Gene
KWMTBOMO06838
Annotation
PREDICTED:_uncharacterized_protein_K02A2.6-like_[Amyelois_transitella]
Location in the cell
Nuclear Reliability : 2.302
Sequence
CDS
ATGGAACACGCCCGACCACCGTCAGAATTGAGTCTGGAAGGCAACTCCGTCAGCCGGGCTGACGCATGGAAGCGTTGGAGGAAACAATTTCATCTATTTTTGAAAGCATCAGGGGTGCATAAAGAAGAAGGCAGTGTGCAAGCCAGCTTGCTCATCAATTTAATTGGAACGGAAGGTTTCGATGTGTACGAGACGTTCAAGTTTTCAAATGACACTGAAAAAGATGACGTAACGGTTTTGTTAAAAAAATTCGACGAATACTTCGGCGTCAAACCGAATGTTACGTTGGCGAGATATAATTTCTACATGAGAAACCAGGAAGGCGGCGAGTCCATAGATCAGTATGTGACGGCTTTGAAGCTGCTGAGCAAAACCTGTGAATTTAAAACCTTAGAAGAGGAATTCATTCGCGATCGGATCGTATGCGGCATAAAAAATACGATAGTTCGCGATCGTTTACTGAGAACGGACGACCTAACGATGGACAAAGCTATTAAAATATGCCAAGTCGACGAGGTATCGGCGGACAGCAGTCGCGTATTGCAGGAGTCGCGCGGAGCGAGTGCGGGGCCGGTGCGCGTGGACGCTGTGGGCGCGCGGGGTGGTGCTGGGCCACGTGCGGCGCGGGGTCGAGCCGGCTATGCGCGAGCAGCTCGCGGCGGCCGCGGCGGTCACCGGCTGCGTGCGGTCCCGGATGGCGCGGGGCGCCCGCCGCCTCTTTCCAGTTCATCTGCGTCCAGTACTTGTCTCAGGTGCGGAGGTCCGTGTGTTAGTTGGGCTGACTGTCCTGCGGTCTCAGTGCAGTGTTATGTGTGTCAAAATTATGGTCATTTTGCAAGAATGTGTCAAGTACATAAAGGTGTAAAAAAGTTATATGATATCGGTGTTCTAGAGGACGAAAATAAATACGAGCCGGAACTGGACGATGACTGGGAGTCGTTTTATATATCTACTTTAATTGATGGTTCCAAAATCGACTCGGTGTCGCAGGATTGGTTTGAGGTCCTCCGAGGAGAATGGGGCTCGGAAAATTTTAAACTAGACTCGGGTGCAGATATCAATGTCTTATCTTTTAAGCGATTTGTGCAGTTAGGCAATAACCCTAATAACATTGTTGTAAATCATAAGGTTAAACTGCAATCTTACAGTGGCGATTTCATTCCTATTAAGGGAATTTGTAACATTAAATGGTGGTATAAAAATGTTCAATATGATCTTAAGTTTGCGATAGCTGATATTGATTGTCAAAGTGTACTGGGACTGCAGGCGTGCTTATTATTAGGGTTAATAAAAAGAATTCACGATATAAATTTCTCTAAAAATAGTGATTTGTTCACTGGGTTAGGTTGTTTACCGGGGGAATATCATATAACGGTAGATAGGGATGTGACGCCGGTGGTGTGCGCTCCGCGGAAAGTACCGTTAAGCCTTCGTGATAACTTGAAGGACGAACTCGATAGGATGACAGAGTTAGGTGTGATTAGGAAGGTGACTCATCCGACACCTTGGGTCAACTCGTTAGTAGTAGTGGCCAAGACAAATGGTAAAATGCGCATATGCCTAGACCCGAGGCCTCTCAATAAGGCGATTCAACGTGCTCATTTTCAACTACCCACCATAAATGAGTTGGCTACCAAATTGAATGGGGCTAAATATTTTTCGGTATTGGACGCCAATTCAGGATTTTGGTCCGTAAAGCTAGATAAGGAGAGCGCCGATTTATGCACATTTATTACGCCGTTTGGGCGATATCAATATCTAAGATTACCGTTCGGACTGAACTGCGCACCGGAGGTATTCCACGCTAAATTAAAACAATTGTTAGAAGGTTTAGACGGTGTTGAGTCGTTTATTGATGATATTATTGTCTGGGGGTCCACTAGGCGAGAACATGATGTAAGACTAAATGCGTTATTTCAAAAAGCGCGAGATATTAATTTAAAGTTTAACAAAGATAAGTGTCGCATTTGTGTCGATGAGGTGACATATTTGGGACATATTTTTAATAAAGACGGAATGAAAGTAGATACGGAAAAAGTGCGGGCTGTAATCAATATGCCGGAACCTACGGATTGTAAAAGTTTAGAAAGGTTCTTGGGTGCAATTAATTATTTATCAAAGTTTATACCTAACTACTCGCAACACATATTTCCATTGACTAGATTATTGAAAAAAGATGTCGAGTGGTGTTGGGAAATAGGTCACAAAAACGCCTTTGATAAATTAAAGAAACTGATATGCGAGGCTCCGGTATTATCGTTGTTTGACGTAGGCAGTGAGGTATTGTTGTCGGTGGACGCGAGCAGCGTCGCACTTGGCGCGGTGCTGATGCAGCGCGGCCGCCCGGTCGAGTACGCGTCGCGCACACTCACCGACACACAACAGAGATACGCTCAGATTGAAAAAGAAATGTTAGCTATTGTCTTTGCTTGTGAAAAATTTCACCAGTACATTTATGGAAAAAGGTATATAGTCATAGAAACTGACCATAAACCTCTTGAAAGTATTTTTAAAAAGCCGCTCAATTCAGTCCCAGCACGCTTGCAGCGTATGATGTTAAAATTACAAGGGTACGATCTGAAAATTACTTATAAACCGGGGAAGTATATGTATATACCCGACACGTTATCACGTGCGCCTCTTCCGGATTTATATGACGATAAAATTAGTAAGGCAGTATTGAACCAATTGAAAATGGTAATTAACAATGTACCGATGTCTCAAAGCAAACTGACATTAGTTAAGAAAGAAACTAGTAAAGATGAGTATTTGAAACGTTTGTTAGTTTACATTAATGAAGGTTGGCCCGTTCATAAATATAATGTTGATAGTGATTTAAAGTATTTTTGGTCCATGAGAGACGAGCTGTACTCTGTTGACGGAGTAATTTTTAAAGATAAACAGCAACAGCATAAAACAATAATAGAAAAACAATTAAAAAGTAAAATGTATTATGACCAACATTGTAAAGCGCAGCCGGAGCTAAGTGTCGGCGATGATGTAATTATGTTAGAACATAATAATGAACGAATGCGCGGCACTGTCGTAGGCAAGGCATCTGCACCGCGTTCATACATTGTAAAAAACAAATTAGGTATATATCGACGTAATCGCCGACATTTAATTAAAAATATGCCTGATGAGAAACCTAATGTTGTGGAAAAGCTGAAGAATGATCGGCGCGGCACAATAGTGATCGTATCAGACGAGTCAAGTGGGGGAGAATATGAGATGAGTGTGGATGAGGATGGTTCAGTGTACGAACCGAGTACTTTGTCATCACCTTCATCACCTCATATTTATCCGCCTACTACTCGTAGTAGAACTAAGCAGAATGCAATTAATAATAATTAA
Protein
