Gene
KWMTBOMO07045
Pre Gene Modal
BGIBMGA010453
Annotation
Protein_dachsous_[Papilio_xuthus]
Full name
Protein dachsous
Alternative Name
Adherin
Location in the cell
Nuclear Reliability : 1.501 PlasmaMembrane Reliability : 1.251
Sequence
CDS
ATGTCTGCCATTGATCCTGATTGTGGTGTCAATGCTCTCGTCAACTACACACTGGGAGATGTTTTGGCGAAGACCAGATTCTCAGTGAAACCGGACACAGGAGAACTTTGCGTGACTTCGCCCTTGGATTACGAAGATACCAGTGAATATGAGTTTCCAGTCATTGCTACCGATCGAGGAGGGCTGTCCACGACCGCCGTTGTGAAGATCCAACTAGTCGATATCAACGACAACGCACCAAGCTTCACCGTTAAAGATTACAATGTGTCATTGAAGGAAGGACGGATATCATCTACCGAGCCAATAGTAGCGGTGTCGGCCACAGACACTGATTCGGGAAGATTCGGAACGATCACTTACAGAATTATCAGTGGGAACGAGAACGATATTTTTAGGATAGATCGGAGCAGCGGAGAGATACTAGTTACGAAGCCGGCTCTGATTGATAAAGATAAGAAGTTCCGTCTAGAAGTATCTGCTACTGATGGAGGAGGTCTGGCGGCACCACAAGCTGCTGCGGTCCACATGACTGTTATTCCCGCGGGAGTCGGTACGGCGCTATTCGATAAACCAAGATATAATTTTCGTGTGAAAGAAGACATAAGGATTGGAGCTTTCGTTGGAAGTCTAAAAGCCACAGCTAACGACAGAGGATCACAGCCGGTTCGATACAGCATAATATCTGGAGATATCGACAGAGCTTTCACCGTAGAACCGATGACAGGCGCTATAAGGACTGTGAAAATCCTGGATCGGGAGACCAGACCCTCGTATCAACTGAACGTGAAAGCATCAACTGGGAACCCCGCTAATTTTGATCAGACACAGGTACAAATCACTCTAGAAGACGTGAACGACAACACACCGGATTTCGGTACGTCAACGGTCAGGGTTTCAGTAGCCGAATCAGCAGCGGTGGGTTCAGTGGTGTACTCAGCAAGGGCTACTGATGCCGACGATGGCAAGAACGGACTCATCGGATATCAGCTGATATCTGCTAGTGGACCTTCAAACACCTTTGCTGTTAATTCACAGAACGGCTTGGTGACACTACTAAGGCCATTGGATTACGAGAACCTTGTTCGTCATAATCTGGTGATTCTAGCAAAGGATGGAGGATCTCCTCCCCTCGCTTCCAATTTGACATTAGTGGTTGATGTCCAGGATGTTAATGACAACACACCTGTCTTCGAACATGAGGCTTATACGGCTAATATATTGGAATCGGAAACAGTCAATGCGAAGATATTAGAAGTTCAAGCGATAGATAAAGACACAGGTAATAATGCACGGATAACATACCGCATCTTATCAGAAAATAATAATACTAATGAAGAGTTTTTCAAAGTACAACCTTCCACTGGCTGGGTGTATCTAGCTAAGCCACTGGACAGAGAAACCAAGGCTAAACATAAAATGCTTCTAACAGCAACAGATAATGGCTTACCGCCACTGTCGACAACCGCTAATTTAGTTGTTAATGTGATCGATGCGAATGACAATGACCCGGTGTTCACAAAAAACGCTTATGAGTTCCAAGTCGAAGAGAATTCTAGAGCTGGAGCTTTTGTTGGGAAAATATCGGCCGTCGATTCTGATTTGGGTGATAATGCAGTTGTCAAGTATAGTTTGTTCCCATCGAATACGAGTTTCAACGTTAACCCTACTACTGGTGTTATAACCACGAAAGAAGTTTTAGATCGAGAACTAAAATCTGCATATTCTCTGTTTGCTGAAGCAAGAGATCAAGGCACTTTGCCGAGATCAAGTAGAGTGCCTGTTTACATTAAGATCACTGATGTCAATGATAATTCGCCTGAGATCATTGATCCCAGAGAAGACGTGGTCAGCGTAAGAGAAGAGCAGCAGCCAGGCGCGGAAGTCGCAAGAGTGAAGGCTATTGATAGAGATAACGGCGTGAATTCCTCAATCACTTATTCCATCCTGAACGAGAGAGACATGGATGGATATGGTGTTTTTGTCATTGATCCTAGCACGGGAGTCATTAGAACTAGCACAGTTCTCGATCACGAGGAAAGATCGATCTACCGGTTGACAGTAGCAGCCACAGATGGTGGGAATCCCCCGAAGAAAACCATAAGACAACTCAAAGTCGAGGTGCTGGATTTGAATGACAACAGACCAACTTTCACGAGTTCCAGTTTATCATTTAAAGTCAAAGAGGATTCTGAAATTGGTCACGTGGTTGGTTTAGTCGCCTGCTGTGATAGTGACATACAAGACAATGTCATTAGCAATGACGAAAAACAAATCTCTTACCTGCTTATGCCAATCACTAGCGATTATGCACCCGGTACTTTTGAGATTGATCGAAGAACCGGATCGCTAGTTGTCGCGAGACAACTAGACAGAGAGATACAAGATGAATACAGACTCGAAGTGAGAGCTCTAGATACGTCCGCGACAAACAATCCTCAGAGCAGCGCTGTAACTGTCAGGATCGAAATCGTTGACGTCAATGACAATGCACCGAAATGGCCACAAGATCCTATTCATGTCGAAATTTCAGAAATCACCCCCGTTGGTAGCATCGTGTACAATTTTACCGCAAAAGATGACGATGCAGGTCCGAATGGCGAAATGAATTTTCGTATTGTGCATTCTCTGCCAAATAACAAAAGCGCTTTCAATCTCGATCCACTGACAGGCTCTCTTACTCTTACGTCAAGCTTAGATTATGAAGTCTTGAAAGAATATTGGATAATCGTAGAAGCCACAGATTTAGCCGAAAAGATTTCCGAAAGACTATCAACCTTAGTTACAGTACATGTATCAATAACTGACGCTAACGATAATACGCCTACTTTTGTCTCAACGACTAATGTTGTTCTGTCGCTAAACACATTGCCCGGCACCCTTTACCAGGCTTTAGCTATAGATGCAGACCACGGGGACAACGGCAAAATATCTTACTACATATCAAGCGGTAATGAACATGCGTATTTCTCTTTGGATAACGACTCGGGAAGATTGACTGTCTCAAATAAATATTCTTCGGACACTTCAAAGATCCGGCACGGCCTCTACAAACTAAATCTAACGGCAACGGACCACGGAGTTCCGTTCCCGAGACAAAGTCATATGACGTTAAAACTGAACCTGCAAGAGTCGACTAACGTACCGCCGAGGTTTACAGAATTGACTTATCGCGCGAACATCAGCGAGGACATAAGACCCGGCAGTTTCGTTACTCGTTTGATGGCTAAATCTTCGAGAGGCTCAGCGAGTAACTTAACGTACACGATTCCCTATGGCGTGGCTGATGACAAATTCACAATCGATGATCGCATAGGAACCATAACCGTGAAGACAAAGATCGATCGAGAAGAACGAGACAAATACATTTTTCCAGTTTACGTCACTGATTCCAGTGCTTACCAATCCACGACGAACTTCGACGTCGCAACAGTGACTATCAGTATTATGGACGTAAACGACAATCCGCCGACTTTTAAAATAGGCTCTTGTTACCCTCTAGCTGTACCAGAGAACAACGAACCGGAAGTCATACACACTGTTACGGCCACAGATAAAGATATTGGAGCGAACGGTATAATAACTTACAGCGTTACATCTGGTAACCATGGCAACAAATTCTTCATTGACGCCACTACAGGAAAATTGACCGCCAAGACGTTAGATCGTGAGACTCAAAGTAAATATCTCCTCACAATCACGGCTTTCGACCATGGATCGCCTGTGGCGCTGCAAGGGTCTTGCAATATTACTGTCGTGGTAGAAGATCAAAACGACAATGACCCTGTATTTGATACCGGACACTATTCAGCCGCCATACCGGAGAACGCAATGATCGAAACTTCAGTGATTAAAGTGAGAGCAACGGACGCTGACTTAGGTTTCAATAAGCGCATCGTTTATTCTTTGGCGAATGAGAGTCAAGGACTATTCAGAATCGACAACAGAACCGGAATTATTTTTACGACTGGAACCTTTGATCGGGAGAAAACAAATGTATACCACTTCGAAGCAGTAGCAACTGATCAGGGTCGATATATAACACGCTCCCAAAGGGTTTCAGTCGAAGTAACAATAACCGATGTCAACGATCACAAACCTATATTTACCAAGTACCCCTTCAAGGAACAAGTGGCGTCCCTGACCCCACCGGGACAGAGCTTACTGCGCGTTTCTGCAACCGACAAAGACATAGGAATTAACGCGGAAATTCTATACGAGTTGATTGACAATTTTAATAATAAATTTCGTATCAATCCAACCACAGGCGTGCTAACGGCCACGCAAAGCCTAGCCAGTGAAAACGGGAAACTGGTTCACCTTAAAATTATGGCAAAAGACAAGGGAAATCCCCCACAGAGTTCAACAGGCCTAATAGAGTTGAGAGTTGGAGATTTTTCAGATAACACGCTTTCATTGAACTTCCAAAACTCCACATACAACGTGACCGTTCCAGAGAATTTGCCATACGGCAAAGAAGTCATCCAAGTTACAGCAATAAGGAGTGACGGTCGACGCCAACGAATCATTTACGAAATAGGCAACGGAAACGATCAATACGCCTTTGTGATAGATTCGAACACCGGAGTGATAAGAGTGAACAACTCTGCGAAATTAGACTACGAATCACATCCAGGGCCTTCAAGGAAATTGGTTATCGTAGCTCGCACCGAGGGATCGCCCAGTCTGTACGGATATTGCGACGTCGTGGTCAATCTTAAAGACGAAAACGATCACGCGCCTAGATTCACGCAGCAACAATACATCGCGAATGTACTCGAAGGGAATGCTAAAGGCGAATTTGTTCTGCAATTATCCGCCAAGGATGCTGATCACGGGGCGAACGCGAGGATCCTTTACCACATCGTCGACGGAAACCACGATAACGCGTTCATCATCGAACCGGCCTTCTCTGGTTCGGTGAAGACGAACATCGTACTCGACAGGGAGATCCGCGAGTCGTACAAGCTGACAGTGATCGCTACAGACGAAGGCGACCCGCAGATGACGGGCACGGCGACGCTGCGGATCAATGTCGTGGACGTCAATGACAACCAGCCGACGTTTCCACCGCCCGACGTCATTACCGTCTCGGAAGGAACGGAAATCGGAACGGTCCTGACATCGGTCACCGCTAATGATGTCGATACGTATCCAGCCCTAAAATACTCTATAATACAAGGAGACAACAAATTTTCAATCGATCGATACAGCGGGAAGGTTGTGCTGAATAGGGCTCTCGATTTCGAAGCTGACAACGTTTACGAACTCAACATCGCCGCTTCGGATAGCGAGCACGTCGCCAAAACCACCCTCACGATCAAAGTGAGCGACATCAATGACAATGCTCCCGTTTTCGACGATGTTTCATACAACAAAATCTTGCCGGAAGGCACAGGCGTCTTGGAAATCGGCTCCGTTAGCGCTAAAGACAGGGACAGCGGCGACAATAGCCGAGTGACATACTCGTTGCTTCGCTCGACGGAGGGGTACTACGTCGACGGGAACACGGGGGCCGTCTACGTGAACTACAGCGCCCTGCCTCGGAGCCAGAAGGATGTGGAGCTGGCGATCGTCGCGACGGACCACGGGCGACCGAACAGGAGCGCCGTGGCCGCGATGCGAATCAACGCGGGCGCTTCGTCCGAAATCAAACCTTACATCGGACAAGACACTTACAGAATAACAATTAACGAAGACACAGAGAAAGGCTCTTCATTACTCCGAATCGGTGGAATTAACGATGTGCTCAAGAAGTACAATTTGAACTTTCACATCACTACGGGAAATGAAAACGATTCTTTCGATGTAACTCAAGAAGGAGCACTGATCCTTCTCAAGAAACTAGATCGAGAAACTCAAGACTCATACGTGCTGGGATTGGCTGCAGTCGAACACGGCAAACTATTACGAAATCAAAACAAAACAGCCATCACTGTATTTGTAACCGTCGCCGACGCTAACGACAACGCACCGACGTTCTCAAGCAACGATTTCGAATTGACCGTCAATGAAGGCGTCAAAATCGGATATACGCTTACGAAATTAGTCGCTACAGATGCAGACCAATCCGGAACTCCAAATGCTAATGTAGTTTACAATTTGACTTCAGGAGACGACGAAGGTCTGTTCTTTATACATCCCTCCACGGGAGTACTGAACGTTAATAAGCCCCTTGACTACGACACAGGCAGTACGGAGTATAAGCTGGTTATTATTGCGTGCGATCTAGGTGTCCCTGCTTTGTGCAGTGAGGCTTACATCAAAATCGGTCTGATCGACGAGAATGACAATACTCCCACGTTTCCCGTAAGCGAATACTTCGAGAGTATTGCTGAAAACGAAAGAACGGGTACGTCCGTGTTCATTGCCAGAGCGACCGATCTGGATAAAGGCAAATTCGGGAAACTCGACTATACGATAATACCGTCAACGTTCAATTTAAATAGGAAGGACGATTCGTGGAAGCTGTTCCAGATCGATTCGTCAACTGGACTGGTGAACAGTAACGCGGTGTTCGACTACGAGACGCGAAATAAATACGAGTTCTCAATAAAAGCATCTGACTTGGGCGGGAAAAGTTCAACTGTGAAAGTGAGAATTGACGTAGAGAGTCGCGACGAATTTTATCCTCAATTTACGCAAAAAACCTACAAGTTTAGGATACCGAAATCGGGGTCGTTGCCCGCCGGGTATACCATCGGTCAAGCAACTGCCACAGATCGAGACAAAGGCATCGATGGCCGCATCGTGTACCAACTGTCGACATCGCATTCTTACTTTAAAATCAACAGGACTACAGGCGTTATTATACTGAAGAAGAAAATAGATTCTGTGCAAAATTTGTTTGGTTCAGACAAATCGATTAGTTTGGTTGTCACCGCAAGCTCTGGTCGACAAGGCTCCCTAACAAATAAAACCGCAGTCGAAATCGGATTGAACGGCATGGCTTTGGCTGGTGAAATAGATCAAACAAACGACACAGCGGCCGCCACAAATGGAGGTCTTTCAGATTGGGCTTTAGGATTACTTATCGCTTTCATATTCATTATAATTATATTTGCAGCAGCGTTTCTGTTCTTGCACATGAAAAATAAAAGACACAAAAACGTCAACAAGCCCGGCTTCAATTCTGAAGGAGGGGTCACCACTAATAGTTATGTCGATCCAGGTGCTTTTGATACTATCCCCATTAGAAACACCGGTACGGTCAATTCTGCTGGTCAGTTCGCTCCGCCAAAATACGATGAGATACCTCCGTATGGTCCACACACAGCAAGCTCGAATTCCGGGGCCGCTACTACATCAGAACTCTCAGGCTCTGATCAATCCGGCTCAAGCGGGCGTGGCTCAGCTGAGGACGGAGAAGACGGTGAGGACGAGGAAATAAGAATGATTAATGAAGGTCCCTTGCAACGAGAGTCCGGGATGCATAGATCAGGAGACGATGACAATCTCTCTGATGTTTCAGTACGTAATACACAAGAATATTTAGCGAGACTCGGTATAGTTGACACGGGTGCCGGAGGCGGAGCTTCAACGTCATCAAGGCGATGCTCTGAAAATACAGGAACTAAAGATAATATGTTACATCACCCACCGATGGATTCTATGCATATGTTCGATGAAGATGGCGGTCACGAAAACGATATCACGAATCTCATTTACGCCAAACTTAATGAAGTTACCGGCAGCGAAAGAGCCAGTAGTGCTGATGAAGCCAGTGCTGCCGTAGACAGAGCTATGGCTTTAGGTGCATTTCCCAGCGCTCCAGGGGAGAACACAGCCGTACCAACCGCTGGTCCTTCTATGACCGGCAGTCTTAGTTCAATAGTACATTCTGAAGAGGAATTAACTGGCAGCTACAACTGGGACTACTTACTCGATTGGGGTCCGCAGTATCAGCCCTTAGCGCATGTCTTTTCGGAAATAGCGCGTCTAAAAGACGATGCCGTGTCACTTCAAAGTGGAAATAGTGCGGCGTCTAGTGCCAAAAGTAAAGGAACGTCCATATCTGGAGGTAAAAGTGTGCCGCCCCCTCTTTTAACGACAGTAGCGCCAAGGAGTTGTCCTGCGCCGTCGCTGTCGTGTAGACAACCGCAGCTCCTACTGCCTAGATCGCCTATAAGTCATGATGTTCCTGGGGGATTTTCTGCTGCGGCTGCCATGTCTCCGTCCTTCTCCCCCTCATTATCTCCTCTAGCTACGAGATCGCCATCGATGTCTCCCCTTGTAGGTCCCGGCCTTCCGCCGGTGCCCGGTAGCAGAAAACCTCCCCACACAACTATGCGAATGTGA
Protein
