Gene
KWMTBOMO07122
Pre Gene Modal
BGIBMGA010542
Annotation
PREDICTED:_cadherin-86C_[Amyelois_transitella]
Full name
Cadherin-86C
Location in the cell
Nuclear Reliability : 3.888
Sequence
CDS
ATGACGTTCGCTTTAGCACTGGTAGTGGTGTTCGCTTGGAGTGTCCATGCTGGCGAGCCTGTTTTCGATCCAAGCACTCTCATGCGGCTAGTGCTGGTACCAGCAGACGCGGCCGTCGGCTCAGTCATTTACCGCGTCAGGGCCTCCGATCCTGATTTTGATTATCCATTGCATTTCGAGCTCATTGGTCAAATGGGTCGCTTAGACATCGGCATCGAGACACTCCCTTGCACACGTTACAACTCCGTGTGCCAAGCCAACGTGATCCTCCTCCGGAGATTGGAGCCAGGACGCTACGTGGACTTCAGGTTGTCGGTCAGAAATACCAGAGGACGAAGCAATCGCATCGCCTGTTCCATAACCGGCACTAATGCGACAACACCAAGGGACACGATTTTCCCTCATCAACCCAGCATAGTGCTAGTACCTGAGGATGCGAAGCGTGGTACAGAACTCGAGATTGTTATTGCAAGGAAGAACCCCCTGTCACCAAAACCTTTGGAATTGGAGCTCTGGGGTTCGCCTTTATTCGCCATACGCCAACGCAGAGTTTCAACAGAAAACACCGAGGGAACGATATTTCTGATTGGACCGCTCGACTTCGAAGCGCAATCGATGTACCATTTGACACTCCTGGCCGTGGACCCATACATCGAAGTGGGGAAGGATACGCGGAATATTGCCGGCCTAGAAGTAGTCGTCGTAGTTCAAGACGTACAAGATATGCCGCCAGTATTTACTTCAGCACCTCCAATAACACATTTACCCAAACAAGTTGGTCCGGGTGATATGATAGTGAAAGTTCGAGCTGAAGACGGAGACAAGGGCGCACCTAGGCAGATCAGATACGGCTTAGTGTCTGAAGGGAACCCATTTACGCCATTCTTTAACATCAATGAAACTTCAGGCGAAGTGACTCTTGAACGCCCAATTGAGGAGATAGCGGCGATTTCTCATGCCGGTGCACCAATCTTATTAACAGTGGTCGCCGAAGAAGTAAGGCTGTCTCGAGAGGAACCCGAAGCGATGTCTTCCACTGTACAGCTTGCCTTCATTCTACCTGAACGAGATAATTCTCCTCCGTACTTTGAAAATCAATTTTATATAACTTACCTGGATGAGAACGCACCCCAGGGAACGGCACTTGTATTCAACGACCCCTACATTCCGCAAGTTAACGACAACGATGCCGGTAAGAATGGTGTCTTCGCACTATCTCTCGTCGGCAATAATGGGACCTTCGAAATATCACCGACCGTTGCAGAGAGACACGCGCAATTCCTCATCAAAGTACGAGACAATACAATGCTGGACTATGAAGCACGGAAGTCTGTCATATTTCAGATCACGGCTCAAGAATTGGGTCCAGCTACAAATTTATCGGCGACGGCCAATGTAACGGTTTACTTAAATGACGTAAACGATAATCCGCCCGTATTCTTGGCACAATCTTACGACGTGGAACTGCCTGAGAATGTTACTGCGGGAACTAGAGTCGTCCAAGTAGCGGCAGACGATGTAGACACGGGAGCTTTTGGAAAGATCCAATTCACTGCCATATTAGGGTACTTGAACACGTCGCTACATTTGGACCCTTTGTCTGGGTTGATCACCGTTGCGACCAATAATCATGGCTTCGATAGAGAAGCAATGCCAGATTTGCATTTTTTAGTAGAGGCTAGAGACAATGACGGAGTAGGTTTAAGAGTTACTGTGCCATTAATTATTAAGCTATTAGATGTAAACGATAACCCACCAGAATTCGAAAGATCGCTGTACGAGTTTGTCTTATCTCCGACTTTGAACAACTTTACGTCTCAAGCGTTCGTCAAGGCTATAGATAAAGACGCTGAGCCACCAAATAATGTAGTAAGATACGAAATCATTAATGGAAACCTCAACGGTCAGTTTGCTGTCAATGAAGAAACCGGTGAACTGTACTTACTGCAAAAACTAAAAAGAACAAAGAAACAAAATGTAAATAGAAGAAGACGTCAAGCAGACTCTCAACAGGAGAGCGACGTTTACGTTCTGAATGTGCGAGCTTACGACCTCGGAGTTCCGAGATTATTCTCTTCGACTTTGGTGAAAATCTATCCTCCGGAAAGCAAAACAAGGACAATGTCATTTATAGTGCCCGGGGCTGATCCCGATAGAAAAAAATTAGAAGAGGTTCTCAGTACTCTGTCCGGAGGAAAAGTCACGATAATCGATATCAAACCATATACAGGAGGCGATGGTGCTGCGACAGATTTAAGCGGCCGAGAATCTCAAGAGAAAAGTGAAGTGGTGGCCATAGTACATACAACCGGAAGTACTGCAATCAATGTCGCAAAACTCCAAGAGCAGTTAGCAAAAAATATGACAATATACACAACTGGCACTAGTTCTAGTAACGGTATTACCAATACAGGAAGTAATAATGAAAACGGTCAAGCATCCGATGATAGTGCAGATTCGAGTATATACAAAGCAGAGAGCCGCCTACTTTTCTGGCTCTTGATACTTTTAGCTATACTAGTAGCTCTGGTACTATTACTATTAATATGCTGCTGCATTTGTGAAGGATGCCCACTTTATATGCCTCCTAGCACAGCTTTGTCACAGTTTATTAGGAAAAGAGTGATACGTGTCAACTCCACAGAAGACGACGTGCGTTTAGTGGTCCGGGACAAGGGACTTGGGAGGGAAAACAAGAACCAAAACATAGAGAATAAATCAATTCAAGCAACAGAATGGAGAAAGAGGGAAGCGTGGAGTGCAGAACAAGCAGACTTGAGGACTAAACCAACACAATGGAAATTCAATAAAAGAAATTATCGTGCAAAAGGACCGTCTAAGCCGTCTTCGACTCCTGGTGGTGATATACGTCAAGAATTTGTTCACGCTGCAGCTGACAATGATTACAAATACGACGGACAGCAATCGTTTCGTATGAGAGAGGGACCAAACATTATCTACACAAAAGAGATGCAGATCGAACAAGCTTTCACAAATAAACACAAAGAGTATATAGATGATCTAGAAAATGGCTACGATAGAATTGCTACTTTACATCACAACAGAAGGGATCAAGATAACGATTCAATGCGTAGGCATGAAATAGATAGAGGTTCTGAAGTCGACGTTTATCTTAAAGATGGTGAAGAAAGAGAAAAAAATGAAAAACAAAAGCAAAGTTTTCAAGACAAAGCACATGCTCAATCCTCAATGGGTCGAGATCAATATTTTATAAAAGAAGGTAACACTGAAATTCTTCGTTTAGTGACTAGAGGTAAAAATGAAGAAGAAACATATGTTAATTTACCAGGTCATCAACAAAGACCGGTTACGTTAATACCTCACACTCAATATGTTGTGGTAGATAGTGGTAAAAATTTACTATTAGAAAGATTCATTAGAGAACAAGGCGAGGAAGCAAAAAGCATGAGAGAAAGAATGGAAAAGGTAACGGATTTAGATAATGTATCTATGGGAAGAGATGCCAAAAGTATCGGTCATGTTTCGGGAGCAGCTGAGGTTACTCATCACTTTCATGACTATTCAAATATACCTCCTGATGTCCCTGGCGCGGTCCCAAAAGATAATTATTTCCAGTCAGCTCTACTTCAAATGCAAAACAAATCAACAATTCATCAAGAGCTCTTAGAGTCATCGCTTCGAAAGCAAAATGAACTATTACATCAAATTTTAATCGAACGCGAAAGAATTTTACAGAATCATGAAACCGCTTCCCAAGTTGAAAATAAATTAGAAACTCAGAGCTTACCGGGCCACTCCGTAATGGCAACCCAAACTGAATGTCATATTGGAACGCAAACTGAACCACAACTTCTACAATCAACCAGGCGAAAAGCTAGAAGTGACAACGATTCCTACAGTGAAGATGAGTCACAGATAGCATTACAAGATGATCCTAAAAGTATAGCTTGGGTTAAAAGAAAAAAACCTAAAAAAAAGCTACGACATAAAGACCCAAGACGAAGTATACGAATCTATGATTTAAGGAGAAAAATTAAAACGCCGATTTACGAAGAAAGTGAAATATCTCCGTCATTAGAAAGTGAGAAATTCGTTAAAATAAGTAAAACTAATGAAAGAGAAGAACACATTAAAAATTACGGCGACGTTACCAAAAGCTTTATAACAACCTCGAAAAATGAAACAGTTTGTTCTACACAAATCAAAATCTCTGATATTGATAAAAAACCGAATTTAAGAAAAGAAGTTTTAATGGAAATTTCAGACTCGTTGGATGAGAAAATCGATTCGGATTTAAGCGAAAAACGTCTGCGATTGCAAAGACAGGCAGCGCAGCATGAAGATGATACTGGTAGTTCAAAGCTCAAGCTTTCACTCAGTCCCGAGGAAAACAATAAAAGTAGAAGCAGTTCTGCCTCTAAAGATGAAAGAAACAAAGTTTTTTCAAGACAAGGTTCATCGACCGAAGCTCGCGAAGAAGCAGAGCTCTCGGCAAGAATTAAAACACCAGAACTTGGTGAATCGTCGTCACAGAGAAAAACTACAAACAGCAATGAGTCTGGTATAAATGACAAAAAGAAAGCAGTGGAAGAAACAAGTAAAACATCCGACAGCAAAACTTCACAAAAAAGTTTACCTCGCTATATGCAATGGTACGGGAAAAAGTCCAGCGCCACATCCAAAGCCACTGCCCCTGAAAAAGTAATACCGAACAAACCAAAAAGAATATCGAAAATTAAGACTGACCAAGATGAAAAAGATCGTTCCGGTAGGTACGGAAAAATTTTAAGCAAAGAAACCCACAGTGACAACGCAGAGCTAAAAAAAAACTCCAAAGGAAAAGAAAGTGAATTCATTCATCCGCGAATCTTAAAAGAAGGTAAGGTGACTCCTGTGCCTGAAGGTCCGCTTCCAGATGCGCACCCACTCTTACAACATTCCGAACACAGATATGAACGTCAATACGAAAACCAGAATCCACTGTGTCACGTTCAACAAACACACATTCCAAAATACTTCGGACAACACAACGTTCCAATATTACCTCCAAGACAATCTGTAGAACAGCCGATATACGTGAATCAAGACGACGTCAAAACAAAGGTGATTAACCAAGACATTGCAGAAAGTGCGTTAACTCACAGTATTTCAATATCTACGAACTATGACGAAGATCGAAAAATTTCTTCCGAAGTACATGTATCTAAAGTTAACATTGGAGGAGATTTGGATCTCCAGCCAAGAAATATTACTGCCTTGGACGACAATGACTCTGGGATCGCAATGAACACATTAGTTCAACACGCTGGTAATTTCAAAAGACTACCCATCACTGAGAAAAAAAGCGTTTTTACTATAGCCTATGACGATGTTCAAACCAACAATAAACAACTAAGACCAGATAGCAGCTCCACGTCTTACTGA
Protein