MEHARPPSELSLEGNSVSRADAWKRWRKQFHLFLKASGVHKEEGSVQASLLINLIGTEGFDVYETFKFSNDTEKDDVTVLLKKFDEYFGVKPNVTLARYNFYMRNQEGGESIDQYVTALKLLSKTCEFKTLEEEFIRDRIVCGIKNTIVRDRLLRTDDLTMDKAIKICQVDEVSADSSRVLQESRGASAGPVRVDAVGARGGAGPRAARGRAGYARAARGGRGGHRLRAVPDGAGRPPPLSSSSASSTCLRCGGPCVSWADCPAVSVQCYVCQNYGHFARMCQVHKGVKKLYDIGVLEDENKYEPELDDDWESFYISTLIDGSKIDSVSQDWFEVLRGEWGSENFKLDSGADINVLSFKRFVQLGNNPNNIVVNHKVKLQSYSGDFIPIKGICNIKWWYKNVQYDLKFAIADIDCQSVLGLQACLLLGLIKRIHDINFSKNSDLFTGLGCLPGEYHITVDRDVTPVVCAPRKVPLSLRDNLKDELDRMTELGVIRKVTHPTPWVNSLVVVAKTNGKMRICLDPRPLNKAIQRAHFQLPTINELATKLNGAKYFSVLDANSGFWSVKLDKESADLCTFITPFGRYQYLRLPFGLNCAPEVFHAKLKQLLEGLDGVESFIDDIIVWGSTRREHDVRLNALFQKARDINLKFNKDKCRICVDEVTYLGHIFNKDGMKVDTEKVRAVINMPEPTDCKSLERFLGAINYLSKFIPNYSQHIFPLTRLLKKDVEWCWEIGHKNAFDKLKKLICEAPVLSLFDVGSEVLLSVDASSVALGAVLMQRGRPVEYASRTLTDTQQRYAQIEKEMLAIVFACEKFHQYIYGKRYIVIETDHKPLESIFKKPLNSVPARLQRMMLKLQGYDLKITYKPGKYMYIPDTLSRAPLPDLYDDKISKAVLNQLKMVINNVPMSQSKLTLVKKETSKDEYLKRLLVYINEGWPVHKYNVDSDLKYFWSMRDELYSVDGVIFKDKQQQHKTIIEKQLKSKMYYDQHCKAQPELSVGDDVIMLEHNNERMRGTVVGKASAPRSYIVKNKLGIYRRNRRHLIKNMPDEKPNVVEKLKNDRRGTIVIVSDESSGGEYEMSVDEDGSVYEPSTLSSPSSPHIYPPTTRSRTKQNAINNN
Summary
Uniprot
A0A3B3HLX7
A0A2G8KFU3
A0A3B1JKR1
A0A3P8S414
A0A2G8KHQ8
A0A023EY30
+ More
A0A2S2N8I3 A0A3Q2XZ76 A0A0A9Z4Y4 A0A1Y1L7V1 A0A146LC45 A0A3P9LZF9 A0A3P9K9H2 A0A1A8DQM9 A0A3P9AYU2 A0A3P8R8M6 A0A147BKH7 A0A0P5XDK7 A0A0P5A948 A0A0P6BAV5 A0A0P5V4F7 A0A0P4XRP4 A0A0P5VCW1 A0A0P5DHJ0 A0A267GLM4 A0A1Y1MCJ7 A0A3Q2DE46 I3KYE2 A0A1A8N8J3 A0A147BIE4 A0A1Y1M671 A0A147BJX4 A0A147BN28 W4YP04 A0A075EIL5 A0A146L0H7 A0A1Y1NDC5 A0A3P8RHF8 A0A3P8Q2Q2 J9LYD2 A0A0A9VTL5 A0A3B3IIM2 A0A3P9HMN7 A0A0P4ZSZ7 A0A0P6FGF0 J9JQ26 A0A0P5SUC4 A0A0P6C2C2 A0A1S3DSZ0
A0A2S2N8I3 A0A3Q2XZ76 A0A0A9Z4Y4 A0A1Y1L7V1 A0A146LC45 A0A3P9LZF9 A0A3P9K9H2 A0A1A8DQM9 A0A3P9AYU2 A0A3P8R8M6 A0A147BKH7 A0A0P5XDK7 A0A0P5A948 A0A0P6BAV5 A0A0P5V4F7 A0A0P4XRP4 A0A0P5VCW1 A0A0P5DHJ0 A0A267GLM4 A0A1Y1MCJ7 A0A3Q2DE46 I3KYE2 A0A1A8N8J3 A0A147BIE4 A0A1Y1M671 A0A147BJX4 A0A147BN28 W4YP04 A0A075EIL5 A0A146L0H7 A0A1Y1NDC5 A0A3P8RHF8 A0A3P8Q2Q2 J9LYD2 A0A0A9VTL5 A0A3B3IIM2 A0A3P9HMN7 A0A0P4ZSZ7 A0A0P6FGF0 J9JQ26 A0A0P5SUC4 A0A0P6C2C2 A0A1S3DSZ0
Pubmed