MSAIDPDCGVNALVNYTLGDVLAKTRFSVKPDTGELCVTSPLDYEDTSEYEFPVIATDRGGLSTTAVVKIQLVDINDNAPSFTVKDYNVSLKEGRISSTEPIVAVSATDTDSGRFGTITYRIISGNENDIFRIDRSSGEILVTKPALIDKDKKFRLEVSATDGGGLAAPQAAAVHMTVIPAGVGTALFDKPRYNFRVKEDIRIGAFVGSLKATANDRGSQPVRYSIISGDIDRAFTVEPMTGAIRTVKILDRETRPSYQLNVKASTGNPANFDQTQVQITLEDVNDNTPDFGTSTVRVSVAESAAVGSVVYSARATDADDGKNGLIGYQLISASGPSNTFAVNSQNGLVTLLRPLDYENLVRHNLVILAKDGGSPPLASNLTLVVDVQDVNDNTPVFEHEAYTANILESETVNAKILEVQAIDKDTGNNARITYRILSENNNTNEEFFKVQPSTGWVYLAKPLDRETKAKHKMLLTATDNGLPPLSTTANLVVNVIDANDNDPVFTKNAYEFQVEENSRAGAFVGKISAVDSDLGDNAVVKYSLFPSNTSFNVNPTTGVITTKEVLDRELKSAYSLFAEARDQGTLPRSSRVPVYIKITDVNDNSPEIIDPREDVVSVREEQQPGAEVARVKAIDRDNGVNSSITYSILNERDMDGYGVFVIDPSTGVIRTSTVLDHEERSIYRLTVAATDGGNPPKKTIRQLKVEVLDLNDNRPTFTSSSLSFKVKEDSEIGHVVGLVACCDSDIQDNVISNDEKQISYLLMPITSDYAPGTFEIDRRTGSLVVARQLDREIQDEYRLEVRALDTSATNNPQSSAVTVRIEIVDVNDNAPKWPQDPIHVEISEITPVGSIVYNFTAKDDDAGPNGEMNFRIVHSLPNNKSAFNLDPLTGSLTLTSSLDYEVLKEYWIIVEATDLAEKISERLSTLVTVHVSITDANDNTPTFVSTTNVVLSLNTLPGTLYQALAIDADHGDNGKISYYISSGNEHAYFSLDNDSGRLTVSNKYSSDTSKIRHGLYKLNLTATDHGVPFPRQSHMTLKLNLQESTNVPPRFTELTYRANISEDIRPGSFVTRLMAKSSRGSASNLTYTIPYGVADDKFTIDDRIGTITVKTKIDREERDKYIFPVYVTDSSAYQSTTNFDVATVTISIMDVNDNPPTFKIGSCYPLAVPENNEPEVIHTVTATDKDIGANGIITYSVTSGNHGNKFFIDATTGKLTAKTLDRETQSKYLLTITAFDHGSPVALQGSCNITVVVEDQNDNDPVFDTGHYSAAIPENAMIETSVIKVRATDADLGFNKRIVYSLANESQGLFRIDNRTGIIFTTGTFDREKTNVYHFEAVATDQGRYITRSQRVSVEVTITDVNDHKPIFTKYPFKEQVASLTPPGQSLLRVSATDKDIGINAEILYELIDNFNNKFRINPTTGVLTATQSLASENGKLVHLKIMAKDKGNPPQSSTGLIELRVGDFSDNTLSLNFQNSTYNVTVPENLPYGKEVIQVTAIRSDGRRQRIIYEIGNGNDQYAFVIDSNTGVIRVNNSAKLDYESHPGPSRKLVIVARTEGSPSLYGYCDVVVNLKDENDHAPRFTQQQYIANVLEGNAKGEFVLQLSAKDADHGANARILYHIVDGNHDNAFIIEPAFSGSVKTNIVLDREIRESYKLTVIATDEGDPQMTGTATLRINVVDVNDNQPTFPPPDVITVSEGTEIGTVLTSVTANDVDTYPALKYSIIQGDNKFSIDRYSGKVVLNRALDFEADNVYELNIAASDSEHVAKTTLTIKVSDINDNAPVFDDVSYNKILPEGTGVLEIGSVSAKDRDSGDNSRVTYSLLRSTEGYYVDGNTGAVYVNYSALPRSQKDVELAIVATDHGRPNRSAVAAMRINAGASSEIKPYIGQDTYRITINEDTEKGSSLLRIGGINDVLKKYNLNFHITTGNENDSFDVTQEGALILLKKLDRETQDSYVLGLAAVEHGKLLRNQNKTAITVFVTVADANDNAPTFSSNDFELTVNEGVKIGYTLTKLVATDADQSGTPNANVVYNLTSGDDEGLFFIHPSTGVLNVNKPLDYDTGSTEYKLVIIACDLGVPALCSEAYIKIGLIDENDNTPTFPVSEYFESIAENERTGTSVFIARATDLDKGKFGKLDYTIIPSTFNLNRKDDSWKLFQIDSSTGLVNSNAVFDYETRNKYEFSIKASDLGGKSSTVKVRIDVESRDEFYPQFTQKTYKFRIPKSGSLPAGYTIGQATATDRDKGIDGRIVYQLSTSHSYFKINRTTGVIILKKKIDSVQNLFGSDKSISLVVTASSGRQGSLTNKTAVEIGLNGMALAGEIDQTNDTAAATNGGLSDWALGLLIAFIFIIIIFAAAFLFLHMKNKRHKNVNKPGFNSEGGVTTNSYVDPGAFDTIPIRNTGTVNSAGQFAPPKYDEIPPYGPHTASSNSGAATTSELSGSDQSGSSGRGSAEDGEDGEDEEIRMINEGPLQRESGMHRSGDDDNLSDVSVRNTQEYLARLGIVDTGAGGGASTSSRRCSENTGTKDNMLHHPPMDSMHMFDEDGGHENDITNLIYAKLNEVTGSERASSADEASAAVDRAMALGAFPSAPGENTAVPTAGPSMTGSLSSIVHSEEELTGSYNWDYLLDWGPQYQPLAHVFSEIARLKDDAVSLQSGNSAASSAKSKGTSISGGKSVPPPLLTTVAPRSCPAPSLSCRQPQLLLPRSPISHDVPGGFSAAAAMSPSFSPSLSPLATRSPSMSPLVGPGLPPVPGSRKPPHTTMRM
Summary
Description
Required for normal morphogenesis of adult structures derived from imaginal disks (PubMed:7601355, PubMed:26073018). Plays a role in planar cell polarity and in determining body left-right asymmetry. Expression in segment H1 of the imaginal ring and interaction with Myo31DF are required to induce changes of cell shape and orientation in segment H2, which then gives rise to normal, dextral looping of the adult hindgut (PubMed:26073018).
