Pre Gene Modal
BGIBMGA010628
Annotation
PREDICTED:_E3_ubiquitin-protein_ligase_HECTD1_isoform_X1_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 2.304
Sequence
CDS
ATGGCAGAAGTGGATCCAGAGACATTACTGGAGTGGCTGCTGACTGGGCAGGGTGATGAACGTGATATGCAACTCATTGCTCTTGAACAGCTGTGTATGCTTCTACTAATGTCTGATAATGTTGACAGGTGTTTTGAAAGCTGTCCACCAAGAACATTTCTTCCAGCTTTGTGCAAGATTTTTTTGGATGAATGTGCACCTGATAATGTTTTAGAAGTTACTGCAAGAGCTATCACATATTATCTGGACGTGTCTGCTGAGTGTACAAGGCGCATTGTAGCAATTGAGGGAGCTGTGAAGGCTATATGCAACAGACTGTTGACAGTTGACCCCAATAATCGGACAAGTAAAGATCTAGCAGAGCAATGTATAAAGGTCTTGGAACTTGTTTGCACTCGAGAAGCCGGTGCTGTATGGGAAGGTGGTGGTTTACCTGCTGTTTTGCATTTTATTACAAACCATGGTACCTCAGTGCATAAGGATACACTACATTCAGCCATGGCTGTGGTTTCCAGGGTGTGCGGTAAGATGGAGCCCGGTGACGCTCGCGTAGGTGACGCGGTGTCGTCGTTGTCAATGCTCCTGCGTCACAGCGACGCGCGGGTGGCGGACGCAGCGCTGCGCTGCTTCGCCTCGCTCGCCGACAGGTTTGCACGCGCCCATGCCGACCCGGCGCCGTTGGCTGAACACGGCCTAATTGAAGAATTAGTACGACGTTTGGGAAGCACAGAGAGTGGAGATGATAAATGTCTCACTTCAGCCGTATCCACTACAGTCAGTCTCCTTTCGACGCTATGTCGCGGATCGGCGCAGATCACCCATGATTTAGTTCGTTTGGAATTATGTTCAGCCATTGAAAAGGCAGTTCAAGCAGATGAGCGTTGGTGCTTAGAATGTATGCGATTGGTCGACTTGTTACTAGTACTGCTCTGTGAAGGAAGGCACGCCATAGCAACGGGTGCGAACCGTAATGTCGGTTCATCATCGGGCGCGCGGTCCACGGAGGCGAGTCGCGGCGGAGAGCGCTCGCACCGGCAGCTCATCGACTGCATCCGCGGGAAGGACACGGACGCGCTGCTGTCGGCCGTGTCCAGCGGCGCCGTGGATGTTAACTTCACCGACGACGTCGGCCAGACGCTGCTCAACTGGGCCGCCGCCTTCGGCACCAAGGAGATGGTCGAGTTCCTGTGTGAGAAAGGAGCGGACGTAAATCGAGGACAGCGTAGTTCATCCCTTCATTATGCGGCTTGTTTTGGTCGTCCCGCGATTGCCAAGGTACTGCTTCGGTATGGCGCCAATGCGGATTTGCGTGACGAGGACGGTAAAACCCCATTAGACAAAGCGAGAGAGCGACACGATCAAGGGCACAGGGAAGTGGCAGCAATATTGCAATGTCCCGGAGAGTGGTTGGTTGTCGGCAACAGCGAGTCCCCGTCTCCGTCGACTGATGATGACTTTCCAGAGACGGGCGACAAAGAAATGGCTGAGTTTTACCTAGAACGGCTGGTGCCGCTGTTCTGCGCGCGGTACGTGGGCGCGGGCGGCGGCGGCGTGCGGCGCGCCTGCCTGTCGCTGGTGCGCAAGATGGTGCACTACGCGCCGCCGCGCCTGCTGCGGGACGCGCACCCCGCCGCGCTGCTCACCAACCTCGTCGCCGCCGTGCTCGACAACCAGGATGACGACGATGGACATTTGACAGTTTTGGGCATATCCGAAGAGTTGATGGCCAAGGCCGCCGACGTGTACTTGGAACAGTTCGCTCGGCTCGGCGTCTTCAGCAAAGTCGAAGCACTCGCCATCACACCCATTCAGTACGACAGCGATGGCAGCTCGACTCCAGAGCTGAGCGGCGAGGACGCGTCGTGCTTGTCGAGCGGCGTCGCGTACTCGTGGGGCGAGTGGTCGCTGTGCCGCGGCCGCGACGCGCTGTACGCGTGGAGTGACGCCGCCGCGCTCGAGCTCAGCACCGGCAGCAACGGCTGGTTCCGCTTCCTACTCGACGGCAAGCTGGCCACCATGTACTCCAGCGGCAGTCCCGAGCACCAGACCGACAACACTGAAAATCGCGGAGAGTTCATTGAAAAACTACAAAAGGCAAAAGCTTCGGTGAGAAACTTTATCCCGCAGCCGATCCTGTCGAAACCCGGTCCCAATAAACTAGTTCTCGGGAATTGGTCCTTAACATGTGAAAAGGAAAAGGAGCTGCATATATACAATATAGATGGGCAGCAACAGACCACAATATTGAAAGAGGATTTGCCGGGATTTATTTTTGAATCAAATAGAGGAACCAAACATACATTTACTGCAGAAACATTTTTAGGTCCTGACATCGCCAGTGGCTGGGCTGACAGAAGGTCATTGCTTACCAATAATTCAACACCAACAAAACCTCGTTCTCGAATATCAGCAAAAACCGAAGCTCTTAAAGCACAAGTATGTGAGCGAGCGCGTGCGCTGTACTCGCGGCACCTCGCGAGCGCAGTGACGCGCCAGCCGCGCCCGCCCGTCGCCCGCCTGCGCGCGCTGCTCGCCAGGATGCAACGCATCGCCACCCAGCCTTCCAAAGATTGGCAACGAGAGCTCAACGAATCGCTGGATCAGCTGACCGAGTTGCTGTGTGGAGATGAGCATCTGTCTGCGTATGAGTTACAGTCGTCTGGGTTAGCGCCTGCTCTACTACAGGTCCTCTCCCCACAGGTTAACGACGGTCCGGGCCACCTGTCGGAGCGCAGCCGCGTTGTGAGCGCGTGGATGTGCCGGGCGTCGGGCGCGGCTGGCGCGGCGCTGGCCGAGCGGCTGGTGGCCGTGCTGGAGTCAGTGGAGCGGCTGCCGGTGCTCGCGCCGCACGACGCGCCGCCCGCCCCCGCCTCTGCCTTGCACCACCTCACTAAGCGCATACGCTTGCGCGTCGAACGTGAAAGTGATGAAATCAGCGAAGACAGCAATGCTAATAATAACAGCGGCCGTAACCTGAAAGTGGAAGCCCTCACTACCGTCCGTCAGCTAGAACGGTTCTTGGCCAAGTCCGTAGCGCGGCAGTGGTACGACATGGAGCGGTCCACCTTCCTCTTCGTGCAAAAAATAAAAACTGAAGCTCCTTTAAGCTTCACCTACGACCACGATTTCGATGAAAACGGCGTTCTGTACTTCATCGGAACCAATGCTGGCACTTGTGAGTGGGTGAACCCTGGCGCTCACGGGCTAGTCTACGTGTGGTCATCAGACGGTAAACAGTTACCGTATGGACGACCCGAAGATGTGCTGTCGAGATCTCCAGAACCACTCAACGTGCACACTAATGACGACAGACGCGCTTTCATTGCATTGGACTTAGGCGTTCATATTGTACCAACCGCATACACCTTACGTCACGCCCGTGGCTACGGGCAATCAGCATTGCGGAATTGGCTTTTTCAAATGTCAGTAGACGGCTTGACGTGGTGTACGTTGGTGGCACACACGGACGAGCAGGCGCTGCAGGAGCCGGGCAGCACGGCCACCTGGCGCCTCCGCACGGATTCATCCTATCGATATCTTCGCATACAGCAAAACGGAAAAAATGCGAGCGGTCAAAAATACTACCTTTCACTCTCCGGGCTAGAGATCTACGGAAAGGTGACAGGAGTGGTGGAGACGGCGCCACGACAAAGCGGTGCCCCGCATCAGACCACGGGCACGACGGCGAGCAGCGCATGTAACAACGCTACCGCGGCGAACAACACGAACAACGCCGGCATGGCGGGCGGCGGCGGCGGCGCGCGGGCGCGGCGGTGGTCGCGCGGCCGCGGCGTGTGTGCGGGCGCGCGCGTCTCCCGCGGCCCCGACTGGAAGTGGCGCGACCAGGACGGGCCGCACCCCGCACTCGGCACTCTCACTTCCGAACTGCACAACGGGTGGGTCGATGTCAGGTGGGACCACGGAGTTCGCAATTCGTATCGCATGGGTGCAGAGGGAAAGTTCGACTTGAAAGTTGTGAGCGGTGGTACTGTCATCGAAAGTTCAAAAGCCAGCCGGAAGAGTCACTCAACTCCCAGTTTGCCTGACGCCACTTCTGTCGATCAGGTATCAGTAGCGTCGACGGAACAGGCCTCGTCAGCGGACAATATATCGAGTGAAGAGATGGTCAGTAATATGTCAAGACCCCGTACGCACGCCACAGATCTCTCTGCCATTAATAATTCGACGCATCATATAAACTCTGTGTTTGACATAGATCTCGCGACAATAGTGGAGTCATTGACGTTGGGCGCCGAAAGTAACAATTGCATCACCGAGTTGGGGAATACATCGTTTACCAACATGGAAATGGGACCTACGAGCATTACGGATATCACCAAACCTTATCCCGCCAAAGAGCCGTTACCCGAATCCAGTGCACACGAGTGCGACGAAAATGAAGCCGGGGAAAGTCAATACGGTGATAATAAGAAGGAAAGTCAGTCCGGTTCGGGCACCATGAGCGCTAGCGAACCTGATTTGACGCAGCAGGGCACAGGACGCCTGTTGGAGTCGCTGGGCGTGGGCCGCGGCAACAGTGCAGGACGAGGCAGCAACGTGCCGCGCTCGAACCGTAACAATCATTCCTCTGGTCTCCTACCTAGTTTGGTGCGTTTAGCGTTGTCGAGCAACTTCCCCGGCGGGCTGCTGTCGGCGGCGCAGAGCTACCCCTCGCTGTCGTCCAACGCGCAGAACGCGCTCACGCTGTCGCTCACATCCACGTCCAGCGAAAGCGAACAGGTCTCATTAGAAGACTTTTTGGAGTCTTGTCGTGCTCCCGCGTTGTTGACAGAGTTGGAAGATGATGAAGACGGTGATGAGGCGCTGGACAGCGACAAAGAGAACGAACCCACTTACCAGGAGGTAGTCAGTAAACTTTTGGTATCTCGTAATTTGCTCTCTCTGATGGAGGAAGAAGCTTTAGAGGCTCTACGTGGCAGCTCGGGATCTGGACAAAACAATCGCTCGCGCCGACCCTGGGACGACGACTTCGTGCTCAAGCGACAGTTCTCAGCGCTCATACCGGCCTTCGATCCTCGCCCGGGAAGAACGAATCTCAACCAAACTGTCGATCTCGAAATACCTCTGAACGAGGAGTCCGAAGAGGAGGAGAGTTGGGAAGAAGTGCCAGAGAACGTCGGCGGCGGCGCGACTAGCGAGACCGGTCGCGCCCCGGCGCTGCGCCTGGTACTGAGCGCGGGCGGGGCCTCGCTGCCGCTGGCGCGCGGCTCCTGGACGCTGTACCGCGCCGTGCTGCTGCTGCACGCCCGCCTGCCGCACGCAGACCTCCATCGAGATACCACATACACTTTAACATACAAGGAGGTGGAGGGTTCAGAGGGCGCATTTGCTTCGAGTGACACTGAAGATGATGAACCTAATGATCCAGAAGGCGGTATAGTGGGTGCAGAGGGGAGCGAGGGCGGCATGGCCACGAGCTGCGTGCGCGTGCTGCGGCGCCTGCGAGCGGCCGCGCCCGAGCTGCCCGCCGAGCCCTTCCTCTCCACCAAGCTCACCAACAAGCTGCATCTCCAGCTGCAGGAGCCGCTCGCGCTCGCCGCCGCCGCCACTCCGCATTGGTGTCAGCAACTGATCGATTGGTGTCCATTTCTGTTTCCACTCGAAACAAGACAAATGTTTTTCGCATGCACCGCGTTTGGAACGTCCCGGACCATCGTCTGGCTGCAAGCGCAACGTGACCGTGCTTTGGACAGACAGAGAGCGACCAACACGGTGTCACCGCGCCGAGCGGAGCTGGAAGCGACTGAATTCCGCATGGGTCGCCTCAGACACGAGCGCGTTCGGATTCCGAGAGATCCCGACATGCTGCGTTCTGCTATTCAGGTGATGCGAGTGCACGCGAGTCGCAAGTCTGTATTAGAGGTGGAATTCGCGGGCGAGGAGGGCACTGGTCTCGGGCCCACGCTGGAGTTCTACGCGCTGGTGGCGGCCGAGCTGCAGCGCGCCGACCTCGCCCTGTGGCTGCACGACGCGCCGCTGCACGTCGATGACGACGCGCCGCTGCACCTCATGCAGCCCACAGAAAAGCCACCCGGTTACTACGTGAGCCGGCCCGGTGGCCTGTTTCCGGCTCCACTTCCGCAAGAATCCCCTATCTGTGATAAAGTGTGCAAATATTTCTGGTTTTTAGGAGTATTTTTAGCTAAGGTATTACAAGACGGCCGACTAGTTGACTTGCCTCTGTCAGAGCCGTTCTTACGTATAATGTGTGGTGAAGAGTTAACGAAAGAGAATTTACAAGAAATCGATCCCATTAGACATAGATTCTTAGAGAAGATGCTCGAAGCAGCCGAGGGGTACGACAAAATAATGCGTGATGAATCCTTGGACGAGAACGAGAAGCAGAAACGTGTCAGTGAGTTAAATGTAGACGGCGCCGCTTTTGAAGAATTGTCTTTAACTATGACGCACATCGCACCCAACGTCGACCCCGCTGTCGCCGTGCAACCGCTCTGTGATGGCGGAGAACATATCGAGGTGGGCGCGCACAACGCTCGTCTGTACGCGGAGTGGAGCGCGCGCTGGATGGTGTCGGCGGGCGTGCGGCGCCAGGTGGCGTGGTTCAAGCGCGGGTTCGCACGCGTGTTCCCGCCGCGACGCCTGCGGGCCTTCTCTCCTTCCGAGCTGCGCCTGCTGCTCTGCGGGGAACGCGGCCCCGTCTGGACCAGGGAACATCTGCTGCAGTATACCGAGCCTAAACTCGGATACACCAGAGATAGTCCGGGATTCCTTCGTCTGGTTGACGTTCTGGTTGAGATGTCGATCTGCGAGCGTAAAGCATTCCTGCAGTTCGCGACGGGATGCAGCAGCCTGCCGCCCGGCGGACTCGCCAACCTGCATCCTCGACTCACGGTCGTACGGAAGGTCGACGCCGGAGATGGATCGTACCCTTCAGTGAACACCTGCGTGCACTACCTGAAGTTGCCCGAGTATTCGTGTAAGGAAGTGCTACGCGAACGTTTGCTGGCCGCGACCAACGAGCGCGGCTTTCATTTAAATTAA
Protein
MAEVDPETLLEWLLTGQGDERDMQLIALEQLCMLLLMSDNVDRCFESCPPRTFLPALCKIFLDECAPDNVLEVTARAITYYLDVSAECTRRIVAIEGAVKAICNRLLTVDPNNRTSKDLAEQCIKVLELVCTREAGAVWEGGGLPAVLHFITNHGTSVHKDTLHSAMAVVSRVCGKMEPGDARVGDAVSSLSMLLRHSDARVADAALRCFASLADRFARAHADPAPLAEHGLIEELVRRLGSTESGDDKCLTSAVSTTVSLLSTLCRGSAQITHDLVRLELCSAIEKAVQADERWCLECMRLVDLLLVLLCEGRHAIATGANRNVGSSSGARSTEASRGGERSHRQLIDCIRGKDTDALLSAVSSGAVDVNFTDDVGQTLLNWAAAFGTKEMVEFLCEKGADVNRGQRSSSLHYAACFGRPAIAKVLLRYGANADLRDEDGKTPLDKARERHDQGHREVAAILQCPGEWLVVGNSESPSPSTDDDFPETGDKEMAEFYLERLVPLFCARYVGAGGGGVRRACLSLVRKMVHYAPPRLLRDAHPAALLTNLVAAVLDNQDDDDGHLTVLGISEELMAKAADVYLEQFARLGVFSKVEALAITPIQYDSDGSSTPELSGEDASCLSSGVAYSWGEWSLCRGRDALYAWSDAAALELSTGSNGWFRFLLDGKLATMYSSGSPEHQTDNTENRGEFIEKLQKAKASVRNFIPQPILSKPGPNKLVLGNWSLTCEKEKELHIYNIDGQQQTTILKEDLPGFIFESNRGTKHTFTAETFLGPDIASGWADRRSLLTNNSTPTKPRSRISAKTEALKAQVCERARALYSRHLASAVTRQPRPPVARLRALLARMQRIATQPSKDWQRELNESLDQLTELLCGDEHLSAYELQSSGLAPALLQVLSPQVNDGPGHLSERSRVVSAWMCRASGAAGAALAERLVAVLESVERLPVLAPHDAPPAPASALHHLTKRIRLRVERESDEISEDSNANNNSGRNLKVEALTTVRQLERFLAKSVARQWYDMERSTFLFVQKIKTEAPLSFTYDHDFDENGVLYFIGTNAGTCEWVNPGAHGLVYVWSSDGKQLPYGRPEDVLSRSPEPLNVHTNDDRRAFIALDLGVHIVPTAYTLRHARGYGQSALRNWLFQMSVDGLTWCTLVAHTDEQALQEPGSTATWRLRTDSSYRYLRIQQNGKNASGQKYYLSLSGLEIYGKVTGVVETAPRQSGAPHQTTGTTASSACNNATAANNTNNAGMAGGGGGARARRWSRGRGVCAGARVSRGPDWKWRDQDGPHPALGTLTSELHNGWVDVRWDHGVRNSYRMGAEGKFDLKVVSGGTVIESSKASRKSHSTPSLPDATSVDQVSVASTEQASSADNISSEEMVSNMSRPRTHATDLSAINNSTHHINSVFDIDLATIVESLTLGAESNNCITELGNTSFTNMEMGPTSITDITKPYPAKEPLPESSAHECDENEAGESQYGDNKKESQSGSGTMSASEPDLTQQGTGRLLESLGVGRGNSAGRGSNVPRSNRNNHSSGLLPSLVRLALSSNFPGGLLSAAQSYPSLSSNAQNALTLSLTSTSSESEQVSLEDFLESCRAPALLTELEDDEDGDEALDSDKENEPTYQEVVSKLLVSRNLLSLMEEEALEALRGSSGSGQNNRSRRPWDDDFVLKRQFSALIPAFDPRPGRTNLNQTVDLEIPLNEESEEEESWEEVPENVGGGATSETGRAPALRLVLSAGGASLPLARGSWTLYRAVLLLHARLPHADLHRDTTYTLTYKEVEGSEGAFASSDTEDDEPNDPEGGIVGAEGSEGGMATSCVRVLRRLRAAAPELPAEPFLSTKLTNKLHLQLQEPLALAAAATPHWCQQLIDWCPFLFPLETRQMFFACTAFGTSRTIVWLQAQRDRALDRQRATNTVSPRRAELEATEFRMGRLRHERVRIPRDPDMLRSAIQVMRVHASRKSVLEVEFAGEEGTGLGPTLEFYALVAAELQRADLALWLHDAPLHVDDDAPLHLMQPTEKPPGYYVSRPGGLFPAPLPQESPICDKVCKYFWFLGVFLAKVLQDGRLVDLPLSEPFLRIMCGEELTKENLQEIDPIRHRFLEKMLEAAEGYDKIMRDESLDENEKQKRVSELNVDGAAFEELSLTMTHIAPNVDPAVAVQPLCDGGEHIEVGAHNARLYAEWSARWMVSAGVRRQVAWFKRGFARVFPPRRLRAFSPSELRLLLCGERGPVWTREHLLQYTEPKLGYTRDSPGFLRLVDVLVEMSICERKAFLQFATGCSSLPPGGLANLHPRLTVVRKVDAGDGSYPSVNTCVHYLKLPEYSCKEVLRERLLAATNERGFHLN
Summary
Catalytic Activity
S-ubiquitinyl-[E2 ubiquitin-conjugating enzyme]-L-cysteine + [acceptor protein]-L-lysine = [E2 ubiquitin-conjugating enzyme]-L-cysteine + N(6)-ubiquitinyl-[acceptor protein]-L-lysine.
Uniprot
EMBL
Proteomes
PRIDE
Interpro
SUPFAM
Gene 3D
ProteinModelPortal
PDB
4Y07
E-value=1.03204e-21,
Score=262
Ontologies
GO
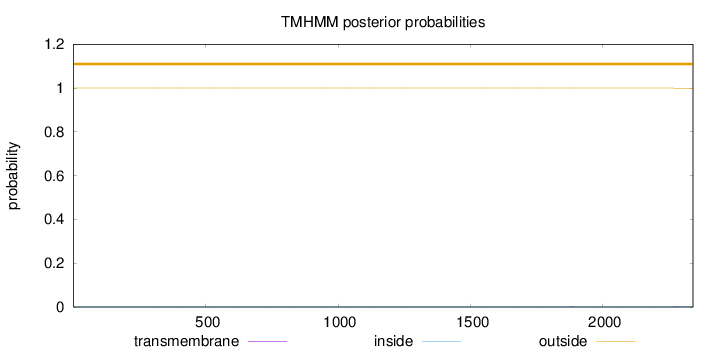
Topology
Length:
2340
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.01445
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00002
outside
1 - 2340
Population Genetic Test Statistics
Pi
17.42374
Theta
17.010542
Tajima's D
-0.979552
CLR
0.654885
CSRT
0.138543072846358
Interpretation
Uncertain
