCAGATGACGAAATCAACCCGATTGCAAATGAGGTCACTACTATAATGGATAGTATTTTAGTAGAAAAAACGAAATCTACAGCTTATGTAATGGACGATGTAATAAGTTCCACCACAACGGAAGATTCGGTTTCTCAAATCATAAAAAGTCCCCTTATATTTGATAAATTGAATTCGACCGTATCGAATGTAAAAAGTTACATAGATTTTGCCGATACAACTACTGATAACAGCAATCTAAATTCAGTAAAAATAAGTGGTTCATCCGAACCTATTGTGATAACCACACCCAAATTGTCTACATCCATCGATGCTACCGATATTAAAAATCTAATTTCAATTGACTTTGACACAACAGTATACACAACTACAGAAAACACCTTATTTAAGGAAAAGCAGAAAGATAAGCTCAGTAACAGAATTTCAGCAGCAATTGTTCAAGCCGACGCACCATCATTTGAAACTATGGATACAACATCGTCTGTTCCAACGGATACCAGTACAACAGACAAATTCAATCCGTATGTTACTATATTGGACGAATCAAAAGCTTTTTCAACAGTTTCATTAAACAATGTTCCCACTGCGATTCCTTCAAGTATAAAGACAATAAATACAAATACTTCTACAACCGTATATAATTATACGGAGTCTACGACATCAAATGTGTTAAAAGCTCAGAGTTTGAAAACAATTGAAAATGATTTGGAACAGGAATCATCCGTTATTAAAAATAATAACTTACAAGTGCCTCCTCAACCAATCAATCAGTCCTGGAATACGACAGCAACATTTGTAACAAATTCTACTACTGCAAGTGAATTGGATACGGCTGGCATTGTTGTGACTACAGAAATAGCCACATTAACTTCATCACTGAGTAATTCACTAAAAAATGAATCTGCATTTGGTACGGAAAATGATTATTACCAAAAAAATATTGCAACGTTTGGACTAATTAATGCTGCACAGAAAGTGACAGAACTAGAACAAAGGACAAACGGTTTAGATGATGAAATTCAATCTACAACACCAACTATATTCAATGAAATTGAAAAACCGGTAACTGACACAATTCATTTTAATGAAGCGACGCAATCGTATACCAAATTATATAAGAAAGAAAATAAAACTAAATCAGAAATTAATGATACACCGATTCCGTTTTCTCTGACCAATAACAGTTTACCCGCTGGAAAATCGACTTTAAATAGTACGAGTGTGGGTCAGAGTACCTTAGACCAGTTGTCTTCTGATTACCCTGATGACCTTAAACAAGTAAATAATGTAGGAAGTGGGTTGAAAAACATGAACAGTGAAGCAGTTATACAAGAGAGTCAGATTACAACTTCACAAATAGTGTTCGATGAGGTGTTGGGGAAAGAATTAGTATTAGGAGCAGAACTATCAACCTTAATTGGTATCGAAAAACCTAACTTAATGCGCACGGTAGAGGATACCGGTGAATTACAGATTCAGAATTCCCTCAAGACAATACCACTTAGGTCATCACCGACATCAAGTCTGAAAATCGAGTCACCTGGGTTACCGTTGGTAGGTACTGTACGGGATTCTGAAATTAACGGGAAAATCTTAGAAGTCGCTAAAAATGATCCCGCAGCAGAAATTAGTAACCGAAAAAATTCAAAAGATGGAACTCCAACACTAAAAATTTTTGTAGATTCACAGCCAAAAGTTCGATTATATTCTGAGCCAACTGTAAGCTATTCTAAGAGTGAAGATCTAACTTTTTCACACTACACTGTTACAGAACCTTCTCAGAAAGTACAAGACTTTTTGAATAGTGCGGCAGTTATGGATAATATTGGAAACGAAGGACACAAACATGTTTCACTGCAAAAGAGTGATAGTGAATACAATTCTGTGCAGATTTATAAACAACCAGAATCAGTCTCTACCACACCCAGCATTTTGGACGATAGAAATTTCGATCAAATTTTATTGAATGATGAAAAAGTGGCTTCAACAATCTATCCAGATTTAAAAAAGGCCACAAAACTAGTAAAGGTAGCTGAGATTCCTAGTAAAGGGACACGAACAATTGATCTAGAAACTATCACCTATCTAGAAAATAAAGAGAATATTGCAAAAAGTGAACCGACTCCTCCTTCAAAAACGAATTACGAAGCCACGAGCCTAAACCAAAATATAGATGCCGTAATTGAAAATAATTCTAAACTGAAGTCGACCATAAAAACTCGTGTGAATGTGGAATCTAACAATAATAATGATGGCAGAGTGAACACACAAAAATTGAGTGACACAGAACAGACAATAGCATCAAAGGCTACTAATTCTTATAATCTAAAAAAAATAGAGGCAACCGTAAATCGTGAAAATAACAAAGATAAAACCGTTTCAACGATACTCAACTTATCATTCAATTGTCAATACAAGAGTAGAGGAAGATACGGTGATAACAAAGATTGTAGAAAGTTCTATATTTGCATAGGAAGAAAACAACCTATTACTGGAAGGTGCCCCGAAAACACAGTATTCAGTGAAGTAAGAAAACAATGCACAAAAAACTTATCATATTGCGTGAGAAATAATCGATTCATGTGTGTGTCAAAAGGCAGGTACATCGACATTAAAAATAATGACCTTTACTATATTTGTGTTAGAAACGGAAATAGAACATTTGTGAGATATACATTTCAATGTCAAAACGGTTATTATTTGAATAAAATTTTAGTTAGATGTTTACCAATCACAAGTTCTGATAATGTCTCCAAAATAGTGGTTACCAAAGTAAAGAAAGATAAGGAAAAACTAGCTATTAAAAAATCGGCTAAAAGCGAAAGCTCTAGAAAAAATAGCGATCAAAGTATCAACCAAAATAATTCTGGGGAATCTGATAAAAACAGTGAATTGATTGAGTCTGTATGTGATGATGTTGGAAAATATTCTGATCCAGATGATTGCAGAATATATTACATTTGTTATAAAAATGGAAAGTCTGAAATGAAAATTAAGAAGAAAAAGTGCGAAAGCGATGAGGTTTTCCATAAGAAGCAAAAAAGATGTGTTGACGCTGAAAGTTACGAATGTTCTACTAATTAA
Protein
MWNWHVKVRKLNDLQGVILLVFATLPLIASTNIDCLGKAFHCVNSTHFMICVDIGAGFSSTIDDFVIPCPPTTVCQQNNRFECEFPPITTPAPTLPTVSYVKESIQWLDPTNPTHENIIRSTQLDTTINEAYNTISTTTIANLENDNEITTRALEKYPLGSSATKDFFWNTSPTLDETTSHYKEKRESVSTNPLTDSTTEAIPEKSTLSVQKETTDDSFIATTSLQNENIPAVISTPLSSVNDPIATSSFQTTEKNIKLSTKAESEYVSYKPTYLSNLVSTMEPATEYYTSNDNTQTPRTQYLPITTSTDSVYTTAPTIVTTIAQFIETSAITSNVLNDSNKINSENSDIKSTTKAFQVQSTLDTNKENTHDEITTPEVSLSVNQNIRPAVSVTNHVIPTDSSYVSTLAAGSTNDDKLITGISTESLSVTDKIILEGNHKQFNDVIPIITYTTTSDAFASKPMTEIDYSSMTESSLKIRADDEINPIANEVTTIMDSILVEKTKSTAYVMDDVISSTTTEDSVSQIIKSPLIFDKLNSTVSNVKSYIDFADTTTDNSNLNSVKISGSSEPIVITTPKLSTSIDATDIKNLISIDFDTTVYTTTENTLFKEKQKDKLSNRISAAIVQADAPSFETMDTTSSVPTDTSTTDKFNPYVTILDESKAFSTVSLNNVPTAIPSSIKTINTNTSTTVYNYTESTTSNVLKAQSLKTIENDLEQESSVIKNNNLQVPPQPINQSWNTTATFVTNSTTASELDTAGIVVTTEIATLTSSLSNSLKNESAFGTENDYYQKNIATFGLINAAQKVTELEQRTNGLDDEIQSTTPTIFNEIEKPVTDTIHFNEATQSYTKLYKKENKTKSEINDTPIPFSLTNNSLPAGKSTLNSTSVGQSTLDQLSSDYPDDLKQVNNVGSGLKNMNSEAVIQESQITTSQIVFDEVLGKELVLGAELSTLIGIEKPNLMRTVEDTGELQIQNSLKTIPLRSSPTSSLKIESPGLPLVGTVRDSEINGKILEVAKNDPAAEISNRKNSKDGTPTLKIFVDSQPKVRLYSEPTVSYSKSEDLTFSHYTVTEPSQKVQDFLNSAAVMDNIGNEGHKHVSLQKSDSEYNSVQIYKQPESVSTTPSILDDRNFDQILLNDEKVASTIYPDLKKATKLVKVAEIPSKGTRTIDLETITYLENKENIAKSEPTPPSKTNYEATSLNQNIDAVIENNSKLKSTIKTRVNVESNNNNDGRVNTQKLSDTEQTIASKATNSYNLKKIEATVNRENNKDKTVSTILNLSFNCQYKSRGRYGDNKDCRKFYICIGRKQPITGRCPENTVFSEVRKQCTKNLSYCVRNNRFMCVSKGRYIDIKNNDLYYICVRNGNRTFVRYTFQCQNGYYLNKILVRCLPITSSDNVSKIVVTKVKKDKEKLAIKKSAKSESSRKNSDQSINQNNSGESDKNSELIESVCDDVGKYSDPDDCRIYYICYKNGKSEMKIKKKKCESDEVFHKKQKRCVDAESYECSTN
Summary
Uniprot
ProteinModelPortal
Ontologies
GO
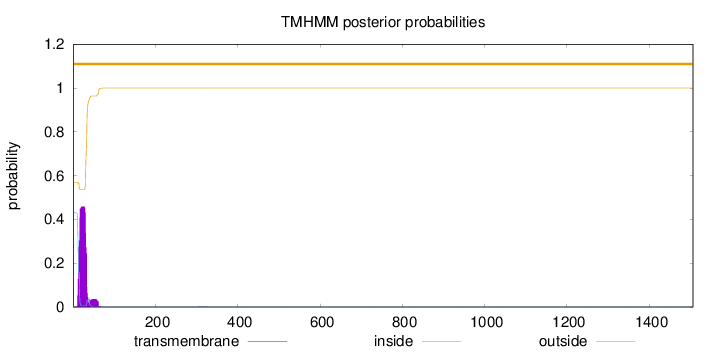
Topology
SignalP
Position: 1 - 30,
Likelihood: 0.716161
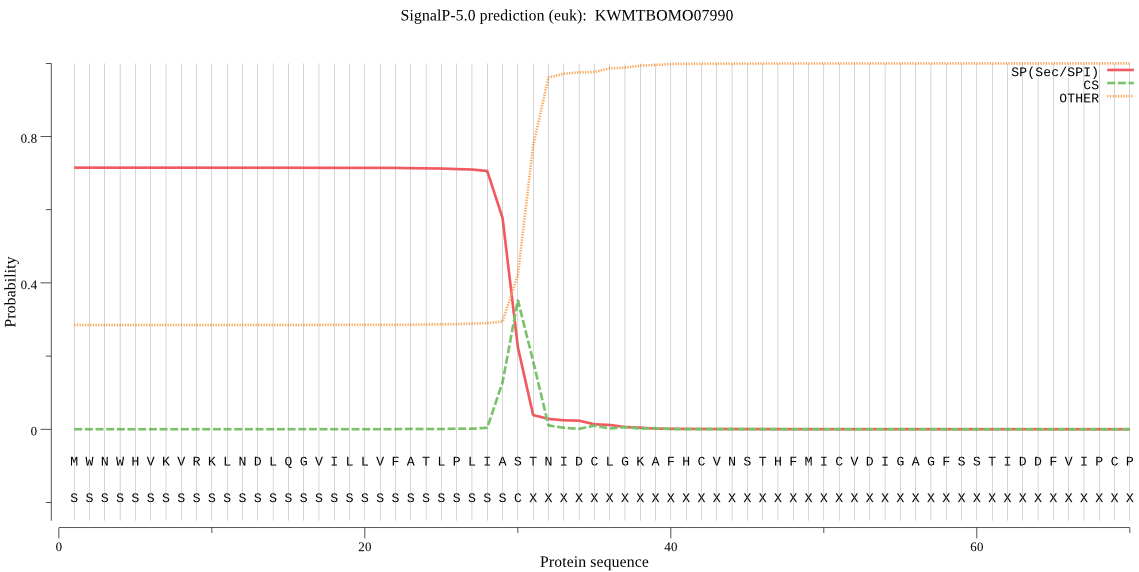
Length:
1506
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
9.73596
Exp number, first 60 AAs:
9.66246
Total prob of N-in:
0.43021
outside
1 - 1506
Population Genetic Test Statistics
Pi
145.740718
Theta
165.877284
Tajima's D
-0.421892
CLR
10.167676
CSRT
0.259237038148093
Interpretation
Uncertain