Cadherins are calcium-dependent cell adhesion proteins.
Cadherins are calcium-dependent cell adhesion proteins.
Subunit
Interacts (via cytoplasmic region) with Myo31DF.
Miscellaneous
Overexpression in segment H1 of the imaginal ring causes aberrant gut looping in about 40% of the cases, but no phenotype is observed when both Myo31DF and ds are overexpressed.
Keywords
Calcium
Cell adhesion
Cell junction
Cell membrane
Complete proteome
Developmental protein
Glycoprotein
Membrane
Phosphoprotein
Reference proteome
Repeat
Signal
Transmembrane
Transmembrane helix
Feature
chain Protein dachsous
Uniprot
H9JLQ1
A0A2A4K1N8
A0A194PP91
A0A194QMY7
A0A212FNL2
A0A2H1VPE4
+ More
A0A2W1BDR9 A0A0L7LU32 A0A1W4WLJ5 A0A182QV25 A0A182PMD9 B0W509 A0A1J1I2P7 Q17NI8 A0A182GQ04 A0A182HEA6 Q7Q3J3 A0A182RBP2 A0A182WTB1 A0A182L262 A0A182HVA4 A0A182VEY7 A0A139WJJ2 A0A182MNG6 A0A067RFM8 A0A182W9R6 A0A084VNZ0 A0A182YGW7 A0A182J8X2 A0A182F4I1 A0A182TEW5 U4U684 A0A1Y1JUP0 E0W399 B4LTP4 B4JDS3 B3N7T5 B4P2W3 A0A0J9QT98 X2J8E9 Q24292 A0A0Q5WKE5 A0A3B0K446 A0A224XHC1 A0A0R1DII4 B5DIW2 A0A0M5IVU2 B4ID02 A0A1W4V2Q6 B4KF91 B4N0S5 B3MLQ6 T1IGF4 A0A0P5IPN6 A0A0P5V9G7 A0A0P5WER7 A0A0P5X8X2 A0A0P5ERX1 A0A0P5WEN0 A0A164YHC3 A0A0P6IAL4 A0A0P5WAQ4 A0A0P6GTD1 A0A0P6FJE9 A0A0P5A0G7 A0A0P5A6D9 A0A0P5P0B0 A0A0P5YE64 A0A0P5DNW1 A0A0P5XF80 E9FRI4 A0A0N7ZML0 A0A0P4Y9Z2 A0A0P5HCT2 A0A0P5NCC0 A0A3L8DVQ5 A0A0P5IJQ0 A0A0P5YF89 A0A0P5AT68 A0A0P5LXZ8 A0A0N8E8W0 A0A0P5BJS1 A0A0P6AL29 A0A336LSR0 A0A182JWX6 A0A0P5DZ38 B4Q669 A0A2H8TRA6 A0A2S2P2R1 A0A0N8D390 A0A2S2NWR9 A0A158NYX4 A0A151J145 J9LPE0 A0A195FT47 A0A0P5QQV1 N6TYV0 A0A0P5RW78 W5J5P8
A0A2W1BDR9 A0A0L7LU32 A0A1W4WLJ5 A0A182QV25 A0A182PMD9 B0W509 A0A1J1I2P7 Q17NI8 A0A182GQ04 A0A182HEA6 Q7Q3J3 A0A182RBP2 A0A182WTB1 A0A182L262 A0A182HVA4 A0A182VEY7 A0A139WJJ2 A0A182MNG6 A0A067RFM8 A0A182W9R6 A0A084VNZ0 A0A182YGW7 A0A182J8X2 A0A182F4I1 A0A182TEW5 U4U684 A0A1Y1JUP0 E0W399 B4LTP4 B4JDS3 B3N7T5 B4P2W3 A0A0J9QT98 X2J8E9 Q24292 A0A0Q5WKE5 A0A3B0K446 A0A224XHC1 A0A0R1DII4 B5DIW2 A0A0M5IVU2 B4ID02 A0A1W4V2Q6 B4KF91 B4N0S5 B3MLQ6 T1IGF4 A0A0P5IPN6 A0A0P5V9G7 A0A0P5WER7 A0A0P5X8X2 A0A0P5ERX1 A0A0P5WEN0 A0A164YHC3 A0A0P6IAL4 A0A0P5WAQ4 A0A0P6GTD1 A0A0P6FJE9 A0A0P5A0G7 A0A0P5A6D9 A0A0P5P0B0 A0A0P5YE64 A0A0P5DNW1 A0A0P5XF80 E9FRI4 A0A0N7ZML0 A0A0P4Y9Z2 A0A0P5HCT2 A0A0P5NCC0 A0A3L8DVQ5 A0A0P5IJQ0 A0A0P5YF89 A0A0P5AT68 A0A0P5LXZ8 A0A0N8E8W0 A0A0P5BJS1 A0A0P6AL29 A0A336LSR0 A0A182JWX6 A0A0P5DZ38 B4Q669 A0A2H8TRA6 A0A2S2P2R1 A0A0N8D390 A0A2S2NWR9 A0A158NYX4 A0A151J145 J9LPE0 A0A195FT47 A0A0P5QQV1 N6TYV0 A0A0P5RW78 W5J5P8
Pubmed
19121390
26354079
22118469
28756777
26227816
17510324
+ More
26483478 12364791 14747013 17210077 20966253 18362917 19820115 24845553 24438588 25244985 23537049 28004739 20566863 17994087 18057021 17550304 22936249 10731132 12537568 12537572 12537573 12537574 16110336 17569856 17569867 7601355 18327897 18635802 26073018 15632085 23185243 21292972 30249741 21347285 20920257 23761445