MTFALALVVVFAWSVHAGEPVFDPSTLMRLVLVPADAAVGSVIYRVRASDPDFDYPLHFELIGQMGRLDIGIETLPCTRYNSVCQANVILLRRLEPGRYVDFRLSVRNTRGRSNRIACSITGTNATTPRDTIFPHQPSIVLVPEDAKRGTELEIVIARKNPLSPKPLELELWGSPLFAIRQRRVSTENTEGTIFLIGPLDFEAQSMYHLTLLAVDPYIEVGKDTRNIAGLEVVVVVQDVQDMPPVFTSAPPITHLPKQVGPGDMIVKVRAEDGDKGAPRQIRYGLVSEGNPFTPFFNINETSGEVTLERPIEEIAAISHAGAPILLTVVAEEVRLSREEPEAMSSTVQLAFILPERDNSPPYFENQFYITYLDENAPQGTALVFNDPYIPQVNDNDAGKNGVFALSLVGNNGTFEISPTVAERHAQFLIKVRDNTMLDYEARKSVIFQITAQELGPATNLSATANVTVYLNDVNDNPPVFLAQSYDVELPENVTAGTRVVQVAADDVDTGAFGKIQFTAILGYLNTSLHLDPLSGLITVATNNHGFDREAMPDLHFLVEARDNDGVGLRVTVPLIIKLLDVNDNPPEFERSLYEFVLSPTLNNFTSQAFVKAIDKDAEPPNNVVRYEIINGNLNGQFAVNEETGELYLLQKLKRTKKQNVNRRRRQADSQQESDVYVLNVRAYDLGVPRLFSSTLVKIYPPESKTRTMSFIVPGADPDRKKLEEVLSTLSGGKVTIIDIKPYTGGDGAATDLSGRESQEKSEVVAIVHTTGSTAINVAKLQEQLAKNMTIYTTGTSSSNGITNTGSNNENGQASDDSADSSIYKAESRLLFWLLILLAILVALVLLLLICCCICEGCPLYMPPSTALSQFIRKRVIRVNSTEDDVRLVVRDKGLGRENKNQNIENKSIQATEWRKREAWSAEQADLRTKPTQWKFNKRNYRAKGPSKPSSTPGGDIRQEFVHAAADNDYKYDGQQSFRMREGPNIIYTKEMQIEQAFTNKHKEYIDDLENGYDRIATLHHNRRDQDNDSMRRHEIDRGSEVDVYLKDGEEREKNEKQKQSFQDKAHAQSSMGRDQYFIKEGNTEILRLVTRGKNEEETYVNLPGHQQRPVTLIPHTQYVVVDSGKNLLLERFIREQGEEAKSMRERMEKVTDLDNVSMGRDAKSIGHVSGAAEVTHHFHDYSNIPPDVPGAVPKDNYFQSALLQMQNKSTIHQELLESSLRKQNELLHQILIERERILQNHETASQVENKLETQSLPGHSVMATQTECHIGTQTEPQLLQSTRRKARSDNDSYSEDESQIALQDDPKSIAWVKRKKPKKKLRHKDPRRSIRIYDLRRKIKTPIYEESEISPSLESEKFVKISKTNEREEHIKNYGDVTKSFITTSKNETVCSTQIKISDIDKKPNLRKEVLMEISDSLDEKIDSDLSEKRLRLQRQAAQHEDDTGSSKLKLSLSPEENNKSRSSSASKDERNKVFSRQGSSTEAREEAELSARIKTPELGESSSQRKTTNSNESGINDKKKAVEETSKTSDSKTSQKSLPRYMQWYGKKSSATSKATAPEKVIPNKPKRISKIKTDQDEKDRSGRYGKILSKETHSDNAELKKNSKGKESEFIHPRILKEGKVTPVPEGPLPDAHPLLQHSEHRYERQYENQNPLCHVQQTHIPKYFGQHNVPILPPRQSVEQPIYVNQDDVKTKVINQDIAESALTHSISISTNYDEDRKISSEVHVSKVNIGGDLDLQPRNITALDDNDSGIAMNTLVQHAGNFKRLPITEKKSVFTIAYDDVQTNNKQLRPDSSSTSY
Summary
Description
Cadherins are calcium-dependent cell adhesion proteins. They preferentially interact with themselves in a homophilic manner in connecting cells (By similarity).
