Gene
KWMTBOMO06301
Pre Gene Modal
BGIBMGA001832
Annotation
Transposon_Tf2-8_polyprotein_[Thelohanellus_kitauei]
Location in the cell
Nuclear Reliability : 4.007
Sequence
CDS
ATGGATAAATACAATCCAGATACATTCAGAATTGACGATTACATTGATTTTTTCGAAAACAAATGCAAAATTCTTGATATCGATAACAGCGACTTACAGAAAGATTTGCTTCTGAATTTACTAACACCAGAGATATTTCACGAATTAAAAGTAGCTTTAACGCCTGATTTCGATATAGCTACATACAGCGAAATTTGTAACAAATTATTAGACCTCTATCGCATAAAAACGACGAGGTATAGAGCCTTAACAGAATTTTGGAATTGCACTAGAGAACAAAATGAAACGATGGAACACTATGCAAACAGATTAAAAGGTCTTAGTCGGGATTGTGGCTACACTAATGACTTCCTGGAACGACAATTACGTGACCGCTTTGCCACTGGATTGAATCATCCAGATTTAGAAACCGACTTGAAACAAAAATGGCCTGATTTAGTTCAAATGGTAGACGGAATACCAAGAGAAGTAACCTTCCAACAAATTTTTACAATCTCTCAATCAAGAGAACAAGCAGAACAAGACACACCACGAACAAGTATTAAAAAAATAACAAGACCTCATAAGTCCTCAACATCATCATCATCATTTATCAGTAATAACGAGGAAGAAAGCGATGATGAAGTTATCTGCAGCGTCTTGGGTACACGTAAGAGAGAATGCAAACAAATCGATGTACGGATCAATGGCATACCTTGCACTATGGATTGGGACCCCGGCTCTGCGTATTCAATAATAAACACGACATTGTGGAAAAAATTAGGATCACCATCTTTACAACCCGCCCCGAAACTTAAGGCCTACGGCAACACAAACTTAAAAACAAAGGGAATTACAAAAGTGACAGTCGAAGTCGACGGACTGCAAAAACTTCTACCTGTGGTCGTAATGAAAAATGCCAAACCAATGTTATTTGGTTTACATTGGAGTGAAGTTTTTGAAATGGAATTTCCAAAACCAGTATACTCCATCAAAACATCAATACCGATTACTCTTAAACAAATACTGGATAAACATTCACAACTCTTTGATGGAAAACTAGGAAAAGTTAACAATTATTACGTAAACATACATGTCAAACCAGAAGCTGAACCGATCCACCTTCCTGCACGGCCTATAAAATTCAGCATGAAAAAGAATATAGAAAGGGAGATAGATCGTCTGATCTCAGAAGGGATAGTGGAAAAAGTAGATCCTAATATTACACCTATTGAATGGGCTACACCCACAGTTAACATTCTGAAATCTACAGGGGAAGTTAGGATATGTGGAGACTACAGAACTACACTTAATCCAGTACTTATTAAACATCTACACCCAGTTCCAATTTTCGATCAACTACGCCAAAATCTCGCAAACGGTAAATTATTTTCAAAAATAGACCTTAAAGACGCATACTTACAATTTGAAATAGCACCGGATTCGAAAAAGTACTTGACGTTGTCAACACATAAAGGGTATTTCCAATACAATAGAATGCCTTTTGGAATATCGACTGCTCCTTCAATTTTCCAACATTTTCTGGATCAACTGCTAGGCGATATCACCAATGTAGCTGTATATTTTGACGACATAGCTATAGCAGGGAAAGATCTTTCAGAACATTTACAAACTTTATCTATTGTATTCGATCGCTTACAAAACGCTGGCCTAAAAGTTAATTTAAAGAAATGTAATTTCTTACAGAATCAGATTGAATACCTAGGTCACATAATAGATAAACATGGCATCCACCCAACCAAATCTAAAATTGATGCCATAACTAAGGCTCCAGCACCGTGTAATGCAAAAGAACTACGATCATTTTTAGGACTAGTTAATTTTTACGAACGGTTTGTATCACACCTTCACGGGATTTGTTCGGATCTTCACGATCTAACTAGTGAAAAAAATAGATGGCGTTGGACTGATCATGAAAACAGAATATTTGAAGATACAAAGAAATGCATAACTTCTTCACAACCATTAATTGCATTTGACGAGAAACGTCCCCTTTATTTAGCATGTGACGCTTCCGAAAAGGGATTGGGTGCAGTATTATTCCACAAGGACTCGAACATAGAACAACCAATTGCTTTTGCTTCAAGGAAACTACGTCCAGCGGAAATGAAATATTCCGTTATTGATCGTGAAGCTTTAGCAATAGTATTTGGTATAAAAAAATTTGATCAGTACTTGAGAGGAACGAAATTTAATCTAGTTACGGACCATAAGCCTCTTATACATATTATGGGTGCACACCGCAACCTTCCTAAACTAGCCAATAACCGATTGGTAAGATGGGCCCTAGTAGTGGGAAGTTATCAATATGATATTTACTACAGGAAAGGTGAAAATAACACATTAGCTGATTGCCTTTCCAGATTACCAAACCCTGAAACTGAACCCTCCGAGACAGAAGGGCTTGTACATAAAATAGATCTACGTCTTTTGAGCACTCGAATGACTGACCTTAATCTATCAGAACAGTTACTTATGAAAACAACTTCAAAGGATCATATACTCACAAAAGTTTGTCAAAATTTAAAAACCGGCTGGAGAGAATCAGATTACAATCCAGAAATGAAACCATTCTACAGAAACCGGACTGAATTATCTGTTGAGAATAAGATACTTATGAGGCAAGGACGCATCGTTATACCTACAGCACTCCGAAAAGCCATTCTTACATACCTTCATCGAGGACATCCTGGCATTTCTGCTATGAAAGCACTTTCACGTTACTATGTTTGGTGGCCTAACCTTGACGAAGACATAGAATTATTTGTCAAGAAATGTACCAGATGCCAACAGAACCGCCCTTGTAATCCTGAACTTCCTGTATTTTCCTGGTCCATACCAGAAGAGGTATGGGAGAGAATCCATATCGACTTTGCTGGACCGTTCGAAGGATCGTATTGGTTGGTATTGTGCGACGCTCTCTCCAAATGGGTGGAAATACGATCGATGAAACACATCAACACCAGATCACTTTGTCTTACATTAGATAACATATTTTGTACATTTGGCTTACCAAAAATGATTATATCCGATAATGGACCTCAATTTACATCTTATGAATTTAAAGAATATTGCACAAAACAATCTATTTTACATGTCACATCATCTCCATATCATCCTCGAACAAATGGGCTGGCAGAACGTTTAGTCAGAACATTCAAAAATAGAATGGCATCGGTAGACAACACAAATCTCGAGCGCCGACTATTAGAATTTTTGTTTACATACAGAAACACTCCGCACTCGTCCACTGGTAAATCTCCAGCTGAGATGATGTTTGGACGACAATTGAATTGCATACTTTCCAACATTCGGCCAGACAAAAGAAGATTAATGCAGTATTTACAAGTAAAAGAAAACATTCGTACCACATCACCGAGTTACCGACCAAGTGACCAAGTATATATTAAAACACGCAATGATAAAATATGGGAACCAGCGGTAATTACATCCCGTAAACATAAATATTCATATATTGTTTCAACACCAGGAGGACTAGAAAAACGAAGACACGCTGATCACATCAGGCCACGCGAGTCCTCCACCTCAGAAACCCCGAGGAATGAAAGGGCGCATTCTTCTATGCTGCCGGCGACTGCTTCTCCAGACATTGGAATGGACACAACAATTGACGAAAGGCTAACTAAAAACAAGAATTCGGCAGCAGTACCATTACCTACACCGCAGTCACCTACAAATGTACAAATTTCTCCAAATTCACCTTCACAGCATTCGAAGTTATACTCCTCACCTGCTCCGGTCTCCACTCCTGTGCCATTTGCTCCGCGTCGAAGAAACGAAATAGTAACTATGGTGGAGCCATCAATTTACAAGTTTACCACAGCTGAAGGGGGTGCTCGTCTCGCTGCAATTGCATCTGAACGTAACACCCTTGCTGTGGAATACTCAAATTTCATTGCAACCAGGCTGGTCTATGAAGAAGCTTATAAGATACGAGGGTCGCTCTATGATAATAAGCAGAGATCAGTGCACGTGACAAGAGAGGATCGTATAAAATGCACCGCCTACGATCTGAGGATTATGACCGACTTGTCGTTGTGTGAGGCTGAGAAATACGATGATGTGTATGATTGGTACGCGGAACTTGATAAGAAAGAAGTTTTGGTCTGCACTTCAGTAGTTTTAAAACGAATTCTAGAAGAGGGAATAATATCAATGGCGAATATTAATGTTCTAATAATTGATAGCTGTCATTTAATAGTGACCGACGAGAATTTGAAATATATTATGCAAGTTTACAAAGATAGCGAAGAATCAAAAAGACCCCGAATACTTTCGTTGACATATCCTCTCTTTGGATCGCACAAAAAATCTGAAGACATTCATAATGACAAACAGGCAGATAACTCTGAGGATTCAAACAAAAGAGACTCATGTAATTTGAAAGATATGCTGATAGAAGAAGATAAACATGATAATGAAAGGTCAGAAAAAGATATGAGACACTCTCAAACTGATTCACCGAATGAAATTACTTGCGACAGTGACATTGGATCTTTGAAAGATACAAAAACAGACCTAGAACAGGATATAGTTGCTGAAGATAAATCATTAGAGAGCGAAAATATCGATGATTTCGATATGTATGAGAAGTTGGAGTGGAAAATTGAGCAACTGGAGAATGAGTTGTGCTGTAAAATGGATCTTGCTGAAGACATCGACACAGGGAAAAGAACAGCGGCGGCATCCACCAAACCAAATGAGCTGATAGTCGAATACTGTCCTCGGAGACCTGATAGCGAGCTCTCAGAGGATTACTTGGAGCTGGAGAGCTACATGAAGAGGACCGTTGAAGACGTCGCGGAGTTTGTTAATGATCACAGACACGATCCCACCGAGATATACGGAGACGAGCTGTACGAGGAGTTCAAGAACATTCCGGACCCGACGAACGAACCCAAAATGATGTTCAAACAGTTCTTACATGTTCTAGAAGAACTGGGTCCTTACGCAGCCGACAAAGCGGCCTTTTCGATATTAACGAAATTAGAGAAGTTAAAAATTAAAGTGCCGTACGAACGACATTTCCTCTTGTTGTGCCTCTGCACGACCGTGTTCGTCAGGATACGATGTTACGCGGACCTCGTGTTCGGGAAGCTGGAGTCGGACTGGGACCGAATCCGGGCCTTCTCGACGCCGAAAATACTGAGGTTGGCCGAAATATTAGAGAGGTTTCGGCCGCCCGATACACCTCACGACGAAGGCAAGAGGAACGGCCTCGCTCAAAACGAAGCCGCCGCCAACTCGAAGGATTCGTGCGCCGAAACATCGAGTTGCATAACGGAAAGCGAAAGCTCTAGCACCATCACTAGTAATTCGAGTTTACGTACCGACAGCGGACATGTGATTCTCGAGTCTGGCAATACCGACAAAGAAAATTTTGCCAGTTTAAATAACGCAGTTAATGTAGTCGCTGACCTGTGCGGTTCTACAGAGAATGTTAAGAACGGTGACAATGGCGGGCGTCTAAATAACACAAGCCCAAATGAAACCGATAATACACAAGTGAAGACCGAGCCTGATGAAGAAAAAATCAAATCGAAAACCCTCGAATTACTGAGTGCTATAGAAAAATGTGATTTCGCGTATTTAGCCGATAGGATAGAAGATAAAGTCAACGCTTACGAAGCTAACCTGAAAGAGATAGACGTTTACATCGACAAGTGCGATAGAGACGGGGATAGCGAACCGAATGAGACCGGGGCACAGGAAGAGAGAAAGTCGTCATATTGTAACGAAAAGATCCCCCAGCCTCACCTAGATCCGCTCCAGGTCAAACCGAGTCCTCTCAGACGTTCCGGGAATCGCGTCAGAGGCAGGACCAAACTCAGGAACAACGCCAATCGAACCCAAAACACGGGACAGAATCCTGACGCCCTGTGTGGCGTTTTATTCGTCAAGGAACCGCTTATGGCCAAAATTCTCTTCATGATTATCGCGGACCTGTCCCGTTGTCATCCGAAGTTATCGTACGTGTGCGCCCAGTACTGTGCAGTAGAGAACCCTGAAGAGTCCCTAGAGCCCAGAGAGTGCCAGCGACAGAATAAGAAACACGAAGATGTTCTCAAGAAGTTCCGGATGCACGAGTGCAACCTGCTGCTGGCCACGGCGGCGCTGGAGGAGGGCATCGACCTGCCGCGCTGCAACCTCGTGCTGAGATGGGACGCGCCGCCCTCGTCAGTATACTTCTGTTTCTGCTCCGCTTTGATGTGA
Protein
MDKYNPDTFRIDDYIDFFENKCKILDIDNSDLQKDLLLNLLTPEIFHELKVALTPDFDIATYSEICNKLLDLYRIKTTRYRALTEFWNCTREQNETMEHYANRLKGLSRDCGYTNDFLERQLRDRFATGLNHPDLETDLKQKWPDLVQMVDGIPREVTFQQIFTISQSREQAEQDTPRTSIKKITRPHKSSTSSSSFISNNEEESDDEVICSVLGTRKRECKQIDVRINGIPCTMDWDPGSAYSIINTTLWKKLGSPSLQPAPKLKAYGNTNLKTKGITKVTVEVDGLQKLLPVVVMKNAKPMLFGLHWSEVFEMEFPKPVYSIKTSIPITLKQILDKHSQLFDGKLGKVNNYYVNIHVKPEAEPIHLPARPIKFSMKKNIEREIDRLISEGIVEKVDPNITPIEWATPTVNILKSTGEVRICGDYRTTLNPVLIKHLHPVPIFDQLRQNLANGKLFSKIDLKDAYLQFEIAPDSKKYLTLSTHKGYFQYNRMPFGISTAPSIFQHFLDQLLGDITNVAVYFDDIAIAGKDLSEHLQTLSIVFDRLQNAGLKVNLKKCNFLQNQIEYLGHIIDKHGIHPTKSKIDAITKAPAPCNAKELRSFLGLVNFYERFVSHLHGICSDLHDLTSEKNRWRWTDHENRIFEDTKKCITSSQPLIAFDEKRPLYLACDASEKGLGAVLFHKDSNIEQPIAFASRKLRPAEMKYSVIDREALAIVFGIKKFDQYLRGTKFNLVTDHKPLIHIMGAHRNLPKLANNRLVRWALVVGSYQYDIYYRKGENNTLADCLSRLPNPETEPSETEGLVHKIDLRLLSTRMTDLNLSEQLLMKTTSKDHILTKVCQNLKTGWRESDYNPEMKPFYRNRTELSVENKILMRQGRIVIPTALRKAILTYLHRGHPGISAMKALSRYYVWWPNLDEDIELFVKKCTRCQQNRPCNPELPVFSWSIPEEVWERIHIDFAGPFEGSYWLVLCDALSKWVEIRSMKHINTRSLCLTLDNIFCTFGLPKMIISDNGPQFTSYEFKEYCTKQSILHVTSSPYHPRTNGLAERLVRTFKNRMASVDNTNLERRLLEFLFTYRNTPHSSTGKSPAEMMFGRQLNCILSNIRPDKRRLMQYLQVKENIRTTSPSYRPSDQVYIKTRNDKIWEPAVITSRKHKYSYIVSTPGGLEKRRHADHIRPRESSTSETPRNERAHSSMLPATASPDIGMDTTIDERLTKNKNSAAVPLPTPQSPTNVQISPNSPSQHSKLYSSPAPVSTPVPFAPRRRNEIVTMVEPSIYKFTTAEGGARLAAIASERNTLAVEYSNFIATRLVYEEAYKIRGSLYDNKQRSVHVTREDRIKCTAYDLRIMTDLSLCEAEKYDDVYDWYAELDKKEVLVCTSVVLKRILEEGIISMANINVLIIDSCHLIVTDENLKYIMQVYKDSEESKRPRILSLTYPLFGSHKKSEDIHNDKQADNSEDSNKRDSCNLKDMLIEEDKHDNERSEKDMRHSQTDSPNEITCDSDIGSLKDTKTDLEQDIVAEDKSLESENIDDFDMYEKLEWKIEQLENELCCKMDLAEDIDTGKRTAAASTKPNELIVEYCPRRPDSELSEDYLELESYMKRTVEDVAEFVNDHRHDPTEIYGDELYEEFKNIPDPTNEPKMMFKQFLHVLEELGPYAADKAAFSILTKLEKLKIKVPYERHFLLLCLCTTVFVRIRCYADLVFGKLESDWDRIRAFSTPKILRLAEILERFRPPDTPHDEGKRNGLAQNEAAANSKDSCAETSSCITESESSSTITSNSSLRTDSGHVILESGNTDKENFASLNNAVNVVADLCGSTENVKNGDNGGRLNNTSPNETDNTQVKTEPDEEKIKSKTLELLSAIEKCDFAYLADRIEDKVNAYEANLKEIDVYIDKCDRDGDSEPNETGAQEERKSSYCNEKIPQPHLDPLQVKPSPLRRSGNRVRGRTKLRNNANRTQNTGQNPDALCGVLFVKEPLMAKILFMIIADLSRCHPKLSYVCAQYCAVENPEESLEPRECQRQNKKHEDVLKKFRMHECNLLLATAALEEGIDLPRCNLVLRWDAPPSSVYFCFCSALM
Summary
Uniprot
ProteinModelPortal
PDB
4OL8
E-value=2.23756e-53,
Score=535
Ontologies
GO
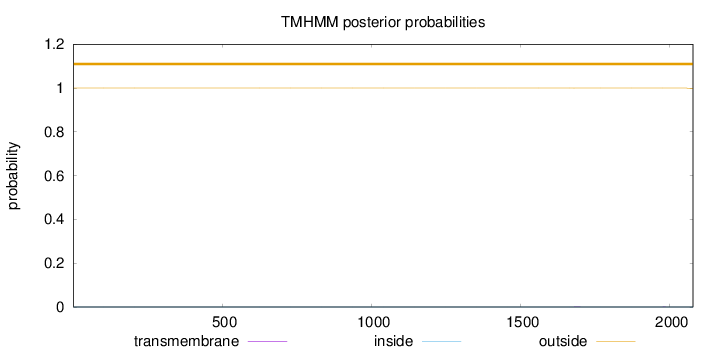
Topology
Length:
2077
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.01053
Exp number, first 60 AAs:
0.00017
Total prob of N-in:
0.00003
outside
1 - 2077
Population Genetic Test Statistics
Pi
27.418248
Theta
195.02596
Tajima's D
0.64593
CLR
0.652923
CSRT
0.55837208139593
Interpretation
Uncertain