EMBL
MRZV01000618
PIK46835.1
MRZV01000576
PIK47528.1
GBBI01004745
JAC13967.1
+ More
GGMR01000868 MBY13487.1 GBHO01004090 JAG39514.1 GEZM01066276 JAV68015.1 GDHC01013957 JAQ04672.1 HADZ01002490 HAEA01007842 SBQ36322.1 GEGO01004116 JAR91288.1 GDIP01073678 JAM30037.1 GDIP01203362 JAJ20040.1 GDIP01019161 JAM84554.1 GDIP01199810 GDIP01181260 GDIP01124130 GDIP01104931 GDIP01053137 GDIP01051184 JAL98783.1 GDIP01239061 JAI84340.1 GDIP01102077 JAM01638.1 GDIP01156216 JAJ67186.1 NIVC01000291 PAA86189.1 GEZM01035137 JAV83383.1 AERX01070080 HAEH01000697 SBR65395.1 GEGO01004841 JAR90563.1 GEZM01041944 JAV80090.1 GEGO01004317 JAR91087.1 GEGO01003204 JAR92200.1 AAGJ04126635 KF319019 AIE48224.1 GDHC01017753 JAQ00876.1 GEZM01011167 JAV93617.1 ABLF02041541 GBHO01044535 JAF99068.1 GDIP01210008 JAJ13394.1 GDIQ01057635 JAN37102.1 ABLF02019772 GDIP01140322 JAL63392.1 GDIP01022208 JAM81507.1
GGMR01000868 MBY13487.1 GBHO01004090 JAG39514.1 GEZM01066276 JAV68015.1 GDHC01013957 JAQ04672.1 HADZ01002490 HAEA01007842 SBQ36322.1 GEGO01004116 JAR91288.1 GDIP01073678 JAM30037.1 GDIP01203362 JAJ20040.1 GDIP01019161 JAM84554.1 GDIP01199810 GDIP01181260 GDIP01124130 GDIP01104931 GDIP01053137 GDIP01051184 JAL98783.1 GDIP01239061 JAI84340.1 GDIP01102077 JAM01638.1 GDIP01156216 JAJ67186.1 NIVC01000291 PAA86189.1 GEZM01035137 JAV83383.1 AERX01070080 HAEH01000697 SBR65395.1 GEGO01004841 JAR90563.1 GEZM01041944 JAV80090.1 GEGO01004317 JAR91087.1 GEGO01003204 JAR92200.1 AAGJ04126635 KF319019 AIE48224.1 GDHC01017753 JAQ00876.1 GEZM01011167 JAV93617.1 ABLF02041541 GBHO01044535 JAF99068.1 GDIP01210008 JAJ13394.1 GDIQ01057635 JAN37102.1 ABLF02019772 GDIP01140322 JAL63392.1 GDIP01022208 JAM81507.1
Proteomes
Pfam
Interpro
IPR036397
RNaseH_sf
+ More
IPR041588 Integrase_H2C2
IPR000477 RT_dom
IPR021109 Peptidase_aspartic_dom_sf
IPR012337 RNaseH-like_sf
IPR041577 RT_RNaseH_2
IPR001584 Integrase_cat-core