26483478 12364791 14747013 17210077 20966253 18362917 19820115 24845553 24438588 25244985 23537049 28004739 20566863 17994087 18057021 17550304 22936249 10731132 12537568 12537572 12537573 12537574 16110336 17569856 17569867 7601355 18327897 18635802 26073018 15632085 23185243 21292972 30249741 21347285 20920257 23761445
EMBL
BABH01005265
NWSH01000294
PCG77673.1
KQ459603
KPI92950.1
KQ461194
+ More
KPJ06887.1 AGBW02005533 OWR55280.1 ODYU01003656 SOQ42700.1 KZ150312 PZC71457.1 JTDY01000080 KOB78988.1 AXCN02000870 DS231840 EDS34575.1 CVRI01000038 CRK94042.1 CH477199 EAT48228.1 JXUM01015453 KQ560430 KXJ82442.1 JXUM01035309 KQ561054 KXJ79852.1 AAAB01008964 EAA12903.4 APCN01002503 KQ971338 KYB28093.1 AXCM01000141 KK852532 KDR21853.1 ATLV01014963 KE524999 KFB39684.1 KB632168 ERL89379.1 GEZM01100129 JAV53004.1 DS235882 EEB20105.1 CH940649 EDW65017.2 KRF81978.1 CH916368 EDW03443.1 CH954177 EDV57261.1 CM000157 EDW87170.1 CM002910 KMY87352.1 AE014134 AHN54066.1 L08811 AAF51468.3 KQS69935.1 OUUW01000004 SPP79741.1 GFTR01008987 JAW07439.1 KRJ97046.1 KRJ97047.1 CH379060 EDY70255.1 KRT04402.1 CP012523 ALC37924.1 CH480829 EDW45428.1 CH933807 EDW13074.2 CH963920 EDW77688.2 CH902620 EDV30777.1 ACPB03011274 ACPB03011275 ACPB03011276 ACPB03011277 ACPB03011278 ACPB03011279 GDIQ01212528 JAK39197.1 GDIP01102817 JAM00898.1 GDIP01087672 JAM16043.1 GDIP01087725 GDIP01087724 JAM15990.1 GDIQ01265362 JAJ86362.1 GDIP01087726 JAM15989.1 LRGB01000915 KZS15253.1 GDIQ01007265 JAN87472.1 GDIP01088771 JAM14944.1 GDIQ01265465 GDIQ01029947 JAN64790.1 GDIQ01056483 JAN38254.1 GDIP01205714 GDIP01205713 GDIP01199758 GDIP01039279 JAJ17688.1 GDIP01203558 GDIP01203557 JAJ19844.1 GDIQ01145352 JAL06374.1 GDIP01073124 JAM30591.1 GDIP01154663 JAJ68739.1 GDIP01073126 GDIP01073125 GDIP01073123 JAM30592.1 GL732523 EFX90172.1 GDIP01230657 JAI92744.1 GDIP01230658 JAI92743.1 GDIQ01229421 JAK22304.1 GDIQ01154897 JAK96828.1 QOIP01000003 RLU24416.1 GDIQ01212529 JAK39196.1 GDIP01058528 GDIP01058477 JAM45187.1 GDIP01198310 GDIP01198309 GDIP01198308 JAJ25093.1 GDIQ01163548 JAK88177.1 GDIQ01050388 JAN44349.1 GDIP01183558 JAJ39844.1 GDIP01183560 GDIP01183559 GDIP01028092 JAM75623.1 UFQS01000093 UFQT01000093 SSW99239.1 SSX19619.1 GDIP01153613 JAJ69789.1 CM000361 EDX03253.1 GFXV01004929 MBW16734.1 GGMR01011162 MBY23781.1 GDIP01073127 JAM30588.1 GGMR01008996 MBY21615.1 ADTU01004343 ADTU01004344 ADTU01004345 ADTU01004346 ADTU01004347 ADTU01004348 KQ980571 KYN15533.1 ABLF02030011 ABLF02030014 KQ981276 KYN43628.1 GDIQ01110813 JAL40913.1 APGK01004339 APGK01027939 KB740679 KB735706 ENN79608.1 ENN83328.1 GDIQ01095416 JAL56310.1 ADMH02002093 ETN59316.1
KPJ06887.1 AGBW02005533 OWR55280.1 ODYU01003656 SOQ42700.1 KZ150312 PZC71457.1 JTDY01000080 KOB78988.1 AXCN02000870 DS231840 EDS34575.1 CVRI01000038 CRK94042.1 CH477199 EAT48228.1 JXUM01015453 KQ560430 KXJ82442.1 JXUM01035309 KQ561054 KXJ79852.1 AAAB01008964 EAA12903.4 APCN01002503 KQ971338 KYB28093.1 AXCM01000141 KK852532 KDR21853.1 ATLV01014963 KE524999 KFB39684.1 KB632168 ERL89379.1 GEZM01100129 JAV53004.1 DS235882 EEB20105.1 CH940649 EDW65017.2 KRF81978.1 CH916368 EDW03443.1 CH954177 EDV57261.1 CM000157 EDW87170.1 CM002910 KMY87352.1 AE014134 AHN54066.1 L08811 AAF51468.3 KQS69935.1 