Keywords
Calcium
Cell adhesion
Cell membrane
Complete proteome
Glycoprotein
Membrane
Metal-binding
Reference proteome
Repeat
Signal
Transmembrane
Transmembrane helix
Feature
chain Cadherin-86C
Uniprot
A0A194R5E9
A0A194PP17
A0A212FPL9
A0A2A4JWD7
W8AQ69
A0A0R1E2B6
+ More
A0A0R1E3R0 A0A1I8N8Q2 A0A1I8N8Q1 B4M5I7 A0A0M5J0H2 A0A0Q9W9T1 A0A1W4VG84 A0A1W4VFX9 A0A0Q9W0H3 Q9VGW1 A0A0B4K655 A0A1J1HIK9 A0A0B4K6E3 A0A0A1WED2 B4NJY8 A0A0P8YDR5 A0A0A1WGF4 A0A1I8NT94 A0A1I8NT98 A0A1I8NT99 B4KC93 A0A0P8ZY96 A0A1I8NT97 A0A336M3Y0 A0A034VM16 A0A182MS56 A0A3B0KAT2 A0A182W532 A0A0R3NHT4 I5AP47 A0A1B0CI24 B5DVI5 A0A182Y535 A0A0B4K720 A0A1A9UX43 A0A2J7QNR1 A0A1B0FQS3 A0A158NZ57 A0A195CVZ1 A0A195AZA3 A0A151IT89 A0A195F6C9 A0A1I8NTA2 A0A2P8YIP2 K7IYP2 E2A653
A0A0R1E3R0 A0A1I8N8Q2 A0A1I8N8Q1 B4M5I7 A0A0M5J0H2 A0A0Q9W9T1 A0A1W4VG84 A0A1W4VFX9 A0A0Q9W0H3 Q9VGW1 A0A0B4K655 A0A1J1HIK9 A0A0B4K6E3 A0A0A1WED2 B4NJY8 A0A0P8YDR5 A0A0A1WGF4 A0A1I8NT94 A0A1I8NT98 A0A1I8NT99 B4KC93 A0A0P8ZY96 A0A1I8NT97 A0A336M3Y0 A0A034VM16 A0A182MS56 A0A3B0KAT2 A0A182W532 A0A0R3NHT4 I5AP47 A0A1B0CI24 B5DVI5 A0A182Y535 A0A0B4K720 A0A1A9UX43 A0A2J7QNR1 A0A1B0FQS3 A0A158NZ57 A0A195CVZ1 A0A195AZA3 A0A151IT89 A0A195F6C9 A0A1I8NTA2 A0A2P8YIP2 K7IYP2 E2A653
Pubmed
EMBL
KQ460883
KPJ11091.1
KQ459603
KPI92870.1
AGBW02002231
OWR55650.1
+ More
NWSH01000479 PCG76096.1 GAMC01019927 JAB86628.1 CM000160 KRK03404.1 KRK03405.1 KRK03406.1 CH940652 EDW58913.2 CP012526 ALC47706.1 KRF78592.1 KRF78593.1 KRF78595.1 EU707853 AE014297 AY113374 AFH06349.1 CVRI01000006 CRK87888.1 AFH06351.1 GBXI01017492 JAC96799.1 CH964272 EDW83990.2 CH902617 KPU79643.1 GBXI01016717 JAC97574.1 CH933806 EDW13702.2 KPU79642.1 UFQT01000524 SSX24974.1 GAKP01015428 JAC43524.1 AXCM01000006 OUUW01000007 