IPR001995 Peptidase_A2_cat
IPR001969 Aspartic_peptidase_AS
IPR005162 Retrotrans_gag_dom
IPR036875 Znf_CCHC_sf
IPR001878 Znf_CCHC
IPR024571 ERAP1-like_C_dom
IPR041588 Integrase_H2C2
IPR000477 RT_dom
IPR021109 Peptidase_aspartic_dom_sf
IPR012337 RNaseH-like_sf
IPR041577 RT_RNaseH_2
IPR001584 Integrase_cat-core
IPR001995 Peptidase_A2_cat
IPR001969 Aspartic_peptidase_AS
IPR005162 Retrotrans_gag_dom
IPR036875 Znf_CCHC_sf
IPR001878 Znf_CCHC
IPR024571 ERAP1-like_C_dom
Gene 3D
ProteinModelPortal
A0A3B3HLX7
A0A2G8KFU3
A0A3B1JKR1
A0A3P8S414
A0A2G8KHQ8
A0A023EY30
+ More
A0A2S2N8I3 A0A3Q2XZ76 A0A0A9Z4Y4 A0A1Y1L7V1 A0A146LC45 A0A3P9LZF9 A0A3P9K9H2 A0A1A8DQM9 A0A3P9AYU2 A0A3P8R8M6 A0A147BKH7 A0A0P5XDK7 A0A0P5A948 A0A0P6BAV5 A0A0P5V4F7 A0A0P4XRP4 A0A0P5VCW1 A0A0P5DHJ0 A0A267GLM4 A0A1Y1MCJ7 A0A3Q2DE46 I3KYE2 A0A1A8N8J3 A0A147BIE4 A0A1Y1M671 A0A147BJX4 A0A147BN28 W4YP04 A0A075EIL5 A0A146L0H7 A0A1Y1NDC5 A0A3P8RHF8 A0A3P8Q2Q2 J9LYD2 A0A0A9VTL5 A0A3B3IIM2 A0A3P9HMN7 A0A0P4ZSZ7 A0A0P6FGF0 J9JQ26 A0A0P5SUC4 A0A0P6C2C2 A0A1S3DSZ0
A0A2S2N8I3 A0A3Q2XZ76 A0A0A9Z4Y4 A0A1Y1L7V1 A0A146LC45 A0A3P9LZF9 A0A3P9K9H2 A0A1A8DQM9 A0A3P9AYU2 A0A3P8R8M6 A0A147BKH7 A0A0P5XDK7 A0A0P5A948 A0A0P6BAV5 A0A0P5V4F7 A0A0P4XRP4 A0A0P5VCW1 A0A0P5DHJ0 A0A267GLM4 A0A1Y1MCJ7 A0A3Q2DE46 I3KYE2 A0A1A8N8J3 A0A147BIE4 A0A1Y1M671 A0A147BJX4 A0A147BN28 W4YP04 A0A075EIL5 A0A146L0H7 A0A1Y1NDC5 A0A3P8RHF8 A0A3P8Q2Q2 J9LYD2 A0A0A9VTL5 A0A3B3IIM2 A0A3P9HMN7 A0A0P4ZSZ7 A0A0P6FGF0 J9JQ26 A0A0P5SUC4 A0A0P6C2C2 A0A1S3DSZ0
PDB
4OL8
E-value=5.70417e-53,
Score=529
Ontologies
KEGG
GO
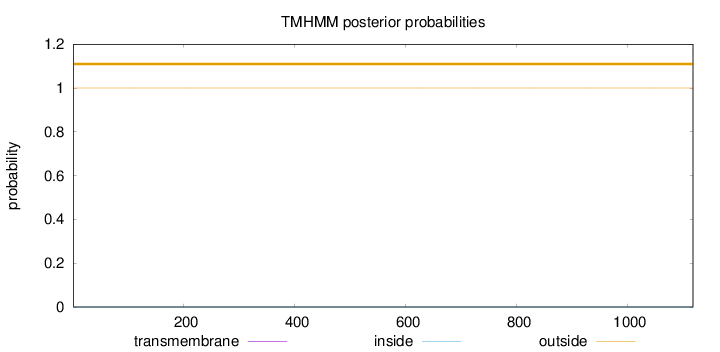
Topology
Length:
1117
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00111
Exp number, first 60 AAs:
0.00015
Total prob of N-in:
0.00002
outside
1 - 1117
Population Genetic Test Statistics
Pi
2.127899
Theta
2.170402
Tajima's D
-1.701354
CLR
57.027364
CSRT
0.0269986500674966
Interpretation
Uncertain