OUUW01000004 SPP79741.1 GFTR01008987 JAW07439.1 KRJ97046.1 KRJ97047.1 CH379060 EDY70255.1 KRT04402.1 CP012523 ALC37924.1 CH480829 EDW45428.1 CH933807 EDW13074.2 CH963920 EDW77688.2 CH902620 EDV30777.1 ACPB03011274 ACPB03011275 ACPB03011276 ACPB03011277 ACPB03011278 ACPB03011279 GDIQ01212528 JAK39197.1 GDIP01102817 JAM00898.1 GDIP01087672 JAM16043.1 GDIP01087725 GDIP01087724 JAM15990.1 GDIQ01265362 JAJ86362.1 GDIP01087726 JAM15989.1 LRGB01000915 KZS15253.1 GDIQ01007265 JAN87472.1 GDIP01088771 JAM14944.1 GDIQ01265465 GDIQ01029947 JAN64790.1 GDIQ01056483 JAN38254.1 GDIP01205714 GDIP01205713 GDIP01199758 GDIP01039279 JAJ17688.1 GDIP01203558 GDIP01203557 JAJ19844.1 GDIQ01145352 JAL06374.1 GDIP01073124 JAM30591.1 GDIP01154663 JAJ68739.1 GDIP01073126 GDIP01073125 GDIP01073123 JAM30592.1 GL732523 EFX90172.1 GDIP01230657 JAI92744.1 GDIP01230658 JAI92743.1 GDIQ01229421 JAK22304.1 GDIQ01154897 JAK96828.1 QOIP01000003 RLU24416.1 GDIQ01212529 JAK39196.1 GDIP01058528 GDIP01058477 JAM45187.1 GDIP01198310 GDIP01198309 GDIP01198308 JAJ25093.1 GDIQ01163548 JAK88177.1 GDIQ01050388 JAN44349.1 GDIP01183558 JAJ39844.1 GDIP01183560 GDIP01183559 GDIP01028092 JAM75623.1 UFQS01000093 UFQT01000093 SSW99239.1 SSX19619.1 GDIP01153613 JAJ69789.1 CM000361 EDX03253.1 GFXV01004929 MBW16734.1 GGMR01011162 MBY23781.1 GDIP01073127 JAM30588.1 GGMR01008996 MBY21615.1 ADTU01004343 ADTU01004344 ADTU01004345 ADTU01004346 ADTU01004347 ADTU01004348 KQ980571 KYN15533.1 ABLF02030011 ABLF02030014 KQ981276 KYN43628.1 GDIQ01110813 JAL40913.1 APGK01004339 APGK01027939 KB740679 KB735706 ENN79608.1 ENN83328.1 GDIQ01095416 JAL56310.1 ADMH02002093 ETN59316.1
Proteomes
UP000005204
UP000218220
UP000053268
UP000053240
UP000007151
UP000037510
+ More
UP000192223 UP000075886 UP000075885 UP000002320 UP000183832 UP000008820 UP000069940 UP000249989 UP000007062 UP000075900 UP000076407 UP000075882 UP000075840 UP000075903 UP000007266 UP000075883 UP000027135 UP000075920 UP000030765 UP000076408 UP000075880 UP000069272 UP000075902 UP000030742 UP000009046 UP000008792 UP000001070 UP000008711 UP000002282 UP000000803 UP000268350 UP000001819 UP000092553 UP000001292 UP000192221 UP000009192 UP000007798 UP000007801 UP000015103 UP000076858 UP000000305 UP000279307 UP000075881 UP000000304 UP000005205 UP000078492 UP000007819 UP000078541 UP000019118 UP000000673
UP000192223 UP000075886 UP000075885 UP000002320 UP000183832 UP000008820 UP000069940 UP000249989 UP000007062 UP000075900 UP000076407 UP000075882 UP000075840 UP000075903 UP000007266 UP000075883 UP000027135 UP000075920 UP000030765 UP000076408 UP000075880 UP000069272 UP000075902 UP000030742 UP000009046 UP000008792 UP000001070 UP000008711 UP000002282 UP000000803 UP000268350 UP000001819 UP000092553 UP000001292 UP000192221 UP000009192 UP000007798 UP000007801 UP000015103 UP000076858 UP000000305 UP000279307 UP000075881 UP000000304 UP000005205 UP000078492 UP000007819 UP000078541 UP000019118 UP000000673
Interpro
SUPFAM
SSF49313
SSF49313
ProteinModelPortal
H9JLQ1
A0A2A4K1N8
A0A194PP91
A0A194QMY7
A0A212FNL2
A0A2H1VPE4
+ More
