Gene
KWMTBOMO06227 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA001644
Annotation
PREDICTED:_la-related_protein_1_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.994
Sequence
CDS
ATGACGGCCGGCGTCACGGCCAGGAGGAAGTCGAGGGCGAGGAGGAGCTGGGCCAAAGTGGAGAACGACGCGCAGGCGTCAGACTTCACGGATATCGGCGACTGGCCGACGCTCGGGGCAGCTGTGGCAGCCTCGAGATGTCACTCGACCCCGCCCCACGACACAGACTCCACGCATCATAATGGCACATTGGAACAAGAACGGAAGCCCCTCGAGGAGCACCATCAGCATCCCCAGAACCAGGCGAAGGTCGACAAGCCGGAGCCGCTTCAGAACCATCACGGTTCGAATGACAAACATCAGGATAAAAAGAACTCGGGCGGCAACAAATCCGGCAAGCACAAGTGGGTGCCTCTGGACATCGAAGTGAAGGGCCCCAGGCAGAACAAGCACGGTCCTCCGCATGGTGCGAGGCCTGAGAACGACACGGTTTCCCTGAACGGCGAGGAGCGTCCCCGCGGGGCACGCTCGGTGCGCGGCGGGGGGCGAGGTCGCGGCGCCCGGCGCCCCGGCCCGCGCCCCGTGTCCGCACTGTCCGCGCTCGCCGCCCCGCCGCACGCCGTGTTCCACCACCCTCACGACTTCGGCCACCATCCGGAACTGTCACAGCTGCGGATACCACAAGCGGGTTTGGCACAGGGTCTAGTGATGCAGTACCCCGGCTTGGCGCTGGGAGGTCTCGGAGCCGGTCTCGCCCAGGCTTATTACTACGGAGCGGCCGCCGCGACCGCTGCCCCATACGGACTAGGTCTGGACCAAGTAACGTTGAAGGATTTGATCAAGAAACAAATCGAATACTACTTCAGTCCGGATAACCTGGCCCGCGACTTCTTCCTGAGACGGAAGATGTCCCCGGACGGCACCATACCGGTGACGCTGATCGCCTCGTTCCACCGCGTCCGGGCGCTCACCTCAGACGTGCAGCTGGTCCTCGACGCGATCCGGGACTCGGAGCGGCTGGAGCTCATCAGCGGCTTCAAGGTGCGGACCGTGTTCGAGCCGACCAAGTGGCCGATACTGGACGTGGCGACCAGCTCCGACGAGGGCGAGAGGCCGGAGAGACCGAAGCCGGCCGAGCCCGAAAAGGCCGGGGCGGAGAAGACGAATCCCGAAAACAACGAAAAGGAACAGGCCAAGACAAACGCCGATGATGTCGTTCAAGTTAAGGAGGACATTGTCGAGGCTCCCAGTATAGAGCGGAAAGATGAGAAGGTTGAACCCGAGACGATAAAAGAACAACCGAATGATGTGAACAACTCCGACGTGGTCGTGGACACTGCGAAGGTCGTAGTGCCTGAACACGTGGAAGATGTAAAGGTGGAAGATGACAAGGAAGTGCAGACCTCTCCGCCGCCGGAGCAGAAGGCGGACAGCGCTCCTGACACTCAGGAAGACAAGAAGCTGGATTCCAGTGACGATCCCCCGCTGCAGACCGAGGGGACCGAGGAGAGGCCGGGCGAGAAACGTCGCAAGAAGCAGATGGTGGGCATCTTCCCGCTGGCGACCATGGGCGGGCCGCTGGTGGCGCCCGTGTCCGGCCTGCTGCGAGCCGTGCCGCCCCCACCCCTGCCGCGGATGTTCCGCACGAGCAGGCCCGGCCCGACGCCGCCGCACGACTCGCTCGACCCGAACGTGCCCGAGTTCGTGCCGCAGGCGAGGCGACAAGAGGACAACGGCAGCGAGCCGGGGGAGCAGCCGGGGGGCCGCCCGCGCTCCGCCGCGCACAGCCCGCAGGCCGAGGGCGGCGCCGCCGACTGGACCGAGGTGAAACGTCGAACGAAAGCCGGCTCCCGCGAGCGCTCCGCCGCCGGGGGGCCCGCGACGGACGGGGAAGTCCCCGACGAGGAGCCTCGCGAGGAGCTGCACTTCCAACTGGACGAAGAACTCGACTTACCTCCACCGAGACACAACACCTTCACCGATGCTTGGTCCGACGAGGAGTCGGACGCGGAGTTCACGGACGGCGATGTGGGGCGGCTGCTGATCGTGACGCAGACGACGCGTGCCGCCAAGCACGACGGACACGACCGCCAGGGGGACTGGACCAGCCGCACCAAGATCACGCAGGACCTCGAGCAGGTCATTACCGACGGACTGCGTCGTTACGAAGAGGACCTGTGGAACGACACAGAATATACTTCATCGTACGGTAGCGGCCGTGAGTACCGCACTGTGAGCCTGATCAGCCGTGAGCAGTTCGAGGCAGCCGTGCCAAACGAGCGGCATAGGAACCCCGCCCGCCCCCCGCCGCCCCCCGCGCACCCCCACCACCAGGTGGATCAGCAGCCGGCCGGTGGCGGCAAGGCGTCTCGTCCCCGGCGAACCGCGCGCTTCTACGCGGCCAGCAAGGACCCACACGCTACCGATGTCATCTGCAGCAGGAAGCACAAGACCAGATACAGCCTCAACCCGCCCGTGGAGCACCACGTCGGCTGGATCATGGACGTGCGCGAACACCGACCCAGGACTCAAAGCACCGGGTCGTCGCTGGGCGCGTCGCCGACGCTGGGCTCGTCGTGCGGCTCCATGCCGCAGTCCCTGCCGACCTTCCACCACCCCAGCCACGGTCTGCTGCGGGAGAACCACTTCACGCAACAGGCGTACCACAAGTACCACTCGCGCTGTCTCAAAGAACGAAAGAAGCTCGGCATCGGGCAGTCGCAGGAGATGAACACGCTCTTCCGTTTCTGGTCCTTCTTCCTGAGGGACCACTTCAACAGGACCATGTACAACGAGTTCAGGTCGTTGGCCATCGAGGACGCGCAGGCCGGCTTCCGCTACGGGCTCGAGTGCCTGTTCCGCTTCTACTCGTACGGGCTCGAGAGGAAGTTCCGGCCGGAGCTCTACCAGCACTTCCAGACGGAGACGATGGCGGACTACGAGAAAGGTCAGCTTTACGGCCTGGAAAAGTTCTGGGCGTTTTTGAAGTACTACAAGCACGCGAGCGCTTTGCAAGTCGAGCCTAAGCTCCAGGGATACTTGTCGAAGTTCAAAAGCATTGAAGACTTTCGTGTGCTCGAGGCGCGGCGCGGCGTGCGGGGGCGGGGCGGCGTGCGGCGCGGCGGCGTGCAGCGCCAGCAAGTCGCGAGGTCGCGCTGGTTCGTGCGGCGCCTCCGCTGGCAGGACGCGTGCGAATCAAAAGCAGAAACCGGAGACCGCCGTCCCGACCGAGGTCAAGTCTATAGCAGCTAA
Protein
MTAGVTARRKSRARRSWAKVENDAQASDFTDIGDWPTLGAAVAASRCHSTPPHDTDSTHHNGTLEQERKPLEEHHQHPQNQAKVDKPEPLQNHHGSNDKHQDKKNSGGNKSGKHKWVPLDIEVKGPRQNKHGPPHGARPENDTVSLNGEERPRGARSVRGGGRGRGARRPGPRPVSALSALAAPPHAVFHHPHDFGHHPELSQLRIPQAGLAQGLVMQYPGLALGGLGAGLAQAYYYGAAAATAAPYGLGLDQVTLKDLIKKQIEYYFSPDNLARDFFLRRKMSPDGTIPVTLIASFHRVRALTSDVQLVLDAIRDSERLELISGFKVRTVFEPTKWPILDVATSSDEGERPERPKPAEPEKAGAEKTNPENNEKEQAKTNADDVVQVKEDIVEAPSIERKDEKVEPETIKEQPNDVNNSDVVVDTAKVVVPEHVEDVKVEDDKEVQTSPPPEQKADSAPDTQEDKKLDSSDDPPLQTEGTEERPGEKRRKKQMVGIFPLATMGGPLVAPVSGLLRAVPPPPLPRMFRTSRPGPTPPHDSLDPNVPEFVPQARRQEDNGSEPGEQPGGRPRSAAHSPQAEGGAADWTEVKRRTKAGSRERSAAGGPATDGEVPDEEPREELHFQLDEELDLPPPRHNTFTDAWSDEESDAEFTDGDVGRLLIVTQTTRAAKHDGHDRQGDWTSRTKITQDLEQVITDGLRRYEEDLWNDTEYTSSYGSGREYRTVSLISREQFEAAVPNERHRNPARPPPPPAHPHHQVDQQPAGGGKASRPRRTARFYAASKDPHATDVICSRKHKTRYSLNPPVEHHVGWIMDVREHRPRTQSTGSSLGASPTLGSSCGSMPQSLPTFHHPSHGLLRENHFTQQAYHKYHSRCLKERKKLGIGQSQEMNTLFRFWSFFLRDHFNRTMYNEFRSLAIEDAQAGFRYGLECLFRFYSYGLERKFRPELYQHFQTETMADYEKGQLYGLEKFWAFLKYYKHASALQVEPKLQGYLSKFKSIEDFRVLEARRGVRGRGGVRRGGVQRQQVARSRWFVRRLRWQDACESKAETGDRRPDRGQVYSS
Summary
Uniprot
EMBL
Proteomes
Interpro
SUPFAM
SSF46785
SSF46785
Gene 3D
ProteinModelPortal
PDB
5V87
E-value=3.85535e-62,
Score=608
Ontologies
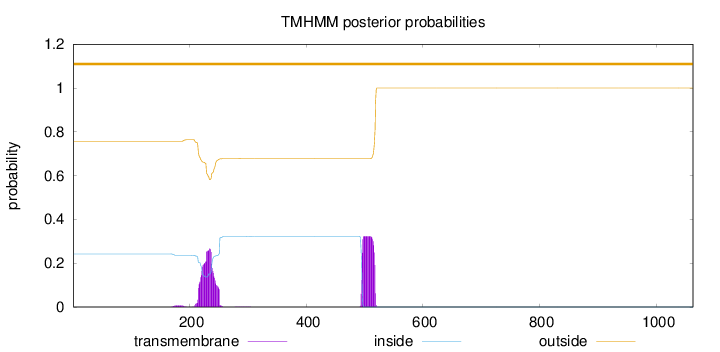
Topology
Length:
1063
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
13.88886
Exp number, first 60 AAs:
0
Total prob of N-in:
0.24248
outside
1 - 1063
Population Genetic Test Statistics
Pi
289.278852
Theta
176.417394
Tajima's D
1.578617
CLR
0.391293
CSRT
0.80385980700965
Interpretation
Uncertain