SPP83209.1 CM000070 KRT00583.1 EIM52732.2 AJWK01012994 AJWK01012995 AJWK01012996 AJWK01012997 AJWK01012998 AJWK01012999 AJWK01013000 AJWK01013001 EDY68162.2 AFH06350.1 NEVH01012563 PNF30221.1 CCAG010015267 ADTU01003876 KQ977220 KYN04846.1 KQ976701 KYM77289.1 KQ981029 KYN10183.1 KQ981768 KYN35941.1 PYGN01000567 PSN44130.1 GL437108 EFN71112.1
NWSH01000479 PCG76096.1 GAMC01019927 JAB86628.1 CM000160 KRK03404.1 KRK03405.1 KRK03406.1 CH940652 EDW58913.2 CP012526 ALC47706.1 KRF78592.1 KRF78593.1 KRF78595.1 EU707853 AE014297 AY113374 AFH06349.1 CVRI01000006 CRK87888.1 AFH06351.1 GBXI01017492 JAC96799.1 CH964272 EDW83990.2 CH902617 KPU79643.1 GBXI01016717 JAC97574.1 CH933806 EDW13702.2 KPU79642.1 UFQT01000524 SSX24974.1 GAKP01015428 JAC43524.1 AXCM01000006 OUUW01000007 SPP83209.1 CM000070 KRT00583.1 EIM52732.2 AJWK01012994 AJWK01012995 AJWK01012996 AJWK01012997 AJWK01012998 AJWK01012999 AJWK01013000 AJWK01013001 EDY68162.2 AFH06350.1 NEVH01012563 PNF30221.1 CCAG010015267 ADTU01003876 KQ977220 KYN04846.1 KQ976701 KYM77289.1 KQ981029 KYN10183.1 KQ981768 KYN35941.1 PYGN01000567 PSN44130.1 GL437108 EFN71112.1
Proteomes
UP000053240
UP000053268
UP000007151
UP000218220
UP000002282
UP000095301
+ More
UP000008792 UP000092553 UP000192221 UP000000803 UP000183832 UP000007798 UP000007801 UP000095300 UP000009192 UP000075883 UP000268350 UP000075920 UP000001819 UP000092461 UP000076408 UP000078200 UP000235965 UP000092444 UP000005205 UP000078542 UP000078540 UP000078492 UP000078541 UP000245037 UP000002358 UP000000311
UP000008792 UP000092553 UP000192221 UP000000803 UP000183832 UP000007798 UP000007801 UP000095300 UP000009192 UP000075883 UP000268350 UP000075920 UP000001819 UP000092461 UP000076408 UP000078200 UP000235965 UP000092444 UP000005205 UP000078542 UP000078540 UP000078492 UP000078541 UP000245037 UP000002358 UP000000311