A0A2W1BDR9 A0A0L7LU32 A0A1W4WLJ5 A0A182QV25 A0A182PMD9 B0W509 A0A1J1I2P7 Q17NI8 A0A182GQ04 A0A182HEA6 Q7Q3J3 A0A182RBP2 A0A182WTB1 A0A182L262 A0A182HVA4 A0A182VEY7 A0A139WJJ2 A0A182MNG6 A0A067RFM8 A0A182W9R6 A0A084VNZ0 A0A182YGW7 A0A182J8X2 A0A182F4I1 A0A182TEW5 U4U684 A0A1Y1JUP0 E0W399 B4LTP4 B4JDS3 B3N7T5 B4P2W3 A0A0J9QT98 X2J8E9 Q24292 A0A0Q5WKE5 A0A3B0K446 A0A224XHC1 A0A0R1DII4 B5DIW2 A0A0M5IVU2 B4ID02 A0A1W4V2Q6 B4KF91 B4N0S5 B3MLQ6 T1IGF4 A0A0P5IPN6 A0A0P5V9G7 A0A0P5WER7 A0A0P5X8X2 A0A0P5ERX1 A0A0P5WEN0 A0A164YHC3 A0A0P6IAL4 A0A0P5WAQ4 A0A0P6GTD1 A0A0P6FJE9 A0A0P5A0G7 A0A0P5A6D9 A0A0P5P0B0 A0A0P5YE64 A0A0P5DNW1 A0A0P5XF80 E9FRI4 A0A0N7ZML0 A0A0P4Y9Z2 A0A0P5HCT2 A0A0P5NCC0 A0A3L8DVQ5 A0A0P5IJQ0 A0A0P5YF89 A0A0P5AT68 A0A0P5LXZ8 A0A0N8E8W0 A0A0P5BJS1 A0A0P6AL29 A0A336LSR0 A0A182JWX6 A0A0P5DZ38 B4Q669 A0A2H8TRA6 A0A2S2P2R1 A0A0N8D390 A0A2S2NWR9 A0A158NYX4 A0A151J145 J9LPE0 A0A195FT47 A0A0P5QQV1 N6TYV0 A0A0P5RW78 W5J5P8
A0A2W1BDR9 A0A0L7LU32 A0A1W4WLJ5 A0A182QV25 A0A182PMD9 B0W509 A0A1J1I2P7 Q17NI8 A0A182GQ04 A0A182HEA6 Q7Q3J3 A0A182RBP2 A0A182WTB1 A0A182L262 A0A182HVA4 A0A182VEY7 A0A139WJJ2 A0A182MNG6 A0A067RFM8 A0A182W9R6 A0A084VNZ0 A0A182YGW7 A0A182J8X2 A0A182F4I1 A0A182TEW5 U4U684 A0A1Y1JUP0 E0W399 B4LTP4 B4JDS3 B3N7T5 B4P2W3 A0A0J9QT98 X2J8E9 Q24292 A0A0Q5WKE5 A0A3B0K446 A0A224XHC1 A0A0R1DII4 B5DIW2 A0A0M5IVU2 B4ID02 A0A1W4V2Q6 B4KF91 B4N0S5 B3MLQ6 T1IGF4 A0A0P5IPN6 A0A0P5V9G7 A0A0P5WER7 A0A0P5X8X2 A0A0P5ERX1 A0A0P5WEN0 A0A164YHC3 A0A0P6IAL4 A0A0P5WAQ4 A0A0P6GTD1 A0A0P6FJE9 A0A0P5A0G7 A0A0P5A6D9 A0A0P5P0B0 A0A0P5YE64 A0A0P5DNW1 A0A0P5XF80 E9FRI4 A0A0N7ZML0 A0A0P4Y9Z2 A0A0P5HCT2 A0A0P5NCC0 A0A3L8DVQ5 A0A0P5IJQ0 A0A0P5YF89 A0A0P5AT68 A0A0P5LXZ8 A0A0N8E8W0 A0A0P5BJS1 A0A0P6AL29 A0A336LSR0 A0A182JWX6 A0A0P5DZ38 B4Q669 A0A2H8TRA6 A0A2S2P2R1 A0A0N8D390 A0A2S2NWR9 A0A158NYX4 A0A151J145 J9LPE0 A0A195FT47 A0A0P5QQV1 N6TYV0 A0A0P5RW78 W5J5P8
PDB
6E6B
E-value=9.89159e-53,
Score=531
Ontologies
PATHWAY
GO
GO:0016021
GO:0005509
GO:0005886
GO:0007156
GO:0004022
GO:0035222
GO:0090176
GO:0090175
GO:0007480
GO:0001737
GO:0007157
GO:0005887
GO:0035159
GO:0044331
GO:0045296
GO:0016339
GO:0045198
GO:0045317
GO:0007164
GO:0048592
GO:0016318
GO:0001736
GO:0098609
GO:0007476
GO:0042067
GO:0030010
GO:0035331
GO:0060071
GO:0016327
GO:0000904
GO:0008283
GO:0030054
GO:0018149
GO:0090251
GO:0035332
GO:0016020
GO:0007155
GO:0005515
GO:0004319
GO:0004320
GO:0016295
GO:0016296
PANTHER
Topology
Subcellular location
Cell membrane
Colocalizes with Myo32DF at cell contact sites. With evidence from 5 publications.
Cell junction Colocalizes with Myo32DF at cell contact sites. With evidence from 5 publications.
Cell junction Colocalizes with Myo32DF at cell contact sites. With evidence from 5 publications.
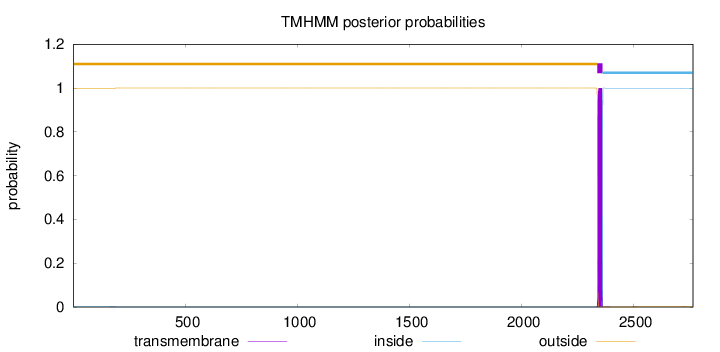
Length:
2764
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
22.84753
Exp number, first 60 AAs:
0.00106
Total prob of N-in:
0.00126
outside
1 - 2337
TMhelix
2338 - 2360
inside
2361 - 2764
Population Genetic Test Statistics
Pi
173.382393
Theta
166.718365
Tajima's D
0.04126
CLR
0.34233
CSRT
0.387330633468327
Interpretation
Uncertain