PRIDE
Pfam
PF00028 Cadherin
SUPFAM
SSF49313
SSF49313
ProteinModelPortal
A0A194R5E9
A0A194PP17
A0A212FPL9
A0A2A4JWD7
W8AQ69
A0A0R1E2B6
+ More
A0A0R1E3R0 A0A1I8N8Q2 A0A1I8N8Q1 B4M5I7 A0A0M5J0H2 A0A0Q9W9T1 A0A1W4VG84 A0A1W4VFX9 A0A0Q9W0H3 Q9VGW1 A0A0B4K655 A0A1J1HIK9 A0A0B4K6E3 A0A0A1WED2 B4NJY8 A0A0P8YDR5 A0A0A1WGF4 A0A1I8NT94 A0A1I8NT98 A0A1I8NT99 B4KC93 A0A0P8ZY96 A0A1I8NT97 A0A336M3Y0 A0A034VM16 A0A182MS56 A0A3B0KAT2 A0A182W532 A0A0R3NHT4 I5AP47 A0A1B0CI24 B5DVI5 A0A182Y535 A0A0B4K720 A0A1A9UX43 A0A2J7QNR1 A0A1B0FQS3 A0A158NZ57 A0A195CVZ1 A0A195AZA3 A0A151IT89 A0A195F6C9 A0A1I8NTA2 A0A2P8YIP2 K7IYP2 E2A653
A0A0R1E3R0 A0A1I8N8Q2 A0A1I8N8Q1 B4M5I7 A0A0M5J0H2 A0A0Q9W9T1 A0A1W4VG84 A0A1W4VFX9 A0A0Q9W0H3 Q9VGW1 A0A0B4K655 A0A1J1HIK9 A0A0B4K6E3 A0A0A1WED2 B4NJY8 A0A0P8YDR5 A0A0A1WGF4 A0A1I8NT94 A0A1I8NT98 A0A1I8NT99 B4KC93 A0A0P8ZY96 A0A1I8NT97 A0A336M3Y0 A0A034VM16 A0A182MS56 A0A3B0KAT2 A0A182W532 A0A0R3NHT4 I5AP47 A0A1B0CI24 B5DVI5 A0A182Y535 A0A0B4K720 A0A1A9UX43 A0A2J7QNR1 A0A1B0FQS3 A0A158NZ57 A0A195CVZ1 A0A195AZA3 A0A151IT89 A0A195F6C9 A0A1I8NTA2 A0A2P8YIP2 K7IYP2 E2A653
PDB
5SZR
E-value=2.17914e-22,
Score=267
Ontologies
GO
Topology
Subcellular location
Cell membrane
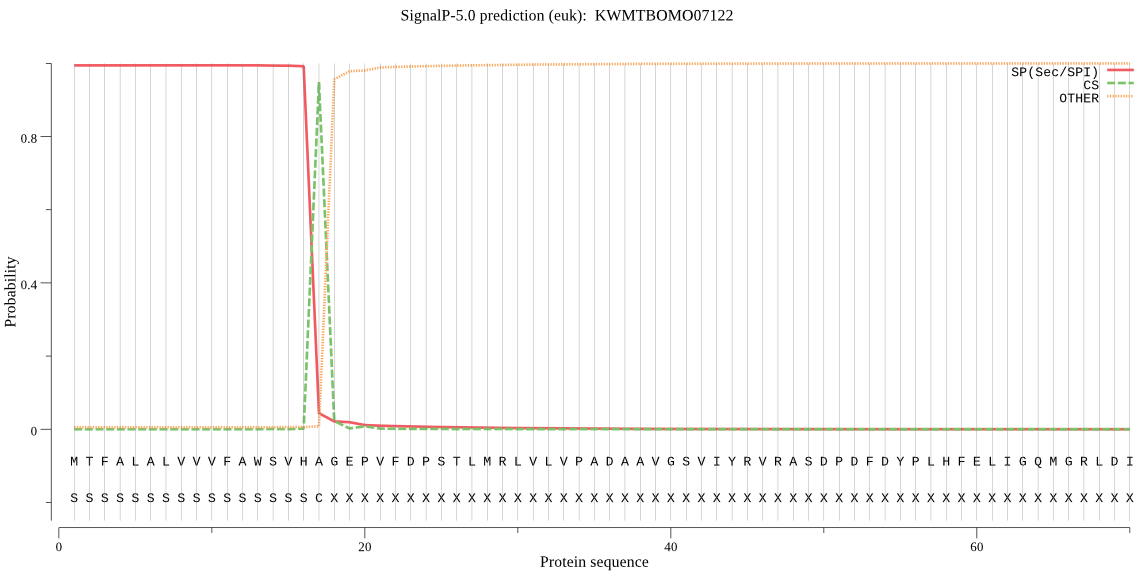
SignalP
Position: 1 - 17,
Likelihood: 0.994122
Length:
1801
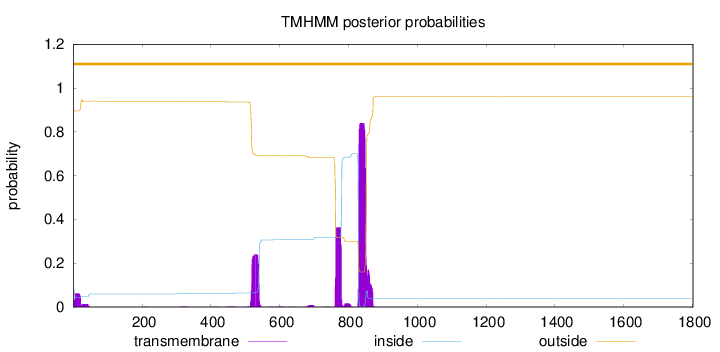
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
35.3174000000001
Exp number, first 60 AAs:
1.45267
Total prob of N-in:
0.10098
outside
1 - 1801
Population Genetic Test Statistics
Pi
206.452655
Theta
162.439008
Tajima's D
0.847276
CLR
0.004412
CSRT
0.613169341532923
Interpretation
Uncertain
